OpenMMLab AI实战营——学习笔记(一)
(一)计算机视觉算法基础与OpenMMLab介绍
一、计算机视觉基础
1.Computer Vision Tasks
机器视觉(又名计算机视觉),计算机视觉是一门让计算机学会"看"的学科,通过计算机算法对图像或视频信息进行数据挖掘、识别、处理,如图像识别、模式识别、特征提取等一系列操作。我们可将其用于一些基础任务,比如图像分类(Image Classification,例:手机拍图识物)、目标检测 (Object Detection,例:识别并标注不同类别)、语义分割(Semantic Segmentation,把每个像素进行分类)、实例分割(Instance Segementation,将每个物体分别识别出来)、关键点检测 (Keypoints Detection,输出若干关键点坐标)。
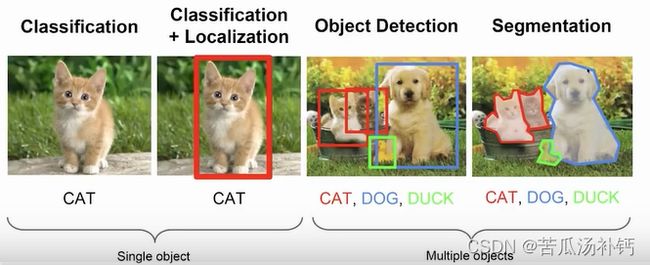
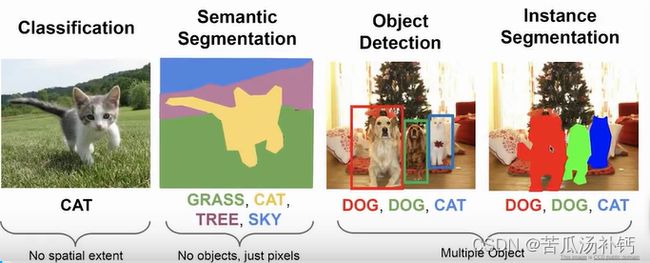
从难易程度而言,实例分割 Instance Segementation 最难,图像分类最简单。
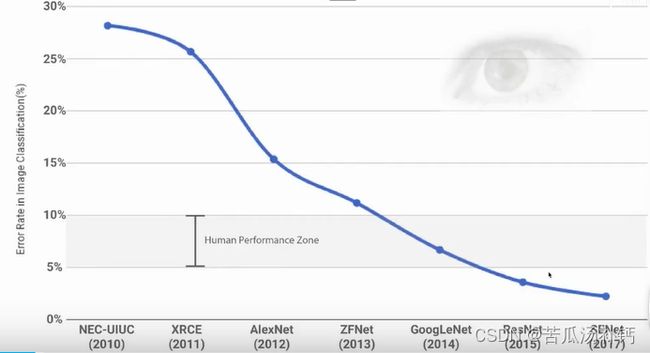
自2012年 AlexNet 的出现,计算机视觉开始应用深度学习,特别是深度卷积式神经网络 (Convolutional Neural Networks, CNN)。例如,目标检测(Object Detection)随着近年来深度学习技术的进步,目标检测技术的研发也取得了较大的突破。2012 年之前的是传统的目标检测方法,但随着深度卷积式神经网络 (Convolutional Neural Networks, CNN)的出现,将目标检测方法的研发重点聚焦在了对基于深度知识的目标测试的探索。
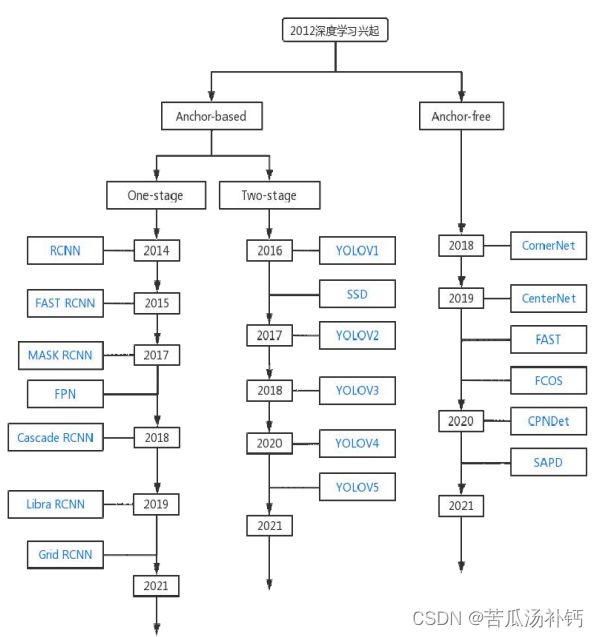
也是从2012年 AlexNet 出现后,计算机视觉的基础任务——图像分类(Image Classification)错误率大大降低。从2012年开始,模型越来越大、参数越来越多,结果越来越精准,2015年更是在 ResNet 时使得错误率低于人类水平(5%~10%)。深度学习,实际上是用深度卷积式神经网络 (Convolutional Neural Networks, CNN)解决数据挖掘问题。
2.计算机视觉发展
早期萌芽时期(1960~1980),最早可以进行边缘提取;统计机器学习与模式识别(1990~2000),开始有人脸检测,人工构建视觉特征;ImageNet 大型数据库(2006),开始建立数据库;初有成效的视觉系统(~2010),底层仍由人工构造;深度学习时代(2012至今)。
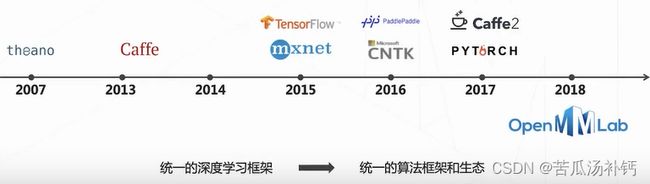
3.开源成为人工智能领域发展引擎
框架学习pytorch足矣,其应用程度与认可度都非常不错。OpenMMLab是基于pytorch搭建的,封装了许多新功能。
二、OpenMMLab算法体系
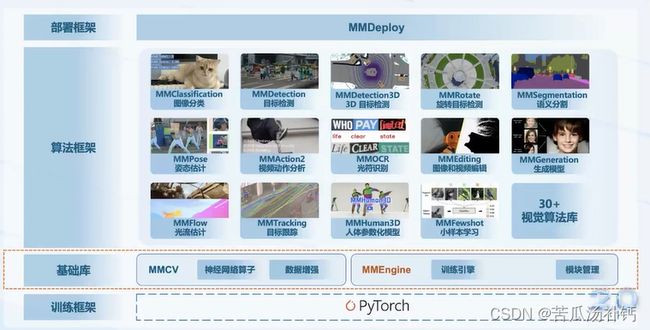
OpenMMLab,深度学习时代最完整的计算机视觉开源算法体系,涵盖计算机视觉的方方面面,支持算法训练部署一体化。
1.算法框架介绍

MMDetection支持目标检测 (Object Detection)、实例分割(Instance Segementation)、全景分割(Panoptic Segmentation)。全景分割,在实例分割基础上加入对背景的处理,应用于无人驾驶。
MMDetection3D,通过点云数据绘制3D的框对图像进行处理,应用于无人驾驶。通过无人驾驶汽车的激光雷达点云数据可感知其他车辆的3D位置。
MMClassification,图像分类库,支持丰富的模型库。
MMSegementation 专门用于语义分割(Semantic Segmentation),可用于无人驾驶、遥感、医疗影像分析。
MMPose & MMHuman3D专门对人体进行分析处理,可进行二维的关节点检测,也可进行三维的立体重现。
MMTracking专门用于追踪目标,可以在每帧中单独定位并识别单个或多个目标,并生成视频序列中的目标运动轨迹。
MMAction2,视频行为理解框架,可进行行为识别、时序动作检测、时空动作检测。
MMOCR,做文本检测、文本识别、关键信息提取,有效果极佳的预训练模型、流行的学术数据集支持、丰富的训练技巧。
MMEditing,底层视觉,在像素层面上进行图像修复、抠图、超分辨率、图像生成等,15种算法支持,30个与训练模型。例如,对古代碑文的残缺部分进行修复。
OpenMMLab涵盖了计算机视觉的各种问题,复现了许多前沿算法,可直接运用算法调用模型库。
2.OpenMMLab 2.0简介
OpenMMLab 2.0框架如下图所示。
三、机器学习
1.机器学习基础
机器学习——“从数据中学习经验,以解决特定问题”。机器学习的典型范式:监督学习、无监督学习、强化学习。
监督学习,有标签。图像分类、目标检测、图像分割都需要先用人标注和的数据去训练算法,算法再将输入的未标记的数据进行标注与预测,这些都属于监督学习。无监督学习,没有标签,无需运用数据本身的标注,例如聚类降维。强化学习,让智能体自己去适应环境。
2.机器学习中的分类问题
(1)特征与分类
将不同的数据模态变成向量,再由这个向量特征去学习n维空间的一个决策边界。关键词提取、统计,形成词频向量,用词频向量代表一个文本,称为特征。特征可以看作是向量空间中的点,不同类文本分布在空间中不同的位置上,将空间划分为不同的区域就可以对目标进行分类。
(2)线性分类器
通过拟合得出边界则为分类问题,如果这个边界为一条直线则为线性分类器。线性分类器假设类别和特征之间存在某种线性关系,换言之,不同类的数据在特征空间中可以被一条线分开。

如何求解分界面?给定两类数据,如何求解可以将两类数据分开的分界面?我们可以由标注的数据去预测得到损失函数的值,在按照使得损失函数最小化的方向去迭代优化权重,不断迭代训练最总收敛,得到合适的决策边界。
感知器Perceptron:从数据中学习。感知器算法是神经网络的一个雏形,实际上也是一个线性分类器。
3.机器学习的基本流程
(1)训练
需要采集一些数据,标注它们的类别,从中选取一部分用于训练分类器,得到一个可以用于分类的分类器。
(2)验证
从采集、标注的数据中另外选取一部分,测试所得分类器的分类精度验证所用的数据不能和训练重合,以保证分类器的泛化性能∶在一部分数据上训练的分类器可以在其余的数据上表现出足够的分类精度。
(3)应用
将经过验证的分类器集成到实际的业务系统中,实现对应的功能在应用阶段,分类器面对的数据都是在训练、验证阶段没有见过的。
四、卷积神经网络基础
1.神经网络的结构
神经元——神经网络的基本组成单位。
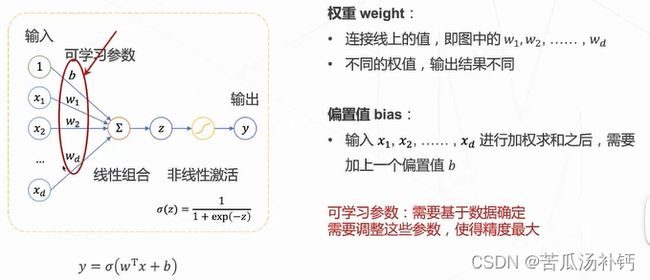
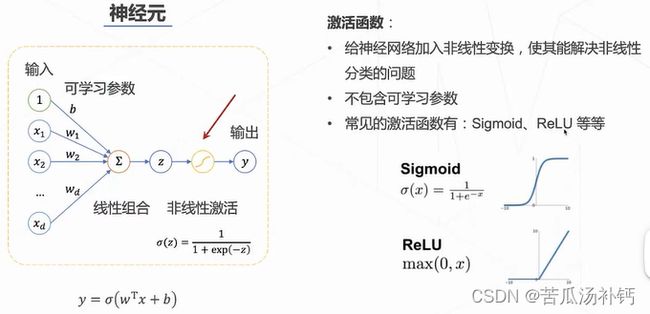
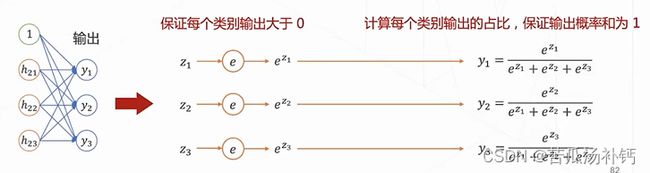
神经网络的输出层∶如果是多分类任务,那么神经网络的输出就有多个(多选一)y1,y2,y3......每个输出yi介于0~1之间,且所有输出的和为1,表示为一个有效的概率分布。为了满足上述特性,输出层的激活函数使用softmax。
2.神经网络的训练
如何衡量神经网络的性能?错误率越低越好;定义连续的损失函数作为媒介。
怎么找到这个最好的可学习参数w的值?调整w降低损失函数→最优化问题。
(1)常用的损失函数:交叉嫡损失Cross-Entropy Loss。

(2)梯度下降算法:调整w,降低损失函数的值
神经网络的训练目标:找到一组比较好的可学习参数w的值,使得神经网络的性能最好。基于梯度下降算法寻找最优参数,进而得到最优(准确率最高)的网络。
如何计算损失函数对于网络参数的梯度?Naive ldea:损失函数是参数的复杂函数——复合函数求导的链式法则。
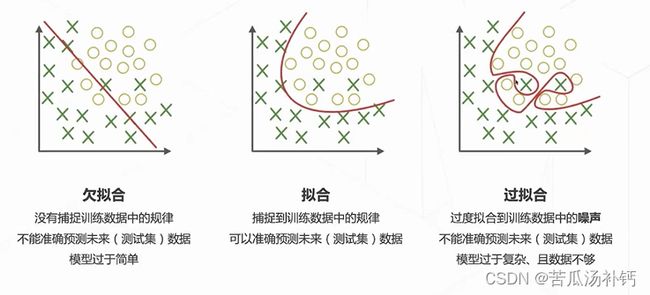
(3)欠拟合、拟合、过拟合
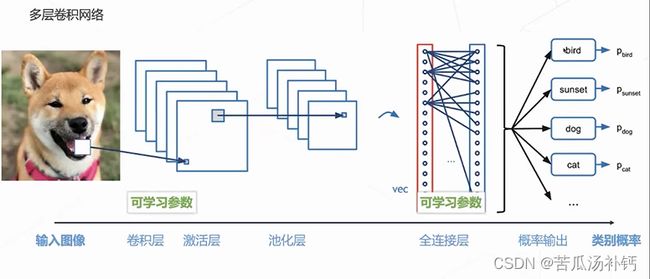
3.卷积神经网络
深度神经网络处理图片数据时存在问题:参数量巨大;没有考虑图像本身的二维结构。卷积神经网络的整体结构如下图所示。