faster-rcnn构建backbone(fpn结构)
torch 1.10以上 对应torch vision
不含fpn结构(一个预测特征层)
修改train文件更改create_model
导入包
import os import datetime import torch import transforms from network_files import FasterRCNN, AnchorsGenerator from my_dataset import VOCDataSet from train_utils import GroupedBatchSampler, create_aspect_ratio_groups from train_utils import train_eval_utils as utils
def create_model(num_classes): import torchvision from torchvision.models.feature_extraction import create_feature_extractor
# vgg16
backbone = torchvision.models.vgg16_bn(pretrained=False)
# pretrained设为true会自动下载预训练权重,实例化vgg16模型
# print(backbone)
backbone = create_feature_extractor(backbone, return_nodes={"features.42": "0"})
# out = backbone(torch.rand(1, 3, 224, 224))
# print(out["0"].shape)
backbone.out_channels = 512
采用下采样16倍的特征层不要32倍,(由原图像224*224到7*7)倍率过大难以检测尺度较小的目标。针对vgg16:
# def forward(self, x: torch.Tensor) -> torch.Tensor: # x = self.features(x) # x = self.avgpool(x) # x = torch.flatten(x, 1) # x = self.classifier(x) # return x
feature:14*14*512后即是max pooling7*7*512所有去掉全连接层
"0":构建backbone后对应值
通过create_feature_extractor方法重构backbone能获取中间层的输出
return_nodes={"features.42": "0"}
其中features.42对应最后一个卷积层14*14*512的最后一个模块
查看方法:
1.查看源码模型nodes
2.print(backbone)设断点如下:
VGG(
(features): Sequential(
(0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(4): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU(inplace=True)
(6): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(7): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(8): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(9): ReLU(inplace=True)
(10): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(11): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(12): ReLU(inplace=True)
(13): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(14): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(15): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(16): ReLU(inplace=True)
(17): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(18): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(19): ReLU(inplace=True)
(20): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(21): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(22): ReLU(inplace=True)
(23): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(24): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(25): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(26): ReLU(inplace=True)
(27): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(28): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(29): ReLU(inplace=True)
(30): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(31): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(32): ReLU(inplace=True)
(33): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(34): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(35): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(36): ReLU(inplace=True)
(37): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(38): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(39): ReLU(inplace=True)
(40): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(41): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(42): ReLU(inplace=True)
(43): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(avgpool): AdaptiveAvgPool2d(output_size=(7, 7))
(classifier): Sequential(
(0): Linear(in_features=25088, out_features=4096, bias=True)
(1): ReLU(inplace=True)
(2): Dropout(p=0.5, inplace=False)
(3): Linear(in_features=4096, out_features=4096, bias=True)
(4): ReLU(inplace=True)
(5): Dropout(p=0.5, inplace=False)
(6): Linear(in_features=4096, out_features=1000, bias=True)
)
)
删除maxpooling,保留至42层
为backbone设置一个参数
# out = backbone(torch.rand(1, 3, 224, 224)) # print(out["0"].shape) 查看该处断点输出out shape backbone.out_channels = 512
以上vgg16backbone构建完成
resnet50:
# resnet50 backbone
# backbone = torchvision.models.resnet50(pretrained=False)
# # print(backbone)
# backbone = create_feature_extractor(backbone, return_nodes={"layer3": "0"})
# layer3对应conv4刚好下采样16倍
# # out = backbone(torch.rand(1, 3, 224, 224))
# 下采样16倍后224/16=14
# # print(out["0"].shape)
# shape为14*14,channel为1024
# backbone.out_channels = 1024
resnet101,152同理
EfficientNetB0:
# EfficientNetB0
# backbone = torchvision.models.efficientnet_b0(pretrained=False)
# # print(backbone)
# backbone = create_feature_extractor(backbone, return_nodes={"features.5": "0"})
# 通过stage6刚好下采样16倍,stage7的stride为2,下采样变为32倍
# stage6对应feature模块索引为5的位置
# # out = backbone(torch.rand(1, 3, 224, 224))
# # print(out["0"].shape)
# size(1,112,14,14)
# backbone.out_channels = 112
搭建faster-rcnn
anchor_generator = AnchorsGenerator(sizes=((32, 64, 128, 256, 512),),
aspect_ratios=((0.5, 1.0, 2.0),))
# 实例化AnchorsGenerator
# sizes元组类型:一个特征层上使用的anchorsizes
# aspect_ratios元组类型:每一个sizes的ratios
# 若不定义在fasterrcnn内部会自动构建fpn结构的AnchorsGenerator和roi_pooler
roi_pooler = torchvision.ops.MultiScaleRoIAlign(featmap_names=['0'], # 在哪些特征层上进行RoIAlign pooling
# MultiScaleRoIAlign是mask-rcnn中的结构,更加精确
output_size=[7, 7], # RoIAlign pooling输出特征矩阵尺寸
sampling_ratio=2) # 采样率
model = FasterRCNN(backbone=backbone,
num_classes=num_classes,
rpn_anchor_generator=anchor_generator,
box_roi_pool=roi_pooler)
return model
以上faster-rcnn不含rpn结构
含fpn
1.获取那些特征层?
2.特征层对应哪些模块的输出?
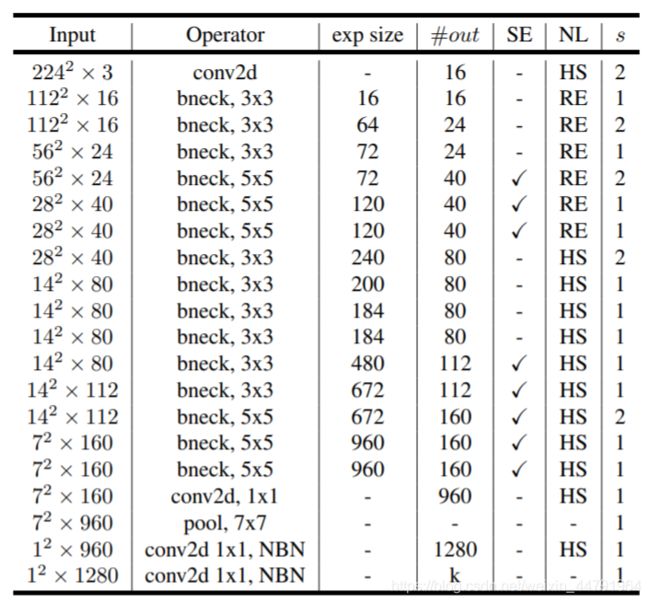 mobilenetv3-large
mobilenetv3-large
import os
import datetime
import torch
import transforms
from network_files import FasterRCNN, AnchorsGenerator
from my_dataset import VOCDataSet
from train_utils import GroupedBatchSampler, create_aspect_ratio_groups
from train_utils import train_eval_utils as utils
from backbone import BackboneWithFPN, LastLevelMaxPool
def create_model(num_classes):
import torchvision
from torchvision.models.feature_extraction import create_feature_extractor
# --- mobilenet_v3_large fpn backbone --- #
backbone = torchvision.models.mobilenet_v3_large(pretrained=True)
# print(backbone)
return_layers = {"features.6": "0", # stride 8
"features.12": "1", # stride 16
"features.16": "2"} # stride 32
# 以上在pool前的16个模块,s列查看下采样倍数
# 提供给fpn的每个特征层channel
in_channels_list = [40, 112, 960]
new_backbone = create_feature_extractor(backbone, return_layers)
img = torch.randn(1, 3, 224, 224)
outputs = new_backbone(img)
[print(f"{k} shape: {v.shape}") for k, v in outputs.items()]
即可查看shape和channel
fpn结构:
backbone_with_fpn = BackboneWithFPN(new_backbone,
return_layers=return_layers,
in_channels_list=in_channels_list,
out_channels=256,
extra_blocks=LastLevelMaxPool(), #最高层之上maxpooling采样,尺度更小,只参与rpn部分运算,在fastrcnn中不使用
re_getter=False) # 重构过backbone不需要再重构
anchor_sizes = ((64,), (128,), (256,), (512,))
aspect_ratios = ((0.5, 1.0, 2.0),) * len(anchor_sizes)
anchor_generator = AnchorsGenerator(sizes=anchor_sizes,
aspect_ratios=aspect_ratios)
RoIAlign在fastrcnn中使用到的
roi_pooler = torchvision.ops.MultiScaleRoIAlign(featmap_names=['0', '1', '2'], # 在哪些特征层上进行RoIAlign pooling
output_size=[7, 7], # RoIAlign pooling输出特征矩阵尺寸
sampling_ratio=2) # 采样率
model = FasterRCNN(backbone=backbone_with_fpn,
num_classes=num_classes,
rpn_anchor_generator=anchor_generator,
box_roi_pool=roi_pooler)
return model
以下efficientnet_b0
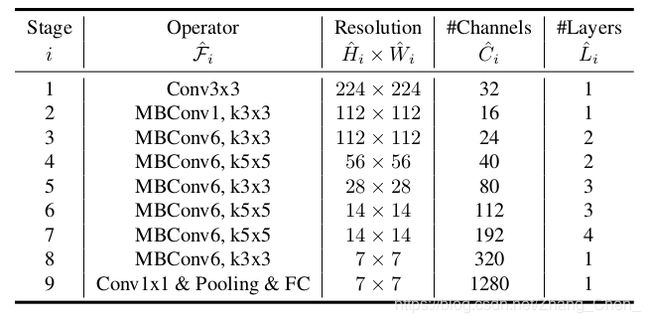
# --- efficientnet_b0 fpn backbone --- #
# backbone = torchvision.models.efficientnet_b0(pretrained=True)
# # print(backbone)
# return_layers = {"features.3": "0", # stride 8
# "features.4": "1", # stride 16
# "features.8": "2"} # stride 32
# # 提供给fpn的每个特征层channel
# in_channels_list = [40, 80, 1280]
# new_backbone = create_feature_extractor(backbone, return_layers)
# # img = torch.randn(1, 3, 224, 224)
# # outputs = new_backbone(img)
# # [print(f"{k} shape: {v.shape}") for k, v in outputs.items()]
自己训练效果一般很差,建议采用coco上预训练权重