AlexNet 经典论文阅读报告 -ImageNet Classification with Deep Convolutional Neural Networks 文献综述
ImageNet Classification with Deep Convolutional Neural Networks 文献综述
阅读时间 :2021年10月15日
论文基本信息
作者在当时借助这篇论文提出了AlexNet ,奠定了深度学习在计算机视觉领域中的地位。
AlexNet被认为是计算机视觉领域最有影响力的论文之一,它刺激了更多使用卷积神经网络和GPU来加速深度学习的论文的出现[17]。截至2020年,AlexNet论文已被引用超过54,000次。 ---- 维基百科
作者
- Alex Krizhevsky 亚历克斯·克里热夫斯基
University of Toronto 多伦多大学 - lya Sutskever
University of Toronto - Geoffrey E. Hinton
University of Toronto
被引用次数:88564
论文主要阐述的内容
作者训练了一个大型深度卷积神经网络,在ImageNet LSVRC-2010 竞赛中的120万张高分辨率图像分类为1000个不同类别。在测试数据上,我们取得了top-1和top-5的错误率分别为37.5%和17.0%,在当时其错误率都远远低于其他的方法。
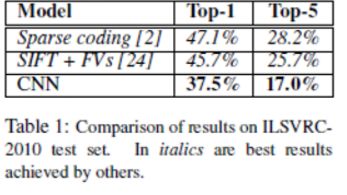
此前不了解top-1以及top-5的概念,查阅资料后如下:
Top-1 error 的意思是:假如模型预测某张动物图片(一只猫)的类别,且模型只输出1个预测结果,那么这一个结果正好能猜出来这个动物是只猫的概率就是Top-1正确率。猜出来的结果不是猫的概率则成为Top-1错误率。简单来说就是模型猜错的概率。
Top-5 error 的意思是:假如模型预测某张动物图片(还是刚才那只猫),但模型会输出来5个预测结果,那么这五个结果中有猫这个分类的概率成为Top-5正确率,相反,预测输出的这五个结果里没有猫这个分类的概率则成为Top-5错误率。
采用的数据集
作者采用了ImageNet LSVRC-2010年竞赛数据集。ImageNet 数据集包含超过1500万张已标记高分辨率图像的数据集,大约属于22,000个类别。ILSVRC使用ImageNet的一个子集,每1000个类别中大约有1000张图片。总共大约有120万张训练图像,50,000张验证图像和150,000张测试图像。ILSVRC-2010是ILSVRC中唯一可用测试集标签的版本。
AlexNet 的网络结构

包含八个学习层:五个卷积神经网络和三个全连接网络,并且使用了最大池化。
输入层:输入图像大小224x224x3,卷积核11x11x3x48x2(在两块GPU上)
第二层:卷积核5x5x48x128x2,步长为1, ReLU->LRN->maxpool
第三层:卷积核3x3x128x192x2,步长为1,ReLU
第四层:卷积核3x3x192x192x2,步长为1,ReLU
第五层:卷积核3x3x192x128x2,步长为1,
ReLU->max pool
第六层:全连接层4096x4096
第七层:全连接层4096x4096
第八层:softmax全连接层4096x1000
在全连接层上使用了Dropout 和 Relu
这篇论文用到的方法
Rectified Linear Unit(ReLU)
使用Rectified Linear Unit(ReLU)作为所有卷积层和全连接层的激活函数,提高训练速度,在大型数据集和大模型中更为重要的是更快的训练速度。使用 ReLU 的深度卷积神经网络的训练速度比使用 tanh units 的等价网络快几倍。
多GPU训练
使用了两块GTX580 3GB的GPU来训练,首先是一块GPU 3GB的显存不够,且使用两块GPU联合训练可以不通过CPU集中调度,提高效率。同时CPU可以对输入图像进行增强处理。
Local Response Normalization 算法
作者提到,尽管RELU激活函数的使用,可以在加快训练速度的同时,取得比饱和非线性映射更好的效果,但是作者在采用了局部归一化技术后,泛化性得到了提高。
为什么在这里采用LRN:
在神经网络中,我们用激活函数将神经元的输出做一个非线性映射,但是tanh和sigmoid这些传统的激活函数的值域都是有范围的,但是ReLU激活函数得到的值域没有一个区间,所以要对ReLU得到的结果进行归一化。也就是Local Response Normalization。
关于泛化性的解释:
泛化能力
- 泛化能力指算法模型对未知数据的预测能力。
- 学习的目的是学到隐含在数据背后的规律,对具有同一规律的学习集以外的数据经过训练的网络也能给出合适的输出,该能力称为泛化能力。
两种数据增强的方法
- 通过对数据的进行尺度放缩和随机裁剪和翻转提高数据量,有效的对抗overfit的方法
具体来讲是对 256x256 的图片,随机抽取了 224*224 的图像用于训练,在测试阶段作者通过取一个样本中的四个角以及中间区域,并将得到的这 5 个进行水平翻转,以此得到10个样本,扩充数据集,以此加大数据集抑制过拟合。
- 对RGB通道进行加权造成颜色偏移,并对图像加噪,使得模型对颜色和明暗变化的鲁棒性强这个方案近似地捕捉原始图像的一些重要属性,对象的身份不受光照的强度和颜色变化影响。这个方案将top-1错误率降低了1%以上。
(这两种图像增强方法都在后面的研究中改进并广泛使用)
Dropout 方法
dropout 对于过拟合有着较好的抑制作用
将每个隐藏层的神经元以50%的概率进行随机置零;这些被随机置零的神经元并不在前向传播中产生作用,也不参与反向传播。使得每次的输入,神经网络都会对不同的体系结构进行采样,但是这些结构是分享权重的;减小了神经元之间复杂的协同适应能力。
作者在前两个全连接层上使用的dropout,并指出,若没有dropout,网络会出现严重的过拟合。但付出了两倍的收敛时间。
与一般池化不同的重叠池化(Overlapping Pooling)
池化过程在一般卷积过程后。池化(pooling) 的本质,其实就是采样。Pooling 对于输入的 Feature Map,选择某种方式对其进行降维压缩,以加快运算速度。
论文中采用的池化算法也是常用的最大池化算法(Max Pooling),但与传统池化不同的是,传统池化相邻池化单元之间互不重叠,重叠池化使相邻池化单元之间出现重叠。采用重叠池化后,该方案将 top-1 和 top-5 错误率分别降低了 0.4% 和 0.3%。
优点以及不足、改进点
优点:
- 激活函数使用 Relu,提升训练速度; Dropout 防止过拟合,提升鲁棒性。
- 由五层卷积、三层全连接组成,输入图像尺寸为 224 * 224 * 3,网络规模在当时来说远大于其他网络模型。
- AlexNet 的出现刺激了沉寂多年的深度学习领域。
- 增加了一些训练上的技巧,包括数据增强、学习率衰减、权重衰减( L2 正则化)等。
改进点:(理解有限,还无法看出缺点以及改进点。)
为什么选这篇论文
因为在入门学习机器学习方面,期初看的是另一篇论文:
Zeiler M D, Fergus R. Visualizing and understanding convolutional networks[C]//European conference on computer vision. Springer, Cham, 2014: 818-833.
看到文中多次提到且引用AlexNet这篇论文,同时那篇论文读上也很晦涩,故暂时停下,找来这篇经典论文阅读。
参考资料
深入理解AlexNet网络