深度学习初探——yolov3经典目标检测算法
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
目录
前言
一、yolov3的网络结构
二、利用Darknet-53进行特征提取
1.残差网络
2.代码实现
三、利用FPN特征金字塔进行特征增强和预测输出
1.利用FPN特征金字塔进行特征增强
1.1.代码实现
2.预测输出
总结
前言
最近刚刚接触深度学习,并且简单学习了yolov3经典目标检测算法,在这里写一写自己的感悟,其中借鉴了很多大佬的博客,有错误的地方希望大家能够帮忙指出。
一、yolov3的网络结构
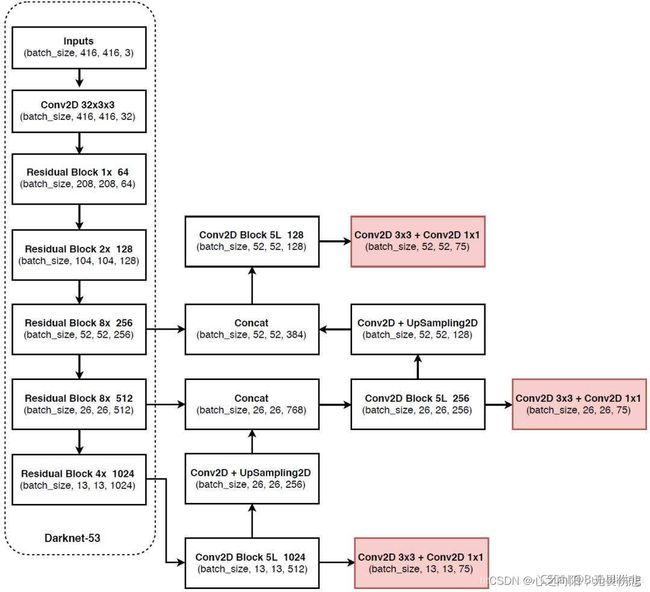
其网络结构主要分为两部分,一部分是利用Darknet-53进行特征提取,另外一部分是利用FPN特征金字塔加强特征提取,然后进行预测输出。
二、利用Darknet-53进行特征提取
上图yolov3的网络结构的左边部分就是Darknet-53。Darknet-53是一个卷积神经网络用于特征提取,其中大量的利用的残差网络Resnet来加深层数从而提高模型的准确程度。
首先输入一个416*416*3的图片,经过3*3的卷积(步长为1)后,得到了416*416*32(增加了通道数)结果,然后经过5个残差块,每个残差块都会首先进行下采样之后,再加入残差网络进行堆叠,加深网络深度,Darknet-53中5个残差块的堆叠次数分别为【1,2,8,8,4】,然后在完成经过第3,4,5次残差块后分别输出52*52*256,26*26*512,13*13*1024大小的特征,该三个大小的特征用于后面的FPN特征金字塔加强提取,预测输出。
1.残差网络
大家都了解,越深层的网络,参数越多,所映射的模型种类越多,也就意味着层数越深,我们训练出来的模型可能就越准确。但是实际过程中,过于深的网络层数可能会导致退化问题,可能会造成关键特征丢失。
残差网络的主要作用在于残差网络应用在深层神经网络中避免了过深层数导致的退化问题,减小了训练损失,下面简单讲一下残差网络是如何能够避免退化问题的。
残差网络与经典的卷积网络不同之处在于,他从输入引出一个分支与输出结果相加,那么其实在训练和卷积的过程中,其实我们训练的是F(X)=f(x)-x这一种映射,并且加上x后就变为f(x)了。

首先我们来看为什么这种残差映射可以避免网络退化问题,我们的输入为x,因为我们在训练过程中不可避免的会产生特征丢失问题,如果我们单纯训练f(x)并且当f(x)训练不准确时,那么x经过f(x)就很有可能会造成关键信息的丢失。但是如果经过F(X)=f(x)-x这一种映射,即使F(x)中存在信息丢失,但是f(x)=F(x)+x,x中仍然存在着关键信息的保留,所以残差网络可以有效的避免深层网络的退化问题。

上图中为什么残差网络中的x有时候还会经过1*1的卷积层,该卷积层的作用主要是改变通道数用于与F(x)的结果进行相加。
2.代码实现
下面我们来简单的看一下Darknet-53的特征提取网络是如何进行代码实现的 。
import math
from collections import OrderedDict
import torch.nn as nn
#---------------------------------------------------------------------#
# 残差结构
# 利用一个1x1卷积下降通道数,然后利用一个3x3卷积提取特征并且上升通道数
# 最后接上一个残差边
#---------------------------------------------------------------------#
class BasicBlock(nn.Module):
def __init__(self, inplanes, planes):
super(BasicBlock, self).__init__()
self.conv1 = nn.Conv2d(inplanes, planes[0], kernel_size=1, stride=1, padding=0, bias=False)
self.bn1 = nn.BatchNorm2d(planes[0])
self.relu1 = nn.LeakyReLU(0.1)
self.conv2 = nn.Conv2d(planes[0], planes[1], kernel_size=3, stride=1, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(planes[1])
self.relu2 = nn.LeakyReLU(0.1)
def forward(self, x):
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu1(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu2(out)
out += residual
return out
class DarkNet(nn.Module):
def __init__(self, layers):
super(DarkNet, self).__init__()
self.inplanes = 32
# 416,416,3 -> 416,416,32
self.conv1 = nn.Conv2d(3, self.inplanes, kernel_size=3, stride=1, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(self.inplanes)
self.relu1 = nn.LeakyReLU(0.1)
# 416,416,32 -> 208,208,64
self.layer1 = self._make_layer([32, 64], layers[0])
# 208,208,64 -> 104,104,128
self.layer2 = self._make_layer([64, 128], layers[1])
# 104,104,128 -> 52,52,256
self.layer3 = self._make_layer([128, 256], layers[2])
# 52,52,256 -> 26,26,512
self.layer4 = self._make_layer([256, 512], layers[3])
# 26,26,512 -> 13,13,1024
self.layer5 = self._make_layer([512, 1024], layers[4])
self.layers_out_filters = [64, 128, 256, 512, 1024]
# 进行权值初始化
for m in self.modules():
if isinstance(m, nn.Conv2d):
n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
m.weight.data.normal_(0, math.sqrt(2. / n))
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(1)
m.bias.data.zero_()
#---------------------------------------------------------------------#
# 在每一个layer里面,首先利用一个步长为2的3x3卷积进行下采样
# 然后进行残差结构的堆叠
#---------------------------------------------------------------------#
def _make_layer(self, planes, blocks):
layers = []
# 下采样,步长为2,卷积核大小为3
layers.append(("ds_conv", nn.Conv2d(self.inplanes, planes[1], kernel_size=3, stride=2, padding=1, bias=False)))
layers.append(("ds_bn", nn.BatchNorm2d(planes[1])))
layers.append(("ds_relu", nn.LeakyReLU(0.1)))
# 加入残差结构
self.inplanes = planes[1]
for i in range(0, blocks):
layers.append(("residual_{}".format(i), BasicBlock(self.inplanes, planes)))
return nn.Sequential(OrderedDict(layers))
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu1(x)
x = self.layer1(x)
x = self.layer2(x)
out3 = self.layer3(x)
out4 = self.layer4(out3)
out5 = self.layer5(out4)
return out3, out4, out5
def darknet53():
model = DarkNet([1, 2, 8, 8, 4])
return model代码首先 建立了一个BasicBlock的类,也就是一个残差块的类,方便后面进行重复利用,残差块的类主要实现的功能就是先后经过1*1和3*3的卷积,并把其结果加上输入,作为输出返回。
class BasicBlock(nn.Module):
def __init__(self, inplanes, planes):
super(BasicBlock, self).__init__()
self.conv1 = nn.Conv2d(inplanes, planes[0], kernel_size=1, stride=1, padding=0, bias=False)
self.bn1 = nn.BatchNorm2d(planes[0])
self.relu1 = nn.LeakyReLU(0.1)
self.conv2 = nn.Conv2d(planes[0], planes[1], kernel_size=3, stride=1, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(planes[1])
self.relu2 = nn.LeakyReLU(0.1)
def forward(self, x):
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu1(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu2(out)
out += residual
return out然后定义一个函数,利用上面的BasicBlock的类,实现每一个残差块的功能,首先进行下采样,3*3的卷积(步长为2),然后进行残差网络的堆叠,堆叠的层数由输入决定。
def _make_layer(self, planes, blocks):
layers = []
# 下采样,步长为2,卷积核大小为3
layers.append(("ds_conv", nn.Conv2d(self.inplanes, planes[1], kernel_size=3, stride=2, padding=1, bias=False)))
layers.append(("ds_bn", nn.BatchNorm2d(planes[1])))
layers.append(("ds_relu", nn.LeakyReLU(0.1)))
# 加入残差结构
self.inplanes = planes[1]
for i in range(0, blocks):
layers.append(("residual_{}".format(i), BasicBlock(self.inplanes, planes)))
return nn.Sequential(OrderedDict(layers))然后通过下面的代码传入参数,并且返回经过第3,4,5个 残差块后的结果,用于后面的特征加强和预测输出。
class DarkNet(nn.Module):
def __init__(self, layers):
super(DarkNet, self).__init__()
self.inplanes = 32
# 416,416,3 -> 416,416,32
self.conv1 = nn.Conv2d(3, self.inplanes, kernel_size=3, stride=1, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(self.inplanes)
self.relu1 = nn.LeakyReLU(0.1)
# 416,416,32 -> 208,208,64
self.layer1 = self._make_layer([32, 64], layers[0])
# 208,208,64 -> 104,104,128
self.layer2 = self._make_layer([64, 128], layers[1])
# 104,104,128 -> 52,52,256
self.layer3 = self._make_layer([128, 256], layers[2])
# 52,52,256 -> 26,26,512
self.layer4 = self._make_layer([256, 512], layers[3])
# 26,26,512 -> 13,13,1024
self.layer5 = self._make_layer([512, 1024], layers[4])
self.layers_out_filters = [64, 128, 256, 512, 1024]
# 进行权值初始化
for m in self.modules():
if isinstance(m, nn.Conv2d):
n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
m.weight.data.normal_(0, math.sqrt(2. / n))
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(1)
m.bias.data.zero_()
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu1(x)
x = self.layer1(x)
x = self.layer2(x)
out3 = self.layer3(x)
out4 = self.layer4(out3)
out5 = self.layer5(out4)
return out3, out4, out5三、利用FPN特征金字塔进行特征增强和预测输出
1.利用FPN特征金字塔进行特征增强
yolov3主要利用三个特征层进行目标检测,13*13*1024,26*26*512,52*52*256,这三个特征层, 以13*13*1024为例,其有两个去向,一个去向是进行5次卷积操作(卷积核大小为1,3,1,3,1)输出为13*13*512,然后进行卷积和上采样变为26*26*256的图像与上一层特征中的26*26*512进行特征叠加叠加形成26*26*768,另外一个去向是进行7次卷积操作(卷积核大小为1,3,1,3,1,3,1)前五次操作为特征提取,后面五次操作为生成预测结果,得到13*13*75。其中75可以拆分为3*(20+4+1),3为三个先验框,20为数据集中预测物体的种类数,4为先验框调整参数(中心点位置和宽高),最后一个参数是否包含物体。
然后26*26*512,52*52*256,也经过类似的操作后就可以对特征进行增强了。首先13*13的图像感受野比较大,适合预测大物体,26*26,52*52的适合于预测中小物体。
1.1.代码实现
from collections import OrderedDict
import torch
import torch.nn as nn
from nets.darknet import darknet53
def conv2d(filter_in, filter_out, kernel_size):
pad = (kernel_size - 1) // 2 if kernel_size else 0
return nn.Sequential(OrderedDict([
("conv", nn.Conv2d(filter_in, filter_out, kernel_size=kernel_size, stride=1, padding=pad, bias=False)),
("bn", nn.BatchNorm2d(filter_out)),
("relu", nn.LeakyReLU(0.1)),
]))
#------------------------------------------------------------------------#
# make_last_layers里面一共有七个卷积,前五个用于提取特征。
# 后两个用于获得yolo网络的预测结果
#------------------------------------------------------------------------#
def make_last_layers(filters_list, in_filters, out_filter):
m = nn.Sequential(
conv2d(in_filters, filters_list[0], 1),
conv2d(filters_list[0], filters_list[1], 3),
conv2d(filters_list[1], filters_list[0], 1),
conv2d(filters_list[0], filters_list[1], 3),
conv2d(filters_list[1], filters_list[0], 1),
conv2d(filters_list[0], filters_list[1], 3),
nn.Conv2d(filters_list[1], out_filter, kernel_size=1, stride=1, padding=0, bias=True)
)
return m
class YoloBody(nn.Module):
def __init__(self, anchors_mask, num_classes, pretrained = False):
super(YoloBody, self).__init__()
#---------------------------------------------------#
# 生成darknet53的主干模型
# 获得三个有效特征层,他们的shape分别是:
# 52,52,256
# 26,26,512
# 13,13,1024
#---------------------------------------------------#
self.backbone = darknet53()
if pretrained:
self.backbone.load_state_dict(torch.load("model_data/darknet53_backbone_weights.pth"))
#---------------------------------------------------#
# out_filters : [64, 128, 256, 512, 1024]
#---------------------------------------------------#
out_filters = self.backbone.layers_out_filters
#------------------------------------------------------------------------#
# 计算yolo_head的输出通道数,对于voc数据集而言
# final_out_filter0 = final_out_filter1 = final_out_filter2 = 75
#------------------------------------------------------------------------#
self.last_layer0 = make_last_layers([512, 1024], out_filters[-1], len(anchors_mask[0]) * (num_classes + 5))
self.last_layer1_conv = conv2d(512, 256, 1)
self.last_layer1_upsample = nn.Upsample(scale_factor=2, mode='nearest')
self.last_layer1 = make_last_layers([256, 512], out_filters[-2] + 256, len(anchors_mask[1]) * (num_classes + 5))
self.last_layer2_conv = conv2d(256, 128, 1)
self.last_layer2_upsample = nn.Upsample(scale_factor=2, mode='nearest')
self.last_layer2 = make_last_layers([128, 256], out_filters[-3] + 128, len(anchors_mask[2]) * (num_classes + 5))
def forward(self, x):
#---------------------------------------------------#
# 获得三个有效特征层,他们的shape分别是:
# 52,52,256;26,26,512;13,13,1024
#---------------------------------------------------#
x2, x1, x0 = self.backbone(x)
#---------------------------------------------------#
# 第一个特征层
# out0 = (batch_size,255,13,13)
#---------------------------------------------------#
# 13,13,1024 -> 13,13,512 -> 13,13,1024 -> 13,13,512 -> 13,13,1024 -> 13,13,512
out0_branch = self.last_layer0[:5](x0)
out0 = self.last_layer0[5:](out0_branch)
# 13,13,512 -> 13,13,256 -> 26,26,256
x1_in = self.last_layer1_conv(out0_branch)
x1_in = self.last_layer1_upsample(x1_in)
# 26,26,256 + 26,26,512 -> 26,26,768
x1_in = torch.cat([x1_in, x1], 1)
#---------------------------------------------------#
# 第二个特征层
# out1 = (batch_size,255,26,26)
#---------------------------------------------------#
# 26,26,768 -> 26,26,256 -> 26,26,512 -> 26,26,256 -> 26,26,512 -> 26,26,256
out1_branch = self.last_layer1[:5](x1_in)
out1 = self.last_layer1[5:](out1_branch)
# 26,26,256 -> 26,26,128 -> 52,52,128
x2_in = self.last_layer2_conv(out1_branch)
x2_in = self.last_layer2_upsample(x2_in)
# 52,52,128 + 52,52,256 -> 52,52,384
x2_in = torch.cat([x2_in, x2], 1)
#---------------------------------------------------#
# 第一个特征层
# out3 = (batch_size,255,52,52)
#---------------------------------------------------#
# 52,52,384 -> 52,52,128 -> 52,52,256 -> 52,52,128 -> 52,52,256 -> 52,52,128
out2 = self.last_layer2(x2_in)
return out0, out1, out22.预测输出
那么在实际过程中,yolov3是如何对预测框进行训练和输出的呢?我们以13*13*75为例来进行一下探讨。13*13*75可以改写为13*13*3*(20+4+1) ,其中3是先验框的数量。我们对图像中的每一个像素点都会先画出三个不同大小的先验框,用于训练,由于我们在训练过程中存在我们已经标注好的真实框,这时候我们就判断真实框和这个特征点的哪个先验框重合程度最高。计算该网格点应该有怎么样的预测结果才能获得真实框,与真实框重合度最高的先验框被用于作为正样本。然后重合度低于一定阈值的会作为负样本,属于中间部分的先验框样本会进行舍弃。其原因为中间样本的重合度仍然较高,如果作为负样本出现会影响模型的拟合。
最终损失由三个部分组成:a、正样本,编码后的长宽与xy轴偏移量与预测值的差距。b、正样本,预测结果中置信度的值与1对比;负样本,预测结果中置信度的值与0对比。c、实际存在的框,种类预测结果与实际结果的对比。
由于代码长度较长,此处暂不粘贴,然后对于预测框分析大家可以参考博客如下
史上最详细的Yolov3边框预测分析_逍遥王可爱的博客-CSDN博客_yolov3 预测框
总结
本文是在借鉴了诸多大佬们的博客后学习所得,是对yolov3的简单回顾和归纳,其中可能存在些许理解错误,错误之处请大家伙们指出,参考博客如下
睿智的目标检测26——Pytorch搭建yolo3目标检测平台_Bubbliiiing的博客-CSDN博客_睿智的目标检测26
史上最详细的Yolov3边框预测分析_逍遥王可爱的博客-CSDN博客_yolov3 预测框
Yolov3边框预测分析_lcczzu的博客-CSDN博客
Pytorch机器学习(九)—— YOLO中对于锚框,预测框,产生候选区域及对候选区域进行标注详解_lzzzzzzm的博客-CSDN博客_yolo锚框