pytorch报错解决方案
一.module not found error: no module named ‘cv2.cv2’
考虑:python与opencv-python的包的版本匹配问题,
pip install opencv-python == 4.4.0.46
二. 把anaconda从C盘移动到E盘
win10 将Anaconda3 从C盘移动到E盘
背景
步骤1:移动文件夹
步骤2:修改环境变量
步骤3:解决app打不开
参考:https://blog.csdn.net/weixin_43499292/article/details/115404131?utm_medium=distribute.pc_relevant.none-task-blog-baidujs_title-1&spm=1001.2101.3001.4242
三.Python常见错误:ValueError: If using all scalar values, you must pass an index(四种解决方案)
1、错误发生场景:
import pandas as pd
dict = {'a':1,'b':2,'c':3}
data = pd.DataFrame(dict)
2、错误原因:
直接传入标称属性为value的字典需要写入index,也就是说,需要在创建DataFrame对象时设定index。
3、解决方案:
通过字典来创建DataFrame对象是很常见的需求,但是针对不同的对象形式,可能会有不同的写法。看代码,以下这四种方法都是可以修正这个错误,而且产生相同的正确结果,具体使用哪种方法根据自己的需求来选择就好。
import pandas as pd
#方法一:直接在创建DataFrame时设置index即可
dict = {'a':1,'b':2,'c':3}
data = pd.DataFrame(dict,index=[0])
print(data)
#方法二:通过from_dict函数将value为标称变量的字典转换为DataFrame对象
dict = {'a':1,'b':2,'c':3}
pd.DataFrame.from_dict(dict,orient='index').T
print(data)
#方法三:输入字典时不要让Value为标称属性,把Value转换为list对象再传入即可
dict = {'a':[1],'b':[2],'c':[3]}
data = pd.DataFrame(dict)
print(data)
#方法四:直接将key和value取出来,都转换成list对象
dict = {'a':1,'b':2,'c':3}
pd.DataFrame(list(dict.items()))
print(data)
四、仍然使用with open,但是mode参数为a,则当文件不存在时会自动创建,不会报错。
with open("test.txt",mode='a',encoding='utf-8') as ff:
print(ff.readlines())
#python中 open的model = ‘a’ 可以在文件不存在的时候自动创建
参考:https://blog.csdn.net/Fantasy_Virgo/article/details/82315727
五:当安装新的python包导致,之前的程序无法运行或者报错:
ModuleNotFoundError: No module named ‘pandas.compat.numpy’ 等
需要卸载pandas
pip3 uninstall pandas
pip3 install pandas
六:Python错误:TypeError: ‘list’ object is not callable
由于变量list和函数list重名了,所以函数在使用list函数时,发现list是一个定义好的列表,而列表是不能被调用的,因此抛出一个类型错误
solu:修改变量名为list的
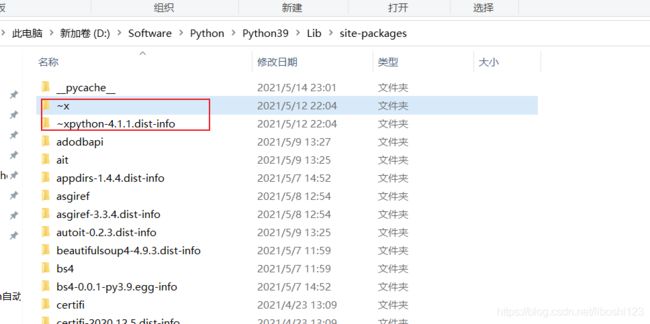
七:WARNING: Ignoring invalid distribution -andas (e:\anaconda3\envs\pytorch\lib\site-packages)
最近在使用pip3 安装插件的时候,出现上面的警告信息
solu:
找到警告信息中报错的目录,然后删掉~开头的文件夹,那种事之前安装插件失败/中途退出,导致插件安装出现异常导致的,虽说警告信息不影响,但是有强迫症 哈哈 。把文件夹删掉就好了 :
待学习的内容:
Yaml:
https://www.bilibili.com/video/BV1Di4y1L76e?p=4
https://www.runoob.com/w3cnote/yaml-intro.html