DETR:基于Transformer的端到端目标检测方法

原文:Carion N, Massa F, Synnaeve G, et al. End-to-end object detection with transformers[C]//European conference on computer vision. Springer, Cham, 2020: 213-229.
源码:https://github.com/facebookresearch/detr
本文提出了一种新的方法,将目标检测视为直接集合预测问题。我们的方法简化了检测流程,有效地消除了对许多手工设计组件的依赖,例如非极大抑制(NMS)或锚框(Anchor)生成,这些组件依赖于人类的先验知识。我们的新框架的主要组成部分是Detection Transformer,简称DETR,这是一种基于Transformer和直接集合预测二分图匹配损失的编码器-解码器架构。DETR基于一组可学习的Object Query,就能推理目标和图像全局上下文之间的关系,直接并行输出最终的预测集。DETR的理念很简单,不需要专门的库,这一点与其他检测器有所不同。DETR在COCO上的性能与高度优化过的Faster R-CNN基线相当。此外,DETR还能轻松扩展到全景分割任务上,并且显著优于基线模型。
1.论文故事
目标检测旨在为每个感兴趣的物体预测一组边框和类别标签。现代检测器通过在大量proposals、anchors、window centers上定义替代回归和分类问题,以间接的方式来处理这一集合预测问题。但是它们的性能受到后处理步骤、anchor设计、启发式算法的显著影响。为了简化流程,我们提出了一种直接集合预测方法来绕过这些代理任务。这种端到端的思想在复杂的结构化预测任务(如机器翻译或语音识别)方面已经取得了重大进展,但在目标检测方面还没有取得进展。之前的尝试要么添加了其他形式的先验知识,要么在挑战性的基准上面比不过基线模型。本文旨在弥合这一差距。
我们通过将目标检测视为一个集合预测问题而简化了训练流程。我们采用了一种基于Transformer的编码器-解码器架构,这是一种流行的序列预测架构。Transformer的自注意力机制可以对序列元素之间的成对交互进行显式地建模,因而特别适用于集合预测的特定约束,例如消除重复预测。
DETR能够一次性对所有物体进行预测,并通过一组损失函数进行端到端的训练,该损失函数可以在预测物体和真实物体之间进行二分图匹配。DETR通过丢弃多个手工设计的编码先验知识的组件(如空间anchor或非极大值抑制)简化了检测流程。与现有的大多数检测方法不同,DETR不需要任何自定义层,因此可以在任何包含标准CNN和Transformer的框架中轻松地复现。
与之前直接预测集合的工作相比,DETR的主要特点是二分图匹配损失与并行非自回归解码的Transformer的结合。相比之下,之前的工作侧重于RNN的自回归解码。匹配损失函数可以为每个物体指定一个预测框,并且对预测物体的排列是不变的,因此我们可以并行地出框。
我们在COCO数据集上对DETR进行了评估,并与Faster R-CNN基线进行了比较。Faster R-CNN自从发布以来经过多次设计迭代,其性能已经有了很大的提高。我们的实验结果表明,DETR取得了具有竞争力的结果。更准确地说,DETR在大物体检测上的性能明显更好,这可能是由Transformer的非局部计算实现的。但是,DETR在小物体检测上的性能较低。我们预计,未来的工作将改善这一方面,就像FPN为Faster R-CNN所做的那样。
DETR的训练设置在许多方面不同于标准的目标检测器,新模型的训练需要较长的时间。我们深入研究了哪些组件对模型性能是至关重要的。DETR的设计理念很容易扩展到更复杂的任务上。我们的实验结果表明,基于DETR训练的分割器可以在全景分割任务上超越基线。
2.模型方法
DETR的训练阶段主要分为三步:第一,使用卷积神经网络(CNN)抽取图像特征。第二,将图像特征输入Transformer的编码器-解码器架构,编码器主要学习图像的全局信息,解码器通过对图像特征和Object Query进行自注意力操作来生成预测框。第三,通过二分图匹配损失将预测框和真实框匹配起来,再利用前馈网络(FFN)计算分类损失和边框损失。
DETR的推理阶段也分为三步:第一,使用CNN抽取图像特征。第二,将图像特征输入Transformer的编码器-解码器架构,生成一系列预测框。第三,保留置信度高于阈值的预测框作为最终输出。
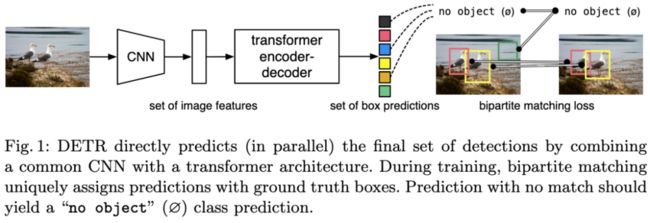
图1:DETR通过结合普通CNN和Transformer架构,直接(并行)预测最终的检测框集合。在训练过程中,二分图匹配使真实框和预测框进行一对一匹配。没有匹配的预测框归到“没有物体(∅)”的类别。
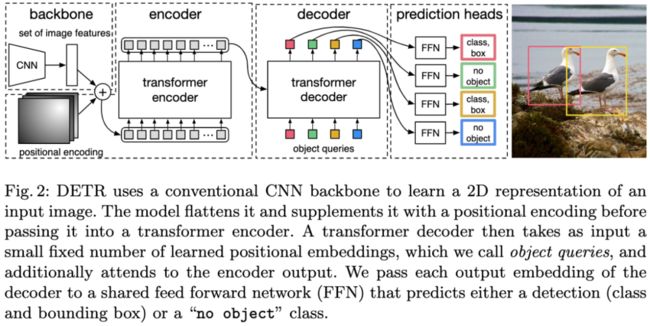
图2:DETR使用传统的CNN骨干网络来学习输入图像的二维表示。
3.实验结果
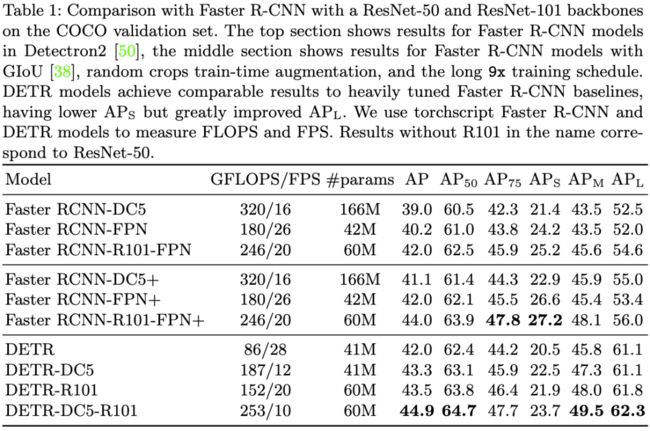
表1:DETR与Faster R-CNN在COCO验证集上的结果比较。
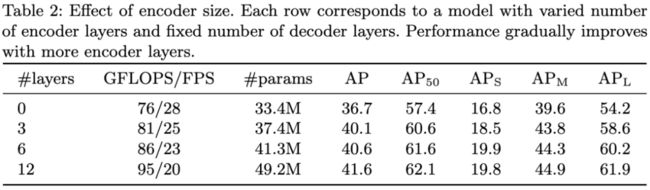
表2:编码器大小对模型性能的影响。每行对应一个模型,该模型具有不同数量的编码器层和固定数量的解码器层。随着编码器层数的增加,模型性能逐渐提高。

图3:编码器对一组参考点的自注意力热图。编码器能够分离单独的实例。
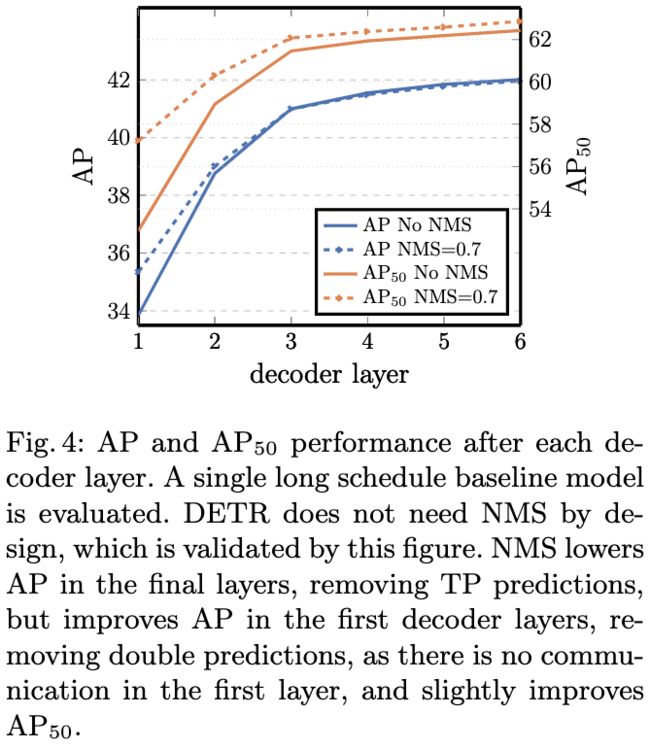
图4:每个解码器层后的AP和AP50值。如图所示,DETR不需要非极大值抑制(NMS)。

图5:稀有种类的分布外泛化。
图6:对每个预测物体的解码器注意力进行可视化。对于不同的物体,注意力分值用不同的颜色进行编码。解码器通常关注物体的肢体,例如腿部和头部。
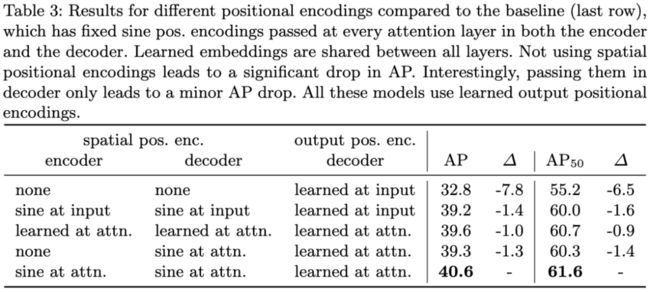
表3:不同位置编码方法的结果比较。基线(最后一行)在编码器和解码器的每个注意力层之间都传递固定的正弦位置编码。学习到的嵌入在所有层之间共享。不使用空间位置编码会导致AP值显著下降。
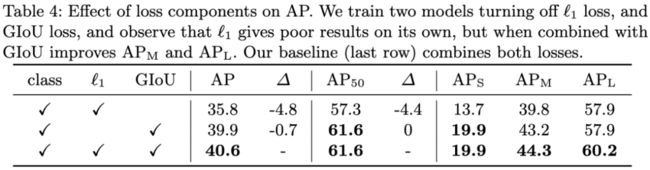
表4:损失函数对AP值的影响。基线(最后一行)综合了L1损失和GIoU损失。

图7:DETR解码器中Object Query的可视化结果。Object Query是从COCO数据集中学出来的,共有100个,这里只展示了20个。绿点表示小边框,红点表示大的水平框,蓝点表示大的垂直框。
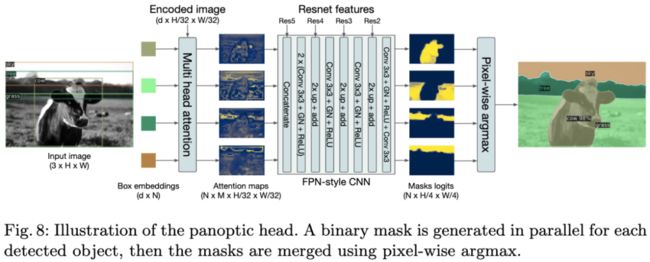
图8:全景分割头的示意图。首先为每个检测到的物体并行生成二进制掩码,然后使用pixel-wise argmax合并掩码。
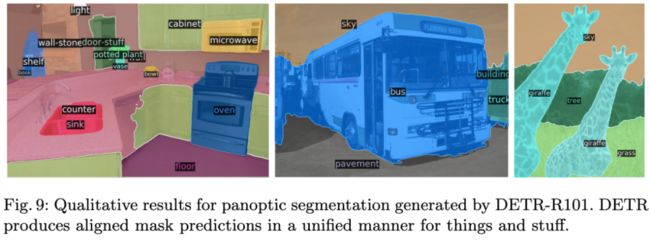
图9:DETR-R101生成的全景分割结果。
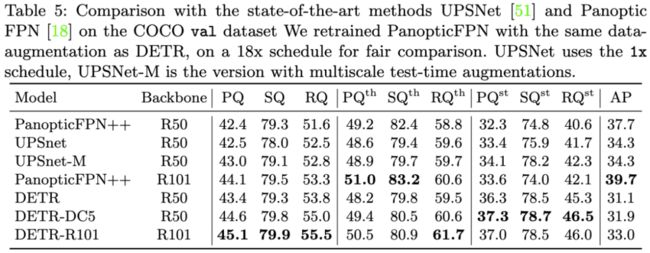
表5:DETR与UPSNet、PanopticFPN全景分割结果的比较。
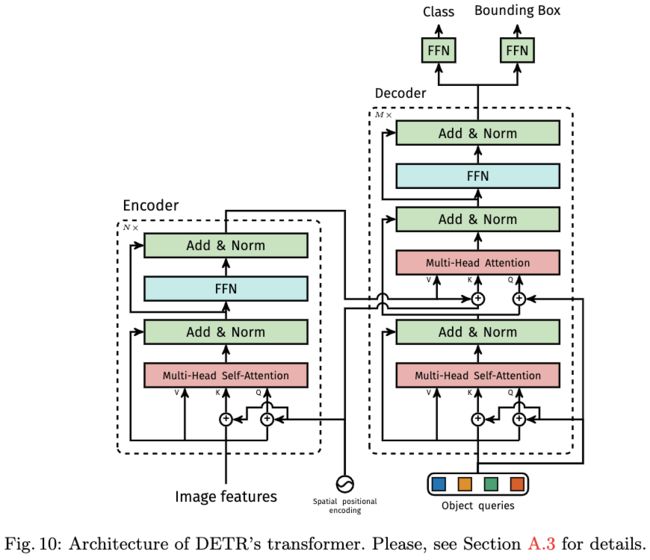
图10:DETR Transformer的架构。
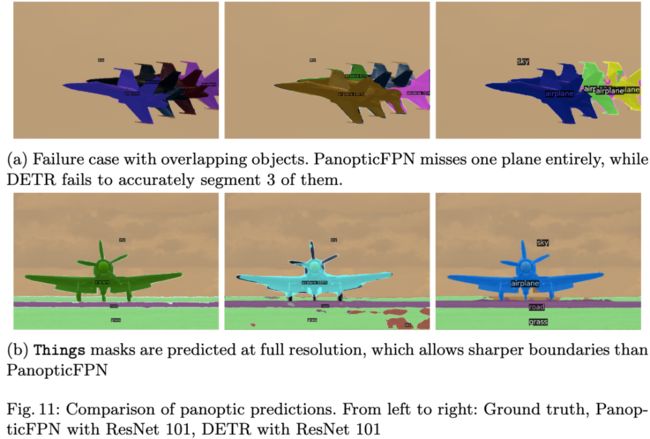
图11:全景分割结果的比较。左:真实情况。中:PanopticFPN+ResNet 101的结果。右:DETR+ResNet 101的结果。
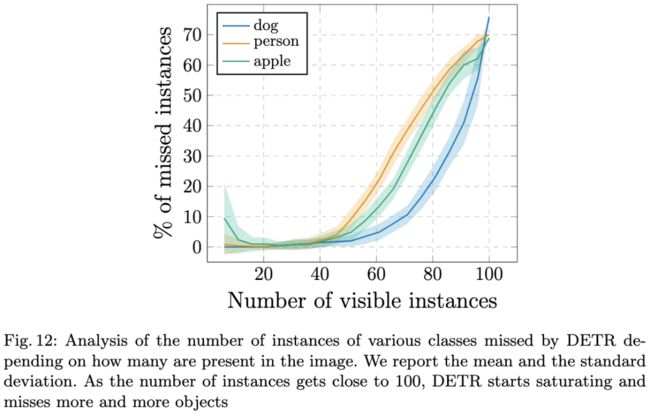
图12:根据图像中的实例数量,分析DETR遗漏的各种类别的实例数量。当实例数量接近100时,DETR开始饱和并丢失越来越多的物体。

DETR的PyTorch代码。为了清晰起见,它在编码器中使用学习到的位置编码,而不是固定的,并且位置编码仅添加到输入中,而不是每个Transformer层。详细情况参见:https://github.com/facebookresearch/detr。
4.总结讨论
我们提出了DETR,这是一种基于Transformer和直接集合预测二分图匹配损失的目标检测系统。该方法在COCO数据集上实现了与Faster R-CNN基线相当的结果。DETR易于实现,具有灵活的架构,可以轻松扩展到全景分割任务上,并且取得了具有竞争力的结果。此外,与Faster R-CNN相比,DETR在大物体上的性能明显更好,这可能要归功于自注意力对全局信息的处理。这种新的架构也带来了新的挑战,特别是在小物体的检测方面。目前的检测器经过几年的改进才能应对类似问题,我们预计未来的工作将成功解决DETR的问题。
多模态人工智能
为人类文明进步而努力奋斗^_^↑
欢迎关注“多模态人工智能”公众号^_^↑