特征工程系列:数据清洗
特征工程系列:数据清洗
本文为数据茶水间群友原创,经授权在本公众号发表。
关于作者:JunLiang,一个热爱挖掘的数据从业者,勤学好问、动手达人,期待与大家一起交流探讨机器学习相关内容~
0x00 前言
数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限而已。由此可见,特征工程在机器学习中占有相当重要的地位。在实际应用当中,可以说特征工程是机器学习成功的关键。
那特征工程是什么?
特征工程是利用数据领域的相关知识来创建能够使机器学习算法达到最佳性能的特征的过程。
特征工程又包含了Data PreProcessing(数据预处理)、Feature Extraction(特征提取)、Feature Selection(特征选择)和Feature construction(特征构造)等子问题,本章内容主要讨论数据预处理的方法及实现。
特征工程是机器学习中最重要的起始步骤,数据预处理是特征工程的最重要的起始步骤,而数据清洗是数据预处理的重要组成部分,会直接影响机器学习的效果。
0x01 数据清洗介绍
数据清洗(Data cleaning)– 对数据进行重新审查和校验的过程,目的在于删除重复信息、纠正存在的错误,并提供数据一致性。
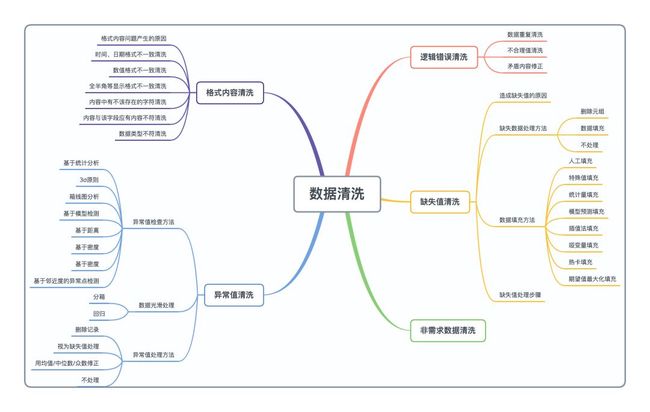
数据清洗, 是整个数据分析过程中不可缺少的一个环节,其结果质量直接关系到模型效果和最终结论。
0x02 格式内容清洗
1.格式内容问题产生的原因
数据是由人工收集或用户填写而来,则有很大可能性在格式和内容上存在一些问题;
不同版本的程序产生的内容或格式不一致;
不同数据源采集而来的数据内容和格式定义不一致。
2.时间、日期格式不一致清洗
根据实际情况,把时间/日期数据库转换成统一的表示方式。
例子:
日期格式不一致:
’2019-07-20’、’20190720’、’2019/07/20’、’20/07/2019’;
时间戳单位不一致,有的用秒表示,有的用毫秒表示;
使用无效时间表示,时间戳使用0表示,结束时间戳使用FFFF表示。
3.数值格式不一致清洗
根据实际情况,把数值转换成统一的表示方式。
例子:1、2.0、3.21E3、四
4.全半角等显示格式不一致清洗
这个问题在人工录入数据时比较容易出现。
5.内容中有不该存在的字符清洗
某些内容可能只包括一部分字符,比如身份证号是数字+字母,中国人姓名是汉字(赵C这种情况还是少数)。最典型的就是头、尾、中间的空格,也可能出现姓名中存在数字符号、身份证号中出现汉字等问题。
这种情况下,需要以半自动校验半人工方式来找出可能存在的问题,并去除不需要的字符。
6.内容与该字段应有内容不符清洗
姓名写了性别,身份证号写了手机号等等,均属这种问题。但该问题特殊性在于:并不能简单的以删除来处理,因为成因有可能是人工填写错误,也有可能是前端没有校验,还有可能是导入数据时部分或全部存在列没有对齐的问题,因此要详细识别问题类型。
7.数据类型不符清洗
由于人为定义错误、转存、加载等原因,数据类型经常会出现数据类型不符的情况。例如:金额特征是字符串类型,实际上应该转换成int/float型。
0x03 逻辑错误清洗
逻辑错误除了以下列举的情况,还有很多未列举的情况,在实际操作中要酌情处理。另外,这一步骤在之后的数据分析建模过程中有可能重复,因为即使问题很简单,也并非所有问题都能够一次找出,我们能做的是使用工具和方法,尽量减少问题出现的可能性,使分析过程更为高效。
1.数据重复清洗
1)存在各个特征值完全相同的两条/多条数据
此时直接删除并只保留其中一条数据。
df.drop_duplicates()2)数据不完全相同,但从业务角度看待数据是同一个数据
如页面埋点时,进入页面和退出页面都会上报一次数据,只有时间不一样,其他字段相同,在统计pv/uv时应该进行去重。
# 根据某个/多个特征值唯一区分每个样本,则可使用该特征/多个特征进行去重。df.drop_duplicates(subset=['ID'], keep='last')2.不合理值清洗
根据业务常识,或者使用但不限于箱型图(Box-plot)发现数据中不合理的特征值。
不合理值的例子:
年龄:
200岁;
个人年收入:
100000万;
籍贯:
汉族。
3.矛盾内容修正
有些字段是可以互相验证的,举例:身份证号是1101031980XXXXXXXX,然后年龄填18岁。在这种时候,需要根据字段的数据来源,来判定哪个字段提供的信息更为可靠,去除或重构不可靠的字段。
0x04 异常值清洗
异常值是数据分布的常态,处于特定分布区域或范围之外的数据通常被定义为异常或噪声。异常分为两种:“伪异常”,由于特定的业务运营动作产生,是正常反应业务的状态,而不是数据本身的异常;“真异常”,不是由于特定的业务运营动作产生,而是数据本身分布异常,即离群点。
1.异常值检查方法
1)基于统计分析
异常检测问题就在统计学领域里得到广泛研究,通常用户用某个统计分布对数据点进行建模,再以假定的模型,根据点的分布来确定是否异常。
如通过分析统计数据的散度情况,即数据变异指标,来对数据的总体特征有更进一步的了解,对数据的分布情况有所了解,进而通过数据变异指标来发现数据中的异常点数据。常用的数据变异指标有极差、四分位数间距、均差、标准差、变异系数等等,变异指标的值大表示变异大、散布广;值小表示离差小,较密集。
譬如最大最小值可以用来判断这个变量的取值是否超过了合理的范围,如客户的年龄为-20岁或200岁,显然是不合常理的,为异常值。
2)3σ原则
若数据存在正态分布,在3σ原则下,异常值为一组测定值中与平均值的偏差超过3倍标准差的值。如果数据服从正态分布,距离平均值3σ之外的值出现的概率为P(|x - μ| > 3σ) <= 0.003,属于极个别的小概率事件。如果数据不服从正态分布,也可以用远离平均值的多少倍标准差来描述。

3)箱线图分析
箱线图提供了识别异常值的一个标准:如果一个值小于QL-1.5IQR或大于OU+1.5IQR的值,则被称为异常值。
* QL为下四分位数,表示全部观察值中有四分之一的数据取值比它小;* QU为上四分位数,表示全部观察值中有四分之一的数据取值比它大;* IQR为四分位数间距,是上四分位数QU与下四分位数QL的差值,包含了全部观察值的一半。箱型图判断异常值的方法以四分位数和四分位距为基础,四分位数具有鲁棒性:25%的数据可以变得任意远并且不会干扰四分位数,所以异常值不能对这个标准施加影响。因此箱型图识别异常值比较客观,在识别异常值时有一定的优越性。

4)基于模型检测
首先建立一个数据模型,异常是那些同模型不能完美拟合的对象;如果模型是簇的集合,则异常是不显著属于任何簇的对象;在使用回归模型时,异常是相对远离预测值的对象。
优点:
有坚实的统计学理论基础,当存在充分的数据和所用的检验类型的知识时,这些检验可能非常有效。
缺点:
对于多元数据,可用的选择少一些,并且对于高维数据,这些检测可能性很差。
5)基于距离
基于距离的方法是基于下面这个假设:即若一个数据对象和大多数点距离都很远,那这个对象就是异常。通过定义对象之间的临近性度量,根据距离判断异常对象是否远离其他对象,主要使用的距离度量方法有绝对距离(曼哈顿距离)、欧氏距离和马氏距离等方法。
优点:
基于距离的方法比基于统计类方法要简单得多;
因为为一个数据集合定义一个距离的度量要比确定数据集合的分布容易的多。
缺点:
基于邻近度的方法需要O(m2)时间,大数据集不适用;
该方法对参数的选择也是敏感的;
不能处理具有不同密度区域的数据集,因为它使用全局阈值,不能考虑这种密度的变化。
6)基于密度
考察当前点周围密度,可以发现局部异常点,离群点的局部密度显著低于大部分近邻点,适用于非均匀的数据集。
优点:
给出了对象是离群点的定量度量,并且即使数据具有不同的区域也能够很好的处理。
缺点:
与基于距离的方法一样,这些方法必然具有O(m2)的时间复杂度。
对于低维数据使用特定的数据结构可以达到O(mlogm);
参数选择困难。
虽然算法通过观察不同的k值,取得最大离群点得分来处理该问题,但是,仍然需要选择这些值的上下界。
7)基于聚类
对象是否被认为是异常点可能依赖于簇的个数(如k很大时的噪声簇)。该问题也没有简单的答案。一种策略是对于不同的簇个数重复该分析。另一种方法是找出大量小簇,其想法是:
较小的簇倾向于更加凝聚;
如果存在大量小簇时一个对象是异常点,则它多半是一个真正的异常点。
不利的一面是一组异常点可能形成小簇而逃避检测。
优点:
基于线性和接近线性复杂度(k均值)的聚类技术来发现离群点可能是高度有效的;
簇的定义通常是离群点的补,因此可能同时发现簇和离群点。
缺点:
产生的离群点集和它们的得分可能非常依赖所用的簇的个数和数据中离群点的存在性;
聚类算法产生的簇的质量对该算法产生的离群点的质量影响非常大。
8)基于邻近度的异常点检测
一个对象是异常的,如果它远离大部分点。这种方法比统计学方法更一般、更容易使用,因为确定数据集的有意义的邻近性度量比确定它的统计分布更容易。一个对象的异常点得分由到它的k-最近邻的距离给定。异常点得分对k的取值高度敏感。如果k太小(例如1),则少量的邻近异常异常点可能导致较异常低的异常点得分;如果K太大,则点数少于k的簇中所有的对象可能都成了异常异常点。为了使该方案对于k的选取更具有鲁棒性,可以使用k个最近邻的平均距离。
优点:
简单。
缺点:
基于邻近度的方法需要O(m2)时间,大数据集不适用;
该方法对参数的选择也是敏感的;
不能处理具有不同密度区域的数据集,因为它使用全局阈值,不能考虑这种密度的变化。
在数据处理阶段将离群点作为影响数据质量的异常点考虑,而不是作为通常所说的异常检测目标点,因而楼主一般采用较为简单直观的方法,结合箱线图和MAD的统计方法判断变量的离群点。
2.数据光滑处理
除了检测出异常值然后再处理异常值外,还可以使用以下方法对异常数据进行光滑处理。
1)分箱
分箱方法通过考察数据的“近邻”(即周围的值)来光滑有序数据的值,有序值分布到一些“桶”或箱中。由于分箱方法考察近邻的值,因此进行局部光滑。
分箱方法:
等高方法:
每个bin中的个数相等;
等宽方法:
每个bin的取值间距相等;
按具体业务场景划分。

一般而言,宽度越大,光滑效果越明显。箱也可以是等宽的,其中每个箱值的区间范围是个常量。分箱也可以作为一种离散化技术使用。
几种分箱光滑技术:
用箱均值光滑:
箱中每一个值被箱中的平均值替换;
用箱中位数平滑:
箱中的每一个值被箱中的中位数替换;
用箱边界平滑:
箱中的最大和最小值同样被视为边界。
箱中的每一个值被最近的边界值替换。
2)回归
可以用一个函数(如回归函数)拟合数据来光滑数据。线性回归涉及找出拟合两个属性(或变量)的“最佳”线,是的一个属性可以用来预测另一个。多元线性回归是线性回归的扩展,其中涉及的属性多于两个,并且数据拟合到一个多维曲面。
3.异常值处理方法
对异常值处理,需要具体情况具体分析,异常值处理的方法常用有四种:
删除含有异常值的记录;
某些筛选出来的异常样本是否真的是不需要的异常特征样本,最好找懂业务的再确认一下,防止我们将正常的样本过滤掉了。
将异常值视为缺失值,交给缺失值处理方法来处理;
使用均值/中位数/众数来修正;
不处理。
0x05 缺失值清洗
没有高质量的数据,就没有高质量的数据挖掘结果,数据值缺失是数据分析中经常遇到的问题之一。
1.造成缺失值的原因
信息暂时无法获取;
如商品售后评价、双十一的退货商品数量和价格等具有滞后效应。
信息被遗漏;
可能是因为输入时认为不重要、忘记填写了或对数据理解错误而遗漏,也可能是由于数据采集设备的故障、存储介质的故障、传输媒体的故障、一些人为因素等原因而丢失。
这个在很多公司恐怕是习以为常的事情。
获取这些信息的代价太大;
如统计某校所有学生每个月的生活费,家庭实际收入等等。
系统实时性能要求较高;
即要求得到这些信息前迅速做出判断或决策。
有些对象的某个或某些属性是不可用的。
如一个未婚者的配偶姓名、一个儿童的固定收入状况等。
2.缺失数据处理方法
1) 删除元组
也就是将存在遗漏信息属性值的对象(元组,记录)删除,从而得到一个完备的信息表。
优点:
简单易行,在对象有多个属性缺失值、被删除的含缺失值的对象与初始数据集的数据量相比非常小的情况下非常有效;
不足:
当缺失数据所占比例较大,特别当遗漏数据非随机分布时,这种方法可能导致数据发生偏离,从而引出错误的结论。
2)数据填充
用一定的值去填充空值,从而使信息表完备化。通常基于统计学原理,根据初始数据集中其余对象取值的分布情况来对一个缺失值进行填充。
数据填充的方法有多种,此处先不展开,下面章节将会详细介绍。
3)不处理
不处理缺失值,直接在包含空值的数据上进行数据挖掘的方法包括XGBoost、贝叶斯网络和人工神经网络等。
补齐处理只是将未知值补以我们的主观估计值,不一定完全符合客观事实,在对不完备信息进行补齐处理的同时,我们或多或少地改变了原始的信息系统。而且,对空值不正确的填充往往将新的噪声引入数据中,使挖掘任务产生错误的结果。因此,在许多情况下,我们还是希望在保持原始信息不发生变化的前提下对信息系统进行处理。
3.数据填充的方法
1)人工填充(filling manually)
根据业务知识来进行人工填充。
2)特殊值填充(Treating Missing Attribute values as Special values)
将空值作为一种特殊的属性值来处理,它不同于其他的任何属性值。如所有的空值都用“unknown”填充。一般作为临时填充或中间过程。
实现代码
df['Feature'].fillna('unknown', inplace=True)3)统计量填充
若缺失率较低(小于95%)且重要性较低,则根据数据分布的情况进行填充。
常用填充统计量:
平均值:
对于数据符合均匀分布,用该变量的均值填补缺失值。
中位数:
对于数据存在倾斜分布的情况,采用中位数填补缺失值。
众数:
离散特征可使用众数进行填充缺失值。
平均值填充法:
将初始数据集中的属性分为数值属性和非数值属性来分别进行处理。
实现代码
# 以pandas库操作为例
display(df.head(10))
# 填充前数据
Feature1 Feature2 Label
0 1.0 A 1
1 2.0 A 1
2 3.0 A 1
3 4.0 C 1
4 NaN A 1
5 2.0 None 0
6 3.0 B 0
7 3.0 None 0
8 NaN B 0
9 NaN B 0
# 均值填充
df['Feature1'].fillna(df['Feature1'].mean(), inplace=True)
# 中位数填充
df['Feature2'].fillna(df['Feature2'].mode().iloc[0], inplace=True)
display(df.head(10))
# 填充后数据
Feature1 Feature2 Label
0 1.000000 A 1
1 2.000000 A 1
2 3.000000 A 1
3 4.000000 C 1
4 2.571429 A 1
5 2.000000 A 0
6 3.000000 B 0
7 3.000000 A 0
8 2.571429 B 0
9 2.571429 B 0条件平均值填充法(Conditional Mean Completer):
在该方法中,用于求平均值/众数/中位数并不是从数据集的所有对象中取,而是从与该对象具有相同决策属性值的对象中取得。
实现代码
# 条件平均值填充
def condition_mean_fillna(df, label_name, feature_name):
mean_feature_name = '{}Mean'.format(feature_name)
group_df = df.groupby(label_name).mean().reset_index().rename(columns={feature_name: mean_feature_name})
df = pd.merge(df, group_df, on=label_name, how='left')
df.loc[df[feature_name].isnull(), feature_name] = df.loc[df[feature_name].isnull(), mean_feature_name]
df.drop(mean_feature_name, inplace=True, axis=1)
return df
df = condition_mode_fillna(df, 'Label', 'Feature2')4)模型预测填充
使用待填充字段作为Label,没有缺失的数据作为训练数据,建立分类/回归模型,对待填充的缺失字段进行预测并进行填充。
最近距离邻法(KNN)
先根据欧式距离或相关分析来确定距离具有缺失数据样本最近的K个样本,将这K个值加权平均/投票来估计该样本的缺失数据。
关键代码
from sklearn.neighbors import KNeighborsClassifier, KNeighborsRegressor
def knn_missing_filled(x_train, y_train, test, k = 3, dispersed = True):
'''
@param x_train: 没有缺失值的数据集
@param y_train: 待填充缺失值字段
@param test: 待填充缺失值数据集
'''
if dispersed:
clf = KNeighborsClassifier(n_neighbors = k, weights = "distance")
else:
clf = KNeighborsRegressor(n_neighbors = k, weights = "distance")
clf.fit(x_train, y_train)
return test.index, clf.predict(test)回归(Regression)
基于完整的数据集,建立回归方程。对于包含空值的对象,将已知属性值代入方程来估计未知属性值,以此估计值来进行填充。当变量不是线性相关时会导致有偏差的估计。常用线性回归。
5)插值法填充
包括随机插值,多重插补法,热平台插补,拉格朗日插值,牛顿插值等。
线性插值法
使用插值法可以计算缺失值的估计值,所谓的插值法就是通过两点(x0,y0),(x1,y1)估计中间点的值,假设y=f(x)是一条直线,通过已知的两点来计算函数f(x),然后只要知道x就能求出y,以此方法来估计缺失值。
实现代码
# df为pandas的DataFrame
df['Feature'] = df['Feature'].interpolate()多重插补(Multiple Imputation)
多值插补的思想来源于贝叶斯估计,认为待插补的值是随机的,它的值来自于已观测到的值。具体实践上通常是估计出待插补的值,然后再加上不同的噪声,形成多组可选插补值。根据某种选择依据,选取最合适的插补值。
多重插补方法分为三个步骤:
Step1:
为每个空值产生一套可能的插补值,这些值反映了无响应模型的不确定性;
每个值都可以被用来插补数据集中的缺失值,产生若干个完整数据集合;
Step2:
每个插补数据集合都用针对完整数据集的统计方法进行统计分析;
Step3:
对来自各个插补数据集的结果,根据评分函数进行选择,产生最终的插补值。
6)哑变量填充
若变量是离散型,且不同值较少,可转换成哑变量,例如性别SEX变量,存在male,fameal,NA三个不同的值,可将该列转换成 IS_SEX_MALE、IS_SEX_FEMALE、IS_SEX_NA。若某个变量存在十几个不同的值,可根据每个值的频数,将频数较小的值归为一类’other’,降低维度。此做法可最大化保留变量的信息。
实现代码
sex_list = ['MALE', 'FEMALE', np.NaN, 'FEMALE', 'FEMALE', np.NaN, 'MALE',]
df = pd.DataFrame({'SEX': sex_list})
display(df)
df.fillna('NA', inplace=True)
df = pd.get_dummies(df['SEX'],prefix='IS_SEX')
display(df)
# 原始数据
SEX
0 MALE
1 FEMALE
2 NaN
3 FEMALE
4 FEMALE
5 NaN
6 MALE
# 填充后
IS_SEX_FEMALE IS_SEX_MALE IS_SEX_NA
0 0 1 0
1 1 0 0
2 0 0 1
3 1 0 0
4 1 0 0
5 0 0 1
6 0 1 07)热卡填充(Hot deck imputation,就近补齐)
热卡填充法在完整数据中找到一个与它最相似的对象,然后用这个相似对象的值来进行填充。不同的问题可能会选用不同的标准来对相似进行判定。该方法概念上很简单,且利用了数据间的关系来进行空值估计。
这个方法的缺点在于难以定义相似标准,主观因素较多。
8)期望值最大化填充(Expectation maximization,EM)
EM算法是一种在不完全数据情况下计算极大似然估计或者后验分布的迭代算法。在每一迭代循环过程中交替执行两个步骤:E步(Excepctaion step,期望步),在给定完全数据和前一次迭代所得到的参数估计的情况下计算完全数据对应的对数似然函数的条件期望;M步(Maximzation step,极大化步),用极大化对数似然函数以确定参数的值,并用于下步的迭代。算法在E步和M步之间不断迭代直至收敛,即两次迭代之间的参数变化小于一个预先给定的阈值时结束。该方法可能会陷入局部极值,收敛速度也不是很快,并且计算很复杂。
缺点:由线性模型化所报告的软件标准误和检验统计量并不正确,且对于过度识别模型,估计值不是全然有效的。
4.缺失值处理步骤
1)确定缺失值范围
对每个字段都计算其缺失值比例,然后按照缺失比例和字段重要性,分别制定策略,可用下图表示:

2)去除不需要的字段
建议清洗每做一步都备份一下,或者在小规模数据上试验成功再处理全量数据。
3)填充缺失内容
使用上面介绍的任意一种或多种方法填充缺失数据。
4)重新取数
如果某些指标非常重要又缺失率高,那就需要和取数人员或业务人员了解,是否有其他渠道可以取到相关数据。
0x06 非需求数据清洗
简单来说就是把不要的字段删了。
看起来简单,但实际操作中容易有以下问题:
把看上去不需要但实际上对业务很重要的字段删了;
某个字段觉得有用,但又没想好怎么用,不知道是否该删;
一时看走眼,删错字段了。
在实际操作中,如果不知道哪些是非需求数据,可以不进行非需求数据清洗,在数据预处理之后再进行特征筛选。详情可参看《特征工程系列:特征筛选的原理与实现(上)》和《特征工程系列:特征筛选的原理与实现(下)》。
0xFF总结
1.数据清洗是特征工程的第一步,也是非常重要的一步。
2.数据清洗的一般流程:
Step 1:
格式内容清洗;
Step 2:
逻辑错误清洗;
Step 3:
异常数据清洗;
Step 4:
缺失数据清洗;
Step 5:
非需求数据清洗。
不同的数据质量不一样,并不是所有项目中都需要进行每一项数据清洗,应该根据实际情况选择必要的数据清洗方式。
注:文章中使用的部分图片源于网络。
欢迎大家一起来讨论。
参考文献
[1] 数据清洗的一些梳理. https://zhuanlan.zhihu.com/p/20571505
[2] 数据预处理——缺失值处理. https://zhuanlan.zhihu.com/p/33996846
[3] Multiple Imputation with Chained Equations. http://www.statsmodels.org/stable/imputation.html
[4] https://www.zhihu.com/question/22077960/answer/473720583
更多特征工程文章:
特征工程系列:特征筛选的原理与实现(上)
特征工程系列:特征筛选的原理与实现(下)
