torch.optim
参考 torch.optim - 云+社区 - 腾讯云
目录
如何使用一个优化器
构建它
预参数选项
采取优化步骤
算法
class torch.optim.Optimizer(params, defaults)[source]
add_param_group(param_group)[source]
load_state_dict(state_dict)[source]
state_dict()[source]
zero_grad()[source]
class torch.optim.Adadelta(params, lr=1.0, rho=0.9, eps=1e-06, weight_decay=0)[source]
class torch.optim.Adagrad(params, lr=0.01, lr_decay=0, weight_decay=0, initial_accumulator_value=0)[source]
step(closure)[source]
class torch.optim.Adam(params, lr=0.001, betas=(0.9, 0.999), eps=1e-08, weight_decay=0, amsgrad=False)[source]
step(closure)[source]
class torch.optim.AdamW(params, lr=0.001, betas=(0.9, 0.999), eps=1e-08, weight_decay=0.01, amsgrad=False)[source]
step(closure)[source]
class torch.optim.SparseAdam(params, lr=0.001, betas=(0.9, 0.999), eps=1e-08)[source]
step(closure)[source]
class torch.optim.Adamax(params, lr=0.002, betas=(0.9, 0.999), eps=1e-08, weight_decay=0)[source]
step(closure)[source]
class torch.optim.ASGD(params, lr=0.01, lambd=0.0001, alpha=0.75, t0=1000000.0, weight_decay=0)[source]
step(closure)[source]
class torch.optim.LBFGS(params, lr=1, max_iter=20, max_eval=None, tolerance_grad=1e-05, tolerance_change=1e-09, history_size=100, line_search_fn=None)[source]
step(closure)[source]
class torch.optim.RMSprop(params, lr=0.01, alpha=0.99, eps=1e-08, weight_decay=0, momentum=0, centered=False)[source]
step(closure)[source]
class torch.optim.Rprop(params, lr=0.01, etas=(0.5, 1.2), step_sizes=(1e-06, 50))[source]
step(closure)[source]
class torch.optim.SGD(params, lr=, momentum=0, dampening=0, weight_decay=0, nesterov=False)[source]
step(closure)[source]
如何调整学习率
class torch.optim.lr_scheduler.LambdaLR(optimizer, lr_lambda, last_epoch=-1)[source]
load_state_dict(state_dict)[source]
state_dict()[source]
class torch.optim.lr_scheduler.StepLR(optimizer, step_size, gamma=0.1, last_epoch=-1)[source]
class torch.optim.lr_scheduler.MultiStepLR(optimizer, milestones, gamma=0.1, last_epoch=-1)[source]
class torch.optim.lr_scheduler.ExponentialLR(optimizer, gamma, last_epoch=-1)[source]
class torch.optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max, eta_min=0, last_epoch=-1)[source]
class torch.optim.lr_scheduler.ReduceLROnPlateau(optimizer, mode='min', factor=0.1, patience=10, verbose=False, threshold=0.0001, threshold_mode='rel', cooldown=0, min_lr=0, eps=1e-08)[source]
class torch.optim.lr_scheduler.CyclicLR(optimizer, base_lr, max_lr, step_size_up=2000, step_size_down=None, mode='triangular', gamma=1.0, scale_fn=None, scale_mode='cycle', cycle_momentum=True, base_momentum=0.8, max_momentum=0.9, last_epoch=-1)[source]
get_lr()[source]
如何使用一个优化器
为了使用torch.optim,你必须构建一个优化对象,那将会保持现有的状态,并且基于计算的来更新参数。
构建它
为了构建一个优化器,你必须给定一个用来优化的参数的迭代器(所有应该是变量s)。然后,你能指定优化指定选项,例如学习率、权重衰减等。
注意:
If you need to move a model to GPU via .cuda(), please do so before constructing optimizers for it. Parameters of a model after .cuda() will be different objects with those before the call.In general, you should make sure that optimized parameters live in consistent locations when optimizers are constructed and used.
如果你通过.cuda()将一个模型移动到GPU,对它请在构建优化器之前这么做。.cuda()之后的模型参数与调用之前的参数是不同的对象。通常情况下,你应该确保使得优化在连续的位置上,当优化器构建和使用的时候。
例:
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.9)
optimizer = optim.Adam([var1, var2], lr=0.0001)预参数选项
Optimizers also support specifying per-parameter options. To do this, instead of passing an iterable of Variable s, pass in an iterable of dict s. Each of them will define a separate parameter group, and should contain a params key, containing a list of parameters belonging to it. Other keys should match the keyword arguments accepted by the optimizers, and will be used as optimization options for this group.
Optimizers也支持预参数选项。这么做,代替传递一个可迭代的变量s,传入一个可迭代的字典s。它们的每一个都会定一个分离的参数组,并且应该包含一个参数键,包含一个属于它的参数列表。其余键应该匹配优化器接受的关键字参数,并将作为这个组的优化选项。
注意:
注意你依然能够传递关键字参数。它们将会被用作默认值,在不重写它们的组中。当你仅仅想改变一个单一的选项时这很有用,同时保持参数组之间的所有其他一致。例如,当需要指定每层的学习速率时,这是非常有用的:
optim.SGD([
{'params': model.base.parameters()},
{'params': model.classifier.parameters(), 'lr': 1e-3}
], lr=1e-2, momentum=0.9)This means that model.base’s parameters will use the default learning rate of 1e-2, model.classifier’s parameters will use a learning rate of 1e-3, and a momentum of 0.9 will be used for all parameters.
这意味着model.base的参数将会使用默认的学习率1e-2,model.classifier的参数将会适应1e-3,对所有参数动量都设置为0.9。
采取优化步骤
所有优化器实现一个step()方法用来更新参数。它的使用方法有两种:
optimizer.step()这是大多数优化器都支持的简单版本。这个函数只调用一次,梯度计算用backward()来实现。
例:
for input, target in dataset:
optimizer.zero_grad()
output = model(input)
loss = loss_fn(output, target)
loss.backward()
optimizer.step()
optimizer.step(closure)一些优化算法例如联合提盒LBFGS需要重新评估函数多次,所以你必须传递一个闭包允许他们重新计算你的模型。闭包应该清除梯度,计算损失,并返回它。
例:
for input, target in dataset:
def closure():
optimizer.zero_grad()
output = model(input)
loss = loss_fn(output, target)
loss.backward()
return loss
optimizer.step(closure)算法
class torch.optim.Optimizer(params, defaults)[source]
所有优化器的基类。
Warning
需要将参数指定为具有确定性排序、在运行之间保持一致的集合。不满足这些属性的对象的例子是集合和字典值的迭代器。
参数:
-
params (iterable) – 一个可迭代的对象或者字典。指定了什么张量应该优化。
-
defaults – (dict): 包含优化选项默认值的字典(当一个优化器组不指定他们时才使用)
add_param_group(param_group)[source]
向Optimizer参数组加入一个参数组。当预先训练好的网络作为冻结层进行微调时,这是有用的,并且可以在训练过程中添加到优化器中。
参数:
-
param_group (dict) – 沿着组指定哪个张量应该优化。
-
optimization options. (specific) – 指定
load_state_dict(state_dict)[source]
载入优化器的状态。
参数:
- state_dict (dict) – 优化器状态。应该是调用state_dict()的返回对象。
state_dict()[source]
以字典的形式返回优化器的状态。
It contains two entries:
它包含两个部分:
-
state - 保持目前优化器状态的字典。它的内容和优化器的类别不同。
-
param_groups - 包含所有优化器组的字典。
step(closure)[source]
执行一个单一的优化步骤(参数更新)。
参数:
- closure (callable) – 重新评估并且返回损失的闭包。对大多数优化器是可选的。
zero_grad()[source]
清楚所有优化后的torch.Tensor的梯度。
class torch.optim.Adadelta(params, lr=1.0, rho=0.9, eps=1e-06, weight_decay=0)[source]
实现Adadelta算法,实现这个算法的文章为:ADADELTA: An Adaptive Learning Rate Method
参数:
-
params (iterable) – 参数的可迭代性,以优化或dicts定义参数组
-
rho (float, optional) – 用来计算平方梯度平均值的系数(默认是0.9)
-
eps (float, optional) – 将项加到分母以提高数值稳定性(默认是1e-6)
-
lr (float, optional) – 在delta应用到参数之前对其进行缩放的系数(默认值:1.0)
-
weight_decay (float, optional) – 体重衰减(L2惩罚)(默认值:0)
tep(closure)[source]
执行一个单一的优化步骤(参数更新)。
参数:
- closure (callable) – 重新评估并且返回损失的闭包。对大多数优化器是可选的。
class torch.optim.Adagrad(params, lr=0.01, lr_decay=0, weight_decay=0, initial_accumulator_value=0)[source]
Implements Adagrad algorithm.
实现Adagrad算法,论文为:Adaptive Subgradient Methods for Online Learning and Stochastic Optimization
参数:
-
params (iterable) – 参数的可迭代性,以优化或dicts定义参数组
-
lr (float, optional) – 学习率(默认为1e-2)
-
lr_decay (float, optional) – 学习率衰减(默认值:0)
-
weight_decay (float, optional) – 权重衰减(L2 乘法)(默认:0)
step(closure)[source]
执行一个单一的优化步骤(参数更新)。
参数:
- closure (callable) – 重新评估并且返回损失的闭包。对大多数优化器是可选的。
class torch.optim.Adam(params, lr=0.001, betas=(0.9, 0.999), eps=1e-08, weight_decay=0, amsgrad=False)[source]
实现Adam算法,论文为:Adam: A Method for Stochastic Optimization
Parameters
-
params (iterable) – 参数的可迭代性,以优化或dicts定义参数组
-
lr (float, optional) – 学习率(默认为1e-3)
-
betas (Tuple[float, float], optional) – 用于计算梯度及其平方的运行平均值的系数(默认值:(0.9,0.999))
-
eps (float, optional) – 添加到分母以提高数值稳定性(默认:1e-8)
-
weight_decay (float, optional) –权重衰减(L2惩罚)(默认值:0)
-
amsgrad (boolean, optional) – 是否使用本文算法的AMSGrad变式 On the Convergence of Adam and Beyond (默认值: False)
step(closure)[source]
执行一个单一的优化步骤(参数更新)。
参数:
- closure (callable) – 重新评估并且返回损失的闭包。对大多数优化器是可选的。
class torch.optim.AdamW(params, lr=0.001, betas=(0.9, 0.999), eps=1e-08, weight_decay=0.01, amsgrad=False)[source]
实现AdamW算法。论文为:Adam: A Method for Stochastic Optimization,AdamW的变体为Decoupled Weight Decay Regularization。
Parameters
-
params (iterable) – 参数的可迭代性,以优化或dicts定义参数组
-
lr (float, optional) – 学习率(默认为1e-3)
-
betas (Tuple[float, float], optional) – 用于计算梯度及其平方的运行平均值的系数(默认值:(0.9,0.999))
-
eps (float, optional) – 添加到分母以提高数值稳定性(默认:1e-8)
-
weight_decay (float, optional) – 重量衰减系数(默认为1e-2)
-
amsgrad (boolean, optional) – 是否使用本文算法的AMSGrad变体 On the Convergence of Adam and Beyond (默认: False)
step(closure)[source]
执行一个单一的优化步骤(参数更新)。
参数:
- closure (callable) – 重新评估并且返回损失的闭包。对大多数优化器是可选的。
class torch.optim.SparseAdam(params, lr=0.001, betas=(0.9, 0.999), eps=1e-08)[source]
实现了适合于稀疏张量的Adam算法的延迟版本。在这个变量中,只有梯度中出现的moments会被更新,并且只有梯度中的那些部分会被应用到参数中。
参数:
-
params (iterable) – 参数的可迭代性,以优化或dicts定义参数组
-
lr (float, optional) – 学习率(默认为1e-3)
-
betas (Tuple[float, float], optional) – 用于计算梯度及其平方的运行平均值的系数(默认值:(0.9,0.999))
-
eps (float, optional) – 添加到分母以提高数值稳定性(默认:1e-8)
step(closure)[source]
执行一个单一的优化步骤(参数更新)。
参数:
- closure (callable) – 重新评估并且返回损失的闭包。对大多数优化器是可选的。
class torch.optim.Adamax(params, lr=0.002, betas=(0.9, 0.999), eps=1e-08, weight_decay=0)[source]
实现了Adamax算法(基于无穷范数的Adam的变体)。实现的论文为:Adam: A Method for Stochastic Optimization
参数:
-
params (iterable) – 参数的可迭代性,以优化或dicts定义参数组
-
lr (float, optional) – 学习率(默认:2e-3)
-
betas (Tuple[float, float], optional) – 系数用于计算梯度及其平方的运行平均值
-
eps (float, optional) – 添加到分母以提高数值稳定性(默认:1e-8)
-
weight_decay (float, optional) – 体重衰减(L2惩罚)(默认值:0)
step(closure)[source]
执行一个单一的优化步骤(参数更新)。
参数:
- closure (callable) – 重新评估并且返回损失的闭包。对大多数优化器是可选的。
class torch.optim.ASGD(params, lr=0.01, lambd=0.0001, alpha=0.75, t0=1000000.0, weight_decay=0)[source]
实现平均随机梯度下降,实现论文为:Acceleration of stochastic approximation by averaging
参数:
-
params (iterable) – 参数的可迭代性,以优化或dicts定义参数组
-
lr (float, optional) – 学习率(默认为1e-2)
-
lambd (float, optional) – 衰减项(默认为1e-4)
-
alpha (float, optional) – eta更新的电源(默认值:0.75)
-
t0 (float, optional) – 开始平均的点(默认值:1e6)
-
weight_decay (float, optional) – 体重衰减(L2惩罚)(默认值:0)
step(closure)[source]
执行一个单一的优化步骤(参数更新)。
参数:
- closure (callable) – 重新评估并且返回损失的闭包。对大多数优化器是可选的。
class torch.optim.LBFGS(params, lr=1, max_iter=20, max_eval=None, tolerance_grad=1e-05, tolerance_change=1e-09, history_size=100, line_search_fn=None)[source]
实现L-BFGS算法,受minFunc - unconstrained differentiable multivariate optimization in Matlab启发。
警告:
这个优化器不支持每个参数选项和参数组(只能有一个)。
警告:
现在所有的参数都必须在单独的设备上。这点将来将会改进。
注意:
这是一个非常耗内存的优化器(它需要额外的param_bytes * (history_size + 1)bytes)。如果它在内存在不匹配,尽力减少历史尺寸,或者使用不同的算法。
Parameters
-
lr (float) – 学习率(默认为1)
-
max_iter (int) – 每个优化步骤的最大迭代次数(默认为20)
-
max_eval (int) – 每个优化步骤的最大函数计算数(默认:max_iter * 1.25)。
-
tolerance_grad (float) – 一阶最优的终止公差(默认:1e-5)。
-
tolerance_change (float) – 函数值/参数变化的终止容忍(默认:1e-9)。
-
history_size (int) – 更新历史记录大小(默认值:100)。
-
line_search_fn (str) – 要么是' strong_wolfe ',要么是None(默认为None)。
step(closure)[source]
执行一个单一的优化步骤(参数更新)。
参数:
- closure (callable) – 重新评估并且返回损失的闭包。对大多数优化器是可选的。
class torch.optim.RMSprop(params, lr=0.01, alpha=0.99, eps=1e-08, weight_decay=0, momentum=0, centered=False)[source]
实现RMSprop算法,论文为:Generating Sequences With Recurrent Neural Networks
Parameters
-
params (iterable) – 参数的可迭代性,以优化或dicts定义参数组
-
lr (float, optional) – 学习率(默认为1e-2)
-
momentum (float, optional) – 动量因子(默认值:0)
-
alpha (float, optional) – 平滑常数(默认值:0.99)
-
eps (float, optional) – 添加到分母以提高数值稳定性(默认:1e-8)
-
centered (bool, optional) – 如果为真,计算中心RMSProp,梯度被估计其方差归一化
-
weight_decay (float, optional) – 体重衰减(L2惩罚)(默认值:0)
step(closure)[source]
执行一个单一的优化步骤(参数更新)。
参数:
- closure (callable) – 重新评估并且返回损失的闭包。对大多数优化器是可选的。
class torch.optim.Rprop(params, lr=0.01, etas=(0.5, 1.2), step_sizes=(1e-06, 50))[source]
实现弹性反向传播算法。
参数:
-
params (iterable) – 参数的可迭代性,以优化或dicts定义参数组
-
lr (float, optional) – 学习率(默认为1e-2)
-
etas (Tuple[float, float], optional) – 对(etaminus, etaplis),它们是乘法增减因子(默认为(0.5,1.2))
-
step_sizes (Tuple[float, float], optional) – 允许的最小和最大步长(默认值:(1e- 6,50))
step(closure)[source]
执行一个单一的优化步骤(参数更新)。
参数:
- closure (callable) – 重新评估并且返回损失的闭包。对大多数优化器是可选的。
class torch.optim.SGD(params, lr=
实现动量可选的随机梯度下降算法。涅斯特洛夫动量是基于:On the importance of initialization and momentum in deep learning
参数:
-
params (iterable) – 参数的可迭代性,以优化或dicts定义参数组
-
lr (float) – 学习率
-
momentum (float, optional) – 动量因子(默认值:0)
-
weight_decay (float, optional) – 体重衰减(L2惩罚)(默认值:0)
-
dampening (float, optional) – 动量抑制(默认值:0)
-
nesterov (bool, optional) – 启用Nesterov动量(默认:False)
例:
>>> optimizer = torch.optim.SGD(model.parameters(), lr=0.1, momentum=0.9)
>>> optimizer.zero_grad()
>>> loss_fn(model(input), target).backward()
>>> optimizer.step()Note
使用Momentum/Nesterov实现SGD与Sutskever等人以及其他一些框架中的实现有稍微的不同。考虑到Momentum的具体情况,更新可以写成:

其中p、g、v和\rho分别表示参数、梯度、速度和动量。这与Sutskever等和其他使用表单更新的框架形成了对比

涅斯特洛夫版本进行了类似的修改。
step(closure)[source]
执行一个单一的优化步骤(参数更新)。
参数:
- closure (callable) – 重新评估并且返回损失的闭包。对大多数优化器是可选的。
如何调整学习率
torch.optim.lr_scheduler提供了几种基于epoch数调整学习速率的方法。torch.optim.lr_scheduler。ReduceLROnPlateau允许基于一些验证测量的动态学习率降低。优化器更新后应采用学习率调度;
例:你应该这样写代码:
>>> scheduler = ...
>>> for epoch in range(100):
>>> train(...)
>>> validate(...)
>>> scheduler.step()警告:
在PyTorch 1.1.0之前,学习率调度器被期望在优化器更新之前被调用;1.1.0用BC-打断的方式改变这种行为。如果在优化器的更新之前使用学习率调度程序(调用scheduler.step()),这将跳过学习率调度的第一个值。如果在升级到PyTorch 1.1.0后无法重现结果,请检查是否在错误的时间调用scheduler.step()。
class torch.optim.lr_scheduler.LambdaLR(optimizer, lr_lambda, last_epoch=-1)[source]
将每个参数组的学习率设置为给定函数的初始lr。当last_epoch=-1时,将初始lr设置为lr。
参数:
-
optimizer (Optimizer) – 包裹优化器
-
lr_lambda (function or list) – 给定一个整数参数epoch计算乘法因子的函数,或这类函数的列表,在optimizer.param_groups中为每一组计算一个乘法因子。
-
last_epoch (int) – 最后一个纪元的索引。默认值:1。
例:
>>> # Assuming optimizer has two groups.
>>> lambda1 = lambda epoch: epoch // 30
>>> lambda2 = lambda epoch: 0.95 ** epoch
>>> scheduler = LambdaLR(optimizer, lr_lambda=[lambda1, lambda2])
>>> for epoch in range(100):
>>> train(...)
>>> validate(...)
>>> scheduler.step()load_state_dict(state_dict)[source]
加载策略状态。
参数:
state_dict (dict) – 调度的状态。应该是调用state_dict()返回的对象。
state_dict()[source]
以dict的形式返回调度程序的状态。它为self中的每个变量都包含一个条目。剩下的不是优化器。学习率lambda函数只有在它们是可调用对象时才会保存,而在它们是函数或lambdas时则不会保存。
class torch.optim.lr_scheduler.StepLR(optimizer, step_size, gamma=0.1, last_epoch=-1)[source]
将每个参数组的学习速率设置为每个step_size epoch由gamma衰减的初始lr。当last_epoch=-1时,将初始lr设置为lr。
参数:
-
optimizer (Optimizer) – 包裹的优化器
-
step_size (int) – 学习率周期衰减。
-
gamma (float) – 学习速率的乘数衰减。默认值:0.1。
-
last_epoch (int) – 最后一个epoch的索引。默认值:1。
例:
>>> # Assuming optimizer uses lr = 0.05 for all groups
>>> # lr = 0.05 if epoch < 30
>>> # lr = 0.005 if 30 <= epoch < 60
>>> # lr = 0.0005 if 60 <= epoch < 90
>>> # ...
>>> scheduler = StepLR(optimizer, step_size=30, gamma=0.1)
>>> for epoch in range(100):
>>> train(...)
>>> validate(...)
>>> scheduler.step()class torch.optim.lr_scheduler.MultiStepLR(optimizer, milestones, gamma=0.1, last_epoch=-1)[source]
将每个参数组的学习率设置为初始lr,一旦epoch的数量达到里程碑之一,就被gamma衰减。当last_epoch=-1时,将初始lr设置为lr。
参数:
-
optimizer (Optimizer) – 包裹的优化器。
-
milestones (list) – epoch索引列表。必须增加。
-
gamma (float) – 学习速率的乘数衰减。默认值:0.1。
-
last_epoch (int) – 最后一个epoch的索引。默认值:1。
例:
>>> # Assuming optimizer uses lr = 0.05 for all groups
>>> # lr = 0.05 if epoch < 30
>>> # lr = 0.005 if 30 <= epoch < 80
>>> # lr = 0.0005 if epoch >= 80
>>> scheduler = MultiStepLR(optimizer, milestones=[30,80], gamma=0.1)
>>> for epoch in range(100):
>>> train(...)
>>> validate(...)
>>> scheduler.step()class torch.optim.lr_scheduler.ExponentialLR(optimizer, gamma, last_epoch=-1)[source]
将各参数组的学习率设为每历元gamma衰减的初始lr。当last_epoch=-1时,将初始lr设置为lr。
参数:
-
optimizer (Optimizer) – 包裹的优化器
-
gamma (float) – 学习速率的乘数衰减。
-
last_epoch (int) – 最后一个epoch的索引。默认值:1。
class torch.optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max, eta_min=0, last_epoch=-1)[source]
使用余弦退火调度设置每个参数组的学习率,其中\eta_{max}设置为初始lr, T_{cur}为SGDR中最后一次重启后的epoch数:
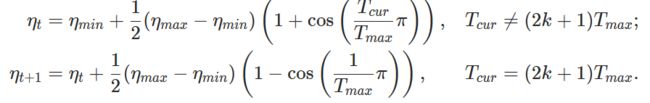
当上一个epoch=-1时,设置初始lr为lr。在SGDR: Stochastic Gradient Descent with Warm Restarts中提出。注意,这只实现了SGDR的余弦退火部分,而没有实现重启。
参数:
-
optimizer (Optimizer) – 包裹的参数
-
T_max (int) – 最大迭代数
-
eta_min (float) – 最低学习速率。默认值:0。
-
last_epoch (int) – 最后一个epoch的索引。默认值:1。
class torch.optim.lr_scheduler.ReduceLROnPlateau(optimizer, mode='min', factor=0.1, patience=10, verbose=False, threshold=0.0001, threshold_mode='rel', cooldown=0, min_lr=0, eps=1e-08)[source]
当一个指标停止改进时降低学习率。一旦学习停滞,模型往往能将学习率降低2-10倍。这个调度器读取一个度量量,如果没有看到一个“patience”的epoch数的改进,学习率降低。
Parameters
-
optimizer (Optimizer) – 包裹的优化器。
-
mode (str) – 最小值之一,最大值。在min模式下,监控数量停止减少,lr减少;在max模式下,当监控数量停止增加时,将会减少。默认值:“分钟”。
-
factor (float) – 学习率降低的因素。new_lr = lr * factor。默认值:0.1。
-
patience (int) – 没有改进的epoch,在此之后学习率将降低。例如,如果patience = 2,那么我们将忽略前2个epoch而没有任何改善,只有在第3个epoch后损失仍然没有改善时才会降低LR。默认值:10。
-
verbose (bool) – 如果为真,则为每次更新向stdout打印一条消息。默认值:False。
-
threshold (float) – 为衡量新的最佳阈值,只关注重大变化。默认值:1e-4。
-
threshold_mode (str) – 在rel模式下,dynamic_threshold =“最大”模式下的最佳* (1 + threshold)或“最小”模式下的最佳* (1 - threshold)。在abs模式下,dynamic_threshold = best + threshold(最大模式)或best - threshold(最小模式)。默认值:rel。
-
cooldown (int) – 减少lr后恢复正常操作之前需要等待的epoch数。默认值:0。
-
min_lr (float or list) – 标量标量或标量列表。所有参数组或各参数组的学习率的下界。默认值:0。
-
eps (float) – 最小衰减作用于lr。如果新旧lr的差异小于eps,则忽略更新。默认值:1 e-8。
例:
>>> optimizer = torch.optim.SGD(model.parameters(), lr=0.1, momentum=0.9)
>>> scheduler = ReduceLROnPlateau(optimizer, 'min')
>>> for epoch in range(10):
>>> train(...)
>>> val_loss = validate(...)
>>> # Note that step should be called after validate()
>>> scheduler.step(val_loss)class torch.optim.lr_scheduler.CyclicLR(optimizer, base_lr, max_lr, step_size_up=2000, step_size_down=None, mode='triangular', gamma=1.0, scale_fn=None, scale_mode='cycle', cycle_momentum=True, base_momentum=0.8, max_momentum=0.9, last_epoch=-1)[source]
根据循环学习率策略(CLR)设置各参数组的学习率。 策略的周期是两个边界之间的学习率具有一个恒定的频率,如本文所述 Cyclical Learning Rates for Training Neural Networks. 这两个边界之间的距离可以按每次迭代或每个周期进行缩放。周期性学习率策略会在每批后改变学习率。步骤应在批处理已用于训练后调用。
这个类有三个内建策略,如论文所述:“三角形”:一个基本的无振幅缩放的三角形周期。
“triangular2”:
一种基本的三角形周期,每周期将初始振幅减半。
“exp_range”:
在每个周期迭代中以gamma**(周期迭代)衡量初始振幅的一种周期。这个实现改编自github repo: bckenstler/CLR。
参数:
-
optimizer (Optimizer) – 包裹的优化器。
-
base_lr (float or list) – 初始学习率,即每个参数组循环的下边界。
-
max_lr (float or list) – 循环中各参数组的上学习速率边界。在功能上,它定义了周期振幅(max_lr - base_lr)。在任何周期的lr是base_lr和一些缩放幅度的总和;因此,实际上可能无法达到max_lr,这取决于缩放函数。
-
step_size_up (int) – 训练迭代次数在一个周期中增加了一半。默认值:2000
-
step_size_down (int) – 训练迭代次数在一个周期中逐渐减少的一半。如果step_size_down为None,则将其设置为step_size_up。默认值:无
-
mode (str) – 是{triangle, triangular2, exp_range}中的一个。值对应于上面详细描述的策略。如果scale_fn不是None,则忽略此参数。默认值:“三角”
-
gamma (float) – 常量在' exp_range '缩放函数:gamma**(循环迭代)默认:1.0
-
scale_fn (function) – 由单个参数lambda函数定义的自定义缩放策略,其中0 <= scale_fn(x) <= 1对于所有x >= 0。如果指定,则忽略“mode”。默认值:无
-
scale_mode (str) – {‘cycle’, ‘iterations’}. 定义scale_fn是根据循环次数评估还是根据循环迭代(从循环开始训练迭代)评估。默认值:“循环”
-
cycle_momentum (bool) – 如果为真,则动量与“base_momentum”和“max_momentum”之间的学习速率成反比循环。默认值:True
-
base_momentum (float or list) – 周期中每个参数组的动量边界较低。注意,动量的循环是反比学习率;在周期的高峰期,动量是“base_momentum”,学习率是“max_lr”。默认值:0.8
-
max_momentum (float or list) – 周期中每个参数组的上动量边界。在功能上,它定义了周期振幅(max_momentum - base_momentum)。在任何周期的动量是max_动量的差和振幅的缩放;因此,实际上可能无法达到base_momentum,这取决于缩放函数。注意,动量的循环是反比学习率;在一个周期开始时,动量是‘max_momentum’,学习速率默认为‘base_lr’:0.9
-
last_epoch (int) – 最后一批的索引。在恢复训练工作时使用此参数。因为step()应该在每个批处理之后而不是在每个epoch之后调用,所以这个数字表示计算的批处理总数,而不是计算的epoch总数。当last_epoch=-1时,计划从头开始。默认值:1
例:
>>> optimizer = torch.optim.SGD(model.parameters(), lr=0.1, momentum=0.9)
>>> scheduler = torch.optim.lr_scheduler.CyclicLR(optimizer, base_lr=0.01, max_lr=0.1)
>>> data_loader = torch.utils.data.DataLoader(...)
>>> for epoch in range(10):
>>> for batch in data_loader:
>>> train_batch(...)
>>> scheduler.step()get_lr()[source]
计算批处理索引的学习率。这个函数自我处理。last_epoch作为最后一批索引。如果自我。如果为True,则该函数的副作用是更新优化器的动量。