channels级别的剪枝论文方法分析-希望能够持续更新
1、韩松的deep_compression:稀疏化、kmeans聚类、哈夫曼压缩编码三个角度压缩模型
2、Pruning Filters for efficient converts
使用l1-norm来作为通道权重的重要性进行剪枝,提出了通道敏感度这一思想,边剪边训练最终达到最佳值
3、Network training:a data driven neuron pruning approach torwards efficient deep archtectures
使用一种新的评价参数判断是否需要被裁剪,称之为AP0Z,剪完微调再继续剪
4、An Entroy-based pruningmethodb for dnn compression
基于熵值裁剪,将feature_map通过gap变成c个(filters)向量,n张图片则由n*c的矩阵,对于每一个filter,将其分为m个bin,统计每个bin的概率,计算熵值,利用熵值来判断filters重要性
5、networks sliming-learning efficient convolutional networks through network sliming
此方法应用很广,因此此处重点介绍,并且给出我的理解。
首先,如何理解l1正则化得到稀疏解这个问题,假定只有一个参数w,损失函数为L(w),分别加上l1和l2正则化项后有:
假定L(w)在0处的导数为d0,即上右图,则可以推导使用l1正则和l2正则时的导数,如下所示,分别为l2和l1:
由上图所示,引入l2后,loss在0处的导数依旧是d0,而引入l1正则后,loss在0处的导数有一个突变,即d0-r和d0+r,如果d0+r和d0-r异号,则在0处会有一个极小值点,因此,优化时,可能优化到该极小值点上。
而各个bn剪枝的源码中,对bn本身的梯度就是grad+s*sign(weight.data),其实就是符合上述公式,其中r值即为设定的正则化超参数,符合定义,直指本质。
https://blog.csdn.net/qq_26598445/article/details/82844393
6、data-driven sparse structer selectin for deep neural networks
针对特定的神经元、block等进行剪枝,天生适合目前流行的block堆叠式网络,为每一个神经元或者block增加一个缩放因子,利用随机加速近端梯度APG来优化和稀疏化这些缩放因子。当缩放因子为0时,则可以移除这些block,大幅度缩减网络结构
此处重点是如何利用sgd推导出APG,然后在torch中实现这个优化器,我已完成,近期最好将代码上传github。
7、channel pruning for accelerating very deep neural network
论文思想:最小化重建feature-map的误差
假定输入feature_map为B,其通道数为c,w为本层的卷积核,数量为n,此时要剪掉c中的k个通道,对应的,也就证明本层w的k个通道卷积核没用,可以删去。分成两步来判断哪些通道可以删去:1、找到最具有代表性的通道,使用lasso回归来做;2、使用中最小均方误差来表示重构feature_map误差。源码是基于caffe做的,复杂且麻烦,并不推荐。
8、thiNet: a filter level pruning method for deep neural network compression
论文思想核心在于filter的选择方式:filter的修剪取决于下一层的输出,而不是当前层,如果某曾的输入数据一部分就可以得到与全部输入近似的结果,那么就可以将输入数据中其它部分去掉,同时将前面对应的filters去掉。
通道选择使用基于数据驱动,建立一个用于重要性评估的训练集,如果: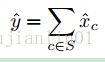
能够成立,其中s是一个通道子集,那么我们就可以不依赖与任何非s的通道,从而对应的上一层的卷积通道也可以删除。此时更进一步的,采用最小化重构误差来作为损失函数,即重构feature_map和原始feature_map进行MSEloss,论文提出最后使用最小二乘法来解决。
9、centripetal sgd for pruning very deep convolutional networks with complicated structure
通过修改SGD→ C-SGD,使得filter越来越接近,然后使用聚类的方式,将卷积核聚类为多个集合,每个集合保留一个卷积核,并且剪枝后的模型是不需要进行finetuning的。
https://blog.csdn.net/znestor/article/details/103287332
10、Soft Filter Pruning for Accelerating Deep Convolutional Neural Networks
区别于hard-prune,本文在每次训练的时候使用l2范数对每个通道的重要性进行评估,完成后将这些重要性低的通道权重全部置为0,但允许梯度更新,由于为0的通道最后面会越来越不重要,即使梯度更新也会越来越小的梯度更新,最终越不重要的通道梯度越小。当剪枝前后精度没有损失后,此时再执行hard-prune,完成通道剪枝。
11、rethining the smaller-norm-less-informative assumption in channel pruning of convlution layers
12、the lottery ticket hypothesis: finding sparse trainable netural networks
将复杂网络的所有参数当成一个奖池,将奖池中的一组自参数所对应的子网络当做中奖彩票,单独训练该中奖彩票,则可以获取与原来复杂复杂网络类似的精度。核心在于如何寻找中奖彩票:
- 随机初始化网络;2、训练网络迭代收敛后得到参数o1,;3、在参数o1中剪掉比例参数,生成一个mask;4、在剩余的结构中永远是初始化参数o1进行训练,以产生中奖彩票。
作者使用iterative pruning来做,也就是重复训练、剪枝、重置网络n次,每次裁剪p^(1/n)%的参数量。注意:每次剪枝一定要用最原始的o1来初始化网络。
13、Rethinking value of netwiork pruning
在通过prune算法得到压缩模型后,使用来自大网络的权重进行finetue,还不如直接随机初始化训练压缩模型,但文中指出,需要更大的epochs才能够得到更好的效果。作者认为剪枝获得的结构比权重参数更加重要。并且在知乎怒怼了上一篇彩票理论的观点。
14、pruning convolutional netural networks for resource efficient inference(英伟达)
使用泰勒展开的新准则,用它去近似由于修剪网络引起的损失函数的变化。
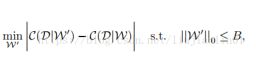
使用如上图函数衡量修剪的w1是否达到最优,即寻找一个修剪后效果接近于与训练好的原始权重w2。
提出三种方式来进行处理:
- 基于卷积核的权重大小进行剪枝,且finetune过程不增加计算量
- 统计激活蹭的结果大小,删除很小的激活值的卷积核
- 利用互信息,衡量一个变量中关于林一个变量存在多少信息的度量,即两个信息的相互依赖程度。
- 泰勒展开,用1阶泰勒展开去逼近下右式:
![]()
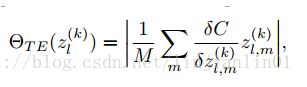
最终训练完后则可以得到每一个通道的一个泰勒展开值。
15、Filter pruning via geometric median for deep convolutational netural network acceleration
基于范数的剪枝必须满足标准差大,最小范数接近于0,但通常不满足,作者认为
几何中心的卷积核不重要,几何中心定义为实数空间内,各个点到某一点a的欧氏距离 最小值之和,即为几何中心:

16、learning to prune in training via dynamic channel propagation
提出channel utility(通道显著性)这个标准,核心计算还是基于泰勒展开,将其作为标准,再更进一步的提出utility。在训练的同时自适应衰减更新utility,更新规则如下式,将utility作为mask,大于门限值则为1,小于则为0,outpu*=mask,
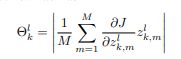
![]()
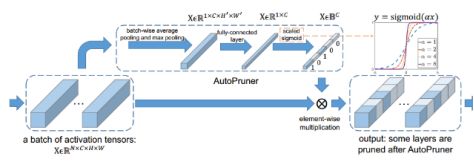
17、Auto pruner: an end-to-end traiable filter pruning method for efficient deep model inference
对每一层,添加一层编码层,设置损失函数使编码层输出为0,1的向量,且1的数量满足剪枝率,最后变成0的通道直接删除。但实际控制每层的1的数量的超参数很难控制。
18、learning filter correlations for deep model compression
以前的方法只考虑了filters之间的重要性,没有考虑冗余程度,因此在冗余压缩中做不到最优,基于相关性提升压缩率。
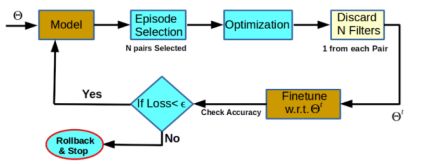
迭代式剪枝:在episode selection阶段逐层计算任意两个filters的相关系数,系数越趋近于0,则越重要,越趋近于|1|,则越相关,越不重要,每层抽取N个最不重要的filter对,构成第t次迭代剪枝的episode St,在optimization阶段,损失函数加入正则化项:
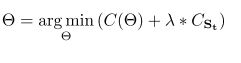
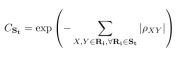
Cst为正则化项,用于提高St中filtre对的相关系数,从而减少剪枝以后的信息损失。Cst的表达式如上右式。当cst减小时,相关系数增大,重要性降低
上图可以进行迭代式剪枝,重点本文指出,本方法可以结合与其他的重要性方法一起使用。
19、cop:custonized deep model compression via regularized correlation-based filter-level pruning
提出剪特征图本身也就是剪过滤器,文章认为一些filters的激活值可以被其他filters所代替,进而feature_map也可以被其他feature_map所替代,产生的feature_map之间存在一个线性关系,进一步的,权重之间也存在线性关系,因此,使用feature_map相关性来进行prune,相关性计算如下式:

20、to filter prune or to layer prune, that is the question
文章提出剪枝方法对延迟度量的影响,似乎没有提到具体的剪枝layer方法,只是将各种方法用剪枝layer进行了比较延迟时间度量。
21、variational convolutional neural etwork pruning
提出一种基于变分贝叶斯的方案用于channels级别的剪枝。Idea来源是基于确定性值的剪枝方法是不确定且不稳定的,引入新的评估因子channel saliency(通道显著性),指出基于BN层的尺度因子的剪枝方法是考虑不完善的,因为只考虑到了尺度因子,没有考虑到平移因子,则文章将bn层的计算进行变形,xout=r*bn(x)+b1变形为
Xout= r*(bn(x) + b2),则此时的r可以代表本层的一个重要性因子channel saliency。
且此时不是根据r的值,而是根据r的分布来做,通过变分推断,可以得到channel-salientyr是一个高斯分布,利用高斯分布的中心性,样本分布在期望值附近,当期值接近于0且方差很小时,变量r的概率也接近于0,基于此思想,当某一个通道的(均值、方差)<(0.02, 0.01)超参数设定时,即可删去该冗余通道。