机器学习——子空间学习(PCA & LDA)
1. 引入:子空间学习与降维
什么是子空间学习?
- 子空间学习大意是指通过投影,实现高维特征向低维空间的映射,是一种经典的降维思想。绝大多数的维数约简(降维,投影)算法都算是子空间学习,如PCA、LDA、LPP、LLE等;
- 本文只介绍前两种维数约减算法,即主成分分析(PCA)和线性判别分析(LDA)。
什么是降维?什么情况下需要降维?
- 降维:寻找一组映射对样本进行重新表示(representation);
- 原样本: x = [ x 1 ; x 2 ; . . . ; x d ] ∈ R d x=[x_1;x_2;...;x_d]∈\mathbb{R}^d x=[x1;x2;...;xd]∈Rd;新表示: y = [ y 1 ; y 2 ; . . . ; y m ] ∈ R m ( m < d ) y=[y_1;y_2;...;y_m]∈\mathbb{R}^m(m
- 我们知道,样本空间是由样本的各个属性张成的空间,假设每个样本有 d d d个属性,则样本空间就是一个 d d d维空间, d d d维空间中的每个点就是一个样本的表示(representation);
- 降维就是学习一个从原样本空间到新样本空间(子空间,即维度小于 d d d,假设为 m m m维)的映射,使得新样本空间中每个点是一个样本的新的表示,也就是说,每个样本的表示从 d d d维向量简化为了 m m m维向量,这显然是一件好事。
需要降维的情况:如数据冗余。下图中前两列表达的是同一个意思,造成了数据冗余,对此,应当进行降维。
数据冗余的弊端?维度灾难!
- 增加计算机开销(存储空间、计算资源);
- 采样困难。

2. 主成分分析(PCA)
假设:映射 ϕ ( ⋅ ) \phi(·) ϕ(⋅)是线性映射,线性映射的实质就是定义了一个新坐标。
ϕ ( ⋅ ) : W T x = y ∈ R m , W = [ w 1 , w 2 , . . . , w m ] ∈ R d × m \phi(·):W^Tx=y∈\mathbb{R}^m,W=[w_1,w_2,...,w_m]∈\mathbb{R}^{d×m} ϕ(⋅):WTx=y∈Rm,W=[w1,w2,...,wm]∈Rd×m
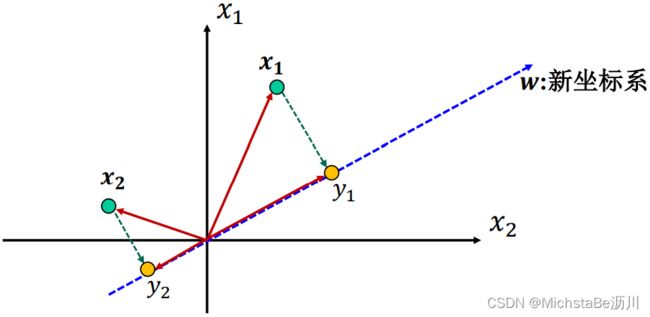
最大方差理论: 在信号处理中认为信号具有较大的方差,噪声有较小的方差。 即新坐标系上数据方差应越大越好。
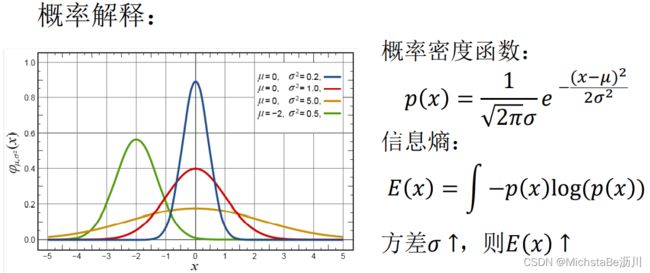
2.1 目标函数
在新坐标系下最大化数据新表征的方差: max w ∑ i = 1 n ( y i − y ˉ ) 2 , \max\limits_w\sum\limits_{i=1}^n(y_i-\bar{y})^2, wmaxi=1∑n(yi−yˉ)2, s.t. y i = w T x i , ∣ ∣ w ∣ ∣ = 1. \text{s.t.}\quad y_i=w^Tx_i,||w||=1. s.t.yi=wTxi,∣∣w∣∣=1.第二个约束条件是为了坐标系标准化。矩阵化表示: max W ∑ i = 1 n ∣ ∣ y i − y ˉ ∣ ∣ 2 , \max\limits_W\sum\limits_{i=1}^n||y_i-\bar{y}||^2, Wmaxi=1∑n∣∣yi−yˉ∣∣2, s.t. y i = W T x i , W T W = I . \text{s.t.}\quad y_i=W^Tx_i,W^TW=I. s.t.yi=WTxi,WTW=I.其中 W = [ w 1 , . . . , w m ] ∈ R d × m W=[w_1,...,w_m]∈\mathbb{R}^{d×m} W=[w1,...,wm]∈Rd×m,第二个约束条件保证坐标系为标准正交坐标系,也可表示为 ∣ ∣ w i ∣ ∣ = 1 , w i T w j = 0 ||w_i||=1,w_i^Tw_j=0 ∣∣wi∣∣=1,wiTwj=0。PCA降维的过程可以通过数据乘以矩阵来表示,因此是一个线性变换。
- 原样本: x = [ x 1 ; x 2 ; . . . ; x d ] ∈ R d x=[x_1;x_2;...;x_d]∈\mathbb{R}^d x=[x1;x2;...;xd]∈Rd
- 新表示: y = [ y 1 ; y 2 ; . . . ; y m ] ∈ R m ( m < d ) y=[y_1;y_2;...;y_m]∈\mathbb{R}^m(m
PCA的目标函数推导: f ( W ) = ∑ i = 1 n ∣ ∣ y i − y ˉ ∣ ∣ 2 = ∑ i = 1 n ( y i − y ˉ ) T ( y i − y ˉ ) = ∑ i = 1 n t r ( ( y i − y ˉ ) ( y i − y ˉ ) T ) f(W)=\sum\limits_{i=1}^n||y_i-\bar{y}||^2=\sum\limits_{i=1}^n(y_i-\bar{y})^T(y_i-\bar{y})=\sum\limits_{i=1}^ntr((y_i-\bar{y})(y_i-\bar{y})^T) f(W)=i=1∑n∣∣yi−yˉ∣∣2=i=1∑n(yi−yˉ)T(yi−yˉ)=i=1∑ntr((yi−yˉ)(yi−yˉ)T) = t r ( ∑ i = 1 n ( y i − y ˉ ) ( y i − y ˉ ) T ) = t r ( ∑ i = 1 n ( W T x i − W T x ˉ ) ( W T x i − W T x ˉ ) ) =tr(\sum\limits_{i=1}^n(y_i-\bar{y})(y_i-\bar{y})^T)=tr(\sum\limits_{i=1}^n(W^Tx_i-W^T\bar{x})(W^Tx_i-W^T\bar{x})) =tr(i=1∑n(yi−yˉ)(yi−yˉ)T)=tr(i=1∑n(WTxi−WTxˉ)(WTxi−WTxˉ)) = t r ( ∑ i = 1 n W T ( x i − x ˉ ) ( x i − x ˉ ) T W ) = t r ( W T ( ∑ i = 1 n ( x i − x ˉ ) ( x i − x ˉ ) T ) W ) =tr(\sum\limits_{i=1}^nW^T(x_i-\bar{x})(x_i-\bar{x})^TW)=tr(W^T(\sum\limits_{i=1}^n(x_i-\bar{x})(x_i-\bar{x})^T)W) =tr(i=1∑nWT(xi−xˉ)(xi−xˉ)TW)=tr(WT(i=1∑n(xi−xˉ)(xi−xˉ)T)W) = t r ( W T ( X − X ˉ ) ( X − X ˉ ) T W ) = t r ( W T ( n − 1 ) c o v ( X ) W ) =tr(W^T(X-\bar{X})(X-\bar{X})^TW)=tr(W^T(n-1)cov(X)W) =tr(WT(X−Xˉ)(X−Xˉ)TW)=tr(WT(n−1)cov(X)W)
综上,PCA的目标函数如下: f ( W ) = t r ( W T ( X − X ˉ ) ( X − X ˉ ) T W ) f(W)=tr(W^T(X-\bar{X})(X-\bar{X})^TW) f(W)=tr(WT(X−Xˉ)(X−Xˉ)TW)
2.2 问题求解
优化目标: max W t r ( W T ( X − X ˉ ) ( X − X ˉ ) T W ) , \max\limits_Wtr(W^T(X-\bar{X})(X-\bar{X})^TW), Wmaxtr(WT(X−Xˉ)(X−Xˉ)TW), s.t. W T W = I \text{s.t.}\quad W^TW=I s.t.WTW=I
采用拉格朗日乘子法,目标转化为: min W L ( W , λ ) = − t r ( W T ( X − X ˉ ) ( X − X ˉ ) T W ) + t r ( λ ( W T W − I ) ) \min\limits_Wℒ(W,\lambda)=-tr(W^T(X-\bar{X})(X-\bar{X})^TW)+tr(\lambda(W^TW-I)) WminL(W,λ)=−tr(WT(X−Xˉ)(X−Xˉ)TW)+tr(λ(WTW−I))令 ∂ L ∂ W = 0 \frac{\partial ℒ}{\partial W}=0 ∂W∂L=0,得: ( X − X ˉ ) ( X − X ˉ ) T W = λ W (X-\bar{X})(X-\bar{X})^TW=\lambda W (X−Xˉ)(X−Xˉ)TW=λW这是一个典型的特征值分解问题,即: C W = λ W , C = ( X − X ˉ ) ( X − X ˉ ) T CW=\lambda W,\quad C=(X-\bar{X})(X-\bar{X})^T CW=λW,C=(X−Xˉ)(X−Xˉ)T对 ( X − X ˉ ) ( X − X ˉ ) T (X-\bar{X})(X-\bar{X})^T (X−Xˉ)(X−Xˉ)T进行特征值分解得: ( X − X ˉ ) ( X − X ˉ ) T = V Λ V T (X-\bar{X})(X-\bar{X})^T=V\Lambda V^T (X−Xˉ)(X−Xˉ)T=VΛVT其中 Λ = d i a g ( λ 1 , λ 2 , . . . , λ d ) , V = [ v 1 , v 2 , . . . , v d ] \Lambda=diag(\lambda_1,\lambda_2,...,\lambda_d), V=[v_1,v_2,...,v_d] Λ=diag(λ1,λ2,...,λd),V=[v1,v2,...,vd],得到的 λ 1 , λ 2 , . . . , λ d \lambda_1, \lambda_2,...,\lambda_d λ1,λ2,...,λd就是 C C C的 d d d个特征值, V V V是特征值对应特征向量构成的矩阵。
注意: V V V的每一列代表一个特征向量。
我们对特征值进行排序,取前 m m m个最大特征值所对应的特征向量即组成了最优投影矩阵: W = [ v 1 , v 2 , . . . , v m ] W=[v_1,v_2,...,v_m] W=[v1,v2,...,vm]至此,我们就可以使用矩阵 W W W对数据进行投影降维了。
2.3 主成分解
- 第一主成分包含了样本方差的最大方向;
- 第二主成分与第一主成分不相关(夹角90度),包含了剩余样本方差的最大方向;
- 前几个主成分包含了样本的绝大部分信息,以至于可以忽略后面的主成分。
2.4 子空间、基和嵌入
- 投影矩阵 W = [ w 1 , . . . , w m ] W=[w_1,...,w_m] W=[w1,...,wm]是新的数据表征的坐标系集合,我们可以说 W W W在样本空间中张了一个子空间;
- 向量 w i w_i wi定义一个样本的主成分,也定义新坐标系中第 i i i个坐标轴,称为 W W W张成的子空间的一个基;
- y i = W T x i y_i=W^Tx_i yi=WTxi是样本 x i x_i xi在 W W W张成的子空间中的一个低维嵌入。
2.5 算法流程
- 样本中心化: A = X − X ˉ A=X-\bar{X} A=X−Xˉ,其中 X ˉ = [ x ˉ , x ˉ , . . . , x ˉ ] ∈ R d × n \bar{X}=[\bar{x},\bar{x},...,\bar{x}]∈\mathbb{R}^{d×n} Xˉ=[xˉ,xˉ,...,xˉ]∈Rd×n;
- 计算协方差矩阵: C = A A T = ( X − X ˉ ) ( X − X ˉ ) T C=AA^T=(X-\bar{X})(X-\bar{X})^T C=AAT=(X−Xˉ)(X−Xˉ)T;
- 特征值分解: C = V Λ V T C=V\Lambda V^T C=VΛVT
- 根据特征值选取特征向量构建投影矩阵: W = [ v 1 , v 2 , . . . , v m ] W=[v_1,v_2,...,v_m] W=[v1,v2,...,vm]
注意: W W W对应 V V V的前 m m m列!(前提:特征值已排序!)
- 输入原样本投影至新子空间完成降维: Y ~ = W T A \tilde{Y}=W^TA Y~=WTA
使用奇异值分解(SVD)后:
- 样本中心化: A = X − X ˉ A=X-\bar{X} A=X−Xˉ,其中 X ˉ = [ x ˉ , x ˉ , . . . , x ˉ ] ∈ R d × n \bar{X}=[\bar{x},\bar{x},...,\bar{x}]∈\mathbb{R}^{d×n} Xˉ=[xˉ,xˉ,...,xˉ]∈Rd×n;
- 奇异值分解: A = U Σ V T A=U\Sigma V^T A=UΣVT
- 根据奇异值选取奇异向量构建投影矩阵: W = [ u 1 , u 2 , . . . , u m ] W=[u_1,u_2,...,u_m] W=[u1,u2,...,um]
注意: W W W对应 U U U的前 m m m列!(前提:奇异值已排序!)
- 输入原样本投影至新子空间完成降维: Y ~ = W T A \tilde{Y}=W^TA Y~=WTA
问题: y y y的维度如何确定?
- 固定值(分类问题设为类别数目-1);
- 试错法(trial by error);
- 设定特征值比重的阈值: max m ∑ i = 1 m λ i / ∑ i = 1 d λ i ≥ h \max\limits_{m}\sum_{i=1}^m\lambda_i/\sum_{i=1}^d\lambda_i≥h mmax∑i=1mλi/∑i=1dλi≥h;
- 根据保留维度-精度的图像拐点(如下)。

2.6 小结
- 核心思想:寻找合适的正交投影矩阵 W W W,使得投影后的样本 Y = W T X Y=W^TX Y=WTX方差最大,也就是说在新的空间中保留的信息越多越好。
- 不足之处:存储、计算开销大;并未利用到监督信息。
如何改进?
-
减小存储、计算开销:奇异值分解(SVD)。 A = U Σ V T A=U\Sigma V^T A=UΣVT,其中 A ∈ R d × n , U ∈ R d × r , Σ ∈ R r × r , V ∈ R n × r A∈\mathbb{R}^{d×n},U∈\mathbb{R}^{d×r},\Sigma∈\mathbb{R}^{r×r},V∈\mathbb{R}^{n×r} A∈Rd×n,U∈Rd×r,Σ∈Rr×r,V∈Rn×r, U U U和 V V V都是正交矩阵, U U U中每个向量称为 A A A的左奇异向量, V V V中每个向量称为 A A A的右奇异向量,而 Σ \Sigma Σ是一个对角方阵,且 r r r等于 A A A的秩。(更多请看这篇:求分解后的 U , Σ , V U,\Sigma,V U,Σ,V三个矩阵的方法)
-
利用监督信息:线性判别分析(LDA)。
3. 线性判别分析(LDA)
费希尔准则(Fisher Criteria):同类样本应该尽量聚合在一起,而不同类样本之间应该尽量扩散。如下图,即使得红线尽可能短,蓝线尽可能长。
如何定义聚合程度和扩散程度?
其实方差就可以实现!方差大,既可以表示聚合程度小,也可以表示扩散程度大!
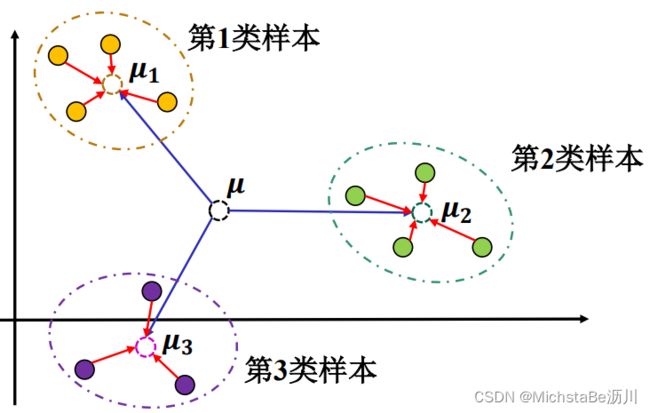
3.1 同类样本的聚合程度
一维情况下(方差): s w ( c ) = ∑ i ∈ c ( y i − μ c ) 2 s_w(c)=\sum\limits_{i∈c}(y_i-\mu_c)^2 sw(c)=i∈c∑(yi−μc)2其中 c ∈ [ 1 , . . . , c , . . . , C ] c∈[1,...,c,...,C] c∈[1,...,c,...,C],共 C C C个类, μ c = 1 n c ∑ i ∈ c y i \mu_c=\frac{1}{n_c}\sum\limits_{i∈c}y_i μc=nc1i∈c∑yi是 c c c类样本的中心。
多维情况下(协方差矩阵): s w ( c ) = t r ( ∑ i ∈ c ( y i − μ c ) ( y i − μ c ) T ) s_w(c)=tr(\sum\limits_{i∈c}(y_i-\mu_c)(y_i-\mu_c)^T) sw(c)=tr(i∈c∑(yi−μc)(yi−μc)T)
3.2 类别之间的扩散程度
s b = ∑ c = 1 C t r ( ( μ c − μ ) ( μ c − μ ) T ) s_b=\sum\limits_{c=1}^Ctr((\mu_c-\mu)(\mu_c-\mu)^T) sb=c=1∑Ctr((μc−μ)(μc−μ)T)其中 μ c = 1 n c ∑ i ∈ c y i \mu_c=\frac{1}{n_c}\sum\limits_{i∈c}y_i μc=nc1i∈c∑yi是 c c c类样本中心, μ = 1 n ∑ i y i \mu=\frac{1}{n}\sum\limits_iy_i μ=n1i∑yi是总样本中心。
3.3 目标函数
根据费希尔准则, y y y在一个理想的坐标系下应当满足: ∀ c , s w ( c ) ↓ , s b ↑ \forall c,s_w(c)↓,s_b↑ ∀c,sw(c)↓,sb↑故目标函数构建如下: min ∑ c s w ( c ) s b \min \frac{\sum_cs_w(c)}{s_b} minsb∑csw(c)假设低维嵌入 y y y由 x x x通过投影矩阵 W W W投影到LDA子空间,即: y = W T x , y ∈ R m × 1 , x ∈ R d × 1 , W ∈ R d × m y=W^Tx,\quad y∈\mathbb{R}^{m×1}, x∈\mathbb{R}^{d×1}, W∈\mathbb{R}^{d×m} y=WTx,y∈Rm×1,x∈Rd×1,W∈Rd×m则目标函数变为: min W t r ( W T S w W W T S b W ) \min_W tr(\frac{W^TS_wW}{W^TS_bW}) Wmintr(WTSbWWTSwW)该目标函数是 S w S_w Sw和 S b S_b Sb的广义瑞利商。其中类内散度矩阵 S w S_w Sw和类间散度矩阵 S b S_b Sb定义如下: S w = ∑ c = 1 C ∑ i ∈ c ( x i − x ˉ c ) ( x i − x ˉ c ) T ∈ R d × d S_w=\sum\limits_{c=1}^C\sum\limits_{i∈c}(x_i-\bar{x}_c)(x_i-\bar{x}_c)^T∈\mathbb{R}^{d×d} Sw=c=1∑Ci∈c∑(xi−xˉc)(xi−xˉc)T∈Rd×d S b = ∑ c = 1 C n c ( x ˉ c − x ˉ ) ( x ˉ c − x ˉ ) T ∈ R d × d S_b=\sum\limits_{c=1}^Cn_c(\bar{x}_c-\bar{x})(\bar{x}_c-\bar{x})^T∈\mathbb{R}^{d×d} Sb=c=1∑Cnc(xˉc−xˉ)(xˉc−xˉ)T∈Rd×d该目标函数的最优解有无穷多个,因为可以对 W W W进行任意缩放。所以,我们可以认为该问题等价于: min W t r ( W T S w W ) , s.t. , W T S b W = I \min_Wtr(W^TS_wW),\quad \text{s.t.},W^TS_bW=I Wmintr(WTSwW),s.t.,WTSbW=I
3.4 问题求解
在PCA中已求解过类似问题,即构造拉格朗日函数求偏导,得到一个典型的特征值分解问题,故此处不再详述。
构造构造拉格朗日函数,并求偏导得到: S b − 1 S w W = λ W S_b^{-1}S_wW=\lambda W Sb−1SwW=λW同理,这也是一个特征值分解问题。
3.5 算法流程
- 计算各类样本中心和所有样本中心: μ c = 1 n c ∑ i ∈ c y i , μ = 1 n ∑ i y i \mu_c=\frac{1}{n_c}\sum\limits_{i∈c}y_i,\quad\mu=\frac{1}{n}\sum\limits_iy_i μc=nc1i∈c∑yi,μ=n1i∑yi
- 计算类间散度矩阵和类内散度矩阵: S w = ∑ c = 1 C ∑ i ∈ c ( x i − x ˉ c ) ( x i − x ˉ c ) T ∈ R d × d S_w=\sum\limits_{c=1}^C\sum\limits_{i∈c}(x_i-\bar{x}_c)(x_i-\bar{x}_c)^T∈\mathbb{R}^{d×d} Sw=c=1∑Ci∈c∑(xi−xˉc)(xi−xˉc)T∈Rd×d S b = ∑ c = 1 C n c ( x ˉ c − x ˉ ) ( x ˉ c − x ˉ ) T ∈ R d × d S_b=\sum\limits_{c=1}^Cn_c(\bar{x}_c-\bar{x})(\bar{x}_c-\bar{x})^T∈\mathbb{R}^{d×d} Sb=c=1∑Cnc(xˉc−xˉ)(xˉc−xˉ)T∈Rd×d
- 特征值分解: S b − 1 S w W = λ W S_b^{-1}S_wW=\lambda W Sb−1SwW=λW;
- 根据特征值选取特征向量构建投影矩阵: W = [ v 1 , v 2 , . . . , v m ] W=[v_1,v_2,...,v_m] W=[v1,v2,...,vm];
- 输入原样本投影至新子空间完成降维: Y = W T X Y=W^TX Y=WTX
3.6 PCA vs LDA
思想上:
- PCA旨在寻找一组子坐标系(定义一个子空间)使得样本点的方差最大,即信息量保留最多;
- LDA旨在寻找一组子坐标系(定义一个子空间)使得样本点类内散度小,类间散度大(费希尔准则)。
监督性:
- PCA是无监督学习方法;
- LDA是有监督学习方法。
子空间学习(subspace learning)角度:
- 两者都属于线性子空间学习算法,因为都在样本空间定义了一个新的子坐标系(子空间),每个列向量定义了一个坐标轴;
- 目标都是学习一个投影矩阵 W W W,使得样本在新坐标系上的表示具有相应特性;
降维(dimension reduction)角度:
- 两者都有降维的效果,坐标轴数目减少,维度减少。
特征提取(feature extraction)角度:
- 两者都起到了特征提取的作用,样本在新坐标系下的坐标就相当于样本的新特征(表征、表示)。
效率:PCA效率好于LDA。
4. 子空间学习的核化
想想:如果样本分布不是线性的,怎么办?
思路:把样本利用非线性映射投射到更高的维度(一般来说),使得在高维非线性空间,可以使用线性子空间学习进行数据分析。

然而,对于任意给定数据寻找合适的非线性映射 ϕ \phi ϕ是不现实的。
回顾一下,在支持向量机这篇文章中,我曾介绍过核方法(kernel trick),也就是我们定义核函数 κ ( x i , x j ) = ϕ ( x i ) T ϕ ( x j ) \kappa(x_i,x_j)=\phi(x_i)^T\phi(x_j) κ(xi,xj)=ϕ(xi)Tϕ(xj),使得 ϕ \phi ϕ可以隐式地由核函数表示出来。只要满足Mercer条件(即核矩阵对称半正定)的函数就是核函数,因此核函数很容易找到,并且有了核函数后,内积的计算也变得十分方便。链接中的文章也介绍了常见的核函数。
在此,我们以PCA和LDA为例,对子空间学习进行核化。
