import pandas as pd
import numpy as np
df = pd.read_csv('../data/LoanStats3a.csv', skiprows = 1, low_memory = False)
df.drop('id', 1, inplace = True)
df.drop('member_id', 1, inplace = True)
df.term.replace(to_replace= '[^0-9]+', value = '', inplace = True, regex = True)
df.term.astype(float)
df.int_rate.replace('%', '', inplace = True)
df.drop(['sub_grade','emp_title'], 1, inplace = True)
df.emp_length.replace('n/a', np.nan , inplace = True)
df.emp_length.replace(to_replace='[^0-9]+', value = '',\
inplace = True, regex = True)
df.dropna(1, how = 'all', inplace = True)
df.dropna(0, how = 'all', inplace = True)
df.drop(['mths_since_last_record','next_pymnt_d','debt_settlement_flag_date','settlement_status',\
'settlement_date','settlement_amount','settlement_percentage','settlement_term',],\
1, inplace = True)
for col in df.select_dtypes(include = ['float']).columns:
df.drop(['collections_12_mths_ex_med','policy_code','acc_now_delinq','chargeoff_within_12_mths',\
'delinq_amnt','pub_rec_bankruptcies','tax_liens','total_acc','out_prncp','out_prncp_inv',\
'delinq_2yrs','inq_last_6mths','mths_since_last_delinq','open_acc','pub_rec',],\
1, inplace = True)
print('===========================================================')
for col in df.select_dtypes(include = ['object']).columns:
df.drop(['term','int_rate','grade','emp_length','home_ownership','verification_status','issue_d','desc',\
'pymnt_plan','purpose','zip_code','addr_state','earliest_cr_line','initial_list_status',\
'last_pymnt_d','last_credit_pull_d','application_type','hardship_flag','disbursement_method','debt_settlement_flag',],\
1, inplace = True)
df.loan_status.replace('Fully Paid', int(1), inplace = True)
df.loan_status.replace('Charged Off', int(0), inplace = True)
df.loan_status.replace('Does not meet the credit policy. Status:Fully Paid', np.nan, inplace = True)
df.loan_status.replace('Does not meet the credit policy. Status:Charged Off', np.nan, inplace = True)
df.dropna(subset = ['loan_status'],inplace = True)
df.drop('title', 1, inplace = True)
df.fillna(0, inplace = True)
df.fillna(0.0, inplace = True)
df.drop(['loan_amnt','funded_amnt','total_pymnt'], 1 ,inplace = True)
cor = df.corr()
cor.loc[:,:] = np.tril(cor, k=-1)
cor = cor.stack()
print(cor[(cor>0.55) | (cor < -0.55)])
df = pd.get_dummies(df)
df.to_csv('../data/feature02.csv')
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.linear_model.logistic import LogisticRegression
from sklearn import metrics
from sklearn.ensemble.forest import RandomForestClassifier
from sklearn.ensemble import GradientBoostingClassifier
from sklearn import svm
import time
from sklearn.model_selection import GridSearchCV
import matplotlib as mpl
import matplotlib.pyplot as plt
import numpy as np
df = pd.read_csv('../data/feature02.csv')
Y = df.loan_status
X = df.drop('loan_status', 1, inplace = False)
x_train, x_test, y_train, y_test = train_test_split(X, Y, test_size = 0.3, random_state = 0)
lr = LogisticRegression()
start= time.time()
lr.fit(x_train, y_train)
train_predict = lr.predict(x_train)
train_f1 = metrics.f1_score(train_predict, y_train)
train_acc = metrics.accuracy_score(train_predict, y_train)
train_rec = metrics.recall_score(train_predict, y_train)
print("逻辑回归模型上的效果入下:")
print("在训练集上f1_mean的值为%.4f" % train_f1, end=' ')
print("在训练集上的精确率的值为%.4f" % train_acc, end=' ')
print("在训练集上的查全率的值为%.4f" % train_rec)
test_predict = lr.predict(x_test)
test_f1 = metrics.f1_score(test_predict, y_test)
test_acc = metrics.accuracy_score(test_predict, y_test)
test_rec = metrics.recall_score(test_predict, y_test)
print("在测试集上f1_mean的值为%.4f" % test_f1, end = ' ')
print("在训练集上的精确率的值为%.4f" % test_acc, end=' ')
print("在训练集上的查全率的值为%.4f" % test_rec)
end = time.time()
print(end-start)
print("随机森林效果如下" + "=" * 30)
rf = RandomForestClassifier()
start = time.time()
rf.fit(x_train, y_train)
train_predict = rf.predict(x_train)
train_f1 = metrics.f1_score(train_predict, y_train)
train_acc = metrics.accuracy_score(train_predict, y_train)
train_rec = metrics.recall_score(train_predict, y_train)
print("在训练集上f1_mean的值为%.4f" % train_f1, end=' ')
print("在训练集上的精确率的值为%.4f" % train_acc, end=' ')
print("在训练集上的查全率的值为%.4f" % train_rec)
test_predict = rf.predict(x_test)
test_f1 = metrics.f1_score(test_predict, y_test)
test_acc = metrics.accuracy_score(test_predict, y_test)
test_rec = metrics.recall_score(test_predict, y_test)
print("在测试集上f1_mean的值为%.4f" % test_f1, end = ' ')
print("在训练集上的精确率的值为%.4f" % test_acc, end=' ')
print("在训练集上的查全率的值为%.4f" % test_rec)
end = time.time()
print(end - start)
print("GBDT上效果如下" + "=" * 30)
gb = GradientBoostingClassifier()
start = time.time()
gb.fit(x_train, y_train)
train_predict = gb.predict(x_train)
train_f1 = metrics.f1_score(train_predict, y_train)
train_acc = metrics.accuracy_score(train_predict, y_train)
train_rec = metrics.recall_score(train_predict, y_train)
print("在训练集上f1_mean的值为%.4f" % train_f1, end=' ')
print("在训练集上的精确率的值为%.4f" % train_acc, end=' ')
print("在训练集上的查全率的值为%.4f" % train_rec)
test_predict = gb.predict(x_test)
test_f1 = metrics.f1_score(test_predict, y_test)
test_acc = metrics.accuracy_score(test_predict, y_test)
test_rec = metrics.recall_score(test_predict, y_test)
print("在测试集上f1_mean的值为%.4f" % test_f1, end = ' ')
print("在训练集上的精确率的值为%.4f" % test_acc, end=' ')
print("在训练集上的查全率的值为%.4f" % test_rec)
end = time.time()
print(end-start)
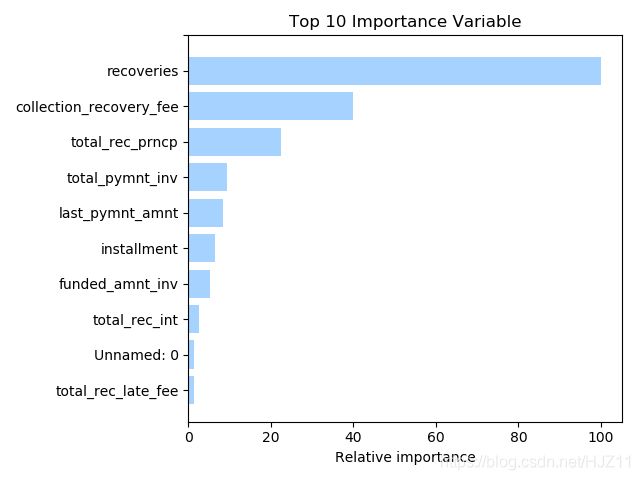
feature_importance = rf.feature_importances_
feature_importance = 100.0*(feature_importance/feature_importance.max())
index = np.argsort(feature_importance)[-10:]
plt.barh(np.arange(10), feature_importance[index], color = 'dodgerblue', alpha = 0.4)
print(np.array(X.columns)[index])
plt.yticks(np.arange(10+0.25), np.array(X.columns)[index])
plt.xlabel('Relative importance')
plt.title('Top 10 Importance Variable')
plt.show()