计算机视觉 什么是计算机视觉
1、什么是计算机视觉?
作为人类,我们可以轻松地感知周围世界的三维结构。想想当你看着坐在你旁边桌子上的花瓶时,三维感知是多么生动。您可以通过在其表面上播放的微妙的光影图案来分辨每个花瓣的形状和半透明度,并毫不费力地将每朵花从场景的背景中分割出来(图1)。
 图1:人类视觉系统可以毫无问题地解释这张照片中半透明和阴影的细微变化,并正确地从背景中分割出物体。
图1:人类视觉系统可以毫无问题地解释这张照片中半透明和阴影的细微变化,并正确地从背景中分割出物体。
看着相框的集体肖像,您可以轻松地计算和命名照片中的所有人,甚至猜测从他们的面部表情中了解他们的情绪(图2-a )。
 图2:计算机视觉算法和应用的一些例子。
图2:计算机视觉算法和应用的一些例子。
(a) 面部检测算法与基于颜色的服装和头发检测算法相结合,可以定位和识别该图像中的个人
(b) 对象实例分割可以描绘复杂场景中的每个人和对象
(c) 运动算法的结构可以从数百张部分重叠的照片中重建大型复杂场景的稀疏 3D 点模型
(d) 立体匹配算法可以根据从互联网上拍摄的数百张不同曝光的照片构建建筑立面的详细 3D 模型
知觉心理学家花了几十年的时间试图理解视觉系统是如何工作的,尽管他们可以设计视错觉来梳理它的一些原理(图3),但这个难题的完整解决方案仍然难以捉摸。
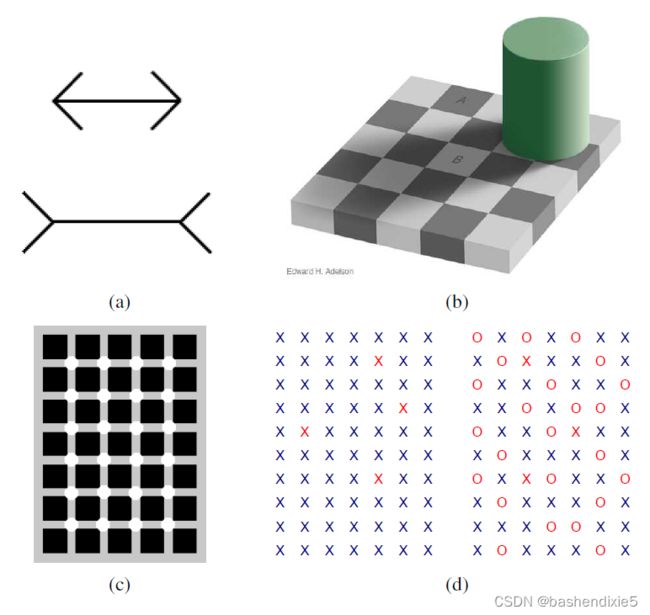 图3:一些常见的视错觉以及它们可能会告诉我们有关视觉系统的信息
图3:一些常见的视错觉以及它们可能会告诉我们有关视觉系统的信息
(a) 经典的 Müller-Lyer 错觉,两条水平线的长度看起来不同,可能是由于想象的透视效果。
(b) 阴影中的“白”方块和光照中的“黑”方块 A 实际上具有相同的绝对强度值。 这种感觉是由于亮度恒定性,视觉系统在解释颜色时试图减少照明。
(c) 赫尔曼网格错觉的一种变体。当您将视线移到图形上时,交叉点处会出现灰点。
(d) 数图左半边的红色 X。 现在把它们算在右半边。 是不是更难了? 解释与弹出效应有关,它告诉我们大脑中平行感知和整合路径的操作。
计算机视觉领域的研究人员一直在同时开发用于恢复图像中物体的3D形状和外观的数学技术。在这方面,过去 20 年的进展非常迅速。我们现在拥有可靠的技术,可以从数千张部分重叠的照片中准确计算环境的3D模型(图2-c)。给定足够多的特定对象或立面视图集,我们可以使用立体匹配创建精确的密集 3D 表面模型(图2-d)。我们甚至可以在一定程度上成功地描绘出照片中的大部分人和物体(图2-a)。然而,尽管取得了所有这些进步,让计算机以与两岁儿童相同的细节和因果关系水平解释图像的梦想仍然难以实现。
为什么视觉这么难?部分原因是它是一个逆问题,在该问题中,我们试图在没有足够信息来完全指定解决方案的情况下恢复一些未知数。因此,我们必须求助于基于物理的概率模型,或从大量示例中进行机器学习,以消除潜在解决方案之间的歧义。然而,对具有丰富复杂性的视觉世界进行建模比对产生语音的声道进行建模要困难得多。
我们在计算机视觉中使用的前向模型通常是在物理学(辐射测量、光学和传感器设计)和计算机图形学中开发的。这两个领域都模拟物体如何移动和动画,光如何从其表面反射,如何被大气散射,通过相机镜头(或人眼)折射,最后投影到平面(或弯曲)图像平面上。虽然计算机图形学尚不完美,但在许多领域,例如渲染由日常物品组成的静止场景或为恐龙等灭绝生物制作动画,都已经相对比较成熟。
在计算机视觉中,我们试图做相反的事情,即描述我们在一幅或多幅图像中看到的世界,并重建其属性,例如形状、光照和颜色分布。令人惊讶的是,人类和动物如此轻松地做到这一点,而计算机视觉算法却如此容易出错。没有在该领域工作过的人往往会低估问题的难度。这种认为视觉应该很容易的误解可以追溯到人工智能的早期,当时人们最初认为智能的认知(逻辑证明和计划)部分本质上比感知部分更难。
2、计算机视觉的应用
好消息是,计算机视觉如今已被广泛用于现实世界的各种应用中,其中包括:
1、光学字符识别(OCR):读取字母上的手写邮政编码(图4-a)和自动车牌识别(ANPR)
2、机器检测:使用立体视觉进行快速零件检测以确保质量,并使用专门的照明来测量飞机机翼或车身零件的公差(图4-b)或使用 X 射线视觉寻找铸钢件中的缺陷;
3、零售:自动结账通道和全自动商店的对象识别;
4、仓库物流:自动包裹递送和托盘搬运“驱动器”和机器人机械手拣选零件(图4-c)
5、医学成像:记录术前和术中图像(图4-d)或对随着年龄增长的人的大脑形态进行长期研究
6、自动驾驶汽车:能够在城市之间进行点对点驾驶(图4-e)以及自动驾驶飞行
7、3D 模型构建(摄影测量):从航拍和无人机照片中全自动构建 3D 模型(图4-f)
 图4:计算机视觉的一些工业应用。
图4:计算机视觉的一些工业应用。
(a)光学字符识别(OCR)
(b) 机械检查
(c) 仓库拣货
(d) 医学成像
(e) 自动驾驶汽车
(f) 基于无人机的摄影测量
8、匹配移动:通过跟踪源视频中的特征点,将计算机生成的图像 (CGI) 与实景镜头合并,以估计 3D 摄像机运动和环境形状。 这种技术在好莱坞被广泛使用,例如,在侏罗纪公园等电影中; 它们还需要使用精确的抠图在前景和背景元素之间插入新元素。
9、动作捕捉(mocap):使用从多个摄像机或其他基于视觉的技术观察到的反射标记来捕捉计算机动画的演员
10、监控:监控入侵者、分析高速公路交通和监控溺水受害者池
11、指纹识别和生物识别:用于自动访问认证以及取证应用。
David Lowe 的工业视觉应用网站 (http://www.cs.ubc.ca/spider/lowe/vision.html) 列出了许多其他有趣的计算机视觉工业应用。 尽管上述应用程序都非常重要,它们大多属于相当专业的各种图像和狭窄的领域。
除了所有这些工业应用之外,还有无数的消费级应用,例如您可以用自己的个人照片和视频做的事情。 这些包括:
拼接:将重叠的照片变成一个无缝拼接的全景图(图5-a)
包围曝光:将在具有挑战性的光照条件(强烈的阳光和阴影)下进行的多次曝光合并成一个完美曝光的图像(图5-b)
变形:使用无缝变形转换(图5-c)将您的一个朋友的照片变成另一张照片;
3D 建模:将一个或多个快照转换为您正在拍摄的对象或人的 3D 模型(图5-d)
视频匹配移动和稳定:通过自动跟踪附近的参考点或使用运动估计来消除视频中的抖动,将 2D 图片或 3D 模型插入到您的视频中;
基于照片的虚拟漫游:通过在不同的 3D 照片之间切换来浏览大量照片,例如您的房屋内部
人脸检测:用于改进相机对焦以及更相关的图像搜索
视觉验证:当家庭成员坐在网络摄像头前时,自动将他们登录到您的家庭计算机上
 图5:计算机视觉的一些消费者应用:
图5:计算机视觉的一些消费者应用:
(a) 图像拼接:合并不同的视图
(b) 曝光包围:合并不同的曝光;
(c) 变形:两张照片之间的混合
(d) 显示实时深度遮挡效果的智能手机增强现实
这些应用程序是可以立即欣赏并与他们自己的个人媒体一起使用的技术。 由于计算机视觉是一个具有挑战性的主题,考虑到所涉及的学科范围广泛(这些技术包括数学、物理学、欧几里得几何和射影几何、统计和优化。 它们使计算机视觉成为一个引人入胜的研究领域,也是学习广泛适用于其他领域的技术的好方法。)以及所解决问题的内在难度,因此解决有趣且相关的问题可能会非常激励和鼓舞人心。
3、如何解决计算机视觉问题?
如何解决计算机视觉问题?首先,提出了一个详细的问题定义,并决定了问题的约束和规范。 然后,我尝试找出哪些技术是已知的,实施其中的一些,评估它们的性能,最后做出选择。 为了使这个过程起作用,重要的是要有真实的测试数据,包括合成的,可用于验证正确性和分析噪声敏感性,以及系统最终使用方式的典型真实世界数据。 如果使用机器学习,更重要的是要有足够数量的具有代表性的无偏训练数据,以便在现实世界的输入中获得良好的结果。这种从问题到解决方案的工作是视觉研究的典型工程方法。
然而,计算机视觉不仅仅是一门工程。它还需要对基本的是视觉问题有深刻的了解,并会对其采取科学的方法。 比如场景是如何创建的,光如何与场景和大气效应相互作用,以及传感器如何工作,包括噪声源和不确定性。 然后的任务是尝试反转采集过程,以提出对场景的最佳描述。
统计学方法经常用来制定和解决计算机视觉问题。在适当的情况下,概率分布用于模拟场景和噪声图像采集过程。先验分布与未知数的关联通常称为贝叶斯建模。可以将风险或损失函数与错误估计的答案相关联,并设置您的推理算法以最小化预期风险。(考虑一个机器人试图估计到障碍物的距离:低估通常比高估更安全。)使用统计技术,它通常有助于收集大量训练数据来学习概率模型。最后,统计方法使您能够使用经过验证的推理技术来估计最佳答案(或答案的分布)并量化结果估计中的不确定性。
因为很多计算机视觉都涉及逆问题的解决或未知量的估计,所以算法也十分重要,尤其是那些已知在实践中运行良好的算法。对于许多视觉问题,很容易提出问题的数学描述,但该描述要么不符合现实的现实世界条件,要么不适合对未知数的稳定估计。我们需要对噪声和模型偏差具有鲁棒性并且在运行时资源和空间方面具有合理效率的算法。比如在适用的情况下使用贝叶斯技术来确保稳健性,并使用高效搜索、最小化和线性系统求解算法来确保效率。
4、计算机视觉的历史
简要介绍过去50年来计算机视觉的主要发展(图6),重点介绍了有趣且经受住时间考验的进展。
 计算机视觉中一些最活跃的研究主题的粗略时间表。
计算机视觉中一些最活跃的研究主题的粗略时间表。
(1)1970年
当计算机视觉在 1970 年代初首次出现时,它被视为一项雄心勃勃的计划中的视觉感知组件,旨在模仿人类智能并赋予机器人智能行为。 当时,一些人工智能和机器人技术的早期先驱(在麻省理工学院、斯坦福大学和 CMU 等地)认为,解决“视觉输入”问题将是解决更困难问题的简单步骤,例如作为更高层次的推理和计划。根据一个众所周知的故事,1966 年,麻省理工学院的 Marvin Minsky要求他的本科生将相机连接到计算机,并让计算机描述它所看到的。 我们现在知道这个问题比这稍微困难一些。
计算机视觉与现有的数字图像处理领域的区别在于希望从图像中恢复世界的三维结构,并将其用作通向全场景理解的垫脚石。
场景理解的早期尝试涉及提取边缘,然后从 2D 线的拓扑结构中推断出对象或“块世界”的 3D 结构。 当时开发了几种线标记算法(图7-a)。边缘检测的主题也是一个活跃的研究领域。
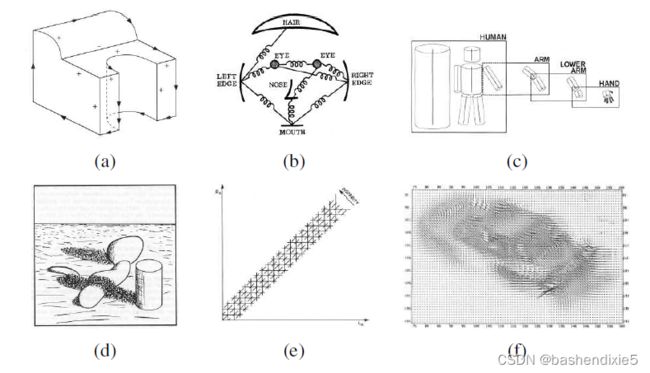 图7: 计算机视觉算法的一些早期(1970 年代)示例:(a)线标记(b)图形结构(c)铰接体模型(d)内在图像(e)立体对应(f)光流
图7: 计算机视觉算法的一些早期(1970 年代)示例:(a)线标记(b)图形结构(c)铰接体模型(d)内在图像(e)立体对应(f)光流
非多面体对象的三维建模也在研究中。 一种流行的方法使用广义圆柱体,即旋转固体和扫掠闭合曲线,通常排列成部分关系(图7-c)。将这种零件的弹性排列称为图形结构(图7-b)。
Barrow 和 Tenenbaum(1981 年)在他们关于内在图像的论文(图7-d)中倡导了一种理解强度和阴影变化并通过图像形成现象(例如表面方向和阴影)的影响来解释它们的定性方法。 当时还开发了更多的计算机视觉定量方法,包括许多基于特征的立体对应算法中的第一个(图7-e)和基于强度的光流算法(图7-f)。 同时恢复 3D 结构和相机运动的早期工作也是在这个时候开始的。
David Marr (1982) 的书中总结了当时人们认为视觉如何工作的许多哲学。Marr 介绍了他对(视觉)信息处理系统的三个层次描述的概念。 这三个级别非常松散地解释为:
• 计算理论:计算(任务)的目标是什么?已知的或可以对问题施加的约束是什么?
• 表示和算法:输入、输出和中间信息是如何表示的,哪些算法用于计算期望的结果?
• 硬件实现:表示和算法如何映射到实际硬件,例如生物视觉系统或专用硅片?反过来,如何使用硬件约束来指导表示和算法的选择? 随着图形芯片 (GPU) 和多核架构在计算机视觉中的普遍使用,这个问题再次变得非常相关。
(2)1980年
在 1980 年代,很多注意力都集中在用于执行定量图像和场景分析的更复杂的数学技术上。图像金字塔开始被广泛用于执行诸如图像混合(图8-a)和从粗到细的对应搜索等任务。 还开发了使用尺度空间处理概念的金字塔的连续版本。 在1980年代后期,小波开始在某些应用中取代或增强常规图像金字塔。
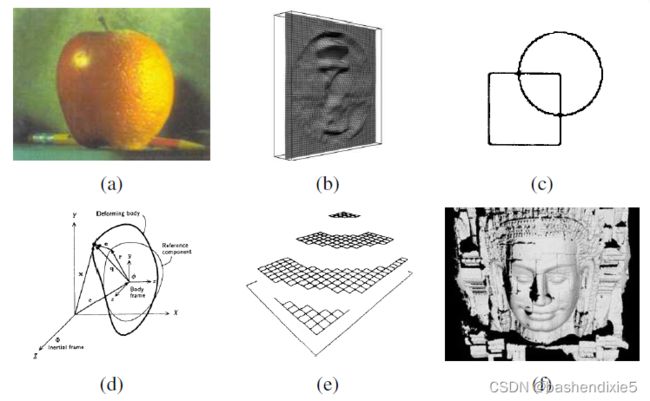 图8:1980 年代的计算机视觉算法示例:(a) 金字塔混合 (b) 阴影形状 (c) 边缘检测 (d) 基于物理的模型 (e) 基于正则化的表面重建 (f) 范围数据采集和合并
图8:1980 年代的计算机视觉算法示例:(a) 金字塔混合 (b) 阴影形状 (c) 边缘检测 (d) 基于物理的模型 (e) 基于正则化的表面重建 (f) 范围数据采集和合并
立体作为定量形状提示的使用通过各种各样的 shapefrom-X 技术得到扩展,包括阴影形状(图8-b),光度立体,从纹理中塑造形状,以及从焦点塑造形状。
在此期间,对更好的边缘和轮廓检测(图8-c)的研究也很活跃(Canny 1986;Nalwa 和 Binford 1986),包括引入动态演化的轮廓跟踪器,例如snakes以及基于物理的三维模型(图8-d)。
研究人员注意到,如果将许多立体、流动、X 形状和边缘检测算法统一起来,或者至少可以使用相同的数学框架进行描述,如果它们被提出为变分优化问题并变得更加鲁棒(适定) 使用正则化(图8-e)。 大约在同一时间,Geman 和 Geman (1984) 指出,此类问题同样可以使用离散马尔可夫随机场 (MRF) 模型来表述,这使得能够使用更好的(全局)搜索和优化算法,例如模拟退火。
使用卡尔曼滤波器对不确定性进行建模和更新的 MRF 算法的在线变体。还尝试将正则化算法和 MRF 算法映射到并行硬件上。 Fischler 和 Firschein(1987 年)的这本书包含了一系列专注于所有这些主题(立体、流动、正则化、MRF 甚至更高层次的视觉)的文章。
在这十年中,三维范围数据处理(采集、合并、建模和识别;见图8-f)继续得到积极探索。
(3)1990年
虽然前面提到的许多主题仍在继续探索,但其中一些主题变得更加活跃。
使用射影不变量进行识别的大量活动演变为从运动问题中解决结构的协同努力。许多最初的活动是针对投影重建,这不需要相机校准知识。同时,分解技术被开发来有效解决正交相机近似适用的问题(图9-a),然后扩展到透视情况。最终,该领域开始使用全全局优化,后来被认为与传统摄影测量中使用的束平差技术相同。使用这些技术构建了全自动 3D 建模系统。
 图9:1990 年代的计算机视觉算法示例:(a) 基于运动的分解结构 (b) 密集立体匹配 (c) 多视图重建 (d) 人脸跟踪 (e) 图像分割 (f) 人脸识别
图9:1990 年代的计算机视觉算法示例:(a) 基于运动的分解结构 (b) 密集立体匹配 (c) 多视图重建 (d) 人脸跟踪 (e) 图像分割 (f) 人脸识别
1980 年代开始使用对颜色和强度的详细测量以及辐射传输和彩色图像形成的精确物理模型开始的工作创建了自己的子领域,称为基于物理的视觉。
光流方法继续得到改进。 同样,密集立体对应算法也取得了很大进展,最大的突破可能是使用图切割技术进行全局优化(图9-b))。
产生完整3D表面的多视图立体算法(图9-c)也是一个活跃的研究主题,今天仍然很活跃。 从二进制轮廓生成 3D 体积描述的技术继续得到发展,以及基于跟踪和重建平滑遮挡轮廓的技术。
跟踪算法也有很大改进,包括使用活动轮廓的轮廓跟踪,例如snakes、粒子过滤器和水平集以及基于强度的(直接)技术,通常应用于跟踪面部(图9-d)和全身。
图像分割(图9-e),自计算机视觉早期以来一直很活跃的主题,也是一个活跃的研究课题,生产基于最小能量和最小描述长度、归一化分割和均值偏移的技术。
统计学习技术开始出现,首先是主成分特征面分析在人脸识别中的应用(图9-f)和用于曲线跟踪的线性动力系统。
也许这十年中计算机视觉最显着的发展是与计算机图形的交互增加,特别是在基于图像的建模和渲染的跨学科领域。直接操纵现实世界的图像以创建新动画的想法首先通过图像变形技术(图 5-c)而受到重视,后来被应用于视图插值、全景图像拼接(图5-a)和全光场渲染(图10-a)。同时,还引入了基于图像的建模技术(图10-b),用于从图像集合中自动创建逼真的 3D 模型。
(4)2000年
这十年继续加深视觉和图形领域之间的相互作用,但更重要的是,将数据驱动和学习方法作为视觉的核心组成部分。在基于图像的渲染的标题下介绍的许多主题,
 图10:2000 年代计算机视觉算法的示例:(a) 基于图像的渲染 (b) 基于图像的建模 (c) 交互式 色调映射 (d) 纹理合成 (e) 基于特征的识别 (f) 基于区域的识别
图10:2000 年代计算机视觉算法的示例:(a) 基于图像的渲染 (b) 基于图像的建模 (c) 交互式 色调映射 (d) 纹理合成 (e) 基于特征的识别 (f) 基于区域的识别
例如图像拼接、光场捕获和渲染以及通过曝光包围捕获的高动态范围 (HDR) 图像(图5-b)被重新命名为计算摄影,以承认这种技术在日常数码摄影中的使用越来越多。例如,曝光包围的迅速采用要创建高动态范围的图像,需要开发色调映射算法(图10-c),以将这些图像转换回可显示的结果。除了合并多重曝光之外,还开发了将闪光图像与非闪光图像合并的技术,并以交互方式或自动从重叠图像中选择不同区域。
纹理合成(图10-d)、绗缝和修复是附加主题这可以归类为计算摄影技术,因为它们重新组合输入图像样本以生成新照片。
这十年中的第二个显着趋势是出现了基于特征的技术(与学习相结合)用于对象识别。 该领域的一些著名论文包括 Fergus、Perona 和 Zisserman(2007 年)的星座模型(图10-e)和 Felzenszwalband Huttenlocher(2005 年)的图形结构。 基于特征的技术也主导其他识别任务,例如场景识别和全景和位置识别。 虽然兴趣点(基于补丁的)特征往往主导当前的研究,但一些团体正在追求基于轮廓的识别。
这十年的另一个重要趋势是针对复杂的全局优化问题开发更有效的算法。 虽然这一趋势始于图切割,但在消息传递算法方面也取得了很大进展,例如循环信念传播 (LBP)。
这十年中最显着的趋势,是将复杂的机器学习技术应用于计算机视觉问题,现在已经完全接管了视觉识别和计算机视觉的大多数方面。 这一趋势与互联网上大量部分标记数据的可用性增加以及计算能力的显着提高相吻合,这使得在不使用仔细的人工监督的情况下学习对象类别变得更加可行。
(5)2010年
使用大型标记(以及自我监督)数据集来开发机器学习算法的趋势成为一股浪潮,彻底改变了图像识别算法以及其他应用的发展,例如之前使用贝叶斯和全局优化技术的去噪和光流 .
这一趋势得益于高质量大规模注释数据集的发展,例如 ImageNet, Microsoft COCO和 LVIS。 这些数据集不仅为跟踪识别和语义分割算法的进展提供了可靠的指标,更重要的是,为开发基于机器学习的完整解决方案提供了足够的标记数据。
 图11:2010 年代计算机视觉算法示例:(a) 神经网络 (b) 对象实例分割 (c) 来自单个图像的全身、表情和手势拟合 (d) 使用 KinectFusion 实时系统融合多色深度图像 (e) 具有实时深度遮挡效果的智能手机增强现实 (f) 在全自动 Skydio R1 无人机上实时计算的 3D 地图。
图11:2010 年代计算机视觉算法示例:(a) 神经网络 (b) 对象实例分割 (c) 来自单个图像的全身、表情和手势拟合 (d) 使用 KinectFusion 实时系统融合多色深度图像 (e) 具有实时深度遮挡效果的智能手机增强现实 (f) 在全自动 Skydio R1 无人机上实时计算的 3D 地图。
另一个主要趋势是图形处理单元 (GPGPU) 上通用(数据并行)算法的开发可提供的计算能力急剧增加。 突破性的 SuperVision(“AlexNet”)深度神经网络(图11-a)是第一个赢得年度 ImageNet 大规模视觉识别挑战的神经网络,它依靠 GPU 训练,以及 许多技术进步,因其戏剧性的表现。 本文发表后,使用深度卷积架构的进展显着加快,以至于它们现在是识别和语义分割任务中唯一考虑的架构(图11-b),以及许多其他视觉任务的首选架构、去噪和单目深度推断。
大型数据集和 GPU 架构,以及通过在 arXiv 上及时发布的想法的快速传播,以及深度学习语言的开发和神经网络模型的开源,都促成了该领域的爆炸式增长,无论是快速进步还是能力 ,以及现在研究这些主题的大量出版物和研究人员。 他们还能够将图像识别方法扩展到视频理解任务,例如动作识别,以及结构化回归任务,例如实时多人姿态估计。
用于计算机视觉任务的专用传感器和硬件也在不断发展。2010年发布的 Microsoft Kinect 深度相机迅速成为许多 3D 建模(图11-d)和人员跟踪的重要组成部分系统。十年来,3D身体形状建模和跟踪系统不断发展,现在可以从单个图像中推断出具有手势和表情的人的3D模型(图11-c)。
虽然深度传感器尚未普及(高端手机上的安全应用除外),但计算摄影算法可在当今所有智能手机上运行。计算机视觉社区引入的创新,例如全景图像拼接和包围式高动态范围图像合并, 现在是标准功能,多图像低光去噪算法也变得司空见惯。 允许创建软景深效果的光场成像算法现在也变得越来越可用。 最后,使用特征跟踪和惯性测量的组合执行实时姿态估计和环境增强的移动增强现实应用程序很常见,并且目前正在扩展以包括像素精确的深度遮挡效果(图11-e)。
在自动驾驶汽车和无人机等高端平台上,强大的实时 SLAM(同时定位和映射)和 VIO(视觉惯性里程计)算法可以构建精确的 3D 地图,例如,可以在森林等具有挑战性的场景中进行自主飞行(图11-f)。
总之,在过去的十年中,计算机视觉算法的性能和可靠性取得了令人难以置信的进步,部分原因是转向机器学习和对大量真实世界数据进行训练。 它还看到了视觉算法的应用在无数的商业和消费场景中,以及它们的广泛使用带来的新挑战。
5、常见的视觉软件
(1)HALCON
HALCON是德国MVTec公司开发的一套完善的、标准的机器视觉算法包,拥有应用广泛的机器视觉集成开发环境。它降低了产品成本,缩短了软件开发周期。HALCON灵活的架构便于机器视觉、医学图像等图像分析应用的快速开发。HALCON在欧洲及日本的工业界已经是公认的具有最佳效能的机器视觉软件。
HALCON源自学术界,它有别于市面上一般的商用软件包。事实上,这是一套图像处理库,由一千多个独立的函数及底层的数据管理核心构成,其中包含了各类滤波、色彩及几何、数学转换、形态学计算分析、校正、分类辨识,以及形状搜寻等基本的几何及影像计算功能。由于这些功能大多并非针对特定工作设计,因此,只要用到图像处理的地方,就可以用HALCON来完成。其应用范围涵盖医学、遥感探测、监控,以及工业上的各类自动化检测。
HALCON支持Windows、Linux和Mac OS X操作环境,整个函数库可以用C、C++、C#、Visual Basic和Delphi等多种普通编程语言访问。HALCON为大量的图像获取设备提供了接口,保证了硬件的独立性。它为百余种工业相机和图像采集卡提供了接口,包括GenlCam、GigE、1394、USB3.0等。
(2)VisionPro
VisionPro是美国康耐视推出的图像处理工具包,是一套基于.NET的视觉工具,适用于包括FireWire和CameraLink在内的所有硬件平台。这套先进的视觉工具具有可轻松进行设置的图形开发环境,支持Windows系统,以及Visual Basic和C#等编程语言。
用户可以访问功能较强的图案匹配、斑点、卡尺、线位置、图像过滤、OCR和OCV视觉工具库,以及进行一维条码和二维码的读取,以实现各种功能,如检测、识别和测量。
(3)OpenCV
OpenCV是一个用于图像处理与分析、机器视觉方面的开源函数库。它采用C和C++语言编写,支持Python语言,可以运行在Linux、Windows、Mac等操作系统上。OpenCV包含常用的图像处理算法,同时对机器学习与深度学习支持良好,非常适合用于科研领域。
(4)MATLAB
MATLAB是由美国MathWorks公司发布的主要面向科学计算、可视化及交互式程序设计的高科技计算环境。MATLAB可进行矩阵运算、函数绘制、算法实现、用户界面创建、与其他编程语言的程序连接等,主要应用于工程计算、控制设计、信号处理与通信、图像处理、信号检测、金融建模设计与分析等领域。
另外,MATLAB网页服务程序还允许用户在Web应用中使用自己的MATLAB数学和图形程序。MATLAB的一个重要特色就是具有一套程序扩展系统和一组称为工具箱的特殊应用子程序。工具箱是MATLAB函数的子程序库,每个工具箱都是为某一类学科专业和应用定制的,可用于信号处理、控制系统、神经网络、模糊逻辑、小波分析和系统仿真等方面。
MATLAB因为其商业软件属性,授权费高,运行效率低,很少用于工业编程,更多地用于科学研究领域。