【学习笔记】经典语义分割模型
Image Segmentation
-
- 定义
- 编码器-解码器网络结构
- FCN
- U-Net
- SegNet
- RefineNet
- PSPNet
- DeepLab
-
- DeepLabv1
- DeepLabv2
- DeepLabv3
- DeepLabv3+
- FastFCN
- 性能测试
- 损失函数
-
- Focal Loss
- Dice Loss
定义
图像分割将图像中的每个像素都与一个对象类型相关联。图像分割主要有两种类型:语义分割和实例分割。在语义分割中,所有相同类型的对象都使用一个类标签进行标记,而在实例分割中,相似的对象使用各自的标签。语义分割更注重类别之间的区分,实例分割更注重个体之间的区分。

编码器-解码器网络结构
图像分割中的编码器可视为特征提取网络,通常使用池化层来逐渐缩减输入数据的空间维度;解码器通过上采样/反卷积等网络层来逐步恢复目标的细节和相应的空间维度。编码器中的池化层可以增加后续卷积层的感受野,并能使特征提取聚焦在重要的信息中,降低背景干扰;但池化操作使位置信息大量流失,给解码器修复物体的细节造成了困难。一些方法在编码器和解码器之间建立skip connection,使高分辨率的特征信息参与到后续的解码环节,进而帮助解码器更好的复原目标的细节信息。
FCN
《Fully Convolutional Networks for Semantic Segmentation》 2015 CVPR
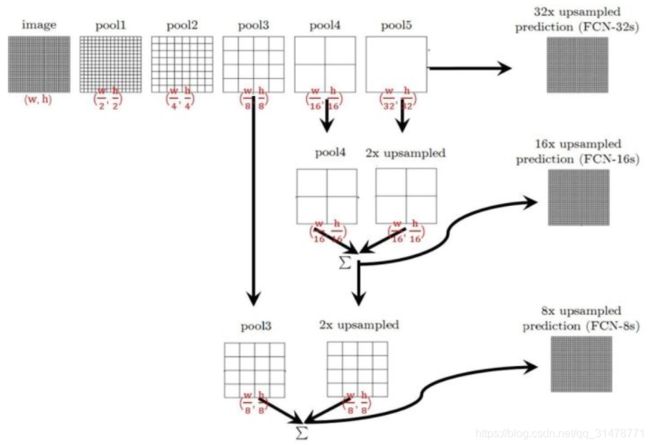
- 优点:
FCN允许输入任意尺寸的图片,并输出和原图一样大小的分割图,比基于像素块的分类方法要快很多;
采用反卷积层来上采样,提出跳跃层来改进上采样的失真问题。 - 缺点:
FCN没有关注池化带来的信息损失;
得到的结果由于上采样的原因比较模糊和平滑,对图像中的细节不敏感;
对各个像素分别进行分类,没有充分考虑像素与像素的关系,缺乏空间一致性。
class FCN8(nn.Module):
def __init__(self, num_classes=21):
super(FCN8, self).__init__()
resnet = list(resnet50(True).children())
self.features1 = nn.Sequential(*resnet[:-4])
self.features2 = nn.Sequential(*resnet[-4])
self.features3 = nn.Sequential(*resnet[-3])
self.score_pool1 = nn.Conv2d(512, num_classes, kernel_size=1)
self.score_pool2 = nn.Conv2d(1024, num_classes, kernel_size=1)
self.score_pool3 = nn.Conv2d(2048, num_classes, kernel_size=1)
self.upscore2 = nn.ConvTranspose2d(num_classes, num_classes, kernel_size=4, stride=2, padding=1, bias=False)
self.upscore2_ = nn.ConvTranspose2d(num_classes, num_classes, kernel_size=4, stride=2, padding=1, bias=False)
self.upscore8 = nn.ConvTranspose2d(num_classes, num_classes, kernel_size=16, stride=8, padding=4, bias=False)
def forward(self, x):
pool1 = self.features1(x)
pool2 = self.features2(pool1)
pool3 = self.features3(pool2)
score_pool3 = self.score_pool3(pool3)
upscore_pool3 = self.upscore2(score_pool3)
score_pool2 = self.score_pool2(0.01 * pool2)
upscore_pool2 = self.upscore2_(score_pool2 + upscore_pool3)
score_pool1 = self.score_pool1(0.0001 * pool1)
upscore_pool1 = self.upscore8(score_pool1 + upscore_pool2)
return upscore_pool1
U-Net
《U-Net: Convolutional Networks for Biomedical Image Segmentation》 2015 MICCAI
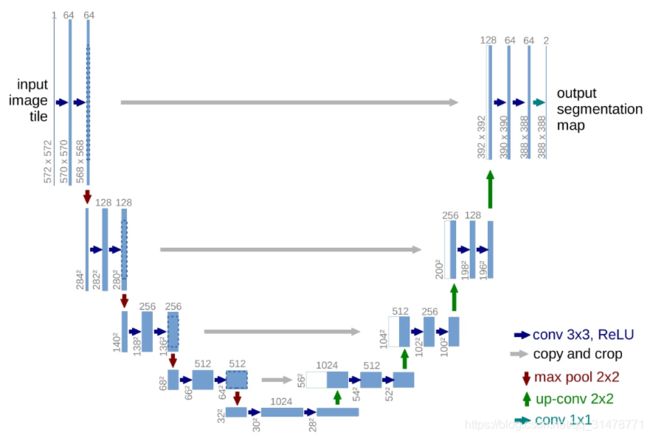
- 优点:
U-Net采用将特征在channel维度拼接在一起,形成更“厚”的特征,相较于FCN多尺度信息更加丰富,同时适合超大图像分割;
使用编码器-解码器架构,四次下采样,四次上采样,形成了U型结构;
作者采用数据增强,通过使用在粗糙的3*3点阵上的随机取代向量来生成平缓的变形,解决了可获得的训练数据很少的问题。 - 缺点:
在医疗图像上表现良好,但对于通用的语义分割数据集,由于语义上比较抽象,过于底层的信息非但作用不大,反而会引入很多噪音;
UNet的提出主要想解决的问题是医学图像数据集不充足,对于大数据集反而效果一般。
class DoubleConv(nn.Sequential):
def __init__(self, in_channels, out_channels, mid_channels=None):
super().__init__()
if not mid_channels:
mid_channels = out_channels
self.conv1 = nn.Conv2d(in_channels, mid_channels, kernel_size=3, padding=1)
self.bn1 = nn.BatchNorm2d(mid_channels)
self.relu1 = nn.ReLU(inplace=True)
self.conv2 = nn.Conv2d(mid_channels, out_channels, kernel_size=3, padding=1)
self.bn2 = nn.BatchNorm2d(out_channels)
self.relu2 = nn.ReLU(inplace=True)
class DownSample(nn.Sequential):
def __init__(self, in_channels, out_channels):
super().__init__()
self.maxpool = nn.MaxPool2d(2)
self.conv = DoubleConv(in_channels, out_channels)
class UpSample(nn.Module):
def __init__(self, in_channels, out_channels):
super().__init__()
self.up = nn.Upsample(scale_factor=2, mode='bilinear', align_corners=True)
self.conv = DoubleConv(in_channels, out_channels, in_channels // 2)
def forward(self, x1, x2):
x1 = self.up(x1)
diffY = x2.size()[2] - x1.size()[2]
diffX = x2.size()[3] - x1.size()[3]
x1 = F.pad(x1, [diffX // 2, diffX - diffX // 2, diffY // 2, diffY - diffY // 2])
x = torch.cat([x2, x1], dim=1)
return self.conv(x)
class UNet(nn.Module):
def __init__(self, num_classes=21):
super(UNet, self).__init__()
self.stem = DoubleConv(3, 32)
self.down1 = DownSample(32, 64)
self.down2 = DownSample(64, 128)
self.down3 = DownSample(128, 256)
self.down4 = DownSample(256, 256)
self.up1 = UpSample(256 + 256, 128)
self.up2 = UpSample(128 + 128, 64)
self.up3 = UpSample(64 + 64, 32)
self.up4 = UpSample(32 + 32, 32)
self.reduce = nn.Conv2d(32, num_classes, kernel_size=1)
def forward(self, x):
x = self.stem(x)
x_d1 = self.down1(x)
x_d2 = self.down2(x_d1)
x_d3 = self.down3(x_d2)
x_d4 = self.down4(x_d3)
x_up1 = self.up1(x_d4, x_d3)
x_up2 = self.up2(x_up1, x_d2)
x_up3 = self.up3(x_up2, x_d1)
x_up4 = self.up4(x_up3, x)
y = self.reduce(x_up4)
return y
SegNet
《SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation》 2015 TPAMI
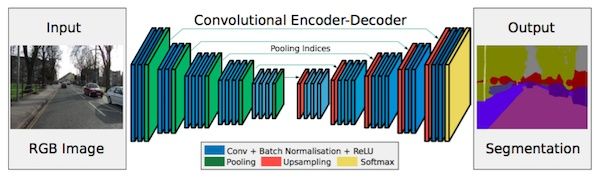
解码器使用从相应的编码器接受的max-pooling indices来进行输入特征图的非线性upsampling。
将最大池化指数转移至解码器中,改善了分割分辨率。
在FCN网络中,通过上卷积层和一些跳跃连接产生了粗糙的分割图,为了提升效果而引入了更多的跳跃连接。
然而,FCN网络仅仅复制了编码器特征,而Segnet网络复制了最大池化指数。这使得在内存使用上,SegNet比FCN更为高效。
SegNet是剑桥提出的旨在解决自动驾驶或者智能机器人的图像语义分割深度网络,SegNet基于FCN,与FCN的思路十分相似,只是其编码-解码器和FCN的稍有不同,其解码器中使用去池化对特征图进行上采样,并在分各种保持高频细节的完整性;而编码器不使用全连接层,因此是拥有较少参数的轻量级网络:
SetNet的优缺点:
保存了高频部分的完整性;
网络不笨重,参数少,较为轻便;
对于分类的边界位置置信度较低;
对于难以分辨的类别,例如人与自行车,两者如果有相互重叠,不确定性会增加。
以上两种网络结构就是基于反卷积/上采样的分割方法,当然其中最最最重要的就是FCN了,哪怕是后面大名鼎鼎的SegNet也是基于FCN架构的,而且FCN可谓是语义分割领域中开创级别的网络结构,所以虽然这个部分虽然只有两个网络结构,但是这两位可都是重量级嘉宾,希望各位能够深刻理解~
SegNet是用于进行像素级别图像分割的全卷积网络。SegNet与FCN的思路较为相似,区别则在于Encoder中Pooling和Decoder的Upsampling使用的技术。Decoder进行上采样的方式是Segnet的亮点之一,SegNet主要用于场景理解应用,需要在进行inference时考虑内存的占用及分割的准确率。同时,Segnet的训练参数较少,可以用SGD进行end-to-end训练。
RefineNet
《RefineNet: Multi-Path Refinement Networks for High-Resolution Semantic Segmentation》 2017 CVPR
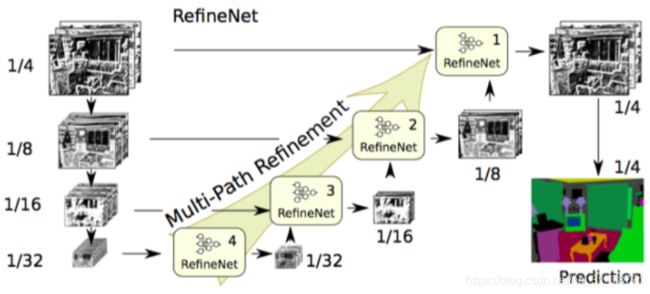
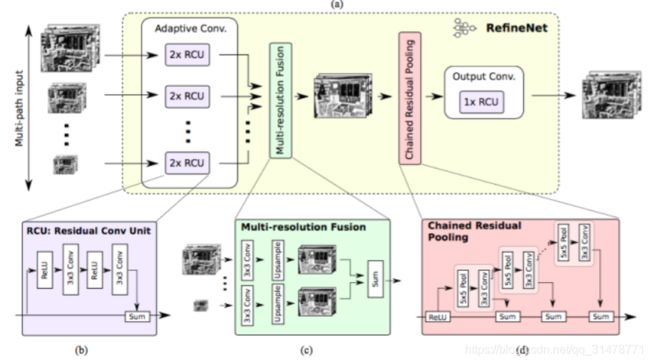
从网络结构上看,RefineNet是U-Net的一个变种。下采样通路以ResNet为基础,上采样通路使用了新提出的RefineNet作为基础。RefineNet利用多级抽象特征进行高分辨率的语义分割,通过递归方式提炼低分辨率的特征,生成高分辨率的特征。RefineNet Block中采用了残差连接结构,使用Sum操作融合不同尺度的特征,最后通过链式池化模块从大的背景区域中俘获上下文信息,多个池化窗口能获得有效的特征,并使用学习到的权重进行融合。
def conv3x3(in_planes, out_planes, dilation=1):
return nn.Conv2d(in_planes, out_planes, kernel_size=3, padding=dilation, bias=False, dilation=dilation)
class ResidualConvUnit(nn.Module):
def __init__(self, channels):
super().__init__()
self.rcu = nn.Sequential(
nn.ReLU(inplace=True),
nn.Conv2d(channels, channels, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
conv3x3(channels, channels)
)
def forward(self, x):
rcu_out = self.rcu(x)
return rcu_out + x
class RCUx2(nn.Sequential):
def __init__(self, channels):
super().__init__(
ResidualConvUnit(channels),
ResidualConvUnit(channels))
class MultiResolutionFusion(nn.Module):
def __init__(self, out_channels, channels):
super().__init__()
self.resolve0 = conv3x3(channels[0], out_channels)
self.resolve1 = conv3x3(channels[1], out_channels)
def forward(self, *xs):
f0 = self.resolve0(xs[0])
f1 = self.resolve1(xs[1])
if f0.shape[-1] < f1.shape[-1]:
f0 = F.interpolate(f0, size=f1.shape[-2:], mode='bilinear', align_corners=True)
else:
f1 = F.interpolate(f1, size=f0.shape[-2:], mode='bilinear', align_corners=True)
out = f0 + f1
return out
class ChainedResidualPool(nn.Module):
def __init__(self, channels):
super().__init__()
self.relu = nn.ReLU(inplace=True)
self.block1 = nn.Sequential(nn.MaxPool2d(kernel_size=5, stride=1, padding=2),
conv3x3(channels, channels))
self.block2 = nn.Sequential(nn.MaxPool2d(kernel_size=5, stride=1, padding=2),
conv3x3(channels, channels))
def forward(self, x):
x = self.relu(x)
out = x
x = self.block1(x)
out = out + x
x = self.block2(x)
out = out + x
return out
class RefineNetBlock(nn.Module):
def __init__(self, in_channels, channels):
super(RefineNetBlock, self).__init__()
self.rcu = nn.ModuleList([])
for channel in channels:
self.rcu.append(RCUx2(channel))
self.mrf = MultiResolutionFusion(in_channels, channels) if len(channels) != 1 else None
self.crp = ChainedResidualPool(in_channels)
self.output_conv = ResidualConvUnit(in_channels)
def forward(self, *xs):
rcu_outs = [rcu(x) for (rcu, x) in zip(self.rcu, xs)]
mrf_out = rcu_outs[0] if self.mrf is None else self.mrf(*rcu_outs)
crp_out = self.crp(mrf_out)
out = self.output_conv(crp_out)
return out
class RefineNet(nn.Module):
def __init__(self, num_classes=21):
super(RefineNet, self).__init__()
resnet = list(resnet50(True).children())
self.layer1 = nn.Sequential(*resnet[:-5])
self.layer2 = nn.Sequential(*resnet[-5])
self.layer3 = nn.Sequential(*resnet[-4])
self.layer4 = nn.Sequential(*resnet[-3])
self.layer1_reduce = conv3x3(256, 256)
self.layer2_reduce = conv3x3(512, 256)
self.layer3_reduce = conv3x3(1024, 256)
self.layer4_reduce = conv3x3(2048, 512)
self.refinenet4 = RefineNetBlock(512, (512,))
self.refinenet3 = RefineNetBlock(256, (512, 256))
self.refinenet2 = RefineNetBlock(256, (256, 256))
self.refinenet1 = RefineNetBlock(256, (256, 256))
self.output_conv = nn.Sequential(
RCUx2(256),
nn.Conv2d(256, num_classes, 1)
)
def forward(self, img):
x = self.layer1(img)
layer1_out = self.layer1_reduce(x)
x = self.layer2(x)
layer2_out = self.layer2_reduce(x)
x = self.layer3(x)
layer3_out = self.layer3_reduce(x)
x = self.layer4(x)
layer4_out = self.layer4_reduce(x)
refine4_out = self.refinenet4(layer4_out)
refine3_out = self.refinenet3(refine4_out, layer3_out)
refine2_out = self.refinenet2(refine3_out, layer2_out)
refine1_out = self.refinenet1(refine2_out, layer1_out)
out = self.output_conv(refine1_out)
out = F.interpolate(out, size=img.shape[-2:], mode='bilinear', align_corners=True)
return out
PSPNet
《PSPNet:Pyramid Scene Parsing Network》 2017 CVPR
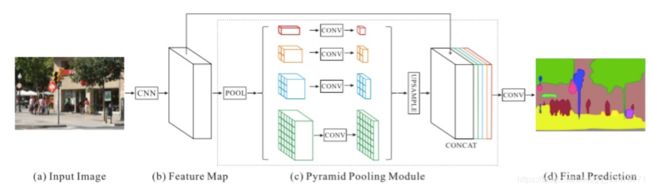
PSPNet提出了金字塔池化模块来聚合背景信息,聚合了基于不同区域的上下文信息,来挖掘全局上下文信息的能力。PSPNet也用空洞卷积来改善ResNet结构。金字塔池化模块使用并行的不同大小池化层来捕获分割类别分布的信息,用1x1的卷积层计算每个金字塔层的权重,然后通过双线性恢复成原始尺寸进行多尺度特征融合。
class ConvBnRelu(nn.Sequential):
def __init__(self, in_planes, out_planes, kernel_size, stride=1, padding=0):
super(ConvBnRelu, self).__init__()
self.conv = nn.Conv2d(in_planes, out_planes, kernel_size, stride, padding, bias=False)
self.bn = nn.BatchNorm2d(out_planes)
self.relu = nn.ReLU(inplace=True)
class PyramidPooling(nn.Module):
def __init__(self, num_classes, pool_scales=(1, 2, 3, 6)):
super(PyramidPooling, self).__init__()
self.ppm = nn.ModuleList([nn.Identity()])
for scale in pool_scales:
self.ppm.append(nn.Sequential(
nn.AdaptiveAvgPool2d(scale),
ConvBnRelu(2048, 512, 1)
))
self.conv = nn.Sequential(
ConvBnRelu(2048 + len(pool_scales)*512, 512, 3, padding=1),
nn.Dropout2d(0.1),
nn.Conv2d(512, num_classes, kernel_size=1)
)
def forward(self, x):
ppm_out = torch.cat([F.interpolate(ppm(x), size=x.shape[-2:], mode='bilinear', align_corners=True)
for ppm in self.ppm], 1)
ppm_out = self.conv(ppm_out)
return ppm_out
class PSPNet(nn.Module):
def __init__(self, num_classes=21):
super(PSPNet, self).__init__()
resnet = resnet50(True, replace_stride_with_dilation=[False, False, True])
self.backbone = nn.Sequential(*list(resnet.children())[:-2])
self.psp_layer = PyramidPooling(num_classes)
def forward(self, img):
x = self.backbone(img)
psp_fm = self.psp_layer(x)
pred = F.interpolate(psp_fm, size=img.shape[-2:], mode='bilinear', align_corners=True)
return pred
DeepLab
《Rethinking Atrous Convolution for Semantic Image Segmentation》 2017 CVPR
DeepLabv1
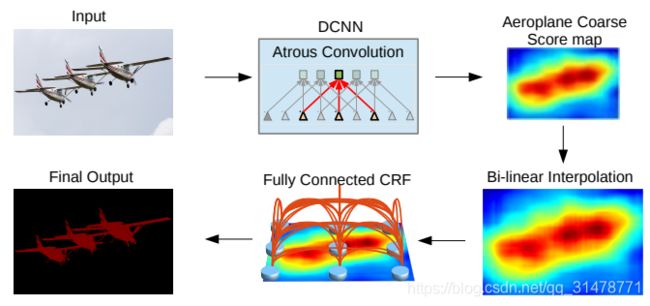
DeepLabv1 结合了DCNNs的识别能力和全连接的CRF的细粒度定位精度,能够产生准确的语义分割结果。(1)DCNN中的池化操作会导致分辨率下降,丢失掉很多细节信息,DeepLabv1中将DCNN中的最后两个 max-pooling 替换为空洞卷积来增大感受野,获取尽可能多的上下文信息。(2)DCNN的分类器获取以对象中心的决策是需要空间变换的不变性,这限制了DCNN的定位精度,DeepLabv1采用完全连接的条件随机场(DenseCRF)提高模型捕获细节的能力。具体来说,将每一个像素作为条件随机场的一个节点,像素与像素间的关系作为边,来构造基于全图的条件随机场。
DeepLabv2
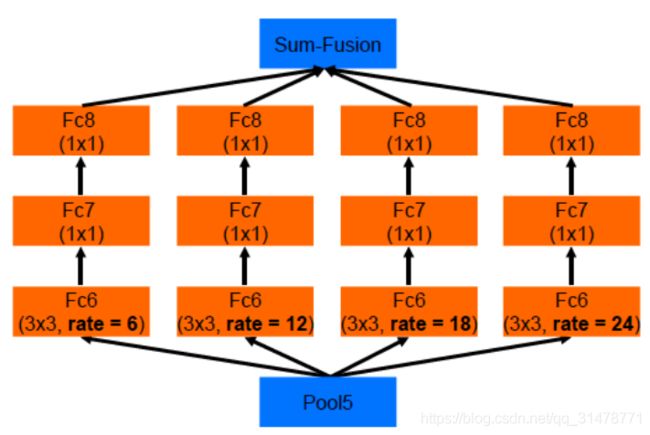
DeepLabv2 相对于 v1 最大的改动是增加了空洞空间金字塔池化(ASPP)模块。ASPP类似于Inception 的结构,包含不同 rate 的空洞卷积。采用了多个并行不同采样率的空洞卷积层,相当于多个滤波器探索原始图像获得互补的视野,从而在多个尺度捕获对象及其有用的上下文信息,增强模型识别不同尺寸的同一物体的能力。将 v1 中使用的VGG网络替换为ResNet网络。
DeepLabv3
DeepLabv3 改进了ASPP。采用一个1x1卷积和三个3x3的采样率为rates={6,12,18}的空洞卷积,而且加入BN层。添加了一个全局平均池化层+1x1卷积+双线性插值上采样 的分支,以利用图像级特征。新的ASPP由5个分支并行提取不同尺度的特征,再进行特征融合。另外DeepLabv3不再依赖CRF就能达到优秀的性能。
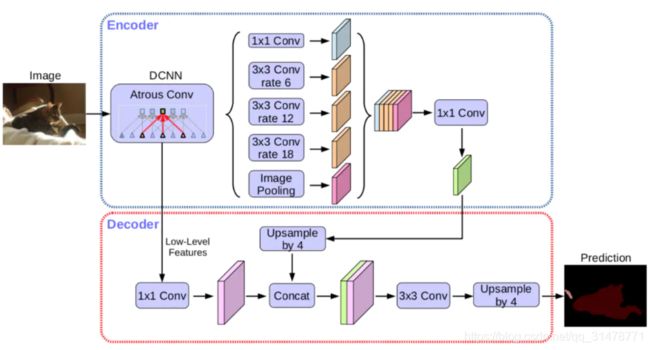
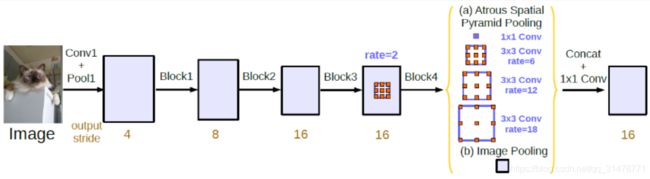
DeepLabv3+
DeepLabv3+ 将 DeepLabv3当作Encoder,添加了额外的Decoder得到新的模型。DeepLabv3中最后的双线性插值上采样可看作是一个简单的 Decoder,而强化 Decoder 便可使模型整体在图像语义分割边缘部分取得良好的结果。DeepLabv3+ 的Decoder 融合了DCNN的低尺度特征,得到相对于 DeepLabv3 更精细的结果。此外,借鉴了MobileNet 使用深度可分卷积。
def conv3x3(in_planes, out_planes, dilation=1):
return nn.Conv2d(in_planes, out_planes, kernel_size=3, padding=dilation, bias=False, dilation=dilation)
def conv1x1(in_planes, out_planes):
return nn.Conv2d(in_planes, out_planes, kernel_size=1, bias=False)
class ASPPConv(nn.Sequential):
def __init__(self, in_channels, out_channels, dilation):
modules = [
conv3x3(in_channels, out_channels, dilation),
nn.BatchNorm2d(out_channels),
nn.ReLU()
]
super(ASPPConv, self).__init__(*modules)
class ASPPPooling(nn.Sequential):
def __init__(self, in_channels, out_channels):
super(ASPPPooling, self).__init__(
nn.AdaptiveAvgPool2d(1),
conv1x1(in_channels, out_channels),
nn.BatchNorm2d(out_channels),
nn.ReLU())
def forward(self, x):
size = x.shape[-2:]
x = super(ASPPPooling, self).forward(x)
return F.interpolate(x, size=size, mode='bilinear', align_corners=False)
class ASPP(nn.Module):
def __init__(self, in_channels, out_channels=256, dilation_rates=(12, 24, 36)):
super(ASPP, self).__init__()
conv1 = nn.Sequential(
conv1x1(in_channels, out_channels),
nn.BatchNorm2d(out_channels),
nn.ReLU()
)
self.convs = nn.ModuleList([
conv1,
ASPPConv(in_channels, out_channels, dilation_rates[0]),
ASPPConv(in_channels, out_channels, dilation_rates[1]),
ASPPConv(in_channels, out_channels, dilation_rates[2]),
ASPPPooling(in_channels, out_channels)
])
self.project = nn.Sequential(
conv1x1(5 * out_channels, out_channels),
nn.BatchNorm2d(out_channels),
nn.ReLU(),
nn.Dropout()
)
def forward(self, x):
res = torch.cat([conv(x) for conv in self.convs], dim=1)
return self.project(res)
class Head(nn.Module):
def __init__(self, num_classes):
super(Head, self).__init__()
self.ASPP = ASPP(2048, dilation_rates=(6, 12, 18))
self.upsample4 = nn.Upsample(scale_factor=4, mode='bilinear', align_corners=False)
self.reduce = nn.Sequential(
conv1x1(256, 48),
nn.BatchNorm2d(48),
nn.ReLU()
)
self.fuse_conv = nn.Sequential(
conv3x3(256 + 48, 256),
nn.BatchNorm2d(256),
nn.ReLU(),
conv3x3(256, 256),
nn.BatchNorm2d(256),
nn.ReLU()
)
self.classifier = nn.Conv2d(256, num_classes, 1)
def forward(self, low_features, high_features):
high_features = self.ASPP(high_features)
high_features = self.upsample4(high_features)
low_features = self.reduce(low_features)
f = torch.cat((high_features, low_features), dim=1)
f = self.fuse_conv(f)
predition = self.classifier(f)
return self.upsample4(predition)
class DeepLabV3(nn.Module):
def __init__(self, num_classes=21):
super(DeepLabV3, self).__init__()
resnet = resnet50(True, replace_stride_with_dilation=[False, False, True])
self.backbone = nn.Sequential(*list(resnet.children())[:-2])
self.ASPP = ASPP(2048, dilation_rates=(6, 12, 18))
self.classifier = nn.Sequential(
nn.Conv2d(256, 256, 3, padding=1, bias=False),
nn.BatchNorm2d(256),
nn.ReLU(),
nn.Conv2d(256, num_classes, 1)
)
def forward(self, x):
input_shape = x.shape[-2:]
features = self.backbone(x)
aspp = self.ASPP(features)
predict = self.classifier(aspp)
output = F.interpolate(predict, size=input_shape, mode='bilinear', align_corners=False)
return output
class DeepLabV3plus(nn.Module):
def __init__(self, num_classes=21):
super(DeepLabV3plus, self).__init__()
resnet = list(resnet50(True, replace_stride_with_dilation=[False, False, True]).children())
self.feature1 = nn.Sequential(*resnet[:5])
self.feature2 = nn.Sequential(*resnet[5:-2])
self.head = Head(num_classes)
def forward(self, x):
x = self.feature1(x)
low = x
x = self.feature2(x)
pred = self.head(low, x)
return pred
FastFCN
《FastFCN: Rethinking Dilated Convolution in the Backbone for Semantic Segmentation》 2019
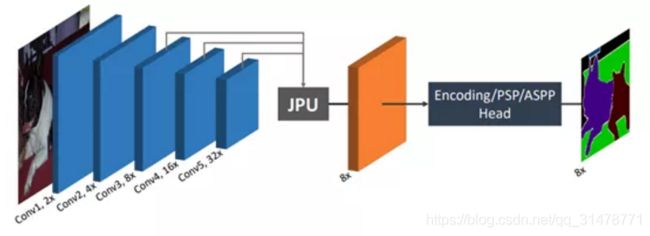
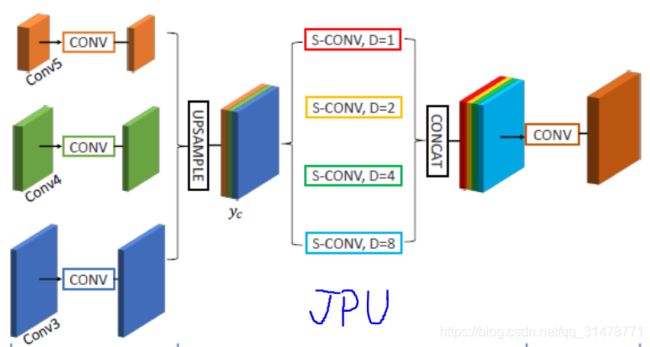
FastFCN使用一个联合金字塔上采样(JPU)模块来替换膨胀卷积,因为它们消耗大量的内存和时间。在应用JPU进行上采样时,其核心部分采用全连接网络。JPU将低分辨率的特征图采样到高分辨率特征图,降低了计算复杂度和内存占用,且不损失甚至会对最终精度有一定的提升。JPU模块融合主干网络的最后三层特征图,可以学习多尺度的特征以获得更好的性能。
class ConvBnRelu(nn.Sequential):
def __init__(self, in_planes, out_planes, kernel_size, stride=1, padding=0, dilation=1):
super(ConvBnRelu, self).__init__()
self.conv = nn.Conv2d(in_planes, out_planes, kernel_size, stride, padding, dilation, bias=False)
self.bn = nn.BatchNorm2d(out_planes)
self.relu = nn.ReLU(inplace=True)
class ASPPConv(nn.Sequential):
def __init__(self, in_channels, out_channels, dilation):
super(ASPPConv, self).__init__()
self.conv = ConvBnRelu(in_channels, out_channels, 3, padding=dilation, dilation=dilation)
class ASPPPooling(nn.Sequential):
def __init__(self, in_channels, out_channels):
super(ASPPPooling, self).__init__(
nn.AdaptiveAvgPool2d(1),
ConvBnRelu(in_channels, out_channels, 1)
)
def forward(self, x):
size = x.shape[-2:]
x = super(ASPPPooling, self).forward(x)
return F.interpolate(x, size=size, mode='bilinear', align_corners=True)
class ASPP(nn.Module):
def __init__(self, in_channels, out_channels=256, dilation_rates=(12, 24, 36)):
super(ASPP, self).__init__()
self.convs = nn.ModuleList([
ConvBnRelu(in_channels, out_channels, 1),
ASPPConv(in_channels, out_channels, dilation_rates[0]),
ASPPConv(in_channels, out_channels, dilation_rates[1]),
ASPPConv(in_channels, out_channels, dilation_rates[2]),
ASPPPooling(in_channels, out_channels)
])
self.project = ConvBnRelu(5 * out_channels, out_channels, 1)
def forward(self, x):
res = torch.cat([conv(x) for conv in self.convs], dim=1)
return self.project(res)
class Head(nn.Module):
def __init__(self, num_classes):
super(Head, self).__init__()
self.ASPP = ASPP(2048, dilation_rates=(6, 12, 18))
self.reduce = ConvBnRelu(256, 48, 1)
self.fuse_conv = nn.Sequential(
ConvBnRelu(256 + 48, 256, 3, padding=1),
ConvBnRelu(256, 256, 3, padding=1),
nn.Dropout2d(0.1)
)
self.classifier = nn.Conv2d(256, num_classes, 1)
def forward(self, low_features, high_features):
high_features = self.ASPP(high_features)
high_features = F.interpolate(high_features, size=low_features.shape[-2:], mode='bilinear', align_corners=True)
low_features = self.reduce(low_features)
f = torch.cat((high_features, low_features), dim=1)
f = self.fuse_conv(f)
predition = self.classifier(f)
return predition
class JPU(nn.Module):
def __init__(self):
super(JPU, self).__init__()
self.conv2 = ConvBnRelu(512, 512, 3, padding=1)
self.conv3 = ConvBnRelu(1024, 512, 3, padding=1)
self.conv4 = ConvBnRelu(2048, 512, 3, padding=1)
self.dilated_convs = nn.ModuleList([
ConvBnRelu(512 * 3, 512, 3, padding=1, dilation=1),
ConvBnRelu(512 * 3, 512, 3, padding=2, dilation=2),
ConvBnRelu(512 * 3, 512, 3, padding=4, dilation=4),
ConvBnRelu(512 * 3, 512, 3, padding=8, dilation=8)
])
def forward(self, f2, f3, f4):
f2 = self.conv2(f2)
f3 = self.conv3(f3)
f3 = F.interpolate(f3, size=f2.shape[-2:], mode='bilinear', align_corners=True)
f4 = self.conv4(f4)
f4 = F.interpolate(f4, size=f2.shape[-2:], mode='bilinear', align_corners=True)
feat = torch.cat([f4, f3, f2], dim=1)
dilat_out = torch.cat([conv(feat) for conv in self.dilated_convs], dim=1)
return dilat_out
class FastFCN(nn.Module):
def __init__(self, num_classes=21):
super(FastFCN, self).__init__()
resnet = list(resnet50(True, replace_stride_with_dilation=[False, False, True]).children())
self.feature1 = nn.Sequential(*resnet[:5])
self.feature2 = nn.Sequential(*resnet[5])
self.feature3 = nn.Sequential(*resnet[6])
self.feature4 = nn.Sequential(*resnet[7])
self.jpu = JPU()
self.head = Head(num_classes)
def forward(self, x):
f1 = self.feature1(x)
f2 = self.feature2(f1)
f3 = self.feature3(f2)
f4 = self.feature4(f3)
jpu_out = self.jpu(f2, f3, f4)
pred = self.head(f1, jpu_out)
output = F.interpolate(pred, size=x.shape[-2:], mode='bilinear', align_corners=True)
return output
性能测试
在PASCAL VOC2007 val上进行测试,batchszie设为32,优化器用Adam(lr=1e-3),没有细调,仅作参考。
| pixel acc. | mean acc. | mean IU | f.w. IU | |
|---|---|---|---|---|
| U-Net | 68.2 | 5.9 | 4.2 | 48.4 |
| SegNet | 69.1 | 7.0 | 4.6 | 49.9 |
| FCN-32s | 82.3 | 49.6 | 39.5 | 70.1 |
| FCN-16s | 82.0 | 49.0 | 40.5 | 69.5 |
| FCN-8s | 82.8 | 53.6 | 43.3 | 71.0 |
| RefineNet | 80.2 | 43.1 | 31.3 | 69.6 |
| PSPNet | 85.5 | 57.0 | 48.5 | 75.0 |
| DeepLab-v3 | 86.7 | 60.8 | 53.0 | 76.7 |
| DeepLab-v3+ | 86.2 | 66.2 | 53.3 | 76.6 |
| DeepLab-v3+ | 86.2 | 66.2 | 53.3 | 76.6 |
| FastFCN | 85.2 | 57.0 | 46.3 | 75.1 |
U-Net和SegNet训得不好,不知道是网络本身的原因还是需要特殊的训练技巧。FCN虽然是元老级别的模型了,但是论文里的FCN使用的backbone是VGG16,将backbone换成ResNet50能大幅提升性能。
损失函数
语义分割模型在训练过程中通常使用一个简单的交叉分类熵损失函数。但是,如果想要获取图像的细粒度信息,则需要用到稍微高级一点的损失函数。
Focal Loss
Focal Loss是对标准交叉熵的改进。通过减少易分类样本的权重,使得模型在训练时更专注于难分类的样本。在这个损失函数中,交叉熵损失被缩放,随着对正确类的置信度的增加,缩放因子衰减为零。在训练时,比例因子会自动降低简单样本的权重,并聚焦于困难样本。
L = − ( 1 − p ) γ log ( p ) L=-(1-p)^{\gamma}\log(p) L=−(1−p)γlog(p)
Dice Loss
语义分割中一般用交叉熵来做损失函数,而评价的时候却使用IOU来作为评价指标,而Dice Loss是类似 IoU 度量的损失函数。
L = 2 ∣ X ∩ Y ∣ ∣ X ∣ + ∣ Y ∣ L=\frac {2|X\cap Y|} {|X|+|Y|} L=∣X∣+∣Y∣2∣X∩Y∣
缺点是Dice Loss训练误差曲线非常混乱,很难看出关于收敛的信息。尽管可以检查在验证集上的误差来避开此问题。