ResNeXt
Aggregated Residual Transformations for Deep Neural Networks
文章地址https://arxiv.org/abs/1611.05431
代码地址https://github.com/miraclewkf/ResNeXt-PyTorch
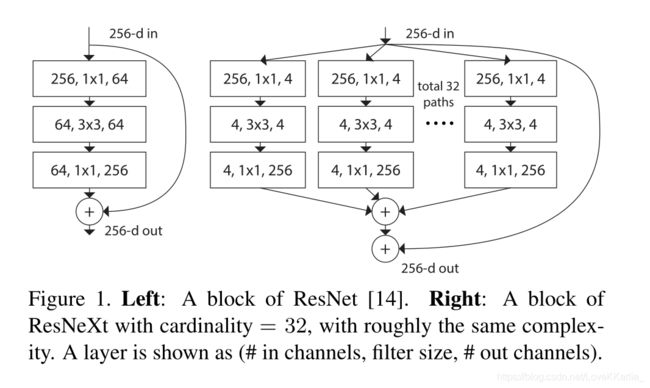
采用VGG/ResNet的重复层策略,同时以简单的、可扩展的方式利用split-transform-merge策略。但是扩展性强。每个被聚合的拓扑结构都是一样的(这也是和 Inception 的差别,减轻设计负担)
multi-branch卷积网络:Inception models,多分枝架构,每个分支仔细定制,ResNet可以被认为是一个分枝网络,其中一个分支是身份映射。
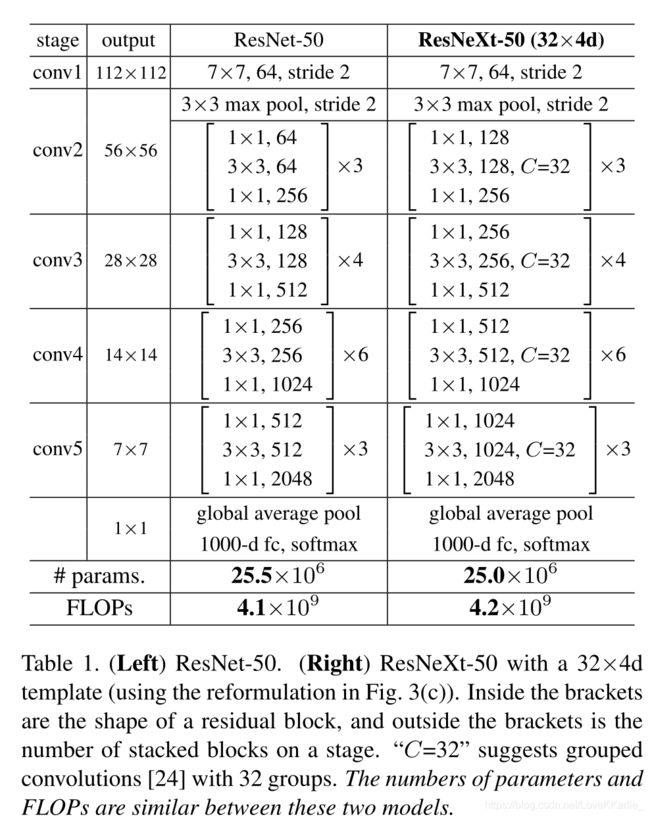
全连接层: ∑ i = 1 D w i s i \sum^D_{i=1}w_is_i ∑i=1Dwisi。
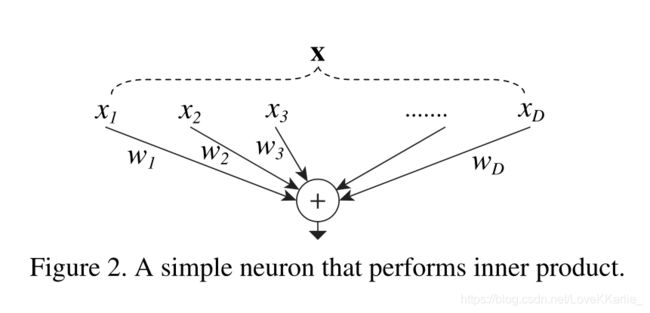
Split:将数据 x \bf x x split成D个特征;
Transform:每个特征经过一个线性变换;
Merge:通过单位加合成最后的输出。
汇总转换: F ( x ) = ∑ i = 1 C T i ( x ) \mathcal F(x)=\sum^C_{i=1}\mathcal T_i(x) F(x)=∑i=1CTi(x)
Inception是一个非常明显的“split-transform-merge”结构,作者认为Inception不同分支的不同拓扑结构的特征有非常刻意的人工雕琢的痕迹,而往往调整Inception的内部结构对应着大量的超参数,这些超参数调整起来是非常困难的。
所以作者的思想是每个结构使用相同的拓扑结构,那么这时候的Inception(这里简称简化Inception)表示为 y = ∑ i = 1 C T i ( x ) {\bf y}=\sum^C_{i=1}\mathcal T_i(\bf x) y=∑i=1CTi(x)
ResNeXt: y = x + ∑ i = 1 C T i ( x ) {\bf y}={\bf x}+\sum^C_{i=1}\mathcal T_i(\bf x) y=x+∑i=1CTi(x)
'''
New for ResNeXt:
1. Wider bottleneck
2. Add group for conv2
'''
import torch.nn as nn
import math
__all__ = ['ResNeXt', 'resnext18', 'resnext34', 'resnext50', 'resnext101',
'resnext152']
def conv3x3(in_planes, out_planes, stride=1):
"""3x3 convolution with padding"""
return nn.Conv2d(in_planes, out_planes, kernel_size=3, stride=stride,
padding=1, bias=False)
class BasicBlock(nn.Module):
expansion = 1
def __init__(self, inplanes, planes, stride=1, downsample=None, num_group=32):
super(BasicBlock, self).__init__()
self.conv1 = conv3x3(inplanes, planes*2, stride)
self.bn1 = nn.BatchNorm2d(planes*2)
self.relu = nn.ReLU(inplace=True)
self.conv2 = conv3x3(planes*2, planes*2, groups=num_group)
self.bn2 = nn.BatchNorm2d(planes*2)
self.downsample = downsample
self.stride = stride
def forward(self, x):
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
if self.downsample is not None:
residual = self.downsample(x)
out += residual
out = self.relu(out)
return out
class Bottleneck(nn.Module):
expansion = 4
def __init__(self, inplanes, planes, stride=1, downsample=None, num_group=32):
super(Bottleneck, self).__init__()
self.conv1 = nn.Conv2d(inplanes, planes*2, kernel_size=1, bias=False)
self.bn1 = nn.BatchNorm2d(planes*2)
self.conv2 = nn.Conv2d(planes*2, planes*2, kernel_size=3, stride=stride,
padding=1, bias=False, groups=num_group)
self.bn2 = nn.BatchNorm2d(planes*2)
self.conv3 = nn.Conv2d(planes*2, planes * 4, kernel_size=1, bias=False)
self.bn3 = nn.BatchNorm2d(planes * 4)
self.relu = nn.ReLU(inplace=True)
self.downsample = downsample
self.stride = stride
def forward(self, x):
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
if self.downsample is not None:
residual = self.downsample(x)
out += residual
out = self.relu(out)
return out
class ResNeXt(nn.Module):
def __init__(self, block, layers, num_classes=1000, num_group=32):
self.inplanes = 64
super(ResNeXt, self).__init__()
self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3,
bias=False)
self.bn1 = nn.BatchNorm2d(64)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.layer1 = self._make_layer(block, 64, layers[0], num_group)
self.layer2 = self._make_layer(block, 128, layers[1], num_group, stride=2)
self.layer3 = self._make_layer(block, 256, layers[2], num_group, stride=2)
self.layer4 = self._make_layer(block, 512, layers[3], num_group, stride=2)
self.avgpool = nn.AvgPool2d(7, stride=1)
self.fc = nn.Linear(512 * block.expansion, num_classes)
for m in self.modules():
if isinstance(m, nn.Conv2d):
n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
m.weight.data.normal_(0, math.sqrt(2. / n))
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(1)
m.bias.data.zero_()
def _make_layer(self, block, planes, blocks, num_group, stride=1):
downsample = None
if stride != 1 or self.inplanes != planes * block.expansion:
downsample = nn.Sequential(
nn.Conv2d(self.inplanes, planes * block.expansion,
kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(planes * block.expansion),
)
layers = []
layers.append(block(self.inplanes, planes, stride, downsample, num_group=num_group))
self.inplanes = planes * block.expansion
for i in range(1, blocks):
layers.append(block(self.inplanes, planes, num_group=num_group))
return nn.Sequential(*layers)
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.avgpool(x)
x = x.view(x.size(0), -1)
x = self.fc(x)
return x
def resnext18( **kwargs):
"""Constructs a ResNeXt-18 model.
"""
model = ResNeXt(BasicBlock, [2, 2, 2, 2], **kwargs)
return model
def resnext34(**kwargs):
"""Constructs a ResNeXt-34 model.
"""
model = ResNeXt(BasicBlock, [3, 4, 6, 3], **kwargs)
return model
def resnext50(**kwargs):
"""Constructs a ResNeXt-50 model.
"""
model = ResNeXt(Bottleneck, [3, 4, 6, 3], **kwargs)
return model
def resnext101(**kwargs):
"""Constructs a ResNeXt-101 model.
"""
model = ResNeXt(Bottleneck, [3, 4, 23, 3], **kwargs)
return model
def resnext152(**kwargs):
"""Constructs a ResNeXt-152 model.
"""
model = ResNeXt(Bottleneck, [3, 8, 36, 3], **kwargs)
return model
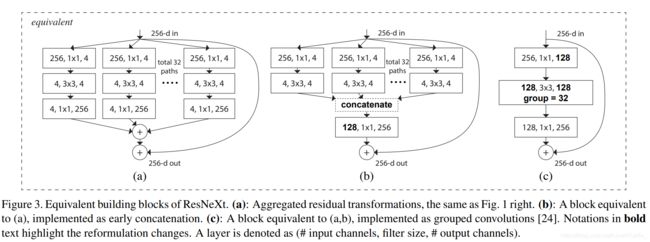
这里作者展示了三种相同的 ResNeXt blocks。fig3.a 就是前面所说的aggregated residual transformations。 fig3.b 则采用两层卷积后 concatenate,再卷积,有点类似 Inception-ResNet,只不过这里的 paths 都是相同的拓扑结构。fig 3.c采用的是grouped convolutions,这个 group 参数就是 caffe 的 convolusion 层的 group 参数,用来限制本层卷积核和输入 channels 的卷积,最早应该是 AlexNet 上使用,可以减少计算量。这里 fig 3.c 采用32个 group,每个 group 的输入输出 channels 都是4,最后把channels合并。这张图的 fig3.c 和 fig1 的左边图很像,差别在于fig3.c的中间 filter 数量(此处为128,而fig 1中为64)更多。作者在文中明确说明这三种结构是严格等价的,并且用这三个结构做出来的结果一模一样,在本文中展示的是 fig3.c 的结果,因为 fig3.c 的结构比较简洁而且速度更快。
ResNeXt的分支的拓扑结构是相同的,Inception V4需要人工设计;
ResNeXt是先进行1×1卷积然后执行单位加,Inception V4是先拼接再执行1×1卷积,如图4所示。

ResNeXt提出了一种介于普通卷积核深度可分离卷积的这种策略:分组卷积,他通过控制分组的数量(基数)来达到两种策略的平衡。分组卷积的思想是源自Inception,不同于Inception的需要人工设计每个分支,ResNeXt的每个分支的拓扑结构是相同的。最后再结合残差网络,得到的便是最终的ResNeXt。
ResNeXt的结构非常简单,但是其在ImageNet上取得了由于相同框架的残差网络,也算是Inception直接助攻了一把吧。
ResNeXt确实比Inception V4的超参数更少,但是他直接废除了Inception的囊括不同感受野的特性仿佛不是很合理,在更多的环境中我们发现Inception V4的效果是优于ResNeXt的。类似结构的ResNeXt的运行速度应该是优于Inception V4的,因为ResNeXt的相同拓扑结构的分支的设计是更符合GPU的硬件设计原则。
【参考文献】
ResNeXt详解https://zhuanlan.zhihu.com/p/51075096
ResNeXt算法详解https://blog.csdn.net/u014380165/article/details/71667916