CV-CNN-2015:ResNet【残差网络,改善深层网络难训练问题:梯度消失或爆炸导致性能退化】【Bottleneck:用1×1核卷积(减小通道数来降维)、3×3核卷积(不变维)、用1×1核升维】
《原始论文:Deep Residual Learning for Image Recognition》
- 一说起“深度学习”,自然就联想到它非常显著的特点“深、深、深”,通过很深层次的网络实现准确率非常高的图像识别、语音识别等能力。
- 因此,我们自然很容易就想到:深的网络一般会比浅的网络效果好,如果要进一步地提升模型的准确率,最直接的方法就是把网络设计得越深越好,这样模型的准确率也就会越来越准确。
- 那现实是这样吗?
- 先看几个经典的图像识别深度学习模型:

- 这几个模型都是在世界顶级比赛中获奖的著名模型,然而,一看这些模型的网络层次数量,似乎让人很失望,少则5层,多的也就22层而已,这些世界级模型的网络层级也没有那么深啊,这种也算深度学习吗?为什么不把网络层次加到成百上千层呢?
- 带着这个问题,我们先来看一个实验,对常规的网络(plain network,也称平原网络)直接堆叠很多层次,经对图像识别结果进行检验,训练集、测试集的误差结果如下图:
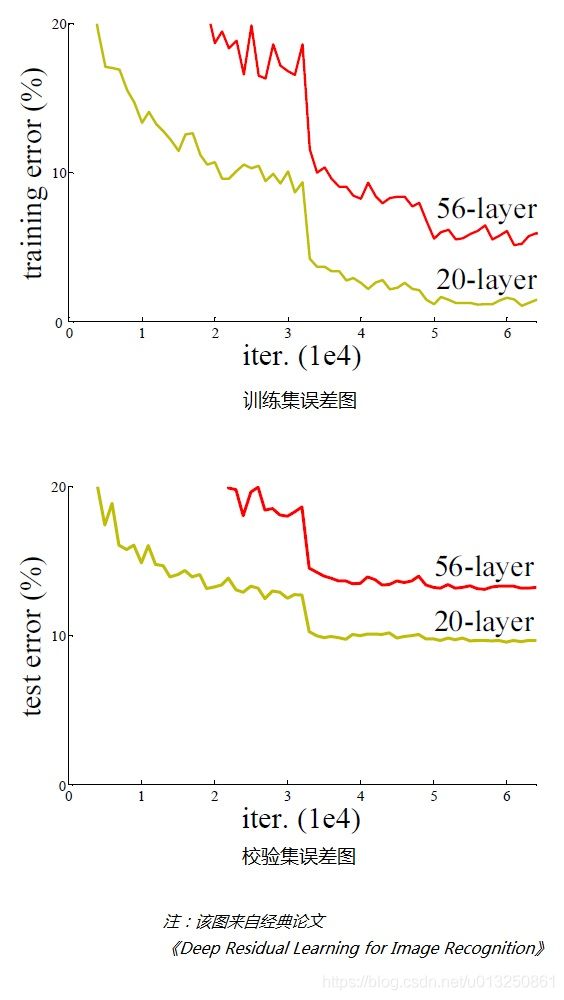
- 从上面两个图可以看出,在网络很深的时候(56层相比20层),模型效果却越来越差了(误差率越高),并不是网络越深越好。
- 通过实验可以发现:随着网络层级的不断增加,模型精度不断得到提升,而当网络层级增加到一定的数目以后,训练精度和测试精度迅速下降,这说明当网络变得很深以后,深度网络就变得更加难以训练了。
1、为什么随着网络层级越深,模型效果却变差了
- 下图是一个简单神经网络图,由输入层、隐含层、输出层构成:
- 回想一下神经网络反向传播的原理,先通过正向传播计算出结果output,然后与样本比较得出误差值 E t o t a l E_{total} Etotal

- 根据误差结果,利用著名的“链式法则”求偏导,使结果误差反向传播从而得出权重 w w w 调整的梯度。下图是输出结果到隐含层的反向传播过程(隐含层到输入层的反向传播过程也是类似):

- 通过不断迭代,对参数矩阵进行不断调整后,使得输出结果的误差值更小,使输出结果与事实更加接近。
- 从上面的过程可以看出,神经网络在反向传播过程中要不断地传播梯度,而当网络层数加深时,梯度在传播过程中会逐渐消失(假如采用Sigmoid函数,对于幅度为1的信号,每向后传递一层,梯度就衰减为原来的0.25,层数越多,衰减越厉害),导致无法对前面网络层的权重进行有效的调整。
- 那么,如何又能加深网络层数、又能解决梯度消失问题、又能提升模型精度呢?残差网络由此产生。
2、深度残差网络(Deep Residual Network,简称DRN)
-
前面描述了一个实验结果现象,在不断加神经网络的深度时,模型准确率会先上升然后达到饱和,再持续增加深度时则会导致准确率下降,示意图如下:

-
那么我们作这样一个假设:假设现有一个比较浅的网络(Shallow Net)已达到了饱和的准确率,这时在它后面再加上几个恒等映射层(identity mapping,也即 y = x y=x y=x,输出=输入),这样就增加了网络的深度,并且起码误差不会增加,也即更深的网络不应该带来训练集上误差的上升。而这里提到的使用恒等映射直接将前一层输出传到后面的思想,便是著名深度残差网络ResNet的灵感来源。
-
ResNet引入了残差网络结构(residual network),通过这种残差网络结构,可以把网络层弄的很深(据说目前可以达到1000多层),并且最终的分类效果也非常好,残差网络的基本结构如下图所示,该图表示一个 Basic Block:

-
残差网络借鉴了高速网络(Highway Network)的跨层链接思想,但对其进行改进(残差项原本是带权值的,但ResNet用恒等映射代替之)。
-
假定某段神经网络的输入是 x x x,期望输出是 H ( x ) H(x) H(x),即 H ( x ) H(x) H(x) 是期望的复杂潜在映射,如果是要学习这样的模型,则训练难度会比较大;
-
回想前面的假设,如果已经学习到较饱和的准确率(或者当发现下层的误差变大时),那么接下来的学习目标就转变为恒等映射的学习,也就是使输入 x x x 近似于输出 H ( x ) H(x) H(x),以保持在后面的层次中不会造成精度下降。
-
在上图的残差网络结构图中,通过 “shortcut connections(短路连接)” 的方式,直接把输入 x x x 传到 输出 作为 “初始结果”,输出结果为 H ( x ) = x + F ( x ) H(x)=x+F(x) H(x)=x+F(x)
其中的 “+” 号表示输出 H ( x ) H(x) H(x) 是 矩阵 x x x 与 F ( x ) F(x) F(x) 的加和。所以 x x x 与 F ( x ) F(x) F(x) 维度要一致。
当 F ( x ) = 0 F(x)=0 F(x)=0 时,那么 H ( x ) = x H(x)=x H(x)=x,也就是上面所提到的恒等映射。于是,ResNet相当于将学习目标改变了,不再是学习一个完整的输出,而是目标值 H ( X ) H(X) H(X) 和 x x x 的差值,也就是所谓的残差 F ( x ) = H ( x ) − x F(x) = H(x)-x F(x)=H(x)−x
因此,后面的训练目标就是要将残差结果逼近于0,使到随着网络加深,准确率不下降。 -
这种残差跳跃式的结构,打破了传统的神经网络 n − 1 n-1 n−1 层的输出只能给 n n n 层作为输入的惯例,使某一层的输出可以直接跨过几层作为后面某一层的输入,其意义在于为叠加多层网络而使得整个学习模型的错误率不降反升的难题提供了新的方向。
-
至此,神经网络的层数可以超越之前的约束,达到几十层、上百层甚至千层,为高级语义特征提取和分类提供了可行性。
-
下图最右侧是一个34层的深度残差网络的结构图,
- 每一条箭头曲线包裹的部分是一个 Basic Block
- 每一组不同颜色的部分代表一个 Residual Block,是由多个Basic Block组成(一般2~3个),
- 每个Residual Network 是由多个Residual Block组成:

-
从图可以看出,怎么有一些 “shortcut connections(短路连接)” 是实线,有一些是虚线,有什么区别呢?

-
因为经过“shortcut connections(短路连接)” 后, H ( x ) = F ( x ) + x H(x)=F(x)+x H(x)=F(x)+x,如果 F ( x ) F(x) F(x) 和 x x x 的通道相同,则可直接相加,那么通道不同怎么相加呢。上图中的实线、虚线就是为了区分这两种情况的:
- 实线的Connection部分,表示通道相同,如上图的第一个粉色矩形和第三个粉色矩形,都是 3 × 3 × 64 3×3×64 3×3×64 的特征图,由于通道相同,所以采用计算方式为 H ( x ) = F ( x ) + x H(x)=F(x)+x H(x)=F(x)+x
- 虚线的的Connection部分,表示通道不同,如上图的第一个绿色矩形和第三个绿色矩形,分别是 3 × 3 × 64 3×3×64 3×3×64 和 3 × 3 × 128 3×3×128 3×3×128 的特征图,通道不同,采用的计算方式为 H ( x ) = F ( x ) + W x H(x)=F(x)+Wx H(x)=F(x)+Wx,其中 W W W 是卷积操作,用来调整 x x x 维度的。
-
除了上面提到的 两层的 残差学习单元 Basic Block,还有 三层的 残差学习单元 Basic Block,如下图所示:

-
两种结构分别针对ResNet34(左图)和ResNet50/101/152(右图),其目的主要就是为了降低参数的数目。官方设计了18、34、50、101、152层。
- 左图是两个 3 × 3 × 256 3×3×256 3×3×256 的卷积,参数数目: 3 × 3 × 256 × 256 × 2 = 1179648 3×3×256×256×2 = 1179648 3×3×256×256×2=1179648,
- 右图是第一个 1 × 1 1×1 1×1的卷积把 256 256 256 维通道降到 64 64 64 维,然后在最后通过 1 × 1 1×1 1×1卷积恢复,整体上用的参数数目: 1 × 1 × 256 × 64 + 3 × 3 × 64 × 64 + 1 × 1 × 64 × 256 = 69632 1×1×256×64 + 3×3×64×64 + 1×1×64×256 = 69632 1×1×256×64+3×3×64×64+1×1×64×256=69632,右图的参数数量比左图减少了16.94倍,因此,右图的主要目的就是为了减少参数量,从而减少计算量。
- 对于常规的ResNet,比如34层或者更少的网络,使用左图结构;对于更深的网络(如101层),则使用右图,其目的是减少计算和参数量。
-
经检验,深度残差网络的确解决了退化问题,如下图所示,左图为平原网络(plain network)网络层次越深(34层)比网络层次浅的(18层)的误差率更高;右图为残差网络ResNet的网络层次越深(34层)比网络层次浅的(18层)的误差率更低。

-
ResNet在ILSVRC2015竞赛中惊艳亮相,一下子将网络深度提升到152层,将错误率降到了3.57,在图像识别错误率和网络深度方面,比往届比赛有了非常大的提升,ResNet毫无悬念地夺得了ILSVRC2015的第一名。如下图所示:

-
在ResNet的作者的第二篇相关论文《Identity Mappings in Deep Residual Networks》中,提出了ResNet V2。ResNet V2 和 ResNet V1 的主要区别在于,作者通过研究 ResNet 残差学习单元的传播公式,发现前馈和反馈信号可以直接传输,因此“shortcut connection”(捷径连接)的非线性激活函数(如ReLU)替换为 Identity Mappings。同时,ResNet V2 在每一层中都使用了 Batch Normalization。这样处理后,新的残差学习单元比以前更容易训练且泛化性更强。
3、ResNet案例-cifar100分类数据集
3.1 自定义ResNet神经网络【Tensorflow2】
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2' # 放在 import tensorflow as tf 之前才有效
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers, optimizers, datasets, Sequential
#==========================================自定义ResNet神经网络:开始==========================================
# 两层的残差学习单元 BasicBlock [(3×3)-->(3×3)]形状,如果是三层的BasicBlock,形状则为:[(1×1)-->(3×3)-->(1×1)]
# stride>1时(比如stride=2),则通过改层Layer后的FeatureMap的大小减半。strides: An integer or tuple/list of 2 integers
class BasicBlock(layers.Layer):
def __init__(self, filter_count, stride=1):
super(BasicBlock, self).__init__()
# ================================F(x) 部分================================
# Layer01
self.conv1 = layers.Conv2D(filters=filter_count, kernel_size=[3, 3], strides=stride, padding='same') # 如果padding='same'&stride!=1:输出维度是输入维度的stride分之一。
self.bn1 = layers.BatchNormalization()
self.relu = layers.Activation('relu')
# Layer02
self.conv2 = layers.Conv2D(filters=filter_count, kernel_size=[3, 3], strides=1, padding='same') # padding='same'&stride==1:输出维度与输入维度一致。
self.bn2 = layers.BatchNormalization()
# ================================identity(x)部分================================
if stride != 1: # 如果 stride != 1,F(x)部分的输入维度减小stride倍。所以利用一层大小为[1×1×filter_count]的卷积层identity_layer设置strides与F(x)部分的stride一致,将输入值x的维度调整为和F(x)的维度一致,即进行SubSampling。然后再进行加和计算 H(x)=x+F(X)
self.identity_layer = layers.Conv2D(filters=filter_count, kernel_size=[1, 1], strides=stride)
else: # 如果 stride = 1,则F(x)输出值与输入值x的维度保持不变(必须保证F(x)部分的padding='same'才能维度不变)。所以identity_layer部分直接可以和F(x)部分进行加和计算,不需要经过卷积层对x进行维度调整。也可减少参数的使用。
self.identity_layer = lambda x: x # lambda匿名函数:输入为x,return x
def call(self, inputs, training=None):
# 前向传播 # [b, h, w, c]
# ================================F(x) 部分================================
# Layer01
F_out = self.conv1(inputs)
F_out = self.bn1(F_out)
F_out = self.relu(F_out)
# Layer02
F_out = self.conv2(F_out)
F_out = self.bn2(F_out)
# ================================identity部分================================
# x=identity(x)
identity_out = self.identity_layer(inputs)
# ================================H(x)=F(x)+x================================
basic_block_output = layers.add([F_out, identity_out]) # layers.add(): A tensor as the sum of the inputs. It has the same shape as the inputs.
basic_block_output = tf.nn.relu(basic_block_output)
return basic_block_output
# 由多个BasicBlock组成的ResidualBlock
class ResidualBlock:
def __init__(self, filter_count, residualBlock_size, stride=1):
self.filter_count = filter_count
self.residualBlock_size = residualBlock_size
self.stride = stride
def __call__(self):
basic_block_stride_not_1 = BasicBlock(self.filter_count, stride=self.stride) # stride != 1 时的BasicBlock H(x)=x+F(X),identity_layer进行SubSampling
basic_block_stride_1 = BasicBlock(self.filter_count, stride=1) # stride = 1 时的BasicBlock H(x)=x+F(X),identity_layer层的输出为直接返回输入
residualBlock = Sequential()
residualBlock.add(basic_block_stride_not_1) # 有一个BasicBlock必须是 stride != 1 时的BasicBlock
for _ in range(1, self.residualBlock_size): # 其余的BasicBlock都是 stride == 1 时的BasicBlock
residualBlock.add(basic_block_stride_1)
return residualBlock
# 由多个ResidualBlock组成的ResidualNet
# residualBlock_size_list:[2, 2, 2, 2] 表示该ResidualNet含有4个ResidualBlock,每个ResidualBlock包含2个BasicBlock
# residualBlock_size_list:[3, 4, 6, 3] 表示该ResidualNet含有4个ResidualBlock,第1个ResidualBlock包含3个BasicBlock,第2个ResidualBlock包含4个BasicBlock,第3个ResidualBlock包含6个BasicBlock,第4个ResidualBlock包含3个BasicBlock
class ResidualNet(keras.Model):
def __init__(self, residualBlock_size_list, class_count=100): # class_count:表示全连接层的输出维度,取决于数据集分类的类别总数量(cifar100为100类)
super(ResidualNet, self).__init__()
# ================================预处理Block================================
self.preprocessBlock = Sequential([layers.Conv2D(filters=50, kernel_size=[3, 3], strides=(1, 1)),
layers.BatchNormalization(),
layers.Activation('relu'),
layers.MaxPool2D(pool_size=(2, 2), strides=(1, 1), padding='same')
])
# ================================所有ResidualBlock================================
residualBlock01_size = residualBlock_size_list[0]
residualBlock02_size = residualBlock_size_list[1]
residualBlock03_size = residualBlock_size_list[2]
residualBlock04_size = residualBlock_size_list[3]
self.residualBlock1 = ResidualBlock(50, residualBlock01_size, stride=1)() # 第01个ResidualBlock,包含residualBlock01_size个BasicBlock,residualBlock1设置为64通道
self.residualBlock2 = ResidualBlock(150, residualBlock02_size, stride=2)() # 第02个ResidualBlock,包含residualBlock02_size个BasicBlock,residualBlock2设置为128通道
self.residualBlock3 = ResidualBlock(300, residualBlock03_size, stride=2)() # 第03个ResidualBlock,包含residualBlock03_size个BasicBlock,residualBlock3设置为256通道
self.residualBlock4 = ResidualBlock(500, residualBlock04_size, stride=2)() # 第04个ResidualBlock,包含residualBlock04_size个BasicBlock,residualBlock4设置为512通道
# ================================输出层================================
# output: [b, h, w, 500] 以上步骤输出的FeatureMap的大小[h,w]不太方便计算
self.avgpool_Layer = layers.GlobalAveragePooling2D() # 不管输入的每一个FeatureMap的大小[h,w]是多少,取每一个FeatureMap上的所有元素的平均值作为输出。所以该步骤输出的数据维度为[1,500]
# 将上一层的维度为[1,500]的输出传给全连接层进行分类,输出维度为[1,class_count]
self.fullcon_Layer = layers.Dense(class_count)
def call(self, inputs, training=None):
# ================================预处理Block================================
x = self.preprocessBlock(inputs) # 输出维度:[b, h, w, 50]
# ================================所有ResidualBlock================================
x = self.residualBlock1(x) # 输出维度:[b, h, w, 50]
x = self.residualBlock2(x) # 输出维度:[b, h, w, 150]
x = self.residualBlock3(x) # 输出维度:[b, h, w, 300]
x = self.residualBlock4(x) # 输出维度:[b, h, w, 500]
# ================================输出层================================
x = self.avgpool_Layer(x) # 输出维度:[b, 500]
x = self.fullcon_Layer(x) # 输出维度:[b, 100]
return x
def resnet18():
return ResidualNet([2, 2, 2, 2])
def resnet34():
return ResidualNet([3, 4, 6, 3])
#==========================================自定义ResNet神经网络:结束==========================================
# 一、获取数据集
(X_train, Y_train), (X_val, Y_val) = datasets.cifar100.load_data()
print('X_train.shpae = {0},Y_train.shpae = {1}------------type(X_train) = {2},type(Y_train) = {3}'.format(X_train.shape, Y_train.shape, type(X_train), type(Y_train)))
Y_train = tf.squeeze(Y_train)
Y_val = tf.squeeze(Y_val)
print('X_train.shpae = {0},Y_train.shpae = {1}------------type(X_train) = {2},type(Y_train) = {3}'.format(X_train.shape, Y_train.shape, type(X_train), type(Y_train)))
# 二、数据处理
# 预处理函数:将numpy数据转为tensor
def preprocess(x, y):
x = tf.cast(x, dtype=tf.float32) / 255.
y = tf.cast(y, dtype=tf.int32)
return x, y
# 2.1 处理训练集
# print('X_train.shpae = {0},Y_train.shpae = {1}------------type(X_train) = {2},type(Y_train) = {3}'.format(X_train.shape, Y_train.shape, type(X_train), type(Y_train)))
db_train = tf.data.Dataset.from_tensor_slices((X_train, Y_train)) # 此步骤自动将numpy类型的数据转为tensor
db_train = db_train.map(preprocess) # 调用map()函数批量修改每一个元素数据的数据类型
# 从data数据集中按顺序抽取buffer_size个样本放在buffer中,然后打乱buffer中的样本。buffer中样本个数不足buffer_size,继续从data数据集中安顺序填充至buffer_size,此时会再次打乱。
db_train = db_train.shuffle(buffer_size=1000) # 打散db_train中的样本顺序,防止图片的原始顺序对神经网络性能的干扰。
print('db_train = {0},type(db_train) = {1}'.format(db_train, type(db_train)))
batch_size_train = 500 # 每个batch里的样本数量设置100-200之间合适。
db_batch_train = db_train.batch(batch_size_train) # 将db_batch_train中每sample_num_of_each_batch_train张图片分为一个batch,读取一个batch相当于一次性并行读取sample_num_of_each_batch_train张图片
print('db_batch_train = {0},type(db_batch_train) = {1}'.format(db_batch_train, type(db_batch_train)))
# 2.2 处理测试集:测试数据集不需要打乱顺序
db_val = tf.data.Dataset.from_tensor_slices((X_val, Y_val)) # 此步骤自动将numpy类型的数据转为tensor
db_val = db_val.map(preprocess) # 调用map()函数批量修改每一个元素数据的数据类型
batch_size_val = 500 # 每个batch里的样本数量设置100-200之间合适。
db_batch_val = db_val.batch(batch_size_val) # 将db_val中每sample_num_of_each_batch_val张图片分为一个batch,读取一个batch相当于一次性并行读取sample_num_of_each_batch_val张图片
# 三、构建ResNet神经网络
# 1、构建ResNet神经网络
resnet18_network = resnet18()
resnet18_network.build(input_shape=[None, 32, 32, 3]) # 原始图片维度为:[32, 32, 3],None表示样本数量,是不确定的值。
# 2、打印神经网络信息
resnet18_network.summary() # 打印卷积神经网络network的简要信息
# 四、梯度下降优化器设置
optimizer = optimizers.Adam(lr=1e-3)
# 五、整体数据集进行一次梯度下降来更新模型参数,整体数据集迭代一次,一般用epoch。每个epoch中含有batch_step_no个step,每个step中就是设置的每个batch所含有的样本数量。
def train_epoch(epoch_no):
print('++++++++++++++++++++++++++++++++++++++++++++第{0}轮Epoch-->Training 阶段:开始++++++++++++++++++++++++++++++++++++++++++++'.format(epoch_no))
for batch_step_no, (X_batch, Y_batch) in enumerate(db_batch_train): # 每次计算一个batch的数据,循环结束则计算完毕整体数据的一次梯度下降;每个batch的序号一般用step表示(batch_step_no)
print('epoch_no = {0}, batch_step_no = {1},X_batch.shpae = {2},Y_batch.shpae = {3}------------type(X_batch) = {4},type(Y_batch) = {5}'.format(epoch_no, batch_step_no + 1, X_batch.shape, Y_batch.shape, type(X_batch), type(Y_batch)))
Y_batch_one_hot = tf.one_hot(Y_batch, depth=100) # One-Hot编码,共有100类 [] => [b,100]
print('\tY_train_one_hot.shpae = {0}'.format(Y_batch_one_hot.shape))
# 梯度带tf.GradientTape:连接需要计算梯度的”函数“和”变量“的上下文管理器(context manager)。将“函数”(即Loss的定义式)与“变量”(即神经网络的所有参数)都包裹在tf.GradientTape中进行追踪管理
with tf.GradientTape() as tape:
# Step1. 前向传播/前向运算-->计算当前参数下模型的预测值
out_logits = resnet18_network(X_batch) # [b, 32, 32, 3] => [b, 100]
print('\tout_logits.shape = {0}'.format(out_logits.shape))
# Step2. 计算预测值与真实值之间的损失Loss:交叉熵损失
MSE_Loss = tf.losses.categorical_crossentropy(Y_batch_one_hot, out_logits, from_logits=True) # categorical_crossentropy()第一个参数是真实值,第二个参数是预测值,顺序不能颠倒
print('\tMSE_Loss.shape = {0}'.format(MSE_Loss.shape))
MSE_Loss = tf.reduce_mean(MSE_Loss)
print('\t求均值后:MSE_Loss.shape = {0}'.format(MSE_Loss.shape))
print('\t第{0}个epoch-->第{1}个batch step的初始时的:MSE_Loss = {2}'.format(epoch_no, batch_step_no + 1, MSE_Loss))
# Step3. 反向传播-->损失值Loss下降一个学习率的梯度之后所对应的更新后的各个Layer的参数:W1, W2, W3, B1, B2, B3...
# grads为整个全连接神经网络模型中所有Layer的待优化参数trainable_variables [W1, W2, W3, B1, B2, B3...]分别对目标函数MSE_Loss 在 X_batch 处的梯度值,
grads = tape.gradient(MSE_Loss, resnet18_network.trainable_variables) # grads为梯度值。MSE_Loss为目标函数,variables为卷积神经网络、全连接神经网络所有待优化参数,
# grads, _ = tf.clip_by_global_norm(grads, 15) # 限幅:解决gradient explosion或者gradients vanishing的问题。
# print('\t第{0}个epoch-->第{1}个batch step的初始时的参数:'.format(epoch_no, batch_step_no + 1))
if batch_step_no == 0:
index_variable = 1
for grad in grads:
print('\t\tgrad{0}:grad.shape = {1},grad.ndim = {2}'.format(index_variable, grad.shape, grad.ndim))
index_variable = index_variable + 1
# 进行一次梯度下降
print('\t梯度下降步骤-->optimizer.apply_gradients(zip(grads, resnet18_network.trainable_variables)):开始')
optimizer.apply_gradients(zip(grads, resnet18_network.trainable_variables)) # network的所有参数 trainable_variables [W1, W2, W3, B1, B2, B3...]下降一个梯度 w' = w - lr * grad,zip的作用是让梯度值与所属参数前后一一对应
print('\t梯度下降步骤-->optimizer.apply_gradients(zip(grads, resnet18_network.trainable_variables)):结束\n')
print('++++++++++++++++++++++++++++++++++++++++++++第{0}轮Epoch-->Training 阶段:结束++++++++++++++++++++++++++++++++++++++++++++'.format(epoch_no))
# 六、模型评估 test/evluation
def evluation(epoch_no):
print('++++++++++++++++++++++++++++++++++++++++++++第{0}轮Epoch-->Evluation 阶段:开始++++++++++++++++++++++++++++++++++++++++++++'.format(epoch_no))
total_correct, total_num = 0, 0
for batch_step_no, (X_batch, Y_batch) in enumerate(db_batch_val):
print('epoch_no = {0}, batch_step_no = {1},X_batch.shpae = {2},Y_batch.shpae = {3}'.format(epoch_no, batch_step_no + 1, X_batch.shape, Y_batch.shape))
# 根据训练模型计算测试数据的输出值out
out_logits = resnet18_network(X_batch) # [b, 32, 32, 3] => [b, 100]
print('\tout_logits.shape = {0}'.format(out_logits.shape))
# print('\tout_logits_fullcon[:1,:] = {0}'.format(out_logits_fullcon[:1, :]))
# 利用softmax()函数将network的输出值转为0~1范围的值,并且使得所有类别预测概率总和为1
out_logits_prob = tf.nn.softmax(out_logits, axis=1) # out_logits_prob: [b, 100] ~ [0, 1]
# print('\tout_logits_prob[:1,:] = {0}'.format(out_logits_prob[:1, :]))
out_logits_prob_max_index = tf.cast(tf.argmax(out_logits_prob, axis=1), dtype=tf.int32) # [b, 100] => [b] 查找最大值所在的索引位置 int64 转为 int32
# print('\t预测值:out_logits_prob_max_index = {0},\t真实值:Y_train_one_hot = {1}'.format(out_logits_prob_max_index, Y_batch))
is_correct_boolean = tf.equal(out_logits_prob_max_index, Y_batch.numpy())
# print('\tis_correct_boolean = {0}'.format(is_correct_boolean))
is_correct_int = tf.cast(is_correct_boolean, dtype=tf.float32)
# print('\tis_correct_int = {0}'.format(is_correct_int))
is_correct_count = tf.reduce_sum(is_correct_int)
print('\tis_correct_count = {0}\n'.format(is_correct_count))
total_correct += int(is_correct_count)
total_num += X_batch.shape[0]
print('total_correct = {0}---total_num = {1}'.format(total_correct, total_num))
acc = total_correct / total_num
print('第{0}轮Epoch迭代的准确度: acc = {1}'.format(epoch_no, acc))
print('++++++++++++++++++++++++++++++++++++++++++++第{0}轮Epoch-->Evluation 阶段:结束++++++++++++++++++++++++++++++++++++++++++++'.format(epoch_no))
# 七、整体数据迭代多次梯度下降来更新模型参数
def train():
epoch_count = 1 # epoch_count为整体数据集迭代梯度下降次数
for epoch_no in range(1, epoch_count + 1):
print('\n\n利用整体数据集进行模型的第{0}轮Epoch迭代开始:**********************************************************************************************************************************'.format(epoch_no))
train_epoch(epoch_no)
evluation(epoch_no)
print('利用整体数据集进行模型的第{0}轮Epoch迭代结束:**********************************************************************************************************************************'.format(epoch_no))
if __name__ == '__main__':
train()
打印结果:
X_train.shpae = (50000, 32, 32, 3),Y_train.shpae = (50000, 1)------------type(X_train) = <class 'numpy.ndarray'>,type(Y_train) = <class 'numpy.ndarray'>
X_train.shpae = (50000, 32, 32, 3),Y_train.shpae = (50000,)------------type(X_train) = <class 'numpy.ndarray'>,type(Y_train) = <class 'tensorflow.python.framework.ops.EagerTensor'>
db_train = <ShuffleDataset shapes: ((32, 32, 3), ()), types: (tf.float32, tf.int32)>,type(db_train) = <class 'tensorflow.python.data.ops.dataset_ops.ShuffleDataset'>
db_batch_train = <BatchDataset shapes: ((None, 32, 32, 3), (None,)), types: (tf.float32, tf.int32)>,type(db_batch_train) = <class 'tensorflow.python.data.ops.dataset_ops.BatchDataset'>
Model: "residual_net"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
sequential (Sequential) (None, 30, 30, 50) 1600
_________________________________________________________________
sequential_1 (Sequential) (None, 30, 30, 50) 91000
_________________________________________________________________
sequential_2 (Sequential) (None, 15, 15, 150) 685650
_________________________________________________________________
sequential_3 (Sequential) (None, 8, 8, 300) 2886300
_________________________________________________________________
sequential_4 (Sequential) (None, 4, 4, 500) 8260500
_________________________________________________________________
global_average_pooling2d (Gl multiple 0
_________________________________________________________________
dense (Dense) multiple 50100
=================================================================
Total params: 11,975,150
Trainable params: 11,967,050
Non-trainable params: 8,100
_________________________________________________________________
利用整体数据集进行模型的第1轮Epoch迭代开始:**********************************************************************************************************************************
++++++++++++++++++++++++++++++++++++++++++++第1轮Epoch-->Training 阶段:开始++++++++++++++++++++++++++++++++++++++++++++
epoch_no = 1, batch_step_no = 1,X_batch.shpae = (500, 32, 32, 3),Y_batch.shpae = (500,)------------type(X_batch) = <class 'tensorflow.python.framework.ops.EagerTensor'>,type(Y_batch) = <class 'tensorflow.python.framework.ops.EagerTensor'>
Y_train_one_hot.shpae = (500, 100)
out_logits.shape = (500, 100)
MSE_Loss.shape = (500,)
求均值后:MSE_Loss.shape = ()
第1个epoch-->第1个batch step的初始时的:MSE_Loss = 4.608854293823242
grad1:grad.shape = (3, 3, 3, 50),grad.ndim = 4
grad2:grad.shape = (50,),grad.ndim = 1
grad3:grad.shape = (50,),grad.ndim = 1
grad4:grad.shape = (50,),grad.ndim = 1
grad5:grad.shape = (3, 3, 50, 50),grad.ndim = 4
grad6:grad.shape = (50,),grad.ndim = 1
grad7:grad.shape = (50,),grad.ndim = 1
grad8:grad.shape = (50,),grad.ndim = 1
grad9:grad.shape = (3, 3, 50, 50),grad.ndim = 4
grad10:grad.shape = (50,),grad.ndim = 1
grad11:grad.shape = (50,),grad.ndim = 1
grad12:grad.shape = (50,),grad.ndim = 1
grad13:grad.shape = (3, 3, 50, 50),grad.ndim = 4
grad14:grad.shape = (50,),grad.ndim = 1
grad15:grad.shape = (50,),grad.ndim = 1
grad16:grad.shape = (50,),grad.ndim = 1
grad17:grad.shape = (3, 3, 50, 50),grad.ndim = 4
grad18:grad.shape = (50,),grad.ndim = 1
grad19:grad.shape = (50,),grad.ndim = 1
grad20:grad.shape = (50,),grad.ndim = 1
grad21:grad.shape = (3, 3, 50, 150),grad.ndim = 4
grad22:grad.shape = (150,),grad.ndim = 1
grad23:grad.shape = (150,),grad.ndim = 1
grad24:grad.shape = (150,),grad.ndim = 1
grad25:grad.shape = (3, 3, 150, 150),grad.ndim = 4
grad26:grad.shape = (150,),grad.ndim = 1
grad27:grad.shape = (150,),grad.ndim = 1
grad28:grad.shape = (150,),grad.ndim = 1
grad29:grad.shape = (1, 1, 50, 150),grad.ndim = 4
grad30:grad.shape = (150,),grad.ndim = 1
grad31:grad.shape = (3, 3, 150, 150),grad.ndim = 4
grad32:grad.shape = (150,),grad.ndim = 1
grad33:grad.shape = (150,),grad.ndim = 1
grad34:grad.shape = (150,),grad.ndim = 1
grad35:grad.shape = (3, 3, 150, 150),grad.ndim = 4
grad36:grad.shape = (150,),grad.ndim = 1
grad37:grad.shape = (150,),grad.ndim = 1
grad38:grad.shape = (150,),grad.ndim = 1
grad39:grad.shape = (3, 3, 150, 300),grad.ndim = 4
grad40:grad.shape = (300,),grad.ndim = 1
grad41:grad.shape = (300,),grad.ndim = 1
grad42:grad.shape = (300,),grad.ndim = 1
grad43:grad.shape = (3, 3, 300, 300),grad.ndim = 4
grad44:grad.shape = (300,),grad.ndim = 1
grad45:grad.shape = (300,),grad.ndim = 1
grad46:grad.shape = (300,),grad.ndim = 1
grad47:grad.shape = (1, 1, 150, 300),grad.ndim = 4
grad48:grad.shape = (300,),grad.ndim = 1
grad49:grad.shape = (3, 3, 300, 300),grad.ndim = 4
grad50:grad.shape = (300,),grad.ndim = 1
grad51:grad.shape = (300,),grad.ndim = 1
grad52:grad.shape = (300,),grad.ndim = 1
grad53:grad.shape = (3, 3, 300, 300),grad.ndim = 4
grad54:grad.shape = (300,),grad.ndim = 1
grad55:grad.shape = (300,),grad.ndim = 1
grad56:grad.shape = (300,),grad.ndim = 1
grad57:grad.shape = (3, 3, 300, 500),grad.ndim = 4
grad58:grad.shape = (500,),grad.ndim = 1
grad59:grad.shape = (500,),grad.ndim = 1
grad60:grad.shape = (500,),grad.ndim = 1
grad61:grad.shape = (3, 3, 500, 500),grad.ndim = 4
grad62:grad.shape = (500,),grad.ndim = 1
grad63:grad.shape = (500,),grad.ndim = 1
grad64:grad.shape = (500,),grad.ndim = 1
grad65:grad.shape = (1, 1, 300, 500),grad.ndim = 4
grad66:grad.shape = (500,),grad.ndim = 1
grad67:grad.shape = (3, 3, 500, 500),grad.ndim = 4
grad68:grad.shape = (500,),grad.ndim = 1
grad69:grad.shape = (500,),grad.ndim = 1
grad70:grad.shape = (500,),grad.ndim = 1
grad71:grad.shape = (3, 3, 500, 500),grad.ndim = 4
grad72:grad.shape = (500,),grad.ndim = 1
grad73:grad.shape = (500,),grad.ndim = 1
grad74:grad.shape = (500,),grad.ndim = 1
grad75:grad.shape = (500, 100),grad.ndim = 2
grad76:grad.shape = (100,),grad.ndim = 1
梯度下降步骤-->optimizer.apply_gradients(zip(grads, resnet18_network.trainable_variables)):开始
梯度下降步骤-->optimizer.apply_gradients(zip(grads, resnet18_network.trainable_variables)):结束
epoch_no = 1, batch_step_no = 2,X_batch.shpae = (500, 32, 32, 3),Y_batch.shpae = (500,)------------type(X_batch) = <class 'tensorflow.python.framework.ops.EagerTensor'>,type(Y_batch) = <class 'tensorflow.python.framework.ops.EagerTensor'>
Y_train_one_hot.shpae = (500, 100)
out_logits.shape = (500, 100)
MSE_Loss.shape = (500,)
求均值后:MSE_Loss.shape = ()
第1个epoch-->第2个batch step的初始时的:MSE_Loss = 5.222436428070068
梯度下降步骤-->optimizer.apply_gradients(zip(grads, resnet18_network.trainable_variables)):开始
梯度下降步骤-->optimizer.apply_gradients(zip(grads, resnet18_network.trainable_variables)):结束
...
...
...
...
...
epoch_no = 1, batch_step_no = 100,X_batch.shpae = (500, 32, 32, 3),Y_batch.shpae = (500,)------------type(X_batch) = <class 'tensorflow.python.framework.ops.EagerTensor'>,type(Y_batch) = <class 'tensorflow.python.framework.ops.EagerTensor'>
Y_train_one_hot.shpae = (500, 100)
out_logits.shape = (500, 100)
MSE_Loss.shape = (500,)
求均值后:MSE_Loss.shape = ()
第1个epoch-->第100个batch step的初始时的:MSE_Loss = 4.207188129425049
梯度下降步骤-->optimizer.apply_gradients(zip(grads, resnet18_network.trainable_variables)):开始
梯度下降步骤-->optimizer.apply_gradients(zip(grads, resnet18_network.trainable_variables)):结束
++++++++++++++++++++++++++++++++++++++++++++第1轮Epoch-->Training 阶段:结束++++++++++++++++++++++++++++++++++++++++++++
++++++++++++++++++++++++++++++++++++++++++++第1轮Epoch-->Evluation 阶段:开始++++++++++++++++++++++++++++++++++++++++++++
epoch_no = 1, batch_step_no = 1,X_batch.shpae = (500, 32, 32, 3),Y_batch.shpae = (500,)
out_logits.shape = (500, 100)
is_correct_count = 18.0
epoch_no = 1, batch_step_no = 2,X_batch.shpae = (500, 32, 32, 3),Y_batch.shpae = (500,)
out_logits.shape = (500, 100)
is_correct_count = 27.0
...
...
...
epoch_no = 1, batch_step_no = 20,X_batch.shpae = (500, 32, 32, 3),Y_batch.shpae = (500,)
out_logits.shape = (500, 100)
is_correct_count = 26.0
total_correct = 454---total_num = 10000
第1轮Epoch迭代的准确度: acc = 0.0454
++++++++++++++++++++++++++++++++++++++++++++第1轮Epoch-->Evluation 阶段:结束++++++++++++++++++++++++++++++++++++++++++++
利用整体数据集进行模型的第1轮Epoch迭代结束:**********************************************************************************************************************************
Process finished with exit code 0
3.2 自定义ResNet神经网络【Pytorch】
import torch
from torch.utils.data import DataLoader
from torchvision import datasets
from torchvision import transforms
from torch import nn, optim
from torch.nn import functional as F
# 两层的残差学习单元 BasicBlock [(3×3)-->(3×3)]形状,如果是三层的BasicBlock,形状则为:[(1×1)-->(3×3)-->(1×1)]
# filter_count_in≠filter_count_out时,则通过该层Layer后的FeatureMap的大小改变,identity层也需要reshape
class BasicBlock(nn.Module):
def __init__(self, filter_count_in, filter_count_out, stride=1):
super(BasicBlock, self).__init__()
# we add stride support for resbok, which is distinct from tutorials.
self.conv1 = nn.Conv2d(in_channels=filter_count_in, out_channels=filter_count_out, kernel_size=3, stride=stride, padding=1)
self.bn1 = nn.BatchNorm2d(filter_count_out)
self.conv2 = nn.Conv2d(filter_count_out, filter_count_out, kernel_size=3, stride=1, padding=1)
self.bn2 = nn.BatchNorm2d(filter_count_out)
self.identity = nn.Sequential()
if filter_count_in != filter_count_out: # 将输入值x的维度调整为和F(x)的输出维度保持一致 [b, filter_count_in, h, w] => [b, filter_count_out, h, w]
self.identity = nn.Sequential(
nn.Conv2d(filter_count_in, filter_count_out, kernel_size=1, stride=stride),
nn.BatchNorm2d(filter_count_out)
)
def forward(self, input):
x = self.conv1(input)
x = self.bn1(x)
x = F.relu(x)
x = self.conv2(x)
F_out = self.bn2(x)
# short cut
identity_out = self.identity(input) # 调整input的维度与F_out保持一致,然后才能和F_out相加:[b, ch_in, h, w] => [b, ch_out, h, w]
H_out = identity_out + F_out
H_out = F.relu(H_out)
return H_out
# 由多个BasicBlock组成的ResidualBlock
class ResidualBlock:
def __init__(self, filter_count_in, filter_count_out, residualBlock_size=1, stride=1):
self.filter_count_in = filter_count_in
self.filter_count_out = filter_count_out
self.residualBlock_size = residualBlock_size
self.stride = stride
def __call__(self):
basic_block_stride_eq = BasicBlock(self.filter_count_in, self.filter_count_in, stride=1) # stride = 1 时的BasicBlock H(x)=x+F(X),identity_layer层的输出为直接返回输入
basic_block_stride_not_eq = BasicBlock(self.filter_count_in, self.filter_count_out, stride=self.stride) # stride != 1 时的BasicBlock H(x)=x+F(X),identity_layer进行SubSampling
residualBlock = nn.Sequential()
for _ in range(0, self.residualBlock_size - 1): # 其余的BasicBlock都是 filter_count_in == filter_count_out 时的BasicBlock
residualBlock.add_module('basic_block_stride_eq', basic_block_stride_eq)
residualBlock.add_module('basic_block_stride_not_eq', basic_block_stride_not_eq) # 有一个BasicBlock必须是 filter_count_in != filter_count_out 时的BasicBlock
return residualBlock
# 由多个ResidualBlock组成的ResidualNet
class ResNet18(nn.Module):
def __init__(self):
super(ResNet18, self).__init__()
self.conv1 = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=3, stride=3, padding=0),
nn.BatchNorm2d(64)
)
# followed 4 ResidualBlock
self.residualBlock1 = ResidualBlock(filter_count_in=64, filter_count_out=128, residualBlock_size=2, stride=2)() # [b, 64, h, w] => [b, 128, h ,w]
self.residualBlock2 = ResidualBlock(filter_count_in=128, filter_count_out=256, residualBlock_size=2, stride=2)() # [b, 128, h, w] => [b, 256, h, w]
self.residualBlock3 = ResidualBlock(filter_count_in=256, filter_count_out=512, residualBlock_size=2, stride=2)() # [b, 256, h, w] => [b, 512, h, w]
self.residualBlock4 = ResidualBlock(filter_count_in=512, filter_count_out=512, residualBlock_size=2, stride=2)() # [b, 512, h, w] => [b, 1024, h, w]
self.outlayer = nn.Linear(512 * 1 * 1, 10)
def forward(self, X):
X = F.relu(self.conv1(X))
# [b, 64, h, w] => [b, 1024, h, w]
X = self.residualBlock1(X)
X = self.residualBlock2(X)
X = self.residualBlock3(X)
X = self.residualBlock4(X) # [b, 512, 2, 2]
X = F.adaptive_avg_pool2d(X, [1, 1]) # [b, 512, 2, 2] => [b, 512, 1, 1]
X = X.view(X.size(0), -1) # [b, 512, 1, 1] => [b, 512]
X = self.outlayer(X) # [b, 512] => [b, 10]
return X
def main():
batch_size = 200
# 一、获取cifar10训练数据集
cifar_train = datasets.CIFAR10('cifar', True, transform=transforms.Compose([
transforms.Resize((32, 32)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
]), download=True)
cifar_train = DataLoader(cifar_train, batch_size=batch_size, shuffle=True)
cifar_test = datasets.CIFAR10('cifar', False, transform=transforms.Compose([
transforms.Resize((32, 32)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
]), download=True)
cifar_test = DataLoader(cifar_test, batch_size=batch_size, shuffle=True)
# 二、设置GPU
device = torch.device('cuda')
# 三、实例化ResNet18神经网络模型
model = ResNet18().to(device)
# Find total parameters and trainable parameters
total_params = sum(p.numel() for p in model.parameters())
print(f'{total_params:,} total parameters.')
total_trainable_params = sum(
p.numel() for p in model.parameters() if p.requires_grad)
print(f'{total_trainable_params:,} training parameters.')
print('model = {0}\n'.format(model))
# 四、实例化损失函数
criteon = nn.CrossEntropyLoss().to(device)
# 五、梯度下降优化器设置
optimizer = optim.Adam(model.parameters(), lr=1e-3)
# 六、训练
for epoch in range(3):
# **********************************************************训练**********************************************************
print('**************************训练模式:开始**************************')
model.train() # 切换至训练模式
for batch_index, (X_batch, Y_batch) in enumerate(cifar_train):
X_batch, Y_batch = X_batch.to(device), Y_batch.to(device)
out_logits = model(X_batch)
loss = criteon(out_logits, Y_batch)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if batch_index % 100 == 0:
print('epoch = {0}, batch_index = {1}, loss.item() = {2}'.format(epoch, batch_index, loss.item()))
print('**************************训练模式:结束**************************')
# **********************************************************模型评估**********************************************************
print('**************************验证模式:开始**************************')
model.eval() # 切换至验证模式
with torch.no_grad(): # torch.no_grad()所包裹的部分不需要参与反向传播
# test
total_correct = 0
total_num = 0
for batch_index, (X_batch, Y_batch) in enumerate(cifar_test):
X_batch, Y_batch = X_batch.to(device), Y_batch.to(device)
out_logits = model(X_batch)
out_pred = out_logits.argmax(dim=1)
correct = torch.eq(out_pred, Y_batch).float().sum().item()
total_correct += correct
total_num += X_batch.size(0)
acc = total_correct / total_num
if batch_index % 100 == 0:
print('epoch = {0}, batch_index = {1}, test acc = {2}'.format(epoch, batch_index, acc))
print('**************************验证模式:结束**************************')
if __name__ == '__main__':
main()
打印结果:
Files already downloaded and verified
Files already downloaded and verified
15,826,314 total parameters.
15,826,314 training parameters.
model = ResNet18(
(conv1): Sequential(
(0): Conv2d(3, 64, kernel_size=(3, 3), stride=(3, 3))
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(residualBlock1): Sequential(
(basic_block_stride_eq): BasicBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(basic_block_stride_not_eq): BasicBlock(
(conv1): Conv2d(64, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(identity): Sequential(
(0): Conv2d(64, 128, kernel_size=(1, 1), stride=(2, 2))
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
)
(residualBlock2): Sequential(
(basic_block_stride_eq): BasicBlock(
(conv1): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(basic_block_stride_not_eq): BasicBlock(
(conv1): Conv2d(128, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(identity): Sequential(
(0): Conv2d(128, 256, kernel_size=(1, 1), stride=(2, 2))
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
)
(residualBlock3): Sequential(
(basic_block_stride_eq): BasicBlock(
(conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(basic_block_stride_not_eq): BasicBlock(
(conv1): Conv2d(256, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(identity): Sequential(
(0): Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2))
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
)
(residualBlock4): Sequential(
(basic_block_stride_eq): BasicBlock(
(conv1): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(basic_block_stride_not_eq): BasicBlock(
(conv1): Conv2d(512, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(outlayer): Linear(in_features=512, out_features=10, bias=True)
)
**************************训练模式:开始**************************
epoch = 0, batch_index = 0, loss.item() = 2.784912109375
epoch = 0, batch_index = 100, loss.item() = 1.2591865062713623
epoch = 0, batch_index = 200, loss.item() = 1.2418736219406128
**************************训练模式:结束**************************
**************************验证模式:开始**************************
epoch = 0, batch_index = 0, test acc = 0.515
**************************验证模式:结束**************************
**************************训练模式:开始**************************
epoch = 1, batch_index = 0, loss.item() = 1.0537413358688354
epoch = 1, batch_index = 100, loss.item() = 1.088006615638733
epoch = 1, batch_index = 200, loss.item() = 1.0332653522491455
**************************训练模式:结束**************************
**************************验证模式:开始**************************
epoch = 1, batch_index = 0, test acc = 0.635
**************************验证模式:结束**************************
**************************训练模式:开始**************************
epoch = 2, batch_index = 0, loss.item() = 0.9080470204353333
epoch = 2, batch_index = 100, loss.item() = 0.7950635552406311
epoch = 2, batch_index = 200, loss.item() = 0.7487978339195251
**************************训练模式:结束**************************
**************************验证模式:开始**************************
epoch = 2, batch_index = 0, test acc = 0.64
**************************验证模式:结束**************************
Process finished with exit code 0
3.3 自定义ResNet18&自定义数据集【Pytorch】
import torch
from torch.utils.data import DataLoader
from torch import nn, optim
from torch.nn import functional as F
import visdom
import csv
import glob
import os
import random
from PIL import Image
from torch.utils.data import Dataset # 自定义数据集的父类
from torchvision import transforms
torch.manual_seed(1234) # 随机种子
device = torch.device('cuda') # 设置GPU
# =============================================================================Pokemon自定义数据集:开始=============================================================================
class Pokemon(Dataset):
# root表示数据位置;resize表示数据输出的size;mode表示训练模式/测试模式
def __init__(self, root, resize, mode):
super(Pokemon, self).__init__()
self.root = root
self.resize = resize
# 给各个类型进行编号
self.name2label = {} # {'bulbasaur': 0, 'charmander': 1, 'mewtwo': 2, 'pikachu': 3, 'squirtle': 4}
for name in sorted(os.listdir(os.path.join(root))):
if not os.path.isdir(os.path.join(root, name)): # 过滤掉不是文件夹的文件
continue
self.name2label[name] = len(self.name2label.keys())
print('self.name2label = {0}'.format(self.name2label)) # {'bulbasaur': 0, 'charmander': 1, 'mewtwo': 2, 'pikachu': 3, 'squirtle': 4}
# 读取已保存的图片+标签数据集
self.img_paths, self.labels = self.load_csv('img_paths.csv') # 数据对(img_path + image_label):img_paths, labels
# 对数据集根据当前模式进行裁剪
if mode == 'train': # 60%
self.img_paths = self.img_paths[:int(0.6 * len(self.img_paths))]
self.labels = self.labels[:int(0.6 * len(self.labels))]
elif mode == 'val': # 20% = 60%->80%
self.img_paths = self.img_paths[int(0.6 * len(self.img_paths)):int(0.8 * len(self.img_paths))]
self.labels = self.labels[int(0.6 * len(self.labels)):int(0.8 * len(self.labels))]
else: # 20% = 80%->100%
self.img_paths = self.img_paths[int(0.8 * len(self.img_paths)):]
self.labels = self.labels[int(0.8 * len(self.labels)):]
def load_csv(self, filename):
# 1、如果没有csv文件,则创建该csv文件
if not os.path.exists(os.path.join(self.root, filename)):
img_paths = [] # 把所有图片的path都保存在该list中,各个图片的label可以从path推断出来,所有没有单独保存。
for name in self.name2label.keys():
img_paths += glob.glob(os.path.join(self.root, name, '*.png')) # 'pokemon\\mewtwo\\00001.png
img_paths += glob.glob(os.path.join(self.root, name, '*.jpg'))
img_paths += glob.glob(os.path.join(self.root, name, '*.jpeg'))
img_paths += glob.glob(os.path.join(self.root, name, '*.gif'))
print('len(img_paths) = {0}, img_paths = {1}'.format(len(img_paths), img_paths)) # len(img_paths) = 1168, img_paths = ['pokemon\\bulbasaur\\00000000.png','pokemon\\bulbasaur\\00000001.png',...]
random.shuffle(img_paths) # 打乱list中的图片顺序
# 向csv文件保存图片的path+label
with open(os.path.join(self.root, filename), mode='w', newline='') as f:
writer = csv.writer(f)
for img_path in img_paths: # 'pokemon\\bulbasaur\\00000000.png'
name = img_path.split(os.sep)[-2]
label = self.name2label[name]
writer.writerow([img_path, label]) # 'pokemon\\bulbasaur\\00000000.png', 0
print('writen into csv file:', filename)
# 2、如果已经有csv文件,则读取该csv文件
img_paths, labels = [], []
with open(os.path.join(self.root, filename)) as f:
reader = csv.reader(f)
for row in reader:
img_path, label = row # 'pokemon\\bulbasaur\\00000000.png', 0
label = int(label)
img_paths.append(img_path)
labels.append(label)
assert len(img_paths) == len(labels)
return img_paths, labels
def __len__(self):
return len(self.img_paths)
def denormalize(self, x_hat):
mean = [0.485, 0.456, 0.406]
std = [0.229, 0.224, 0.225]
# x_hat = (x-mean)/std
# x = x_hat*std = mean
# x: [c, h, w]
# mean: [3] => [3, 1, 1]
mean = torch.tensor(mean).unsqueeze(1).unsqueeze(1)
std = torch.tensor(std).unsqueeze(1).unsqueeze(1)
print('denormalize-->mean.shape = {0}, std.shape = {1}'.format(mean.shape, std.shape))
x = x_hat * std + mean
return x
def __getitem__(self, img_idx): # img_idx~[0~len(img_paths)]
img_path, label = self.img_paths[img_idx], self.labels[img_idx] # img_path: 'pokemon\\bulbasaur\\00000000.png';label: 0
transform = transforms.Compose([
lambda x: Image.open(x).convert('RGB'), # string path --> image data
transforms.Resize((int(self.resize * 1.25), int(self.resize * 1.25))),
transforms.RandomRotation(15), # rotate如果比较大的话,可能会造成网络不收敛
transforms.CenterCrop(self.resize),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) # 该数值是实践中统计的效果比较好的值
])
img = transform(img_path)
label = torch.tensor(label)
return img, label
# =============================================================================Pokemon自定义数据集:结束=============================================================================
# =============================================================================ResNet18神经网络:开始=============================================================================
# 两层的残差学习单元 BasicBlock [(3×3)-->(3×3)]形状,如果是三层的BasicBlock,形状则为:[(1×1)-->(3×3)-->(1×1)]
# filter_count_in≠filter_count_out时,则通过该层Layer后的FeatureMap的大小改变,identity层也需要reshape
class BasicBlock(nn.Module):
def __init__(self, filter_count_in, filter_count_out, stride=1):
super(BasicBlock, self).__init__()
self.filter_count_in = filter_count_in
self.filter_count_out = filter_count_out
self.stride = stride
# we add stride support for resbok, which is distinct from tutorials.
self.conv1 = nn.Conv2d(in_channels=filter_count_in, out_channels=filter_count_out, kernel_size=3, stride=stride, padding=1)
self.bn1 = nn.BatchNorm2d(filter_count_out)
self.conv2 = nn.Conv2d(filter_count_out, filter_count_out, kernel_size=3, stride=1, padding=1)
self.bn2 = nn.BatchNorm2d(filter_count_out)
self.identity = nn.Sequential()
if filter_count_in != filter_count_out: # 将输入值x的维度调整为和F(x)的输出维度保持一致 [b, filter_count_in, h, w] => [b, filter_count_out, h, w]
self.identity = nn.Sequential(
nn.Conv2d(filter_count_in, filter_count_out, kernel_size=1, stride=stride),
nn.BatchNorm2d(filter_count_out)
)
def forward(self, input):
x = self.conv1(input)
x = self.bn1(x)
x = F.relu(x)
x = self.conv2(x)
F_out = self.bn2(x)
# short cut
identity_out = self.identity(input) # 调整input的维度与F_out保持一致,然后才能和F_out相加:[b, ch_in, h, w] => [b, ch_out, h, w]
# print('stride = {0},filter_count_in = {1},filter_count_out = {2},F_out.shape = {3},identity_out.shape = {4}'.format(self.stride, self.filter_count_in, self.filter_count_out, F_out.shape, identity_out.shape))
H_out = identity_out + F_out
H_out = F.relu(H_out)
return H_out
# 由多个BasicBlock组成的ResidualBlock
class ResidualBlock:
def __init__(self, filter_count_in, filter_count_out, residualBlock_size=1, stride=1):
self.filter_count_in = filter_count_in
self.filter_count_out = filter_count_out
self.residualBlock_size = residualBlock_size
self.stride = stride
def __call__(self):
basic_block_stride_eq = BasicBlock(self.filter_count_in, self.filter_count_in, stride=1) # stride = 1 时的BasicBlock H(x)=x+F(X),identity_layer层的输出为直接返回输入
basic_block_stride_not_eq = BasicBlock(self.filter_count_in, self.filter_count_out, stride=self.stride) # stride != 1 时的BasicBlock H(x)=x+F(X),identity_layer进行SubSampling
residualBlock = nn.Sequential()
for _ in range(0, self.residualBlock_size - 1): # 其余的BasicBlock都是 filter_count_in == filter_count_out 时的BasicBlock
residualBlock.add_module('basic_block_stride_eq', basic_block_stride_eq)
residualBlock.add_module('basic_block_stride_not_eq', basic_block_stride_not_eq) # 有一个BasicBlock必须是 filter_count_in != filter_count_out 时的BasicBlock
return residualBlock
# 由多个ResidualBlock组成的ResidualNet
class ResNet18(nn.Module):
def __init__(self, num_class): # num_class 表示最终所有分类数量
super(ResNet18, self).__init__()
self.conv1 = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=3, stride=3, padding=0),
nn.BatchNorm2d(64)
)
# followed 4 ResidualBlock
self.residualBlock1 = ResidualBlock(filter_count_in=64, filter_count_out=128, residualBlock_size=2, stride=2)() # [b, 64, h, w] => [b, 128, h ,w]
self.residualBlock2 = ResidualBlock(filter_count_in=128, filter_count_out=256, residualBlock_size=2, stride=2)() # [b, 128, h, w] => [b, 256, h, w]
self.residualBlock3 = ResidualBlock(filter_count_in=256, filter_count_out=512, residualBlock_size=2, stride=2)() # [b, 256, h, w] => [b, 512, h, w]
self.residualBlock4 = ResidualBlock(filter_count_in=512, filter_count_out=512, residualBlock_size=2, stride=1)() # [b, 512, h, w] => [b, 1024, h, w]
self.outlayer = nn.Linear(512 * 1 * 1, num_class)
def forward(self, X):
X = F.relu(self.conv1(X))
# [b, 64, h, w] => [b, 1024, h, w]
X = self.residualBlock1(X)
X = self.residualBlock2(X)
X = self.residualBlock3(X)
X = self.residualBlock4(X) # [b, 512, 2, 2]
X = F.adaptive_avg_pool2d(X, [1, 1]) # [b, 512, 2, 2] => [b, 512, 1, 1]
X = X.view(X.size(0), -1) # [b, 512, 1, 1] => [b, 512]
X = self.outlayer(X) # [b, 512] => [b, 5]
return X
# =============================================================================ResNet18神经网络:结束=============================================================================
# =============================================================================训练主体:开始=============================================================================
batch_size = 32
viz = visdom.Visdom() # 在控制台开启Visdom:python -m visdom.server
global_step = 0
# 一、获取Pokemon训练数据集
train_db = Pokemon('pokemon', 224, mode='train')
val_db = Pokemon('pokemon', 224, mode='val')
test_db = Pokemon('pokemon', 224, mode='test')
train_loader = DataLoader(train_db, batch_size=batch_size, shuffle=True, num_workers=0) # num_workers表示开启的线程数量
val_loader = DataLoader(val_db, batch_size=batch_size, num_workers=0)
test_loader = DataLoader(test_db, batch_size=batch_size, num_workers=0)
# 三、实例化ResNet18神经网络模型
model = ResNet18(5).to(device)
# Find total parameters and trainable parameters
total_params = sum(p.numel() for p in model.parameters())
print(f'{total_params:,} total parameters.')
total_trainable_params = sum(
p.numel() for p in model.parameters() if p.requires_grad)
print(f'{total_trainable_params:,} training parameters.')
print('model = {0}\n'.format(model))
# 四、实例化损失函数
criteon = nn.CrossEntropyLoss().to(device)
# 五、梯度下降优化器设置
optimizer = optim.Adam(model.parameters(), lr=1e-3)
def train_epoch(epoch_no):
global global_step
print('++++++++++++++++++++++++++++++++++++++++++++第{0}轮Epoch-->Training 阶段:开始++++++++++++++++++++++++++++++++++++++++++++'.format(epoch_no))
model.train() # 切换至训练模式
for batch_index, (X_batch, Y_batch) in enumerate(train_loader):
X_batch, Y_batch = X_batch.to(device), Y_batch.to(device)
out_logits = model(X_batch)
loss = criteon(out_logits, Y_batch)
optimizer.zero_grad()
loss.backward()
optimizer.step()
viz.line([loss.item()], [global_step], win='loss', update='append')
global_step += 1
if batch_index % 5 == 0:
print('epoch_no = {0}, batch_index = {1}, loss.item() = {2}'.format(epoch_no, batch_index, loss.item()))
print('++++++++++++++++++++++++++++++++++++++++++++第{0}轮Epoch-->Training 阶段:结束++++++++++++++++++++++++++++++++++++++++++++'.format(epoch_no))
def evalute(epoch_no, loader):
print('++++++++++++++++++++++++++++++++++++++++++++第{0}轮Epoch-->Evluation 阶段:开始++++++++++++++++++++++++++++++++++++++++++++'.format(epoch_no))
model.eval()
with torch.no_grad():
total_correct = 0
total_num = 0
for batch_index, (X_batch, Y_batch) in enumerate(loader):
X_batch, Y_batch = X_batch.to(device), Y_batch.to(device)
out_logits = model(X_batch)
out_pred = out_logits.argmax(dim=1)
correct = torch.eq(out_pred, Y_batch).float().sum().item()
total_correct += correct
total_num += X_batch.size(0)
val_acc = total_correct / total_num
viz.line([val_acc], [global_step], win='val_acc', update='append')
if batch_index % 5 == 0:
print('epoch_no = {0}, batch_index = {1}, val_acc = {2}'.format(epoch_no, batch_index, val_acc))
print('++++++++++++++++++++++++++++++++++++++++++++第{0}轮Epoch-->Evluation 阶段:结束++++++++++++++++++++++++++++++++++++++++++++'.format(epoch_no))
return val_acc
def main():
epoch_count = 4 # epoch_count为整体数据集迭代梯度下降次数
best_acc, best_epoch = 0, 0
viz.line([0], [-1], win='loss', opts=dict(title='loss'))
viz.line([0], [-1], win='val_acc', opts=dict(title='val_acc'))
for epoch_no in range(1, epoch_count + 1):
print('\n\n利用整体数据集进行模型的第{0}轮Epoch迭代开始:**********************************************************************************************************************************'.format(epoch_no))
train_epoch(epoch_no) # 训练
val_acc = evalute(epoch_no, val_loader) # 验证
if val_acc > best_acc:
best_epoch = epoch_no
best_acc = val_acc
torch.save(model.state_dict(), 'best.mdl')
print('epoch = {0}, best_epoch = {1}, best_acc = {2}'.format(epoch_no, best_epoch, best_acc))
print('**************************验证模式:结束**************************')
print('利用整体数据集进行模型的第{0}轮Epoch迭代结束:**********************************************************************************************************************************'.format(epoch_no))
print('best acc:', best_acc, 'best epoch:', best_epoch)
model.load_state_dict(torch.load('best.mdl'))
print('loaded from ckpt!')
test_acc = evalute(best_epoch, test_loader) # 测试
print('test acc:', test_acc)
if __name__ == '__main__':
main()
# =============================================================================训练主体:结束=============================================================================

打印结果:
Setting up a new session...
self.name2label = {'bulbasaur': 0, 'charmander': 1, 'mewtwo': 2, 'pikachu': 3, 'squirtle': 4}
self.name2label = {'bulbasaur': 0, 'charmander': 1, 'mewtwo': 2, 'pikachu': 3, 'squirtle': 4}
self.name2label = {'bulbasaur': 0, 'charmander': 1, 'mewtwo': 2, 'pikachu': 3, 'squirtle': 4}
15,823,749 total parameters.
15,823,749 training parameters.
model = ResNet18(
(conv1): Sequential(
(0): Conv2d(3, 64, kernel_size=(3, 3), stride=(3, 3))
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(residualBlock1): Sequential(
(basic_block_stride_eq): BasicBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(identity): Sequential()
)
(basic_block_stride_not_eq): BasicBlock(
(conv1): Conv2d(64, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(identity): Sequential(
(0): Conv2d(64, 128, kernel_size=(1, 1), stride=(2, 2))
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
)
(residualBlock2): Sequential(
(basic_block_stride_eq): BasicBlock(
(conv1): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(identity): Sequential()
)
(basic_block_stride_not_eq): BasicBlock(
(conv1): Conv2d(128, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(identity): Sequential(
(0): Conv2d(128, 256, kernel_size=(1, 1), stride=(2, 2))
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
)
(residualBlock3): Sequential(
(basic_block_stride_eq): BasicBlock(
(conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(identity): Sequential()
)
(basic_block_stride_not_eq): BasicBlock(
(conv1): Conv2d(256, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(identity): Sequential(
(0): Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2))
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
)
(residualBlock4): Sequential(
(basic_block_stride_eq): BasicBlock(
(conv1): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(identity): Sequential()
)
(basic_block_stride_not_eq): BasicBlock(
(conv1): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(identity): Sequential()
)
)
(outlayer): Linear(in_features=512, out_features=5, bias=True)
)
利用整体数据集进行模型的第1轮Epoch迭代开始:**********************************************************************************************************************************
++++++++++++++++++++++++++++++++++++++++++++第1轮Epoch-->Training 阶段:开始++++++++++++++++++++++++++++++++++++++++++++
epoch_no = 1, batch_index = 0, loss.item() = 1.939097285270691
epoch_no = 1, batch_index = 5, loss.item() = 1.332801342010498
epoch_no = 1, batch_index = 10, loss.item() = 1.3339236974716187
epoch_no = 1, batch_index = 15, loss.item() = 0.44973278045654297
epoch_no = 1, batch_index = 20, loss.item() = 0.4216762185096741
++++++++++++++++++++++++++++++++++++++++++++第1轮Epoch-->Training 阶段:结束++++++++++++++++++++++++++++++++++++++++++++
++++++++++++++++++++++++++++++++++++++++++++第1轮Epoch-->Evluation 阶段:开始++++++++++++++++++++++++++++++++++++++++++++
epoch_no = 1, batch_index = 0, val_acc = 0.6875
epoch_no = 1, batch_index = 5, val_acc = 0.7395833333333334
++++++++++++++++++++++++++++++++++++++++++++第1轮Epoch-->Evluation 阶段:结束++++++++++++++++++++++++++++++++++++++++++++
epoch = 1, best_epoch = 1, best_acc = 0.7478632478632479
**************************验证模式:结束**************************
利用整体数据集进行模型的第1轮Epoch迭代结束:**********************************************************************************************************************************
利用整体数据集进行模型的第2轮Epoch迭代开始:**********************************************************************************************************************************
++++++++++++++++++++++++++++++++++++++++++++第2轮Epoch-->Training 阶段:开始++++++++++++++++++++++++++++++++++++++++++++
epoch_no = 2, batch_index = 0, loss.item() = 0.5493289232254028
epoch_no = 2, batch_index = 5, loss.item() = 0.6154159307479858
epoch_no = 2, batch_index = 10, loss.item() = 0.6554363965988159
epoch_no = 2, batch_index = 15, loss.item() = 0.4766008257865906
epoch_no = 2, batch_index = 20, loss.item() = 0.45220986008644104
++++++++++++++++++++++++++++++++++++++++++++第2轮Epoch-->Training 阶段:结束++++++++++++++++++++++++++++++++++++++++++++
++++++++++++++++++++++++++++++++++++++++++++第2轮Epoch-->Evluation 阶段:开始++++++++++++++++++++++++++++++++++++++++++++
epoch_no = 2, batch_index = 0, val_acc = 0.71875
epoch_no = 2, batch_index = 5, val_acc = 0.8020833333333334
++++++++++++++++++++++++++++++++++++++++++++第2轮Epoch-->Evluation 阶段:结束++++++++++++++++++++++++++++++++++++++++++++
epoch = 2, best_epoch = 2, best_acc = 0.8076923076923077
**************************验证模式:结束**************************
利用整体数据集进行模型的第2轮Epoch迭代结束:**********************************************************************************************************************************
利用整体数据集进行模型的第3轮Epoch迭代开始:**********************************************************************************************************************************
++++++++++++++++++++++++++++++++++++++++++++第3轮Epoch-->Training 阶段:开始++++++++++++++++++++++++++++++++++++++++++++
epoch_no = 3, batch_index = 0, loss.item() = 0.6022523641586304
epoch_no = 3, batch_index = 5, loss.item() = 0.5406889319419861
epoch_no = 3, batch_index = 10, loss.item() = 0.22856442630290985
epoch_no = 3, batch_index = 15, loss.item() = 0.5484329462051392
epoch_no = 3, batch_index = 20, loss.item() = 0.36236143112182617
++++++++++++++++++++++++++++++++++++++++++++第3轮Epoch-->Training 阶段:结束++++++++++++++++++++++++++++++++++++++++++++
++++++++++++++++++++++++++++++++++++++++++++第3轮Epoch-->Evluation 阶段:开始++++++++++++++++++++++++++++++++++++++++++++
epoch_no = 3, batch_index = 0, val_acc = 0.84375
epoch_no = 3, batch_index = 5, val_acc = 0.859375
++++++++++++++++++++++++++++++++++++++++++++第3轮Epoch-->Evluation 阶段:结束++++++++++++++++++++++++++++++++++++++++++++
epoch = 3, best_epoch = 3, best_acc = 0.8589743589743589
**************************验证模式:结束**************************
利用整体数据集进行模型的第3轮Epoch迭代结束:**********************************************************************************************************************************
利用整体数据集进行模型的第4轮Epoch迭代开始:**********************************************************************************************************************************
++++++++++++++++++++++++++++++++++++++++++++第4轮Epoch-->Training 阶段:开始++++++++++++++++++++++++++++++++++++++++++++
epoch_no = 4, batch_index = 0, loss.item() = 0.47427237033843994
epoch_no = 4, batch_index = 5, loss.item() = 0.30755600333213806
epoch_no = 4, batch_index = 10, loss.item() = 0.7977475523948669
epoch_no = 4, batch_index = 15, loss.item() = 0.3868430554866791
epoch_no = 4, batch_index = 20, loss.item() = 0.46423253417015076
++++++++++++++++++++++++++++++++++++++++++++第4轮Epoch-->Training 阶段:结束++++++++++++++++++++++++++++++++++++++++++++
++++++++++++++++++++++++++++++++++++++++++++第4轮Epoch-->Evluation 阶段:开始++++++++++++++++++++++++++++++++++++++++++++
epoch_no = 4, batch_index = 0, val_acc = 0.90625
epoch_no = 4, batch_index = 5, val_acc = 0.8958333333333334
++++++++++++++++++++++++++++++++++++++++++++第4轮Epoch-->Evluation 阶段:结束++++++++++++++++++++++++++++++++++++++++++++
epoch = 4, best_epoch = 4, best_acc = 0.8931623931623932
**************************验证模式:结束**************************
利用整体数据集进行模型的第4轮Epoch迭代结束:**********************************************************************************************************************************
best acc: 0.8931623931623932 best epoch: 4
loaded from ckpt!
++++++++++++++++++++++++++++++++++++++++++++第4轮Epoch-->Evluation 阶段:开始++++++++++++++++++++++++++++++++++++++++++++
epoch_no = 4, batch_index = 0, val_acc = 0.84375
epoch_no = 4, batch_index = 5, val_acc = 0.828125
++++++++++++++++++++++++++++++++++++++++++++第4轮Epoch-->Evluation 阶段:结束++++++++++++++++++++++++++++++++++++++++++++
test acc: 0.8290598290598291
Process finished with exit code 0
3.4 迁移学习 & 预训练ResNet18 & 自定义数据集【Pytorch】
import torch
from torch.utils.data import DataLoader
from torch import nn, optim
from torch.nn import functional as F
import visdom
import csv
import glob
import os
import random
from PIL import Image
from torch.utils.data import Dataset # 自定义数据集的父类
from torchvision import transforms
from torchvision.models import resnet18
torch.manual_seed(1234) # 随机种子
device = torch.device('cuda') # 设置GPU
# =============================================================================Pokemon自定义数据集:开始=============================================================================
class Pokemon(Dataset):
# root表示数据位置;resize表示数据输出的size;mode表示训练模式/测试模式
def __init__(self, root, resize, mode):
super(Pokemon, self).__init__()
self.root = root
self.resize = resize
# 给各个类型进行编号
self.name2label = {} # {'bulbasaur': 0, 'charmander': 1, 'mewtwo': 2, 'pikachu': 3, 'squirtle': 4}
for name in sorted(os.listdir(os.path.join(root))):
if not os.path.isdir(os.path.join(root, name)): # 过滤掉不是文件夹的文件
continue
self.name2label[name] = len(self.name2label.keys())
print('self.name2label = {0}'.format(self.name2label)) # {'bulbasaur': 0, 'charmander': 1, 'mewtwo': 2, 'pikachu': 3, 'squirtle': 4}
# 读取已保存的图片+标签数据集
self.img_paths, self.labels = self.load_csv('img_paths.csv') # 数据对(img_path + image_label):img_paths, labels
# 对数据集根据当前模式进行裁剪
if mode == 'train': # 60%
self.img_paths = self.img_paths[:int(0.6 * len(self.img_paths))]
self.labels = self.labels[:int(0.6 * len(self.labels))]
elif mode == 'val': # 20% = 60%->80%
self.img_paths = self.img_paths[int(0.6 * len(self.img_paths)):int(0.8 * len(self.img_paths))]
self.labels = self.labels[int(0.6 * len(self.labels)):int(0.8 * len(self.labels))]
else: # 20% = 80%->100%
self.img_paths = self.img_paths[int(0.8 * len(self.img_paths)):]
self.labels = self.labels[int(0.8 * len(self.labels)):]
def load_csv(self, filename):
# 1、如果没有csv文件,则创建该csv文件
if not os.path.exists(os.path.join(self.root, filename)):
img_paths = [] # 把所有图片的path都保存在该list中,各个图片的label可以从path推断出来,所有没有单独保存。
for name in self.name2label.keys():
img_paths += glob.glob(os.path.join(self.root, name, '*.png')) # 'pokemon\\mewtwo\\00001.png
img_paths += glob.glob(os.path.join(self.root, name, '*.jpg'))
img_paths += glob.glob(os.path.join(self.root, name, '*.jpeg'))
img_paths += glob.glob(os.path.join(self.root, name, '*.gif'))
print('len(img_paths) = {0}, img_paths = {1}'.format(len(img_paths), img_paths)) # len(img_paths) = 1168, img_paths = ['pokemon\\bulbasaur\\00000000.png','pokemon\\bulbasaur\\00000001.png',...]
random.shuffle(img_paths) # 打乱list中的图片顺序
# 向csv文件保存图片的path+label
with open(os.path.join(self.root, filename), mode='w', newline='') as f:
writer = csv.writer(f)
for img_path in img_paths: # 'pokemon\\bulbasaur\\00000000.png'
name = img_path.split(os.sep)[-2]
label = self.name2label[name]
writer.writerow([img_path, label]) # 'pokemon\\bulbasaur\\00000000.png', 0
print('writen into csv file:', filename)
# 2、如果已经有csv文件,则读取该csv文件
img_paths, labels = [], []
with open(os.path.join(self.root, filename)) as f:
reader = csv.reader(f)
for row in reader:
img_path, label = row # 'pokemon\\bulbasaur\\00000000.png', 0
label = int(label)
img_paths.append(img_path)
labels.append(label)
assert len(img_paths) == len(labels)
return img_paths, labels
def __len__(self):
return len(self.img_paths)
def denormalize(self, x_hat):
mean = [0.485, 0.456, 0.406]
std = [0.229, 0.224, 0.225]
# x_hat = (x-mean)/std
# x = x_hat*std = mean
# x: [c, h, w]
# mean: [3] => [3, 1, 1]
mean = torch.tensor(mean).unsqueeze(1).unsqueeze(1)
std = torch.tensor(std).unsqueeze(1).unsqueeze(1)
print('denormalize-->mean.shape = {0}, std.shape = {1}'.format(mean.shape, std.shape))
x = x_hat * std + mean
return x
def __getitem__(self, img_idx): # img_idx~[0~len(img_paths)]
img_path, label = self.img_paths[img_idx], self.labels[img_idx] # img_path: 'pokemon\\bulbasaur\\00000000.png';label: 0
transform = transforms.Compose([
lambda x: Image.open(x).convert('RGB'), # string path --> image data
transforms.Resize((int(self.resize * 1.25), int(self.resize * 1.25))),
transforms.RandomRotation(15), # rotate如果比较大的话,可能会造成网络不收敛
transforms.CenterCrop(self.resize),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) # 该数值是实践中统计的效果比较好的值
])
img = transform(img_path)
label = torch.tensor(label)
return img, label
# =============================================================================Pokemon自定义数据集:结束=============================================================================
class Flatten(nn.Module):
def __init__(self):
super(Flatten, self).__init__()
def forward(self, x):
shape = torch.prod(torch.tensor(x.shape[1:])).item()
return x.view(-1, shape)
# =============================================================================训练主体:开始=============================================================================
batch_size = 32
viz = visdom.Visdom() # 在控制台开启Visdom:python -m visdom.server
global_step = 0
# 一、获取Pokemon训练数据集
train_db = Pokemon('pokemon', 224, mode='train')
val_db = Pokemon('pokemon', 224, mode='val')
test_db = Pokemon('pokemon', 224, mode='test')
train_loader = DataLoader(train_db, batch_size=batch_size, shuffle=True, num_workers=0) # num_workers表示开启的线程数量
val_loader = DataLoader(val_db, batch_size=batch_size, num_workers=0)
test_loader = DataLoader(test_db, batch_size=batch_size, num_workers=0)
# 三、实例化预训练ResNet18神经网络模型
trained_model = resnet18(pretrained=True)
model = nn.Sequential(*list(trained_model.children())[:-1], # 提取已经训练好的resnet18模型的前17层,打散。[b, 512, 1, 1]
Flatten(), # [b, 512, 1, 1] => [b, 512]
nn.Linear(512, 5)
).to(device)
# Find total parameters and trainable parameters
total_params = sum(p.numel() for p in model.parameters())
print(f'{total_params:,} total parameters.')
total_trainable_params = sum(
p.numel() for p in model.parameters() if p.requires_grad)
print(f'{total_trainable_params:,} training parameters.')
print('model = {0}\n'.format(model))
# 四、实例化损失函数
criteon = nn.CrossEntropyLoss().to(device)
# 五、梯度下降优化器设置
optimizer = optim.Adam(model.parameters(), lr=1e-3)
def train_epoch(epoch_no):
global global_step
print('++++++++++++++++++++++++++++++++++++++++++++第{0}轮Epoch-->Training 阶段:开始++++++++++++++++++++++++++++++++++++++++++++'.format(epoch_no))
model.train() # 切换至训练模式
for batch_index, (X_batch, Y_batch) in enumerate(train_loader):
X_batch, Y_batch = X_batch.to(device), Y_batch.to(device)
out_logits = model(X_batch)
loss = criteon(out_logits, Y_batch)
optimizer.zero_grad()
loss.backward()
optimizer.step()
viz.line([loss.item()], [global_step], win='loss', update='append')
global_step += 1
if batch_index % 5 == 0:
print('epoch_no = {0}, batch_index = {1}, loss.item() = {2}'.format(epoch_no, batch_index, loss.item()))
print('++++++++++++++++++++++++++++++++++++++++++++第{0}轮Epoch-->Training 阶段:结束++++++++++++++++++++++++++++++++++++++++++++'.format(epoch_no))
def evalute(epoch_no, loader):
print('++++++++++++++++++++++++++++++++++++++++++++第{0}轮Epoch-->Evluation 阶段:开始++++++++++++++++++++++++++++++++++++++++++++'.format(epoch_no))
model.eval()
with torch.no_grad():
total_correct = 0
total_num = 0
for batch_index, (X_batch, Y_batch) in enumerate(loader):
X_batch, Y_batch = X_batch.to(device), Y_batch.to(device)
out_logits = model(X_batch)
out_pred = out_logits.argmax(dim=1)
correct = torch.eq(out_pred, Y_batch).float().sum().item()
total_correct += correct
total_num += X_batch.size(0)
val_acc = total_correct / total_num
viz.line([val_acc], [global_step], win='val_acc', update='append')
if batch_index % 5 == 0:
print('epoch_no = {0}, batch_index = {1}, val_acc = {2}'.format(epoch_no, batch_index, val_acc))
print('++++++++++++++++++++++++++++++++++++++++++++第{0}轮Epoch-->Evluation 阶段:结束++++++++++++++++++++++++++++++++++++++++++++'.format(epoch_no))
return val_acc
def main():
epoch_count = 4 # epoch_count为整体数据集迭代梯度下降次数
best_acc, best_epoch = 0, 0
viz.line([0], [-1], win='loss', opts=dict(title='loss'))
viz.line([0], [-1], win='val_acc', opts=dict(title='val_acc'))
for epoch_no in range(1, epoch_count + 1):
print('\n\n利用整体数据集进行模型的第{0}轮Epoch迭代开始:**********************************************************************************************************************************'.format(epoch_no))
train_epoch(epoch_no) # 训练
val_acc = evalute(epoch_no, val_loader) # 验证
if val_acc > best_acc:
best_epoch = epoch_no
best_acc = val_acc
torch.save(model.state_dict(), 'best.mdl')
print('epoch = {0}, best_epoch = {1}, best_acc = {2}'.format(epoch_no, best_epoch, best_acc))
print('**************************验证模式:结束**************************')
print('利用整体数据集进行模型的第{0}轮Epoch迭代结束:**********************************************************************************************************************************'.format(epoch_no))
print('best acc:', best_acc, 'best epoch:', best_epoch)
model.load_state_dict(torch.load('best.mdl'))
print('loaded from ckpt!')
test_acc = evalute(best_epoch, test_loader) # 测试
print('test acc:', test_acc)
if __name__ == '__main__':
main()
# =============================================================================训练主体:结束=============================================================================
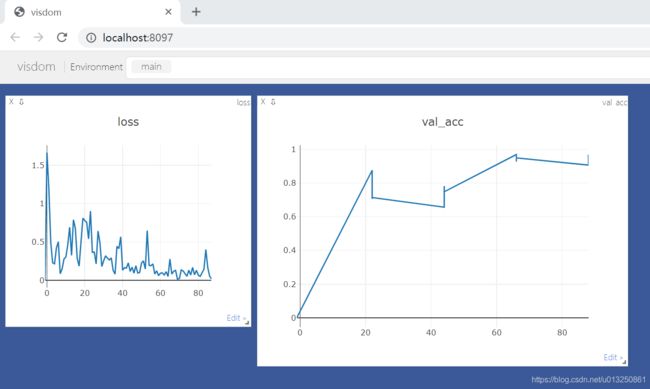
打印结果:
Setting up a new session...
self.name2label = {'bulbasaur': 0, 'charmander': 1, 'mewtwo': 2, 'pikachu': 3, 'squirtle': 4}
self.name2label = {'bulbasaur': 0, 'charmander': 1, 'mewtwo': 2, 'pikachu': 3, 'squirtle': 4}
self.name2label = {'bulbasaur': 0, 'charmander': 1, 'mewtwo': 2, 'pikachu': 3, 'squirtle': 4}
11,179,077 total parameters.
11,179,077 training parameters.
model = Sequential(
(0): Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
(4): Sequential(
(0): BasicBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(1): BasicBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(5): Sequential(
(0): BasicBlock(
(conv1): Conv2d(64, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(64, 128, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(6): Sequential(
(0): BasicBlock(
(conv1): Conv2d(128, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(128, 256, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(7): Sequential(
(0): BasicBlock(
(conv1): Conv2d(256, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(8): AdaptiveAvgPool2d(output_size=(1, 1))
(9): Flatten()
(10): Linear(in_features=512, out_features=5, bias=True)
)
利用整体数据集进行模型的第1轮Epoch迭代开始:**********************************************************************************************************************************
++++++++++++++++++++++++++++++++++++++++++++第1轮Epoch-->Training 阶段:开始++++++++++++++++++++++++++++++++++++++++++++
epoch_no = 1, batch_index = 0, loss.item() = 1.664962887763977
epoch_no = 1, batch_index = 5, loss.item() = 0.4224851131439209
epoch_no = 1, batch_index = 10, loss.item() = 0.3056411147117615
epoch_no = 1, batch_index = 15, loss.item() = 0.6770390868186951
epoch_no = 1, batch_index = 20, loss.item() = 0.778434157371521
++++++++++++++++++++++++++++++++++++++++++++第1轮Epoch-->Training 阶段:结束++++++++++++++++++++++++++++++++++++++++++++
++++++++++++++++++++++++++++++++++++++++++++第1轮Epoch-->Evluation 阶段:开始++++++++++++++++++++++++++++++++++++++++++++
epoch_no = 1, batch_index = 0, val_acc = 0.875
epoch_no = 1, batch_index = 5, val_acc = 0.7239583333333334
++++++++++++++++++++++++++++++++++++++++++++第1轮Epoch-->Evluation 阶段:结束++++++++++++++++++++++++++++++++++++++++++++
epoch = 1, best_epoch = 1, best_acc = 0.7136752136752137
**************************验证模式:结束**************************
利用整体数据集进行模型的第1轮Epoch迭代结束:**********************************************************************************************************************************
利用整体数据集进行模型的第2轮Epoch迭代开始:**********************************************************************************************************************************
++++++++++++++++++++++++++++++++++++++++++++第2轮Epoch-->Training 阶段:开始++++++++++++++++++++++++++++++++++++++++++++
epoch_no = 2, batch_index = 0, loss.item() = 0.5391928553581238
epoch_no = 2, batch_index = 5, loss.item() = 0.641627848148346
epoch_no = 2, batch_index = 10, loss.item() = 0.28850072622299194
epoch_no = 2, batch_index = 15, loss.item() = 0.44357800483703613
epoch_no = 2, batch_index = 20, loss.item() = 0.15881212055683136
++++++++++++++++++++++++++++++++++++++++++++第2轮Epoch-->Training 阶段:结束++++++++++++++++++++++++++++++++++++++++++++
++++++++++++++++++++++++++++++++++++++++++++第2轮Epoch-->Evluation 阶段:开始++++++++++++++++++++++++++++++++++++++++++++
epoch_no = 2, batch_index = 0, val_acc = 0.65625
epoch_no = 2, batch_index = 5, val_acc = 0.7447916666666666
++++++++++++++++++++++++++++++++++++++++++++第2轮Epoch-->Evluation 阶段:结束++++++++++++++++++++++++++++++++++++++++++++
epoch = 2, best_epoch = 2, best_acc = 0.7478632478632479
**************************验证模式:结束**************************
利用整体数据集进行模型的第2轮Epoch迭代结束:**********************************************************************************************************************************
利用整体数据集进行模型的第3轮Epoch迭代开始:**********************************************************************************************************************************
++++++++++++++++++++++++++++++++++++++++++++第3轮Epoch-->Training 阶段:开始++++++++++++++++++++++++++++++++++++++++++++
epoch_no = 3, batch_index = 0, loss.item() = 0.11576351523399353
epoch_no = 3, batch_index = 5, loss.item() = 0.10171618312597275
epoch_no = 3, batch_index = 10, loss.item() = 0.19451947510242462
epoch_no = 3, batch_index = 15, loss.item() = 0.06140638515353203
epoch_no = 3, batch_index = 20, loss.item() = 0.049921028316020966
++++++++++++++++++++++++++++++++++++++++++++第3轮Epoch-->Training 阶段:结束++++++++++++++++++++++++++++++++++++++++++++
++++++++++++++++++++++++++++++++++++++++++++第3轮Epoch-->Evluation 阶段:开始++++++++++++++++++++++++++++++++++++++++++++
epoch_no = 3, batch_index = 0, val_acc = 0.96875
epoch_no = 3, batch_index = 5, val_acc = 0.953125
++++++++++++++++++++++++++++++++++++++++++++第3轮Epoch-->Evluation 阶段:结束++++++++++++++++++++++++++++++++++++++++++++
epoch = 3, best_epoch = 3, best_acc = 0.9487179487179487
**************************验证模式:结束**************************
利用整体数据集进行模型的第3轮Epoch迭代结束:**********************************************************************************************************************************
利用整体数据集进行模型的第4轮Epoch迭代开始:**********************************************************************************************************************************
++++++++++++++++++++++++++++++++++++++++++++第4轮Epoch-->Training 阶段:开始++++++++++++++++++++++++++++++++++++++++++++
epoch_no = 4, batch_index = 0, loss.item() = 0.08163614571094513
epoch_no = 4, batch_index = 5, loss.item() = 0.1351318359375
epoch_no = 4, batch_index = 10, loss.item() = 0.06922706216573715
epoch_no = 4, batch_index = 15, loss.item() = 0.051600512117147446
epoch_no = 4, batch_index = 20, loss.item() = 0.05538956820964813
++++++++++++++++++++++++++++++++++++++++++++第4轮Epoch-->Training 阶段:结束++++++++++++++++++++++++++++++++++++++++++++
++++++++++++++++++++++++++++++++++++++++++++第4轮Epoch-->Evluation 阶段:开始++++++++++++++++++++++++++++++++++++++++++++
epoch_no = 4, batch_index = 0, val_acc = 0.90625
epoch_no = 4, batch_index = 5, val_acc = 0.9479166666666666
++++++++++++++++++++++++++++++++++++++++++++第4轮Epoch-->Evluation 阶段:结束++++++++++++++++++++++++++++++++++++++++++++
epoch = 4, best_epoch = 3, best_acc = 0.9487179487179487
**************************验证模式:结束**************************
利用整体数据集进行模型的第4轮Epoch迭代结束:**********************************************************************************************************************************
best acc: 0.9487179487179487 best epoch: 3
loaded from ckpt!
++++++++++++++++++++++++++++++++++++++++++++第3轮Epoch-->Evluation 阶段:开始++++++++++++++++++++++++++++++++++++++++++++
epoch_no = 3, batch_index = 0, val_acc = 0.96875
epoch_no = 3, batch_index = 5, val_acc = 0.921875
++++++++++++++++++++++++++++++++++++++++++++第3轮Epoch-->Evluation 阶段:结束++++++++++++++++++++++++++++++++++++++++++++
test acc: 0.9230769230769231
Process finished with exit code 0
参考资料:
深度学习:残差网络(ResNet),理论及代码结构
CNN模型合集 | 8 ResNet v1/v2
Residual Networks (ResNet)
Resnet要解决的是什么问题
残差网络ResNet笔记
ResNet详解与分析
ResNet论文详解