python opencv图片拼接、特征点匹配
一、算法目的:
在同一位置拍摄的两幅或者多幅图像是单应性相关的的,使用该约束将很多图片缝补起来,拼成一个大的图像来创建全景图像。两张图片的拼接必须首先找到相同特征,也就是说两张照片必须要有重叠的部分才能实现拼接,对人眼来说很容易找到两张图片的相似点,对计算机来说需要借助算法。因此图像拼接的第一步是分别获取两张图片的特征点并对特征点进行匹配,第二步对图片进行透视变换并对图片进行拼接。
二、特征点配对:
查找特征点使用sift方法,将两幅或者多幅图像中的相似点提取出来并完成图像的特征点匹配,相关sift的原理解释请看前面介绍。
运行sift找到特征匹配点对:

下面的图片是需要匹配的两张原图,而且它们具有相同的区域,可以找到相同特征点并完成匹配,由于两张图片相似点比较多,特征点容易找,所以匹配效果很明显。
三、RANSAC介绍:
1、ransac
是随机一致性采样,该方法是用来找到正确模型来拟合带来有噪声数据的迭代方法。给定一个模型,例如点集之间的单应性矩阵,ransac的基本思想是,数据中包含正确的点和噪声点,合理的模型应该能够在描述正确数据点的同时摒弃噪声点。
RANSAC算法的具体描述是:给定N个数据点组成的集合P,假设集合中大多数的点都是可以通过一个模型来产生的,且最少通过n个点(n
(1)从P中随机选择n个数据点;
(2)用这n个数据点拟合出一个模型M;
(3)对P中剩余的数据点,计算每个点与模型M的距离,距离超过阈值的则认定为局外点,不超过阈值的认定为局内点,并记录该模型M所对应的局内点的值m;
迭代k次以后,选择m最大的模型M作为拟合的结果。
因为在实际应用中N的值通常会很大,那么从其中任选n个数据点的组合就会很大,如果对所有组合都进行上面的操作运算量就会很大,因此对于k的选择就很重要。通常情况下,只要保证模型估计需要的n个点都是点的概率足够高即可。因此设w为N个数据中局内点的比例,z为进行k次选取后,至少有一次选取的n个点都是局内点的概率。则有

拟合结果显示表示为:
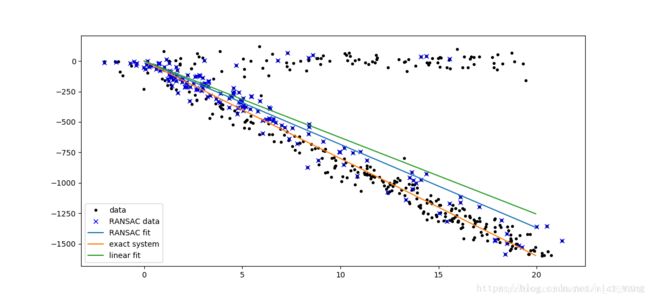
2、Ransac原理:
OpenCV中滤除误匹配对采用RANSAC算法寻找一个最佳单应性矩阵H,矩阵大小为3×3。RANSAC目的是找到最优的参数矩阵使得满足该矩阵的数据点个数最多,通常令h33=1来归一化矩阵。由于单应性矩阵有8个未知参数,至少需要8个线性方程求解,对应到点位置信息上,一组点对可以列出两个方程,则至少包含4组匹配点对。
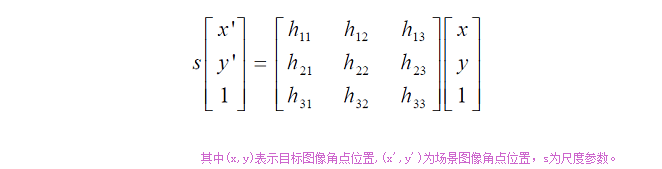
RANSAC算法从匹配数据集中随机抽出4个样本并保证这4个样本之间不共线,计算出单应性矩阵,然后利用这个模型测试所有数据,并计算满足这个模型数据点的个数与投影误差(即代价函数),若此模型为最优模型,则对应的代价函数最小。
3、ransac算法步骤为:
1. 随机从数据集中随机抽出4个样本数据 (此4个样本之间不能共线),计算出变换矩阵H,记为模型M;
2. 计算数据集中所有数据与模型M的投影误差,若误差小于阈值,加入内点集 I ;
3. 如果当前内点集 I 元素个数大于最优内点集 I_best , 则更新 I_best = I,同时更新迭代次数k ;
4. 如果迭代次数大于k,则退出 ; 否则迭代次数加1,并重复上述步骤)
注:迭代次数k在不大于最大迭代次数的情况下,是在不断更新而不是固定的;
使用ransac算法求解单应性矩阵,将下面模型类添加到homography.py中,相关解释如下:
class RansacModel(object):
#用于测试单应性矩阵的类
def __init__(self, debug=False):
self.debug = debug
def fit(self, data):
#计算选取的4个对应的单应性矩阵
#将其转置,来调用H_from_points()计算单应性矩阵
data = data.T
# 映射的起始点
fp = data[:3, :4]
# 映射的目标点
tp = data[3:, :4]
# 计算单应性矩阵然后返回
return H_from_points(fp, tp)
def get_error(self, data, H):
#对所有的对应计算单应性矩阵,然后对每个变换后的点,返回相应的误差
data = data.T
# 映射的起始点
fp = data[:3]
# 映射的目标点
tp = data[3:]
# 变换 fp
fp_transformed = dot(H, fp)
# 归一化齐次坐标
for i in range(3):
fp_transformed[i]/=fp_transformed[2]
# 返回每个点的坐标
return sqrt(sum((tp - fp_transformed) ** 2, axis=0))
四、拼接图片:
估计出图像间的单应性矩阵,现在我们需要将所有的图像扭曲到一个公共的图像平面上。通常,这里的公共平面为中心图像平面。一种方法是创建一个很大的图像,比如图像中全部填充0,使其和中心图像平行,然后将所有的图像扭曲到上面。由于我们所有的图像是由照相机水平旋转拍摄的,由此我们可以使用一个简单的步骤:将中心图像左边或者右边的区域填充0,以便扭曲的图像腾出空间。
利用panorama()函数,使用单应性矩阵H,协调相幅图像,创建水平全景图像。结果为一幅和toim具有相同高度的图像。
扭曲图像的相关代码为:
im1 = array(Image.open(imname[1]), "uint8")
im2 = array(Image.open(imname[2]), "uint8")
im_12 = warp.panorama(H_12, im1, im2, delta, delta)
im1 = array(Image.open(imname[0]), "f")
im_02 = warp.panorama(dot(H_12, H_01), im1, im_12, delta, delta)
im1 = array(Image.open(imname[3]), "f")
im_32 = warp.panorama(H_32, im1, im_02, delta, delta)
im1 = array(Image.open(imname[4]), "f")
im_42 = warp.panorama(dot(H_32, H_43), im1, im_32, delta, 2 * delta)
五、实验结果分析:
第一对图片特征点匹配结果为:

拼接效果为:

由于两张图片重合的地方比较多,而且相同点比较多,特征点找到的比较多,图片经过扭曲后的拼接效果较好,而且拼接也算完美,但是对于图片相差较较大的两张图片进行拼接时就会出现问题。