OpenMMLab学习 Day2
目录
图像分类
什么是图像分类?
视觉任务的难点
机器学习的优势和局限性
传统方法 : 设计图像特征(1990s ~ 2000s)
从特征工程到特征学习
AlexNet的诞生 & 深度学习时代的开始
Going Deeper (2012 ~ 2014)
残差学习的基本思路
更强的图像分类模型
神经结构搜索 Neural Architecture Search (2016+)
Vision Transformers(2020+)
ConvNeXt(2022)
轻量化卷积神经网络
卷积的参数量
GoogLeNet 使用不同大小的卷积核
ResNet 使用 1x1 卷积核压缩通道数
可分离卷积
MobileNet V1/V2/V3 (2017 ~ 2019)
ResNeXt 中的分组卷积
模型学习
模型学习的范式
范式一 : 监督学习
范式二 : 自监督学习
图像分类
什么是图像分类?
任务目标 : 给定一张图片,识别图像中的物体是什么?
图像分类问题的本质 : 构建一个可计算实现的函数 F ,且预测结果符合人类认识。
视觉任务的难点
难点在于图像的内容是像素整体呈现出的结果,和个别像素的值没有之间关联,难以遵循具体的规则设计算法
超越规则 : 让机器从数据中学习
- 收集数据
- 定义模型
- 训练
- 预测
机器学习的优势和局限性
- 机器学习算法善于处理低维、分布相对简单的数据
- 图像数据在几十万维的空间中以复杂的方式"缠绕"在一起,常规的机器学习算法难以处理这种复杂数据分布
传统方法 : 设计图像特征(1990s ~ 2000s)
使用人工设计的算法从图像中提取出特征向量,再将提取出的数千维特征向量交给机器,通过机器学习达到分类的效果。
特征工程的天花板 : 在 ImageNet 图像识别挑战赛里,2010 和 2011 年的冠军队伍都使用了经典的视觉方法,基于手工设计的特征 + 机器学习算法实现图像分类,Top-5 错误率在 25% 上下。
缺陷 : 受限于人类的智慧,手工设计特征更多局限在像素层面的计算,丢失信息过多,在视觉任务上的性能达到瓶颈。
从特征工程到特征学习
将图像直接交给机器,让机器自己从图像中进行可学习的特征提取,学习如何产生合适分类的特征。
AlexNet的诞生 & 深度学习时代的开始
AlexNet (2012)
- 第一个成功实现大规模图像的模型,在 ImageNet 数据集上达到 ~85% 的 top-5 准确率
- 5个卷积层,3个全连接层,共有 60M 个可学习参数
- 使用 ReLU 激活函数,大幅提高收敛速度
- 实现并开源了 cuda-convnet,在 GPU 上训练大规模神经网络在工程上成为可能
Going Deeper (2012 ~ 2014)
VGG (2014)
将大尺寸的卷积拆解为多层 3x3 的卷积,是网络具有相同的感受野、更少的参数量、更多的层数和表达能力。
- 网络层数 : 11、13、16、19层
- 3x3 卷积配合 1 像素的边界填充,维持空间分辨率
- 每个几层倍增通道数、减半分辨率,生成 1/2、1/4 尺度的更高抽象层级的特征
GoogLeNet (Inception v1,2014)
- 使用 Inception 模块堆叠形成,22个可学习层
- 最后的分类仅使用单层全连接层,可节省大量参数
- 仅 7M 权重参数(AlexNet 60M、VGG 138M)
残差学习的基本思路
精度退化问题 : 模型层数增加到一定程度后,分类正确率不增反降。
实验的反直觉 : 如果一个浅层网络在分类问题上已经表现得很不错了,深层网络无非就是在浅层网络后再加上一个卷积层,但卷积层实质上是一个线性操作,他会退化成恒等映射,当卷积退化为恒等映射时,深层网络与浅层网路相同,所以,深层网络应具备不差于浅层网络的分类精度。
猜想 : 虽然深层网络有潜力达到更高的精度,但常规的优化算法难以找到这个更优的模型,即,让新增加的卷积层拟合一个近似恒等映射,恰好可以让浅层网络变好一点。
残差建模 : 让新增加的层拟合浅层网络和深层网络之间的差异,更容易学习梯度可以直接回传到浅层网络监督浅层网络的学习。该范式没有引入额外参入,能让参数更有效贡献到最终的模型中。
残差网络 ResNet (2015)
以 VGG 为基础,保持多级结构、增加层数,增加跨层连接。
- 5 级,每级包含若干残差模块,不同残差模块个数不同 ResNet 结构
- 每级输出分辨率减半,通道倍增
- 全局平均池化压缩空间维度
- 单层全连接层产生类别概率
ResNet中的两种残差模块 :
- Basic block 用于 ResNet-18 和 34
- Bottleneck block 用于 ResNet-50、101和152,1x1 卷积用于压缩通道,降低计算开销
ResNet的后续改进 :
- ResNet B/C/D 残差模块的局部改进
- ResNeXt 使用分组卷积,降低参数量
- SEResNet 在通道维度引入注意力机制
更强的图像分类模型
神经结构搜索 Neural Architecture Search (2016+)
基本思路 : 借助强化学习等方法搜索表现最佳的网络。
代表工作 : NASNet(2017)、MnasNet(2018)、EfficientNet(2019)、RegNet(2020)等。
Vision Transformers(2020+)
使用 Transformer 替代卷积网络实现图像分类,使用更大的数据集训练,达到超越卷积网络的精度
代表工作 : Vision Transformer(2020),Swin-Transformer(2021 ICCV 最佳论文) 。
ConvNeXt(2022)
将 Swim Transformer 的模型元素迁移到卷积网络中,性能反超 Transformer。
轻量化卷积神经网络
卷积的参数量
- 输入特征图 X (H x W x C)
- 输出特征图 Y (H' x W' x C')
- C‘ 个 C 通道的卷积核 K (C' x K x K' x C)
- C' 个 偏置值 b (C')
卷积层的可学习参数包括 : 卷积核 + 偏置值。
参数量计算公式 : C’ x (C x K x K + 1) = C‘CK² + C’
输出特征图每个通道上的每个值都是输入特征图和 1 个 C 通道的卷积核进行一次卷积的结果。
乘加次数计算公式 : H‘ x W’ x C‘ x (C x K x K) = H’W‘C’CK²
- 降低通道数 C‘ 和 C (平方级别)
- 减小卷积核的尺寸 K (平方级别)
GoogLeNet 使用不同大小的卷积核
基本思路 : 并不是所有特征都需要同样大的感受野,在同一层中混合使用不同尺寸的特征可以减少参数量。
ResNet 使用 1x1 卷积核压缩通道数
1x1 卷积用于压缩通道,降低计算开销。
可分离卷积
将常规卷积分解为逐层卷积和逐点卷积,降低参数量和计算量。
例如将 32个3通道3x3的卷积核 拆解成 3个单通道3x3的卷积核 + 32个1x1的卷积核。
MobileNet V1/V2/V3 (2017 ~ 2019)
MobileNet V1 使用可分离卷积,只有 4.2M 参数。
MobileNet V2/V3 在 V1 的基础上加入了残差模块和 SE 模块。
ResNeXt 中的分组卷积
ResNeXt 将 ResNet 的 bottleneck block 中 3x3 的卷积改为分组卷积,降低模型计算量可分离卷积为分组卷积的特殊情形,组数=通道数。
模型学习
模型学习的范式
目标 : 确定模型 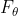 的具体形式后,寻找最优函数
的具体形式后,寻找最优函数  ,使得模型
,使得模型 ![]() 给出准确的分类结果
给出准确的分类结果 ![]()
范式一 : 监督学习
- 标注一个数据集
- 定义损失函数,衡量单个预测结果的好坏
- 解一个最优化问题,寻找使得总损失最小的参数
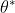
监督学习存在的问题 : 互联网数据是海量的,但数据的标注是昂贵的。
范式二 : 自监督学习
- 通过恰当设计辅助任务,让模型在无标注数据集上学习好的特征
- 再把模型放在一个相对小的标注数据集上训练分类