利用GPU训练
利用GPU来训练一般来说训练的速度比CPU要快的多,并且添加GPU也并不复杂,添加cuda()即可。
在下面模块添加GPU操作语句:
1.神经网络模型
#搭建神经网络
class Gu(nn.Module):
def __init__(self):
super(Gu , self).__init__()
self.model1 = Sequential(
Conv2d(3, 32, 5, 1, 2),
MaxPool2d(2),
Conv2d(32, 32, 5, 1, 2),
MaxPool2d(2),
Conv2d(32, 64, 5, 1, 2),
MaxPool2d(2),
Flatten(),
Linear(64*4*4, 64),
Linear(64, 10)
)
def forward(self,x):
x = self.model1(x)
return x
gu = Gu()
#添加gu=gu.cuda()
if torch.cuda.is_available():
gu=gu.cuda()这里添加if torch.cuda.is_available()语句保证程序可以运行,后面各处添加cuda()语句前都添加了这里的if语句
如果你电脑有GPU则优先利用GPU训练,如果没有自动选择CPU训练
如果没有这个if语句,电脑上没有GPU,运行时会报出你没有GPU无法训练
2.损失函数
#损失函数
loss_fn = nn.CrossEntropyLoss()
if torch.cuda.is_available():
loss_fn = loss_fn.cuda()3.训练及测试的数据
#训练
gu.train()
for data in train_dataloader:
imgs,targets = data
if torch.cuda.is_available():
imgs = imgs.cuda()
targets = targets.cuda()
outputs = gu(imgs)
loss = loss_fn(outputs,targets) #测试
gu.eval()
total_test_loss = 0
total_accuracy = 0
with torch.no_grad():
for data in test_dataloader:
imgs, targets = data
if torch.cuda.is_available():
imgs = imgs.cuda()
targets = targets.cuda()
outputs = gu(imgs)
loss = loss_fn(outputs, targets)
total_test_loss = total_test_step + loss.item()
accuracy = (outputs.argmax(1) == targets).sum()
total_accuracy = total_accuracy + accuracyGPU训练时长: CPU训练时长:
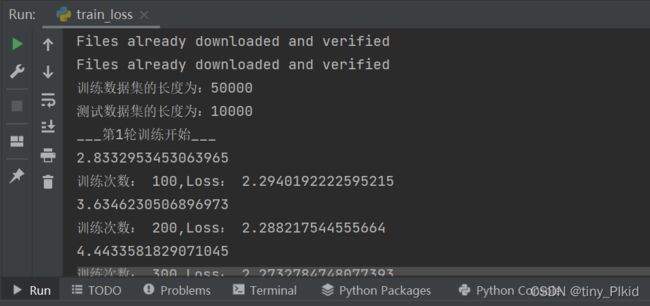
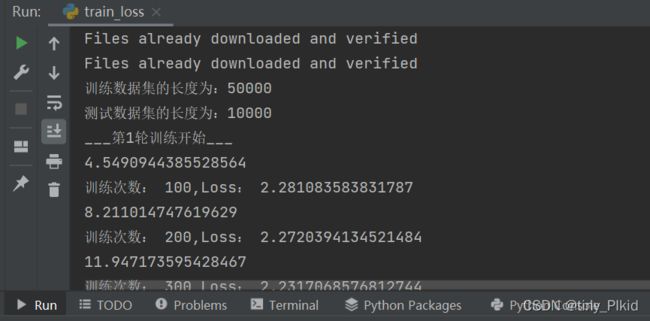
第一百次时GPU用时2秒多,CPU用时4秒多
可以看出GPU的训练速度是明显快于CPU的,在训练一些数据集较大的项目时还是可以省下很多时间的
完整代码:
import time
import torch
import torchvision.datasets
from torch import nn
from torch.nn import Sequential, Conv2d, MaxPool2d, Flatten, Linear
#数据集
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
train_data = torchvision.datasets.CIFAR10(root="../data",train=True,transform=torchvision.transforms.ToTensor(),download=True)
test_data = torchvision.datasets.CIFAR10(root="../data",train=False,transform=torchvision.transforms.ToTensor(),download=True)
#获取数据集长度
train_data_size = len(train_data)
test_data_size = len(test_data)
print("训练数据集的长度为:{}".format(train_data_size))
print("测试数据集的长度为:{}".format(test_data_size))
#利用DataLoader加载数据集
train_dataloader = DataLoader(train_data, batch_size=64)
test_dataloader = DataLoader(test_data, batch_size=64)
#搭建神经网络
class Gu(nn.Module):
def __init__(self):
super(Gu , self).__init__()
self.model1 = Sequential(
Conv2d(3, 32, 5, 1, 2),
MaxPool2d(2),
Conv2d(32, 32, 5, 1, 2),
MaxPool2d(2),
Conv2d(32, 64, 5, 1, 2),
MaxPool2d(2),
Flatten(),
Linear(64*4*4, 64),
Linear(64, 10)
)
def forward(self,x):
x = self.model1(x)
return x
gu = Gu()
#添加gu=gu.cuda()
if torch.cuda.is_available():
gu=gu.cuda()
#损失函数
loss_fn = nn.CrossEntropyLoss()
if torch.cuda.is_available():
loss_fn = loss_fn.cuda()
#优化器
learnnig_rate = 1e-2
optimizer = torch.optim.SGD(gu.parameters(),lr= learnnig_rate)
#设置参数
total_train_step = 0
total_test_step = 0
epoch = 10
#tensorboard
writer = SummaryWriter("../logs_train")
start_time = time.time()
for i in range(epoch):
print("___第{}轮训练开始___".format(i+1))
#训练
gu.train()
for data in train_dataloader:
imgs,targets = data
if torch.cuda.is_available():
imgs = imgs.cuda()
targets = targets.cuda()
outputs = gu(imgs)
loss = loss_fn(outputs,targets)
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_train_step = total_train_step + 1
if total_train_step % 100 == 0:
end_time = time.time()
print(end_time - start_time)
print("训练次数: {},Loss: {}".format(total_train_step,loss.item()))
writer.add_scalar("trian_loss",loss.item(),total_train_step)
#测试
gu.eval()
total_test_loss = 0
total_accuracy = 0
with torch.no_grad():
for data in test_dataloader:
imgs, targets = data
if torch.cuda.is_available():
imgs = imgs.cuda()
targets = targets.cuda()
outputs = gu(imgs)
loss = loss_fn(outputs, targets)
total_test_loss = total_test_step + loss.item()
accuracy = (outputs.argmax(1) == targets).sum()
total_accuracy = total_accuracy + accuracy
print("整体测试集上的Loss:{}".format(total_test_loss))
print("整体测试集上的正确率:{}".format(total_accuracy/test_data_size))
writer.add_scalar("test_loss",total_test_loss,total_test_step)
writer.add_scalar("test_accuracy", total_accuracy/test_data_size, total_test_step)
total_test_step = total_test_step + 1
torch.save(gu,"gu_{}.pth".format(i))
print("模型已保存!")
writer.close()