Tesseract综述
第二个:识别原理
- 架构说明-Tesseract的识别步骤大致如下:
1. 连通区域分析,检测出字符区域区域(轮廓外形),以及子轮廓。在此阶段轮廓线集成为块区域。(it is simple to detect inverse text and recognize it as easily as black-on-white text,outlines are gathered together, purely by nesting, into Blobs.)
2. 由字符轮廓和块区域得出文本行(Blobs are organized into text lines),以及通过空格(字符间距)识别出单词。固定字宽文本(fixed pitch)通过字符单元分割出单个字符,而对百分号的文本(Proportional text)通过一定的间隔(空格)和模糊间隔(fuzzy spaces)来分割;
3. 两阶段识别过程之第一阶段:依次对每个单词进行分析,然后传递给自适应分类器,分类器有学习能力,先分析的且满足条件的单词也作为训练样本,所以后面的字符(比如页尾)识别更准确;两阶段识别过程之第二阶段:此时,页首的字符识别相对而言比较不准确,所以tesseract会再次对识别不太好的字符识别是其精度得到提高。
4.最后,识别含糊不清的空格,及用其他方法,如由笔画高度(x-height),识别小写字母(small-cap)的文本。
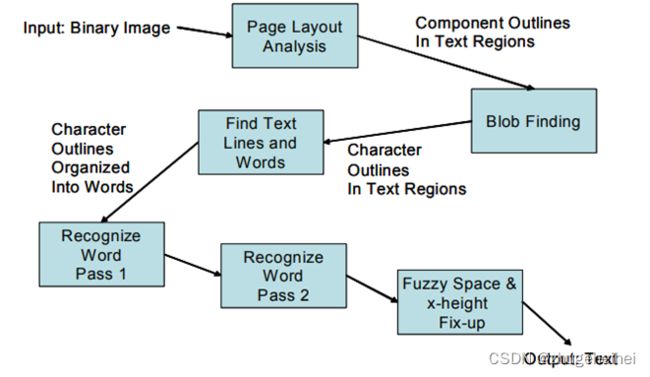
- 文本行和单词的查找技术(Blobs:连通区域、连通域、连通分量)
a. 连通域分析及过滤:假设页面布局分析(page layout analysis)大致确定了文本区域和文本尺寸,一个简单百分位高度过滤器(percentile height filter)可以将跨行大写字母及纵向粘连一起的字符过滤掉,利用字符的高度信息,选取所有字符的中值高度,通过高度的比例调节去掉一些无关的块,比如标点符号,变音符和噪声等;
b. 排序、创建初始行、基线拟合:对块区域的x坐标排序,运用α算法创建初始行,然后利用坐标拟合基线/直线(baseline),拟合方法:中位数最小方差拟合(least median of squares fit)à>二次线条+最小二乘法
c. 进一步,拟合文本行的形状,利用四次多项式,将文本行看成螺线形,采用最小二乘法拟合
d. 固定间隔检测和分割:检测出等距文本(fixed pitch text)并立刻分割为字符,中断之后的单词识别阶段的分割和分类操作,对粘连的文本进行分割(chopping)
e. 对非等距字体如百分号,斜体等问题,利用中线、基准线之间的空白大小,来分割字符,对接近阈值的空间被视为模糊空间,最后阶段进行处理。
注:相关函数:
页面结构分析:PageIterator * tesseract::TessBaseAPI::AnalyseLayout()
获取页面结构分析结果:Boxa * tesseract::TessBaseAPI::GetRegions(Pixa ** pixa)
连通域分析:Boxa * tesseract::TessBaseAPI::GetConnectedComponents;
获取每一块(block由页面结构分析获得)中的文字方向:
void tesseract::TessBaseAPI::GetBlockTextOrientations
获取Strip区域:Boxa * tesseract::TessBaseAPI::GetStrips
获取文本行:Boxa * tesseract::TessBaseAPI::GetTextlines
以Boxa格式获取文字:Boxa * tesseract::TessBaseAPI::GetWords(Pixa ** pixa)
- 单词识别
上面得到的字符送入分类器,反之非固定间隔的最后处理。
首先是分割粘连字符,将凹进去的轮廓点作为备选分割点,分割后,进行识别,如果都失败,就认为字符破损不全,修补字符(associator)。
然后对破碎的字符,放入associator,它采用利用A*算法搜索最优的字符组合,直到达到满意的识别结果。(识别成功的关键是字符分类器可以很好的识别破碎的字符)
(A*算法尽可能多的组合分割的字符,通过维护访问状态的哈希表隐藏分割,算法引入了优先级队列,存放候选的新状态/组合,并通过分类来评估当前操作)

- 静态字符识别(分类器)
PART1:特征
最初:拓扑特征,但是不适用现实的图形
然后:将字符近似为多边形作为特征,但不适合于破碎字符
突破:训练阶段的特征不必和识别的特征相同。训练阶段用近似多边形作为特征,识别阶段,抽取字符的轮廓特征(固定的小的长度)并归一化,然后将训练集中的原型特征再与之进行多对一的方式匹配。(matched many-to-one against the clustered
prototype features of the training data.)
演示:如下图,待识别的短线和训练集提取的虚线特征。

优点:小特征匹配大原型可以适用于受损图像识别
缺点:二者直接的距离计算困难。
注:The features extracted from the unknown:待识别字符的特征,3维数据(x, y坐标,角度),每个字符一般有50-100个特征
the prototype features:原型特征(训练集中的字符特征),4维数据(x, y坐标,角度,长度)一般有10-20个特征。
PART2:分类
第一步:
class pruner类修剪器创建未知字符可能匹配的字符类短列表。每个特征从一个三维查找表中获取一个他可能匹配的类的比特向量,同时这些比特向量基于所有特征求和。值最大的类(修正了预期的特征数量后)作为下一步中的短列表。
未知的每一个特征都查找一个他可能匹配的给定类原型的位向量。然后哦计算他们之间的实际相似度。每个原型字符类用带有称为”配置”的逻辑和积表达式,因此距离计算过程记录下每个配置中的每个特征以及每个原型的总相似度。计算出的最佳组合距离是该类所有存储配置的最佳。
分为两个步骤:
a. 粗分,多个特征,将每个特征相近的字符列举出来
b. 细分,对相近的字符,用特征距离进行细分
PART3:训练数据
分类器能够识别受损数据,没必要训练它们。
94个字符,8种字体(统一大小),4种属性(正常,粗体,斜体,斜粗体),每种20个样本,共60160个样本。
- 语法分析
在新的分割时,选择以下标准的最佳可用单词:最常用的高频词,字典中的常用词,常用数字,常用大写、小写单词(带有可选的首字母大写)、最常用的分类器选择单词。
给定的分割方式用总举例评分最低的单词评定,其中算法采用分类加权计算最小距离。
(将分割出的、待识别的词与这些词进行比较计算,算法采用加权最小距离。)
问题:不同的分割,会识别出不同的结果(有不同的字符个数)。两种结果都有可能,原因在于分割的不确定。因此Tesseract用两个指标进行量化,一个是confidence,将未知字符到原型的归一化距离的负值为指标(confidence越大识别效果越好);第二是评级(rating)将未知字符的轮廓长度与未知字符到原型的归一化的距离相乘作为指标。可以有意义地求和单词内的字符评级,因为单词内所有字符的总轮廓长度总是相同的。
注:相关函数:
以数组形式返回所有文字的置信值(confidence):
int * tesseract::TessBaseAPI::AllWordConfidences()
返回所有文字的平均置信值(confidence):
int tesseract::TessBaseAPI::MeanTextConf()
- 自适应分类器
由于静态分类器涉及到/擅长多种字体,其区分相近字符、字符与非字符的能力被削弱。此时,由于每页文档内的字符的个数有限,利用静态分类器的结果可以训练出对字体更敏感的自适应分类器,以便提高分类能力。
tesseract不用模板分类器,但使用和静态分类器相同的特征和分类器。除了训练集外,静态与自适应分类器的区别唯一显著的区别是自适应分类器会将一行字符的基线(baseline)/x-高度(小写字母x的高度) 归一化。 【归一化后,很容易区分字母大小写及噪声】;而静态分类器用质心(一阶矩)进行位置归一化,用二阶矩进行各向异性大小归一化。值得注意的是,自适应分类是是实时训练的。
前者能够很容易区分大小写字母,同时能够对噪声的抵抗力(据tesseract历史一文提到,与单独使用静态分类器相比,它可以将超大文档的错误率降低30%-60%)。而后者,即将字符的矩归一化最大的好处是去除高宽比( aspect ratio )和一定程度的字体笔画宽度(stroke width)的影响,且使上标、下标的区分简单,但这需要额外的分类器特征来区分字母的大小写。(两种归一化:基线/x行高的归一化,单个字符距的归一化)
注:下图为二者对比:

- 结论
第一:现有与原来的区别很大,如下图:
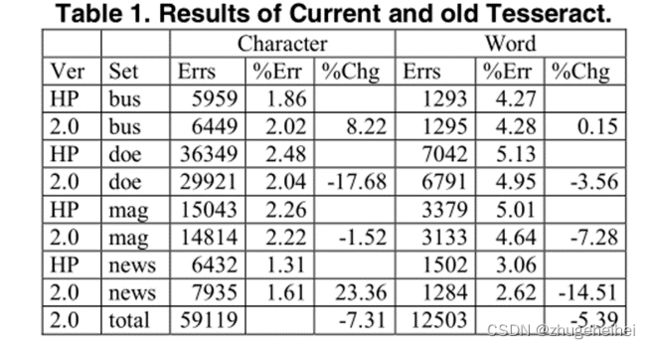
第二:准确率不比商业引擎,但是关键优势在于特征选择策略,缺点在于用多边形近似放入分类器,而不是用原始轮廓。
第三:如果适当地增加一个基于隐马尔可夫模型的字符n - gram模型,并可能增加一个改进的字符分割器,准确率可能会显著提高
文档组件:adaptive character classification, adaptive font spacing/character size models, and document dictionaries. segmentation-free, also-known-as sliding window
classification,
加:Tesseract搜索很简单,它从分类器中剔除置信度差的区域,每一次搜索都要听分类器和语言模型的指示。如果分割结果不理想,他会根据二者的指示连接相邻的字符片段。每个新分割都会采用光束搜索(The beam search),直到产生一个满意的结果。
而这种搜索依赖于初始分割接近正确的假设。
Tesseract最近添加了基于制表符停止检测的完整布局分析,可以处理非文本、多列和表格。布局分析和字符分割过程使用二进制(二值化的?)连接组件/连通域的轮廓,但没有任何基本的规定说分类器必须从二进制轮廓中提取特征。在最近的一个变化中,针对中文和低分辨率输入,增加了从灰度中提取特征的能力。
传统的机器学习分类器方法要么在这个n维空间中找到最近的训练样本(例如kNN分类器),要么将空间划分为与类标签对应的区域(例如SVM),并为给定的未知样本返回相应的标签。Tesseract采取了不同的方法。
第一阶段(概率统计模型):早期的Tesseract受到了心理学研究的影响,他们认为人类的知觉利用了拓扑/结构特征。即手写笔轨迹类似于骨架拓扑特征,但是这并不适用于打印字符。
Tesseract仍然着眼于一系列低维特征向量集合分类的路线,而不是单一的高维特征向量。其分类器基于贝叶斯参数高斯混合模型,它把每一个字体/字符组合视为独立的类。它假设统计独立性,同时这个团队中就独立性假设有许多讨论。
具有象征意义的是,在训练中,单个字符/字体组合的含有n维的样本特征聚类为JK个聚类均值,基于正态分布模型 。一个具有M个n维特征向量的未知字符Xl
。一个具有M个n维特征向量的未知字符Xl
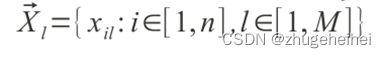
这么分类:
其中i是特征维度,j是聚类,k是字符类,l是未知字符的特征索引(让l和j能够匹配使得如下平方和距离最小)
因此,特征仍然是拓扑的,但是是从轮廓中提取(除非图像退化)。基于此,特征必须尽可能不受退化影响。
第二阶段(对称欧氏距离模型):收缩特征-放弃统计学模型
在发现拓扑太鸡肋后,特征变成了越来越小的轮廓碎片,一度是四维的,最后变成了三维(x,y,方向/角度 0-2π),原本是长度的第四维变为了小的常数。如下图,左边为纳米特征,右边为皮米特征。在3.0的tesseract中,特征提取皮特征,训练聚集了纳米特征,这种安排提供了更好的聚类和对于噪声的鲁棒性。

当然,这一趋势也反映在OCR领域。结构特征被大量抛弃,转而去更小的特征,例如像素,标志是DBN网络的出现,它输入像素级然后通过多层卷积获得更高级别/结构特征。
Tesseract特征减少,数量增多,独立性不再成立,因此它丢弃了统计概率模型,用欧几里得距离取而代之。此时距离为未知字符轮廓碎片和训练字符的轮廓碎片,分类算法如下:
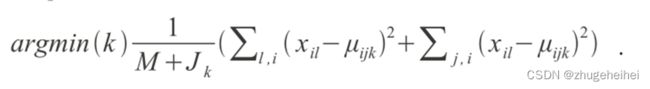
分类器为未知字符的每个特征寻找最近的聚类均值,反之亦然,然后距离相加再除未知字符总特征数量和训练样本的总特征数量。与上面方程比,该方程计算了平均距离而不是最大值。
由于特征数量很多,一组特征可能同时出现,并随着角色变换一起运动,这使得绝对距离判断变得复杂。但对称的优势在于减轻了第二个求和的统计独立性问题。
第三阶段:维度是否可变?--与常规方法的比较
传统的(有些说现代的)分类器,如SVM,需要固定维度的特征空间。从结构特征集(如Tesseract)转换到固定维度空间的一种传统方法是将特征空间量化为高维二进制特征空间,其中每个比特表示每个量子单元中某个特征的出现。因此,n个Tesseract特征将产生一个具有n个设定位的稀疏高维二进制特征向量,该方法用于Tesseract的类修剪器。其缺点是,当每个维度都是二进制时,特征空间中的欧氏距离在每个维度为二进制时变为汉明距离,因此单个特征从一个量子单元移动到下一个量子单元时,其值发生微小变化,此时汉明距离为2,这与特征空间中某个位置的特征消失并被替换相同。原空间中邻近的特征在量化空间中没有特殊的联系,这意味着泛化能力大大降低。
另一种将结构空间映射到固定维空间的方法是在更粗的量化网络上计算直方图,如梯度直方图。该方法在处理自然位于量子边界附件特征时会出现问题。最近的工作是通过优化粗量子边界来解决这个问题。
增强泛化的现代方法是在训练期间给分类器喂更多的数据。理论和实践表明,判断模型渐进优于生成模型(至少是朴素贝叶斯模型),但通常需要更多的训练数据。这是另一种说法,即判别式模型的泛化能力相较而言更低,但比生成式模型更善于学习更复杂的空间。
隐马尔可夫模型( Hidden Markov Model,HMM )分类器是最接近Tesseract的传统系统。它们带自循环的状态转换类似于处理多个可变数目的特征,尽管有严重的序列限制,并且通常比Tesseract典型字符的特征数目少一个数量级。HMM分类器的主要优点是内部状态转换包含了所需特征的更细粒度的细节,因此比公式( 2 )能更好地解决统计独立性问题。
principled是一个经常与统计方法,特别是与HMM相关的词,而非统计方法,比如Tesseract被描述为ad - hoc,然而这些所谓的principled模型通常使用对数线性模型来组合概率,而这些概率是由高斯混合模型衍生而来的。在对数线性模型中,分类是基于调整一组权重α i:

对于某些特征函数xi中的i上的集合,像之前一样使用k作为类,高斯混合模型提供基于正态分布的概率:
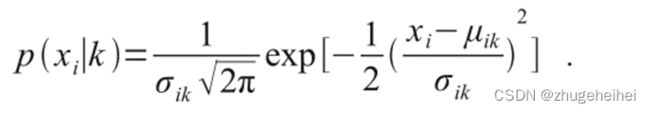
二者结合:

看起来很像式子。( 2 ),加上一个加法和一个乘法常数,但丧失了对称性,转而由字符中允许的状态的组合来弥补。这是一个特别有趣的结果,因为它显示了Tesseract的ad - hoc、无统计的方法与所谓的原则统计方法所使用的模型有多么密切的关系。标准差的加入并不具有严格的重要性,一个学习到的参数会推翻它。这里真正的区别在于额外的一组学习参数( αi ),但需要注意的是,这些并不是来自严格的统计模型。
第四阶段:通过归一化进行适应和泛化
第二节提到Tesseract使用自适应分类器。自适应分类器和静态分类器之间唯一真正的区别是在特征提取时应用于轮廓的归一化类型。在静态分类器中,未知轮廓的质心以特征空间为中心,并对轮廓的二阶矩进行各向异性缩放归一化。这种居中和缩放的目的是消除一些字体差异,例如纵横比,并允许上/下标被识别为正常字符,但也会引入一些歧义。自适应分类器通过以轮廓线的水平质心为中心,而以文本线的垂直中心为中心来规范化未知内容。缩放是各向同性的,以归一化字符的x高度。这种规范化保留了字体差异,并提高了对胡椒噪声的免疫力,但使下/上标与正常文本不同。不同归一化的组合有助于提高整体精度
分类器
分类器本质上是一个优化的KNN分类器,返回最近匹配的训练样本(在字母簇的粒度级别)和字体对,名义上用公式2计算距离。暴力时间为O(JkKMn).,虽然这些特征是拓扑的,但是计算量并不大。当随着特征缩小时,大多数字符中存在50-100个特征。就英语而言,M是50-100,K=3520(32个训练字体* 110个字符集),n = 3,使得O(10的8次幂)距离计算,每个字符分类,这在当时的机器上是非常昂贵的。
将平方阶特征匹配降为线性的首要解决方法是量化和倒排索引。这与两阶段分类相结合,显著降低了总CPU负载。第一阶段分类器,称为Class Pruner,如下图4所示,
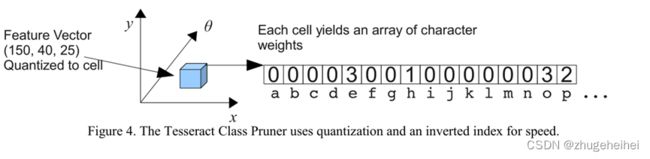
索引未知中每个特征向量的量化值,以获得允许该特征的类的集合。每个类的这种特征命中次数加总到特征上,最好的几个匹配类成为第二阶段的类短列表。这个过程与线性分类器完全相同,只是不需要进行乘法运算。象征性的,给定一个量化函数f:ℝn { 1,.. n ' },量化过程可以描述为:
![]()
在Tesseract Class Pruner中,每个三维维度都被量化为24个单元格,因此n'=24的3次方=13824。然后,类修剪器中的线性分类器可以简单地描述为:

其中权重wik为2位值。2bit权重定义了每个特征聚类平均值附近的倒排索引中的接受邻域,并使用任意距离常数而不是标准偏差计算。有了足够的训练数据,就没有特别的理由不使用标准差来定义邻域。
第二阶段的分类器按照式( 2 )计算距离,使用第二个倒排索引将未知的特征匹配到训练样本的特征,称为原型(prototypes)。因此,类修剪器的计算时间减少到O(KM),类修剪器提出的每个类的第二阶段的计算时间减少到O(Mn)。在英语中,Class Pruner约占总CPU的10%(每分类约60μs),二级分类器约占45%。在中文中,这些角色是相反的,因为类修剪器在类数量上是线性的,类修剪器占60%左右,二级分类器占30%左右。即使这些速度的改进也使得Tesseract的速度比20世纪90年代中期的商用发动机慢了大约10倍,但在随后的几年里,在提高精度方面,商用发动机也放慢了速度,使Tesseract的速度与今天相当。
测试
最初在一组30页的图像上完成测试的,这些图像以每英寸250像素的速度扫描,每像素4位灰度。而扫描仪是定制的,一个线阵CCD阵列连接到一个小型惠普钢笔绘图仪的绘图头,每个图像3MB,在4MB机器上甚至无法容纳单个完整图像。在将测试集扩展到400页8位灰度和每英寸300像素以及使用剩余系统升级部分拼凑出大约20台废旧机器组成的计算机服务器系统之后,准确性开发才真正开始发展。该系统在一组单独的图像上进行训练,这些图像以选择的字体进行打印并扫描获得真实场景的图像退化。多年来Tesseract的测试提出了几个重要的教训:
•小测试集毫无意义。在小型测试集上显示准确的OCR很容易,但要演示“工业级”的性能需要有足够大的含有真实变化的测试集。以阈值处理为例(它本身就是教训1的一个例子),最小误差阈值使用图像的前景和背景像素的统计模型来构造阈值解决方案,然后使用少量图像(由基于相同模型人为生成的)来测试该解决方案。不出所料,它在这个小规模的测试集上表现良好,但是该解决方案在许多真实的文字图像上表现得很糟糕,因为模型本身是有缺陷的。真实的细瘦文字图像无法与模型匹配,这是由于前景像素被字符边缘的像素严重超过,这导致前景峰值比实际的更宽许多。
•测试不同于训练数据的数据。识别像训练数据一样的数据,无论是单个或多个字体OCR都很容易。套外壳(Shrink-wrapped)的商业OCR引擎被称为“万能字体”,因为它可以识别任何以任何字体打印的内容,并且被设计用来这么做。万能字体OCR很难,因此,如果你想演示工业级的OCR,就必须测试与训练数据完全不同的数据。这使得随机划分数据集成训练和测试/验证集的常用方法存在缺陷。这种随机划分将类似或甚至相同的字体放到训练和测试集中,在万能字体OCR看来这是在作弊。尽管使用了常用的交叉验证方法可以最大限度地减少过度训练,但它们并不能评估样本所在的数据集之外的泛化能力。Tesseract现在使用合成数据(synthetic data)进行训练,使用真实数据进行测试,因此毫无疑问,测试结果显示了一些泛化能力。发展测试集(test set)与发展盲目测试集(blind test set)不同。
•每次更改都要测试。任何代码更改都有可能导致回归,因此测试的次数越多,就越容易确定造成问题的原因。在更细粒度的层次上,单元测试可以确保更改不会破坏假设或导致以前修复的问题出现回归。
•测量越多改进越多。测试数据和指标的维度越多,就越容易确定哪个模块导致特定错误。例如,仅仅测量字符错误率并不能表明错误是由字符分类器、语言模型还是布局分析引起的,但是引入 bag-of-words单词错误率和编辑距离单词错误率后,它们之间的差异会给出版面分析的错误率。在数据层面,仅仅看扫描的印刷材料并不能判断系统在相机拍摄的图像上如何表现。
•如果它能打破它就会。类似于完整的OCR系统这样复杂的软件必须经过彻底的测试。Tesseract的一个成功之处在于在1995年 UNLV测试中没有发生崩溃。这种鲁棒性是通过在200个不同的阈值下对400页集进行阈值处理生成的80000多幅图像进行测试得到的,这产生了大量严重退化的图像。由此产生的每一个崩溃都得到了修复。
•强大的计算能力有很大帮助。转变越快发展越快。上面的80000个页面占用了400个cpu天,这只有在分布式测试环境中才可能实现。我们现在通常/定期在30分钟内测试1500本书。
•如果您可以在测试运行的时间内编写更快的代码,那么就这样做吧。人们普遍认为过早的优化是一种浪费,或者在某种程度上缩小了研究方向。这种想法需要与更快的训练/测试周期会导致更快的进展这一事实相平衡。避免迭代训练算法的好处之一是,Tesseract的核心形状训练只需要几分钟,而不是通常需要几个小时或几天的训练(例如,训练一个基于神经网络的分类器)。
语言
直到2017年,Tesseract还只支持英语。Tesseract升级后可以支持大多数语言这件事更多是运气,而不是正确的判断。升级路径从西欧语言,接下来是东亚语言,然后是印度语、最后是希伯来语。本节将学到的关键教训是:一个针对特定语言的OCR系统对世界语言的OCR贡献不大,因为即使在包含历史变体之前,使用的语言也非常多
发展多语言引擎的第一个设计决策是识别单元(RU)的内部表示。它是OCR引擎识别的独立单元/形状。这里用RU来概括字母表、字符集和字形聚类,他们之中的每一个都有特定的含义。根据设计,OCR系统可能会选择识别不同的字形集,因此需要一个不同的术语。比如,类似于Tesseract的OCR系统,会识别整个汉字,而另一个OCR系统可以识别每个汉字中的单个偏旁。要意识到,在对某些语言(尤其是印度语)进行设计的早期阶段,一个单一的Unicode字符不能充分表示RU。在印度语言中,多个辅音可以与一个可选的元音组合在一起,形成一个字形聚类(代表一个音节),要么是一个连词,要么是一组孤立的连接组件,这些组件可能与单个unicode具有不同的形状。印度语有许多不同的字形聚类,这些字形聚类可以使用6个或更多个Unicode来表示,而且它们的大小和形状也不完全相同。
以下语言提供了涵盖大多数orthogonal difficulties的拓展语言集:
• English:英语之所以在这个名单上,是因为它是最难达到最先进水平的语言。在英语中很容易获得90%或更高的字符准确性,但商业引擎可以达到99%以上,这是由于数十年对“长尾”格式问题的研究:大写字母, 小写字母, pair字对(例如:Of goods vs. 11),外来词(含外来字符),多语言文件,双单引号vs.单双引号,破折号vs.连字符,软连字符vs.硬连字符,花引号vs.直引号,项目符号和内嵌logo,括号匹配,Helvetica/Arial I vs. l, Times Roman 1 vs. l,难以处理的字体(尤其是斜体和类似于script的字体),一行多尺寸,图像上的文本,垂直文本,反向文本,非矩形块,行号,表格,方程式,下标和上标,下划线,划除。 为了达到这样的准确性,必须降低语言模型的复杂度,而文档模型,无论是手工制作的马尔可夫模型的函数代码的一部分,,还是以某种方式学习的,都必须关注这些问题。
• 德语:德语名词组合随意,这是难处,Tesseract对于德语没有任何对于名词符合的特殊处理。
• 匈牙利语
• 俄语
• 日语/繁体中文:这两种文字都有竖线、字符集大、字细而字差小、字间距大等问题。繁体中文字符集更大,日语也有问题:一些字符集有两种大小。由于Tesseract内部对于页面的表示完全是矢量轮廓,因此把垂直文本行围绕原点进行简单旋转就可以实现下面操作:只需要使用负坐标,就可以让为水平文本行编写的代码也可以操作垂直文本行。当要对单个字符进行分类时,将其垂直旋转。分类器在简体中文中表现良好,但在繁体中文中开始与歧义作斗争。
软肋:语言模型和单词识别
Tesseract非常弱的组件是单词识别模块。它负责搜索分割空间(把单词分为字符),并把来自静态和动态分类器的信息与语言模型结合起来,形成对每个单词的最佳解释。语言模型开始是一个简单的状态机,它接受特定的字符类型序列,如大写、小写、小写,但不接受大写、小写、大写。
通过使用DAWG有向无环图作为连接表示(compact representation),一个单词清单被迅速添加,但是如何比较字典中的单词和非字典中的单词呢?两个不同长度的单词应该如何比较?如果我们没有放弃分类器返回概率的方式,我们可以以某种方式将词频和分类器概率结合起来,以获得一些总体概率,用于比较候选单词,但即使这样也会有缺陷。一个非字典中的单词需要一些随意/任意的字典外概率。一个4个字母的单词会将4个非统计独立的概率相乘,并且可能必须与一个3个字母的单词的3个非统计独立概率的乘积进行比较。
因此,在这一节中,将讨论非严格应用统计的价值。这里没有可靠的概率论和统计学理论可以严格应用。是不是或多或少地原则性地抛弃上述表示而使用机器学习?尽管Tesseract的单词识别器不是基于统计数据构建的,但它的原理可以清楚而简洁地陈述如下:
第一点:一个单词的字符分类器距离是根据字符中材料的数量(在本例中是轮廓的长度)进行加权组合的。在含有n个 RUs的单词中,用分类器距离di和每RU的长度为li的轮廓长度,则总单词距离(称为评级)r为: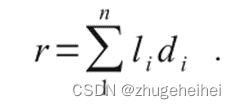
这使得不同长度的单词可以公平地进行比较,而不需要使用任意常数,因为这些常数必须从可能不是真正恒定的先验概率中推导出来。
第二点:这有几个词源,包括首选词,字典:系统,常用词,用户词,文档和数字解析器。每个词源都有一个权重。如果单词源j的权重为wj,并产生了一个评级为rj的单词,那么给定词源组合后产生的结果(单词)就是: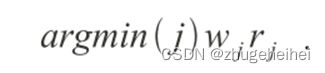
第三点:权重wj应该从数据中训练出来
第四点:最后的结果是在分段搜索中找到的加权评分/评级最小的单词
理想情况下,权重应该通过机器学习来训练。在UNLV试验之前,权重是用简单的遗传算法优化的。从那时起,权重一直是手工调整的,但现在一种新的机器学习方案也应用于这些权重,以提高特定于语言的准确性,并支持新的字符分类器的快速融入。
回到基于统计的系统是否更好的问题上,这取决于语言和输入的质量。如果语言出现OCR问题,和/或输入图像质量较差,那么更复杂的语言模型和更重的语言模型频率权重可能会有显著的好处。在高质量输入的英语情况下,必须仔细使用语言模型以获得最佳准确性,这导致了最后的教训:严格应用统计方法>严格应用数据驱动的机器学习>统计模型的不正确使用>非数据驱动模型。不幸的是,严格应用统计模型的场景寥寥无几,因此很难找到充分证明上述严格不等号的例子。以阈值划分为例,不恰当地使用统计模型(最小误差阈值划分)可能比非数据驱动的方法(以50%的灰度作为固定阈值)更糟糕,而使用严格应用统计分类的专有阈值划分算法胜过其他任何方法。在从不恰当的统计模型转向数据驱动的机器学习之后,Tesseract的准确性确实有所提高,但作为反面教材,基于HMM的系统对统计学的使用表现的很好,这难免让人怀疑。
结果
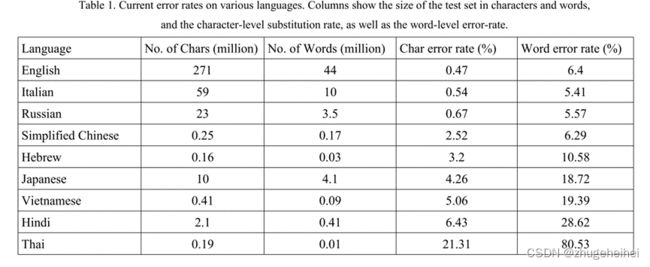
Tesseract定期测试30种语言,测试集采用多种办法创建。大多数基于拉丁语的语言和俄语的测试数据都是通过并行扫描书籍和PDF文本层创建的。大多数非拉丁语测试数据是由人类从谷歌books项目下扫描的书籍中随机选择10页连续输入文本创建的。没有一个真实的文本是完美的,尤其是pdf格式的文本,它包含大量的空白(破碎和合并的单词)错误。这些错误导致表1中报告的单词错误率明显高于给定字符错误率(不包括添加/删除空格)的预期。简体中文和日文的单词错误率是使用分词系统计算的,该系统本身就受到字符错误的影响。泰语的错误率特别高,因为它不是用空格分隔的语言,并且没有应用分词系统来计算错误率。另一个使单词错误率出乎意料地高的因素是,页面分割错误包括在单词错误率中,但字符错误率不包括这些错误。
结论
工业强度、高精度、通用的OCR很难实现,因为有许多组件必须是世界级的,才能与最好的商用系统竞争。在过去20年左右的时间里,传统的OCR方法获得了“ad-hoc”的标签,因为更多的统计系统试图通过使用“principled”的标签来疏远它们。本文描述了Tesseract如何明确地远离统计,试图将其分类器建立在比乏力/不严格的应用统计更严格的基础上。在某些方面,这使得Tesseract的“ad-hoc”方法比“peincipled”方法更有原则,但最终结果却惊人地相似。Tesseract和商业OCR系统的特殊性质实际上来自第6节中必须处理的“长尾”问题列表,以实现英语的竞争性准确性。相比之下,基于统计的翻译系统由于其纯粹的可伸缩性而击败了基于语法的翻译系统,但这些系统还没有达到需要解决一长串例外情况的准确性水平。考虑到这些问题,“ad-hoc”和“principled”的替代术语可能是“mature”和“naive”。
尽管Tesseract随着时间的推移而进化,但它的方向一直朝着成熟mature的传统架构:进化,而不是革命。进一步的进展可以通过对字符 和/或 单词分类器进行重大更改来实现。在最近最有前途的(革命性的)方法中,应用隐马尔可夫模型作为字符分类器(除了它们在语言模型中的长期使用外)比传统的机器学习更有优势,可以更好地匹配变长特征描述。DBN网络有一个额外的优势,它可以从无监督的训练数据中自动获得更高层次的特征(二维的,这与hmm不同)。