从SNE到t-SNE再到LargeVis
0x00 前言
本文谢绝转载,如有需要请联系bindog###outlook.com,###换成@
数据可视化是大数据领域非常倚重的一项技术,但由于业内浮躁的大环境影响,这项技术的地位渐渐有些尴尬。尤其是在诸如态势感知、威胁情报等应用中,简陋的可视化效果太丑,过于华丽的可视化效果只能忽悠忽悠外行,而给内行的感觉就是刻意为之、华而不实。
曾几何时,可视化技术不过是一种数据分析的手段罢了。惭愧的说就是我们的算法还不够智能,必须依靠人类的智慧介入分析。所以,需要通过可视化技术把高维空间中的数据以二维或三维的形式展示给我们这样的低维生物看,展示的效果如何也就直接决定着我们分析的难度。
抛开浮躁的大环境,在数据可视化领域还是有人踏踏实实做研究的,比如深度学习大牛Hinton(SNE)、Maaten(t-SNE)还有唐建大神(LargeVis,新鲜出炉,WWW’16最佳论文提名),下面言归正传,我们从简单的基础知识开始。
0x01 预备知识
说实在的,想要彻底搞清楚这些算法的原理并不轻松,需要长时间关注和积累。这里我把所需要知识和资料简要列出,供大家有针对性的了解。
降维
降维顾名思义就是把数据或特征的维数降低,一般分为线性降维和非线性降维,比较典型的如下:
-
线性降维:PCA(Principal Components Analysis)、LDA(Linear Discriminant Analysis)、MDS(Classical Multidimensional Scaling)
-
非线性降维:Isomap(Isometric Mapping)、LLE(Locally Linear Embedding)、LE(Laplacian Eigenmaps) 大家可能对线性降维中的一些方法比较熟悉了,但是对非线性降维并不了解,非线性降维中用到的方法大多属于流形学习方法。
流形学习
流形学习(Manifold Learning)听名字就觉得非常深奥,涉及微分流行和黎曼几何等数学知识。当然,想要了解流形学习并不需要我们一行一行的去推导公式,通过简单的例子也能够有一个直观的认识。关于流行学习的科普文章首推pluskid写的《浅谈流行学习》,里面有很多通俗易懂的例子和解释。
简单来说,地球表面就是一个典型的流形,在流形上计算距离与欧式空间有所区别。例如,计算南极与北极点之间的距离不是从地心穿一个洞计算直线距离,而是沿着地球表面寻找一条最短路径,这样的一条路径称为测地线。如下面所示的三幅图

其中第一张图为原始数据点分布,红色虚线是欧式距离,蓝色实线是沿着流形的真实测地线距离。第二张图是在原始数据点的基础上基于欧式距离构造的kNN图(灰色线条,下面还会具体介绍kNN图),红色实线表示kNN图中两点之间的最短路径距离。第三张图是将流形展开后的效果,可以看到,kNN图中的最短路径距离(红色实线)要略长于真实测地线距离(蓝色实线)。
在实际应用中,真实测地距离较难获得,一般可以通过构造kNN图,在kNN图中寻找最短路径距离作为真实测地线距离的近似。
t分布
大家在概率与统计课程中都接触过tt分布的概念,从正态总体中抽取容量为NN的随机样本,若该正态总体的均值为μμ,方差为σ2σ2。随机样本均值为x¯x¯,方差为s2=1N−1∑Ni=1(xi−x¯)2s2=1N−1∑i=1N(xi−x¯)2,随机变量tt可表示为:
t=x¯−μs/N−−√t=x¯−μs/N
此时我们称tt服从自由度为n−1n−1的tt分布,即t∼t(n−1)t∼t(n−1)
下图展示了不同自由度下的tt分布形状与正态分布对比,其中自由度为1的tt分布也称为柯西分布。自由度越大,tt分布的形状越接近正态分布。
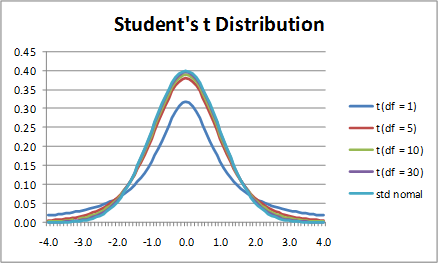
从图中还可以看出,tt分布比正态分布要“胖”一些,尤其在尾部两端较为平缓。tt分布是一种典型的长尾分布。实际上,在稳定分布家族中,除了正态分布,其他均为长尾分布。长尾分布有什么好处呢?在处理小样本和一些异常点的时候作用就突显出来了。下文介绍t-sne算法时也会涉及到t分布的长尾特性。
kNN图
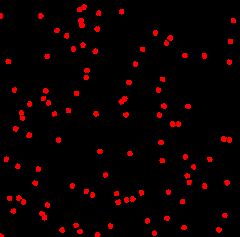
kNN图(k-Nearest Neighbour Graph)实际上是在经典的kNN(k-Nearest Neighbor)算法上增加了一步构图过程。假设空间中有nn个节点,对节点vivi,通过某种距离度量方式(欧式距离、编辑距离)找出距离它最近的kk个邻居v1,v2,⋯,vkv1,v2,⋯,vk,然后分别将vivi与这kk个邻居连接起来,形成kk条有向边。对空间中所有顶点均按此方式进行,最后就得到了kNN图。
当然,为方便起见,在许多场景中我们往往将kNN图中的有向边视为无向边处理。如下图是一个二维空间中以欧式距离为度量的kNN图。
kNN图的一种用途上文已经提到过:在计算流形上的测地线距离时,可以构造基于欧式距离的kNN图得到一个近似。原因很简单,我们可以把一个流形在很小的局部邻域上近似看成欧式的,也就是局部线性的。这一点很好理解,比如我们所处的地球表面就是一个流形,在范围较小的日常生活中依然可以使用欧式几何。但是在航海、航空等范围较大的实际问题中,再使用欧式几何就不合适了,使用黎曼几何更加精确。
kNN图还可用于异常点检测。在大量高维数据点中,一般正常的数据点会聚集为一个个簇,而异常数据点与正常数据点簇的距离较远。通过构建kNN图,可以快速找出这样的异常点。
k-d树与随机投影树
刚才说到kNN图在寻找流形的过程中非常有用,那么如何来构建一个kNN图呢?常见的方法一般有三类:第一类是空间分割树(space-partitioning trees)算法,第二类是局部敏感哈希(locality sensitive hashing)算法,第三类是邻居搜索(neighbor exploring techniques)算法。其中k-d树和随机投影树均属于第一类算法。
很多同学可能不太熟悉随机投影树(Random Projection Tree),但一般都听说过k-d树。k-d树是一种分割k维数据空间的数据结构,本质上是一棵二叉树。主要用于多维空间关键数据的搜索,如范围搜索、最近邻搜索等。那么如何使用k-d树搜索k近邻,进而构建kNN图呢?我们以二维空间为例进行说明,如下图所示:
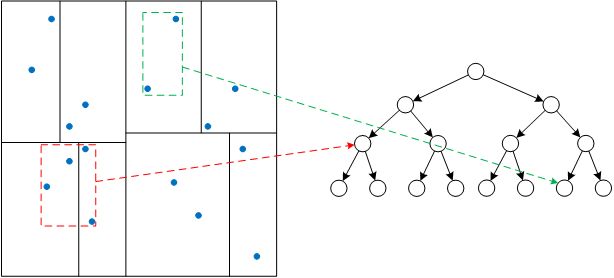
上图是一个二维空间的k-d树,构建k-d树是一个递归的过程,根节点对应区域内所有点,将空间按某一维划分为左子树和右子树之后,重复根结点的分割过程即可得到下一级子节点,直到k-d树中所有叶子节点对应的点个数小于某个阈值。
有了k-d树之后,我们寻找k近邻就不用挨个计算某个点与其他所有点之间的距离了。例如寻找下图中红点的k近邻,只需要搜索当前子空间,同时不断回溯搜索父节点的其他子空间,即可找到k近邻点。
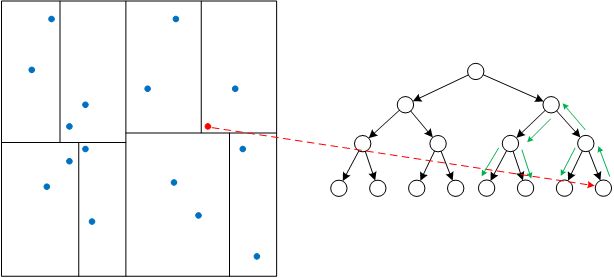
当然,搜索过程还有一些缩小搜索范围的方法,例如画圆判断是否与父节点的分割超平面相交等等,这里就不展开讨论了。
不过k-d树最大的问题在于其划分空间的方式比较死板,是严格按照坐标轴来的。对高维数据来说,就是将高维数据的每一维作为一个坐标轴。当数据维数较高时,k-d树的深度可想而知,维数灾难问题也不可避免。相比之下,随机投影树划分空间的方式就比较灵活,还是以二维空间为例,如下图所示:
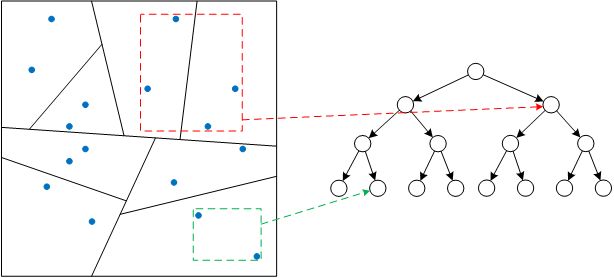
随机投影树的基本思路还是与k-d树类似的,不过划分空间的方式不是按坐标轴了,而是按随机产生的单位向量。有的同学说,这样就能保证随机投影树的深度不至于太深吗?随机产生的单位向量有那么靠谱吗?这里需要注意的是,我们所分析的数据处于一个流形上的,并非是杂乱无章的,因此从理论上讲,随机投影树的深度并不由数据的维数决定,而取决于数据所处的流形维数。(此处可参考Freund等人的论文《Learning the structure of manifolds using random projections》)
那么如何使用随机投影树寻找k近邻呢?当然可以采用和k-d树类似回溯搜索方法。但是当我们对k近邻的精确度要求不高时,可以采用一个更加简单巧妙的方式,充分利用随机投影树的特性。简单来说,我们可以并行的构建多个随机投影树,由于划分的单位向量都是随机产生的,因此每棵随机投影树对当前空间的划分都是不相同的,如下图所示
例如我们想搜索红点的k近邻,只需要在不同的随机投影树中搜索其所处的子空间(或者仅回溯一层父结点),最后取并集即可。这样做虽然在构建随机投影树的过程中较为耗时耗空间,但是在搜索阶段无疑是非常高效的。
LINE
LINE,即Large-scale Information Network Embedding,是唐建大神2015年的一项工作(www’15)。内容依旧很好很强大,而且代码是开源的。
一句话概括,LINE是“Embed Everything”思想在网络表示中的发扬光大。自从Mikolov开源word2vec以来,词向量(word embedding)的概念在NLP界可谓是火的一塌糊涂,embedding的概念更是快速渗透到其他各研究领域。entity embedding、relation embedding…等如雨后春笋般涌现,更是有人在Twitter上犀利的吐槽:
当然,这里完全没有贬低LINE的意思,事实上LINE的工作是非常出色的,主要有两大突出贡献:一是能够适应各种类型(无向边或有向边、带权值不带权值的)的大规模(百万级节点、十亿级边)网络,而且能够很好的捕获网络中的一阶和二阶相似性;二是提出了非常给力的边采样算法(edge-sampling algorithm),大幅降低了LINE的时间复杂度,使用边采样算法后时间复杂度与网络中边的数量呈线性关系。LargeVis的高效也得益于LINE及其边采样算法。
其中一阶相似性指的是网络中两个节点之间的点对相似性,具体为节点之间边的权重(如果点对不存在边,则其一阶相似性为0);二阶相似性指的是若节点间共享相似的邻居节点,那么两者就趋于相似。比如下图展示的这种情况,边的权值大小用粗细表示:
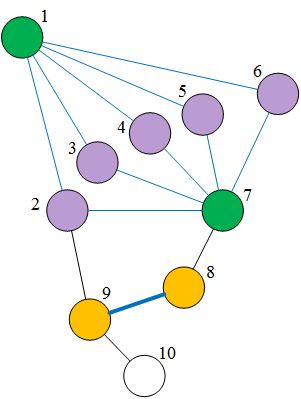
其中节点8与节点9之间的一阶相似性为较高,因为其直接连接边的权值较高。节点1与节点7有着绝大多数相同的邻居,因此两者的二阶相似性非常高。
边采样算法的思路来源于Mikolov在word2vec中使用的负采样优化技术。既提高了训练的效率,也解决了网络表示中带权值边在训练过程中造成的梯度剧增问题,具体的边采样算法在下文涉及的地方进行介绍。
负采样
了解word2vec的同学一定对负采样(Negative sampling)不陌生,Mikolov在word2vec中集成了CBOW和Skip-gram两种词向量模型,在训练过程中使用到了多项优化技术,负采样正是其中一种优化技术。我们以Skip-gram模型为例进行说明,Skip-gram模型的思路是从目标词预测上下文,用一个上下文窗口限定文本范围,如下图所示:
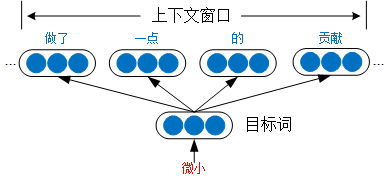
Skip-gram模型需要最大化“做了”“一点”“的”“贡献”等词语出现在目标词“微小”周围的概率,即最大化p(c∣w)=∑p(wi∣w)p(c∣w)=∑p(wi∣w)。出现在目标词周围上下文窗口中的词wi∈cwi∈c构成一个正样本(wi,w)(wi,w),未出现在目标词周围的词wj∈Dwj∈D构成负样本(wj,w)(wj,w)。我们在训练过程中要最大化正样本出现的概率,同时也要减小负样本出现的概率。为什么要减小负样本出现的概率呢,只提高正样本出现的概率不就可以了吗?举个不恰当的例子,这就好比垄断一样,为了达到最终目的不择手段,一方面肯定要加强自身产品的竞争力,另一方面竞争对手也在发展壮大,发展水平并不比我们差,所以必须使用些手段,打压消灭竞争对手,负采样也是这么个道理。
由于负样本数量众多(上下文窗口之外的词基本都可以构成负样本),直接考虑所有的负样本显然是不现实的,所以我们用采样的方式选一部分负样本出来即可。那么负采样具体如何采样呢?在语料中有的词语出现频率高,有的词语出现频率低,直接从词表中随机抽取负样本显然是不科学的。word2vec中使用的是一种带权采样策略,即根据词频进行采样,高频词被采样的概率较大,低频词被采样的概率较小。
那么具体如何带权采样呢?看下面这张图,词wiwi的词频用fwifwi表示
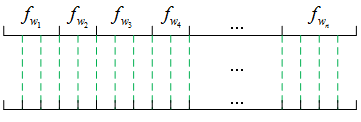
上面那根线段是按词频进行分割的,词频越高线段较长,下面的线段是等距离分割。我们往下方的线段中随机打点(均匀分布),根据点所落在的区间对应到上方的线段,即可确定所采样的词。直观来看,采用这种方式词频较高的词被采样到的概率更大,词频较低的词被采样到的概率更低。
加入负采样优化之后,目标函数的形式变为
logσ(vTwc⋅vw)+∑i=1k Ewi∼Pn(f)[logσ(−vTwi⋅vw)]logσ(vwcT⋅vw)+∑i=1k Ewi∼Pn(f)[logσ(−vwiT⋅vw)]
其中ww表示目标词,wcwc表示目标词周围上下文窗口中的词(正样本),wiwi表示未出现在上下文窗口中的词(负样本),kk表示抽取的负样本个数,Pn(f)Pn(f)是用于负样本生成的噪声分布,ff表示词频,Pn(f)∝f0.75Pn(f)∝f0.75,不要问我0.75怎么来的,Mikolov做实验得出来的,直接用原始词频效果不好,加个0.75次幂效果较好。
word2vec里面还有许多有意思的细节,感兴趣的同学可以去看看peghoty写的《word2vec中的数学原理》
0x02 从SNE说起
了解完预备知识后,我们可以从SNE开始本趟可视化算法之旅了。SNE即stochastic neighbor embedding,是Hinton老人家2002年提出来的一个算法,出发点很简单:在高维空间相似的数据点,映射到低维空间距离也是相似的。常规的做法是用欧式距离表示这种相似性,而SNE把这种距离关系转换为一种条件概率来表示相似性。什么意思呢?考虑高维空间中的两个数据点xixi和xjxj,xixi以条件概率pj∣ipj∣i选择xjxj作为它的邻近点。考虑以xixi为中心点的高斯分布,若xjxj越靠近xixi,则pj∣ipj∣i越大。反之,若两者相距较远,则pj∣ipj∣i极小。因此,我们可以这样定义pj∣ipj∣i:
pj|i=exp(−∥xi−xj∥2/2σ2i)∑k≠iexp(−∥xi−xk∥2/2σ2i)pj|i=exp(−‖xi−xj‖2/2σi2)∑k≠iexp(−‖xi−xk‖2/2σi2)
其中σiσi表示以xixi为中心点的高斯分布的方差。由于我们只关心不同点对之间的相似度,所以设定pi∣i=0pi∣i=0。
当我们把数据映射到低维空间后,高维数据点之间的相似性也应该在低维空间的数据点上体现出来。这里同样用条件概率的形式描述,假设高维数据点xixi和xjxj在低维空间的映射点分别为yiyi和yjyj。类似的,低维空间中的条件概率用qj∣iqj∣i表示,并将所有高斯分布的方差均设定为12√12,所以有:
qj|i=exp(−∥yi−yj∥2)∑k≠iexp(−∥yi−yk∥2)qj|i=exp(−‖yi−yj‖2)∑k≠iexp(−‖yi−yk‖2)
同理,设定qi∣i=0qi∣i=0。此时就很明朗了,若yiyi和yjyj真实反映了高维数据点xixi和xjxj之间的关系,那么条件概率pj∣ipj∣i与qj∣iqj∣i应该完全相等。这里我们只考虑了xixi与xjxj之间的条件概率,若考虑xixi与其他所有点之间的条件概率,则可构成一个条件概率分布PiPi,同理在低维空间存在一个条件概率分布QiQi且应该与PiPi一致。如何衡量两个分布之间的相似性?当然是用经典的KL距离(Kullback-Leibler Divergence),SNE最终目标就是对所有数据点最小化这个KL距离,我们可以使用梯度下降算法最小化如下代价函数:
C=∑iKL(Pi||Qi)=∑i∑jpj|ilogpj|iqj|iC=∑iKL(Pi||Qi)=∑i∑jpj|ilogpj|iqj|i
似乎到这里问题就漂亮的解决了,你看我们代价函数都写出来了,剩下的事情就是利用梯度下降算法进行训练了。但事情远没有那么简单,因为KL距离是一个非对称的度量。最小化代价函数的目的是让pj∣ipj∣i和qj∣iqj∣i的值尽可能的接近,即低维空间中点的相似性应当与高维空间中点的相似性一致。但是从代价函数的形式就可以看出,当pj∣ipj∣i较大,qj∣iqj∣i较小时,代价较高;而pj∣ipj∣i较小,qj∣iqj∣i较大时,代价较低。什么意思呢?很显然,高维空间中两个数据点距离较近时,若映射到低维空间后距离较远,那么将得到一个很高的惩罚,这当然没问题。反之,高维空间中两个数据点距离较远时,若映射到低维空间距离较近,将得到一个很低的惩罚值,这就有问题了,理应得到一个较高的惩罚才对。换句话说,SNE的代价函数更关注局部结构,而忽视了全局结构。
SNE代价函数对yiyi求梯度后的形式如下:
δCδyi=2∑j(pj|i−qj|i+pi|j−qi|j)(yi−yj)δCδyi=2∑j(pj|i−qj|i+pi|j−qi|j)(yi−yj)
这个梯度还有一定的物理意义,我们可以用分子之间的引力和斥力进行解释。低维空间中点yiyi的位置是由其他所有点对其作用力的合力所决定的。其中某个点yjyj对其作用力是沿着yi−yjyi−yj方向的,具体是引力还是斥力占主导就取决于yjyj与yiyi之间的距离了,其实就与(pj∣i−qj∣i+pi∣j−qi∣j)(pj∣i−qj∣i+pi∣j−qi∣j)这一项有关。
SNE算法中还有一个细节是关于高维空间中以点xixi为中心的正态分布方差σiσi的选取,这里不展开讲了,有兴趣的同学可以去看看论文。
最后,我们来看一下SNE算法的效果图。将SNE算法用在UPS database的手写数字数据集上(五种数字,01234),效果如下:

从图中可以看出,SNE的可视化效果还算可以,同一类别的数据点映射到二维空间后基本都能聚集在一起,但是不同簇之间的边界过于模糊。老实说,如果不是这个图上把不同类别用不同颜色和符号标识出来,根本没法把边界处的数据点区分开来,做可视化分析也非常不方便。这个问题下面我们还会详细分析。
0x03 从SNE到t-SNE——小小的t分布,迈进了一大步
SNE算法的思路是不错的,但是它的可视化效果大家也看到了,存在很大改进空间。如何改进它呢?我们一步一步来,先看看如何解决SNE中的不对称问题。
对称SNE
在原始的SNE中,pi∣jpi∣j与pj∣ipj∣i是不相等的,低维空间中qi∣jqi∣j与qj∣iqj∣i也是不相等的。所以如果能得出一个更加通用的联合概率分布更加合理,即分别在高维和低维空间构造联合概率分布PP和QQ,使得对任意i,ji,j,均有pij=pji,qij=qjipij=pji,qij=qji。
在低维空间中,我们可以这样定义qijqij:
qij=exp(−∥yi−yj∥2)∑k≠lexp(−∥yk−yl∥2)qij=exp(−‖yi−yj‖2)∑k≠lexp(−‖yk−yl‖2)
在高维空间呢?是不是可以想当然的写出:
pij=exp(−∥xi−xj∥2/2σ2)∑k≠lexp(−∥xk−xl∥2/2σ2)pij=exp(−‖xi−xj‖2/2σ2)∑k≠lexp(−‖xk−xl‖2/2σ2)
但是如果这样定义pijpij又会遭遇刚才的问题,考虑一个离群点xixi,它与所有结点之间的距离都较大,那么对所有jj,pijpij的值均较小,所以无论该离群点在低维空间中的映射点yiyi处在什么位置,惩罚值都不会太高,这显然也不是我们希望看到的。所以这里采用一种更简单直观的方式定义pijpij:
pij=pj|i+pi|j2npij=pj|i+pi|j2n
其中nn为数据点的总数,这样定义即满足了对称性,又保证了xixi的惩罚值不会过小。此时可以利用KL距离写出如下代价函数:
C=KL(P||Q)=∑i∑jpijlogpijqijC=KL(P||Q)=∑i∑jpijlogpijqij
梯度变为:
δCδyi=4∑j(pij−qij)(yi−yj)δCδyi=4∑j(pij−qij)(yi−yj)
相比刚才定义的公式,这个梯度更加简化,计算效率更高。但是别高兴的太早,虽然我们解决了SNE中的不对称问题,得到了一个更为简单的梯度公式,但是Maaten指出,对称SNE的效果只是略微优于原始SNE的效果,依然没有从根本上解决问题。
拥挤问题(The Crowding Problem)
所谓拥挤问题,顾名思义,看看SNE的可视化效果,不同类别的簇挤在一起,无法区分开来,这就是拥挤问题。有的同学说,是不是因为SNE更关注局部结构,而忽略了全局结构造成的?这的确有一定影响,但是别忘了使用对称SNE时同样存在拥挤问题。实际上,拥挤问题的出现与某个特定算法无关,而是由于高维空间距离分布和低维空间距离分布的差异造成的。
我们生活在一个低维的世界里,所以有些时候思维方式容易受到制约。比如在讨论流形学习问题的时候,总喜欢拿一个经典的“Swiss roll”作为例子,这只不过是把一个简单的二维流形嵌入到三维空间里而已。实际上真实世界的数据形态远比“Swiss roll”复杂,比如一个10维的流形嵌入到更高维度的空间中,现在我们的问题是把这个10维的流形找出来,并且映射到二维空间上可视化。在进行可视化时,问题就来了,在10维流形上可以存在11个点且两两之间距离相等。在二维空间中呢?我们最多只能使三个点两两之间距离相等,想将高维空间中的距离关系完整保留到低维空间是不可能的。
这里通过一个实验进一步说明,假设一个以数据点xixi为中心,半径为rr的mm维球(二维空间就是圆,三维空间就是球),其体积是按rmrm增长的,假设数据点是在mm维球中均匀分布的,我们来看看其他数据点与xixi的距离随维度增大而产生的变化。
代码如下所示:
# -*- coding: utf-8 -*-
import matplotlib.pyplot as plt
import numpy as np
from numpy.linalg import norm
npoints = 1000 # 抽取1000个m维球内均匀分布的点
plt.figure(figsize=(20, 4))
for i, m in enumerate((2, 3, 5, 8)):
# 这里模拟m维球中的均匀分布用到了拒绝采样,即先生成m维立方中的均匀分布,再剔除m维球外部的点
accepts = []
while len(accepts) < 1000:
points = np.random.rand(500, m)
accepts.extend([d for d in norm(points, axis=1) if d <= 1.0]) # 拒绝采样
accepts = accepts[:npoints]
ax = plt.subplot(1, 4, i+1)
ax.set_xlabel('distance') # x轴表示点到圆心的距离
if i == 0:
ax.set_ylabel('count') # y轴表示点的数量
ax.hist(accepts, bins=np.linspace(0., 1., 50), color='green')
ax.set_title('m={0}'.format(str(m)), loc='left')
plt.show()结果如下图所示:

从图中可以看到,随着维度的增大,大部分数据点都聚集在mm维球的表面附近,与点xixi的距离分布极不均衡。如果直接将这种距离关系保留到低维,肯定会出现拥挤问题。如何解决呢?这个时候就需要请出tt分布了。
神奇的长尾——t分布
刚才预备知识部分说到,像tt分布这样的长尾分布,在处理小样本和异常点时有着非常明显的优势,例如下面这个图:

从图中可以看到,在没有异常点时,tt分布与高斯分布的拟合结果基本一致。而在第二张图中,出现了部分异常点,由于高斯分布的尾部较低,对异常点比较敏感,为了照顾这些异常点,高斯分布的拟合结果偏离了大多数样本所在位置,方差也较大。相比之下,tt分布的尾部较高,对异常点不敏感,保证了其鲁棒性,因此其拟合结果更为合理,较好的捕获了数据的整体特征。 那么如何利用tt分布的长尾性来改进SNE呢?我们来看下面这张图,注意这个图并不准确,主要是为了说明tt分布是如何发挥作用的。
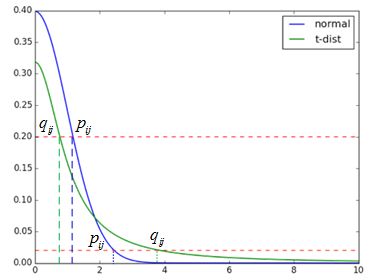
图中有高斯分布和tt分布两条曲线,表示点之间的相似性与距离的关系,高斯分布对应高维空间,tt分布对应低维空间。那么对于高维空间中相距较近的点,为了满足pij=qijpij=qij,低维空间中的距离需要稍小一点;而对于高维空间中相距较远的点,为了满足pij=qijpij=qij,低维空间中的距离需要更远。这恰好满足了我们的需求,即同一簇内的点(距离较近)聚合的更紧密,不同簇之间的点(距离较远)更加疏远。我们使用自由度为1的tt分布重新定义qijqij:
qij=(1+∥yi−yj∥2)−1∑k≠l(1+∥yk−yl∥2)−1qij=(1+‖yi−yj‖2)−1∑k≠l(1+‖yk−yl‖2)−1
依然用KL距离衡量两个分布之间的相似性,此时梯度变为
δCδyi=4∑j(pij−qij)(yi−yj)(1+∥yi−yj∥2)−1δCδyi=4∑j(pij−qij)(yi−yj)(1+‖yi−yj‖2)−1
再利用随机梯度下降算法训练即可。
这就是所谓的t-SNE算法,总结一下其实就是在SNE的基础上增加了两个改进:一是把SNE变为对称SNE,二是在低维空间中采用了tt分布代替原来的高斯分布,高维空间不变。最后来看看t-SNE在可视化效果上是如何完虐其他算法的。(ps:Maaten还是比较厚道的,没有在论文中展示SNE的可视化效果图,不然也是赤果果的打Hinton脸)

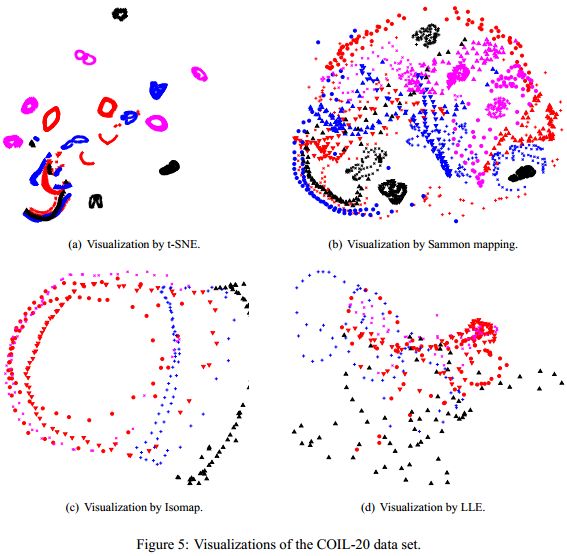
其他算法真是被虐的体无完肤……想看更多图的可以去看原文,这里再给大家展示一个t-SNE算法过程中的点簇之间距离变化的一个动画,使用的是经典的MNIST数据集。
0x04 t-SNE的改进——各种树算法轮番上阵
2014年的时候,Maaten又写了一篇论文对t-SNE算法进行了改进,使用了各种基于树的算法,具体包括两部分内容:一是采用了kNN图来表示高维空间中点的相似性;二是优化了梯度的求解过程,将梯度计算分为引力和斥力两部分,同样使用了一些优化技巧。下面我们简单看看这两项优化的基本思路,具体用到的树算法这里只是简单提一下,不作深入介绍了,感兴趣的同学直接到文末的参考资料中找对应的论文即可。
用kNN图表示高维空间中点的相似性
在t-SNE中,我们用高斯分布描述了高维空间中整体的距离分布关系,注意表达式是这样的一个形式:
pj|i=exp(−∥xi−xj∥2/2σ2i)∑k≠iexp(−∥xi−xk∥2/2σ2i)pj|i=exp(−‖xi−xj‖2/2σi2)∑k≠iexp(−‖xi−xk‖2/2σi2)
pi|i=0pi|i=0
pij=pj|i+pi|j2npij=pj|i+pi|j2n
对每一个数据点都包含∑k≠iexp(−|xi−xk|2/2σ2i)∑k≠iexp(−|xi−xk|2/2σi2)这样一项,当数据量较大时,计算量无疑是非常大的。但实际上,两个相距较远的点互为邻居的概率pijpij是非常小的,几乎可以忽略。因此,在高维空间对一个点构建距离相似性关系时,不必考虑图中的每一个节点,只需考虑与其相近的若干个节点即可。这里我们考虑与点xixi最近的⌊3u⌋⌊3u⌋个点,其中uu为点xixi的周围条件概率分布的perplexity,将这些点的集合表示为NiNi,可得到
pj|i=exp(−∥xi−xj∥2/2σ2i)∑k∈Niexp(−∥xi−xk∥2/2σ2i)pj|i=exp(−‖xi−xj‖2/2σi2)∑k∈Niexp(−‖xi−xk‖2/2σi2)
pi|i=0pi|i=0
pij=pj|i+pi|j2npij=pj|i+pi|j2n
这样就大大降低了计算量,但也引入了一个新的问题,我们必须先构建一个高维空间的kNN图。Maaten采用了VP树(vantage-point tree)来构建这个kNN图,可以在O(uNlogN)O(uNlogN)的时间复杂度内得到一个精确的kNN图。
梯度中斥力的近似
在介绍t-SNE梯度的物理意义时,提到可以将梯度视为所有点对yiyi的合力作用,这里我们利用这个特点对梯度进行变换,令Z=∑k≠l(1+|yk−yl|2)−1Z=∑k≠l(1+|yk−yl|2)−1
δCδyi=4∑j(pij−qij)(yi−yj)(1+∥yi−yj∥2)−1=4∑j(pij−qij)qijZ(yi−yj)δCδyi=4∑j(pij−qij)(yi−yj)(1+‖yi−yj‖2)−1=4∑j(pij−qij)qijZ(yi−yj)
δCδyi=4(Fattr+Frep)=4(∑j≠ipijqijZ(yi−yj)−∑j≠iq2ijZ(yi−yj))δCδyi=4(Fattr+Frep)=4(∑j≠ipijqijZ(yi−yj)−∑j≠iqij2Z(yi−yj))
可以看到,将梯度分解为引力和斥力两部分后,其中引力部分计算起来较为容易,因为qijZ=(1+|yi−yj|2)−1qijZ=(1+|yi−yj|2)−1,我们可以采用刚才的近似,只考虑最近邻的若干个节点,忽略较远的节点,时间复杂度为O(uN)O(uN)。但是计算斥力依然有较大的计算量,时间复杂度约为O(N2)O(N2)因为PP和QQ的分布是不一样的,不过我们依然可以使用一些优化技巧来简化这个计算。
看下面这个图,有三个点yi,yj,ykyi,yj,yk,当yi−yj≈yi−yk>>yj−ykyi−yj≈yi−yk>>yj−yk时,我们可以认为点yjyj和点ykyk对yiyi的斥力是近似相等的。

事实上,这种情况在低维空间中是很常见的,甚至某一片区域中每个点对yiyi的斥力均可用同一个值来近似。现在问题来了,任意给定一个点,我们需要一个方法快速搜索出符合条件的区域,并用刚才的优化方法计算出每块区域的总斥力。如下图所示:
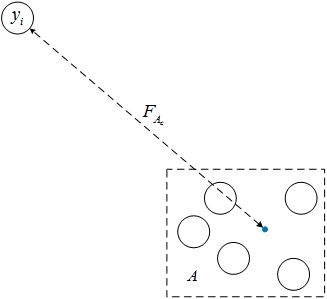
对上图的情形,假设区域AA中的5个点对yiyi产生的斥力都是近似相等的,那么我们可以计算这5个点的中心点(虚构的点)产生的斥力FAcFAc,区域AA产生的总斥力为5FAc5FAc。Maaten使用了四叉树来完成区域搜索任务,并用该区域中心点产生的斥力作为整个区域的代表值,当然,并非所有区域都满足这个近似条件,这里使用Barnes-Hut算法搜索并验证符合近似条件的点-区域对。
从点-区域到区域-区域
在上面的近似中,我们考虑的是一个点与一个区域之间斥力的近似,事实上,我们可以更进一步的优化,考虑一个区域与另一个区域之间斥力的近似。如下图这种情形,AA和BB两个区域之间任意两个节点产生的斥力均可用FABcFABc近似。
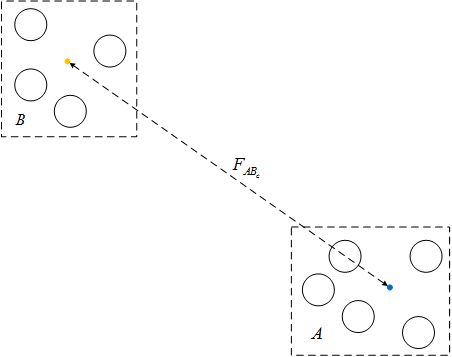
同样,也需要判断两个区域之间的斥力是否满足近似的条件,Maaten采用了Dual-tree算法搜索并验证符合近似条件的区域-区域对。
0x05 从t-SNE再到LargeVis——厚积薄发
虽然t-SNE算法和它的改进算法都得到广泛应用,但存在两个不足:一是处理大规模高维数据时,t-SNE的效率显著降低(包括改进后的算法);二是t-SNE中的参数对不同数据集较为敏感,我们辛辛苦苦的在一个数据集上调好了参数,得到了一个不错的可视化效果,却发现不能在另一个数据集上适用,还得花费大量时间寻找合适的参数。
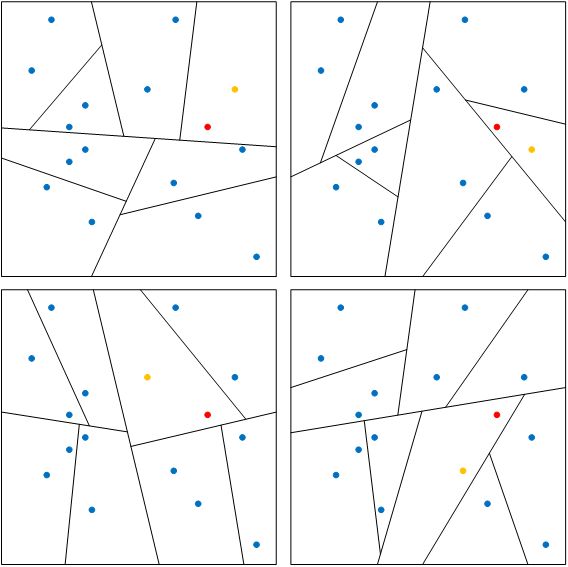
唐建提出的LargeVis基本思路与t-SNE改进算法大致相同,如下图所示:
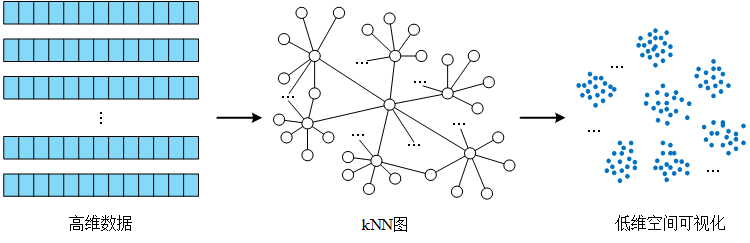
但是LargeVis用到了几个非常漂亮的优化技巧,包括他之前在LINE上的工作。我们分别来看看这些另人耳目一新的优化技术。
高效kNN图构建算法
在t-SNE的改进算法中,高维空间距离相似性我们只考虑与xixi最接近的若干个邻居点,这实质上就是一个构建kNN图的过程。Maaten使用了VP树来构建一个精确的kNN图,但是效率依然堪忧。而LargeVis采用了一种更巧妙的方式,不追求一步到位,先近似再提高准确率。
在预备知识部分我们说到,构建kNN图一般有三类方法,LargeVis的做法是将第一类方法和第三类方法相结合。具体来说,第一步先利用随机投影树得到一个空间划分,在此基础上寻找每个点的kk近邻,得到一个初步kNN图,这个kNN图不要求完全准确。第二步根据“邻居的邻居可能也是我的邻居”的思想,利用邻居搜索算法寻找潜在的邻居,计算邻居与当前点、邻居的邻居与当前点的距离并放入一个小根堆之中,取距离最小的k个节点作为k近邻,最终得到一个精确的kNN图。
低维空间可视化算法
在低维空间可视化过程中,t-SNE的思路是保证高维空间的距离分布P与低维空间的距离分布Q尽可能接近,用KL距离写出代价函数并求梯度。但是效率问题也很突出,不然Maaten也不会花那么大力气,利用各种树算法优化这个梯度求解的过程。
由于我本人是研究自然语言处理的,所以看到LargeVis在这一块的优化思路,联想到word2vec中类似的优化思路,很有一种拍案叫绝的感觉。这里我也重点从word2vec的角度进行阐释。
首先我们知道word2vec中用到了两个模型,CBOW和Skip-gram模型,此外还有众多优化技术,其中一个叫负采样,这个预备知识中强调过了,不记得的同学再回到文章开头看一下。那么在网络中其实也是相类似的,我们可以把当前中心点视为目标词,其邻居节点视为上下文窗口中出现的词,那么中心点和其邻居节点即构成一个正样本,而中心点与非邻居点构成一个负样本。
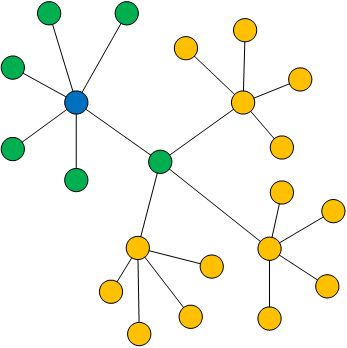
如上面展示的kNN图中的一小部分,若蓝点为中心点,则每个绿点可与蓝点构成正样本,而每个黄点与蓝点构成负样本。如何把这个kNN图中的结构关系映射到低维空间呢?直观来看,在低维空间应该是正样本中的节点对聚合在一起,而负样本中的节点对分散的较远。 我们先考虑无权值网络的情况,用yiyi和yjyj表示低维空间中的两个点,两个点在kNN图中有一条二元边eij=1eij=1(权值为1的边)的概率为:
P(eij=1)=f(∥yi−yj∥2)P(eij=1)=f(‖yi−yj‖2)
其中f(⋅)f(⋅)类似的用到了t-SNE里的tt分布,f(x)=11+x2f(x)=11+x2,若yiyi和yjyj之间的距离越小,两点在kNN图中有二元边的概率较大,反之若yiyi和yjyj之间的距离越大,则两点在kNN图中有二元边的概率越小。
LargeVis还考虑了有权值网络的情况,定义边权值为wijwij的概率为:
P(eij=wij)=P(eij=1)wijP(eij=wij)=P(eij=1)wij
现在我们假定正样本集合为EE,负样本集合为E¯E¯,正样本和负样本的集合都可以直接通过kNN图获得。优化目标可以写为:
O=∏(i,j)∈Ep(eij=1)wij∏(i,j)∈E¯(1−p(eij=1))γO=∏(i,j)∈Ep(eij=1)wij∏(i,j)∈E¯(1−p(eij=1))γ
整个优化目标很好理解,就是最大化正样本的节点对在kNN图中有连接边的概率,最小化负样本的节点对在kNN图中有连接边的概率,其中γγ是我们统一为负样本边设定的权值。这里再取一个对数,优化目标变为:
O=∑(i,j)∈Ewijp(eij=1)∑(i,j)∈E¯γ(1−p(eij=1))O=∑(i,j)∈Ewijp(eij=1)∑(i,j)∈E¯γ(1−p(eij=1))
那么是不是到这里又可以用梯度下降开始训练了呢?很遗憾,还是不行,这里我们使用的是所有负样本E¯E¯,计算量太大,是时候请出负采样算法了。对每一个点ii,我们根据一个噪声分布Pn(j)Pn(j)随机选取MM个点与ii构成负样本,这个噪声分布采用与Mikolov等人使用的噪声分布类似的形式,即Pn(j)∝d0.75jPn(j)∝dj0.75,其中djdj为点jj的度(这里用的是节点的度,word2vec用的是词的词频)。此时我们可重新定义目标函数:
O=∑(i,j)∈Ewij(p(eij=1)+∑k=1M Ejk∼Pn(j)γlog(1−p(eijk=1)))O=∑(i,j)∈Ewij(p(eij=1)+∑k=1M Ejk∼Pn(j)γlog(1−p(eijk=1)))
看这个目标函数,是不是和使用了负采样技术的Skip-gram模型的目标函数非常类似?我们再仔细观察上面的目标函数,求出梯度后,边权值wijwij仍是作为乘积的一项出现的,这就带来一个问题,网络中边的权值wijwij变化范围是很大的,所以受wijwij的影响,梯度的变化也会较大,这对训练是非常不利的,也就是所谓的梯度剧增与消失问题(gradient explosion and vanishing problem)。
到了这一步就可以用LINE里面的边采样技术了,其实原理和负采样是一致的,只不过用在了正样本中。若正样本中两个点之间边的权值为wijwij,我们可以将其转换为wijwij个重叠的二元边,就像下图这种形式,假如权值是5,就转换成5条二元边。

若存在多个较大的带权值边(上百甚至上千),转换成二元边之后,总边数也是非常多的,全部考虑的话同样影响效率。因此,这里将所有带权值边全部转换为二元边之后(相当于做了等距离分割),再随机从这些二元边中进行采样(相当于带权采样)。边采样算法的优势在于:一方面,由于采样到的边是二元边,因此权值都是一样的,解决了梯度变化范围大的问题;另一方面,采样过程实质遵循了带权采样策略,因为权值较大的边转换得到的二元边更多,被采样到的概率也就越大,保证了正确性与合理性。
利用负采样和边采样优化之后,LargeVis还用到了异步随机梯度下降来进行训练,这项技术在稀疏图上是非常有效的,因为不同线程采样的边所连接的两个节点很少有重复的,不同线程之间几乎不会产生冲突。从时间复杂度上来看,每一轮随机梯度下降的时间复杂度为O(sM)O(sM),其中MM是负样本个数,ss是低维空间的维数(2或3),随机梯度的步数通常又与点节数量NN成正比,因此总的时间复杂度为O(sMN)O(sMN)。从这里可以知道,LargeVis的时间复杂度是与网络中的节点数量呈线性关系的。
从可视化效果上看,LargeVis与t-SNE是差不多的,在某些数据集上略胜一筹,但是从训练时间上看,LargeVis比t-SNE高效太多。
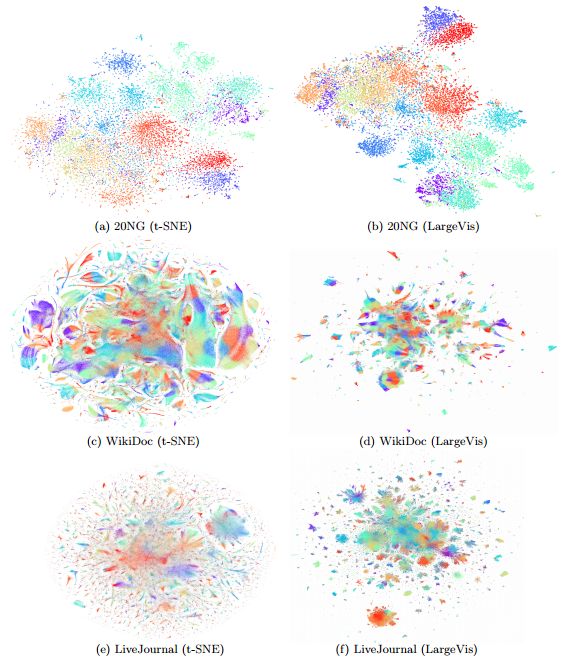
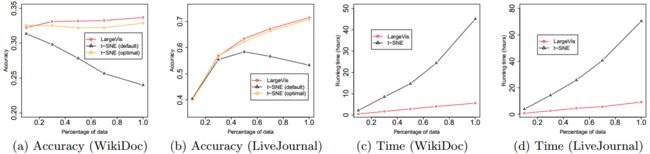
下面是准确率与时间的对比,LargeVis果然不是浪得虚名。
不过到目前为止,LargeVis的代码还没有放出来。还请大家多点耐心,拭目以待。
0x06 总结
从SNE到t-SNE再到LargeVis,SNE奠定了一个非常牢靠的基础,却遗留了一个棘手的拥挤问题;t-SNE用tt分布巧妙的解决了拥挤问题,并采用了多种树算法改进算法效率;LargeVis在t-SNE改进算法的基础上,参考了近年来较为新颖的优化技巧,如随机投影树、负采样、边采样(实质也是负采样)等,直接将训练的时间复杂度降至线性级。在表示学习和深度学习如此火热的年代,任何一种经典的模型或方法都有可能在其他领域发挥不可思议的妙用。word2vec中的Skip-gram模型和负采样优化技术在LargeVis中的应用就是很好的证明。
值得一提的是,Maaten提出t-SNE的时间是2008年,进一步改进t-SNE的时间是2014年,唐建提出LINE和LargeVis的时间分别是2015年和2016年。从这个角度看,t-SNE还是一个非常经典的算法,毕竟傲视群雄了这么多年……不过从另一个角度看,科研之路漫漫,一项值得称道的技术或改进不是一蹴而就的,是要经过长时间积累和沉淀的。
http://bindog.github.io/blog/2016/06/04/from-sne-to-tsne-to-largevis/