2009-2019年亚马逊畅销书50强数据集可视化分析-基于Pandas-Seaborn
Amazon Top 50 Bestselling Books 2009 - 2019
导入相关的包
import numpy as np
import pandas as pd
pd.plotting.register_matplotlib_converters()
import matplotlib.pyplot as plt
%matplotlib inline
import seaborn as sns
print("Setup Complete")
获取相关的数据
- Name:书名
- Author:作者
- User Rating:用户评分
- Reviews:用户评论数
- Price:书的价格
- Year:它在最畅销书中排名的年份
- Genre:小说还是非小说
# 获取原始数据
data_original = pd.read_csv("./bestsellers with categories.csv")
data_original

对全部书进行数据分析
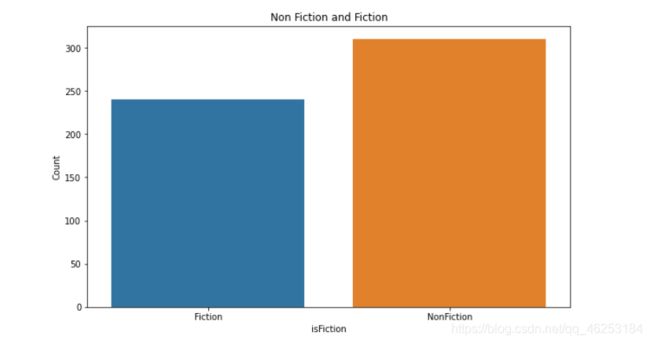
小说和非小说的数量
# 非小说的数量
AllNonFiction_count = data_original.loc[data_original.Genre == "Non Fiction"].Genre.count()
# 小说的数量
AllFiction_count = data_original.loc[data_original.Genre == "Fiction"].Genre.count()
# 转换成DataFrame对象
data = {'count':[AllFiction_count,AllNonFiction_count]}
data = pd.DataFrame(data=data, index=['Fiction','NonFiction'])
绘制条形图
由图像可以知道非小说占大部分
plt.figure(figsize=(10,6))
plt.title("Non Fiction and Fiction")
sns.barplot(x=data.index, y=data['count'])
plt.xlabel("isFiction")
plt.ylabel("Count")
获取评分最高的书和评分最低的书
查看所有书的评分,可以知道最高评分是4.9分,最低是3.3分
# 查看所有的评分
data = data_original['User Rating'].unique()
# 按从小到大排序
data.sort()
data
array([3.3, 3.6, 3.8, 3.9, 4. , 4.1, 4.2, 4.3, 4.4, 4.5, 4.6, 4.7, 4.8,
4.9])
rating_top = data_original.loc[data_original['User Rating']==4.9]
rating_top.head()

评分最低的书仅一本,为《The Casual Vacancy》
# 获取评分最低的书
rating_bottom = data_original.loc[data_original['User Rating']==3.3]
rating_bottom

对评分最高的书做处理分析
# 按年的升序排序
rating_top.sort_values('Year').head()

# 获取统计信息 有52本书
rating_top.count()

获取各项信息
- 小说和非小说的数量
- 每年的评分最高小说的数量
# 非小说的数量
NonFiction_count = rating_top.loc[rating_top.Genre == "Non Fiction"].Genre.count()
# 小说的数量
Fiction_count = rating_top.loc[rating_top.Genre == "Fiction"].Genre.count()
# 转换成DataFrame对象
data = {'count':[Fiction_count,NonFiction_count]}
data = pd.DataFrame(data=data, index=['Fiction','NonFiction'])
绘制条形图
由图像可知,评分最高的书籍中非小说只占小部分
plt.figure(figsize=(10,6))
plt.title("Non Fiction and Fiction")
sns.barplot(x=data.index, y=data['count'])
plt.xlabel("isFiction")
plt.ylabel("Count")

# 获取年
yeararray = rating_top.Year.unique()
# 获取每年的评分最高书籍的数量
count = []
index = []
for i in yeararray:
index.append(i)
count.append(rating_top.loc[rating_top.Year == i].Year.count())
# 生成dataFrame数组
year_topcount = {'count':count}
data = pd.DataFrame(data=year_topcount, index=index)
生成条形图和折现图
由下图可知,2019年评分最高的书最多,2011年最少
# 条形图
plt.figure(figsize=(10,6))
plt.title("Top Rating Book Count")
sns.barplot(x=data.index, y=data['count'])
plt.xlabel("Year")
plt.ylabel("Count")

# 折线图
plt.figure(figsize=(10,6))
sns.lineplot(data=data)
plt.xlabel("Year")
plt.ylabel("Count")
