目标检测学习笔记
目标检测学习笔记1.0(李沐)
2.

3.

目标检测学习笔记2.0(赵卫东)
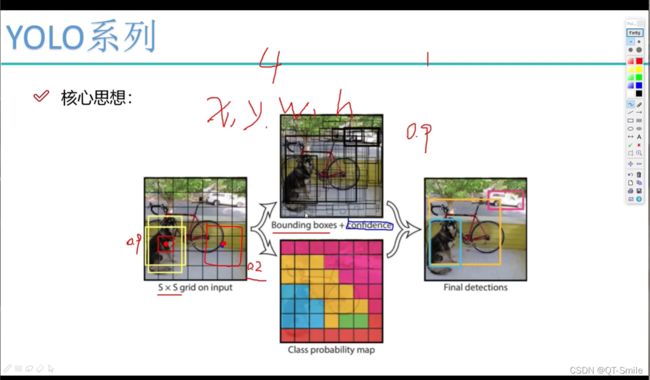
整张图作为输入
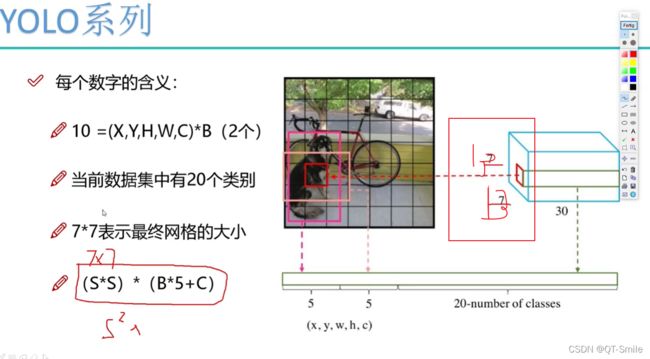
这儿的C是指整个数据集总共只有C类,但是我们只是对每个网格进行类别的预测,不单独对每一个边框进行类别的预测。


3.

目标检测学习笔记3.0(霹雳吧啦Wz)

2.

目标检测学习笔记4.0(人工智能-迪迦)
一、 YOLOV1

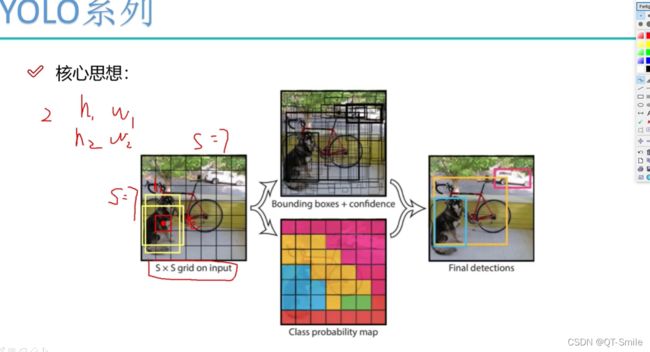
2.
3.
recall:你标记的物体是不是都检测到了多少

4.

精度和召回率的计算公式:

6.
置信度,被检测到的东西是一个物体的概率,下图是在进行人脸检测,所以此时的置信度就是检测到的东西是人脸的概率是多少。
而置信度阈值是程序员自己设置的,当你把阈值设置为0.8,那么置信度低于0.8的框都不会出现。就是是当机器检测出的物体的置信度低于0.8,我们程序员就认为被检测到的东西不是一个物体,拿下图举例,当下图中的置信度低于0.8,那么我们程序员就认为被检测到的区域不是一个人脸,就不再显示。只有大于阈值的框才会被显示出来。

7.
下图中,斜线的阴影面积的大小就被称作MAP值。

8.

9.
10.
我们对于狗有两个黄色的候选框,但是这两个黄色的候选框我们应该选哪个呢?
蓝色的是我们标记的框,通过计算IOU的值,我们知道长方形的候选框的IOU值更大,所以选择长方形的候选框,然后呢,毕竟我们长方形的候选框和蓝色的真实标记的候选框之间还是存在一定的差距,所以,我们还需要对黄色的框进行微调,那怎样微调呢?因为模型是不知道真实的蓝色框的形状的,所以这里需要既往长调,也要往宽调(这儿还要考虑一个置信度,对于置信度低的框,直接舍去了)。是不是可以通过增加长方形黄色框的长和宽,增加完之后,我们再去计算新的候选款和蓝色的框之间的IOU,就能知道下一步该选择哪一个候选框,以此类推。
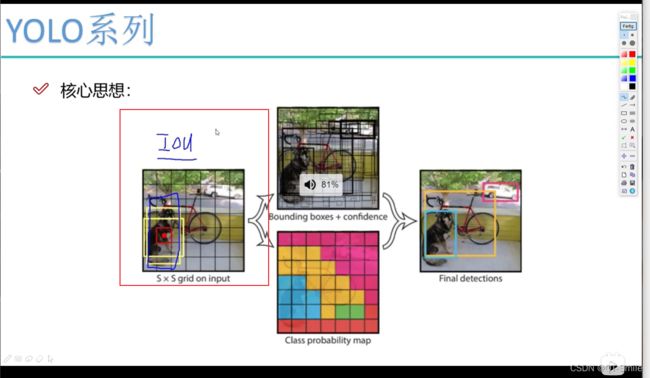
其实还要对每一个框做一个confidence,对于那些confidence值比较小的框就直接舍去不要。
11.
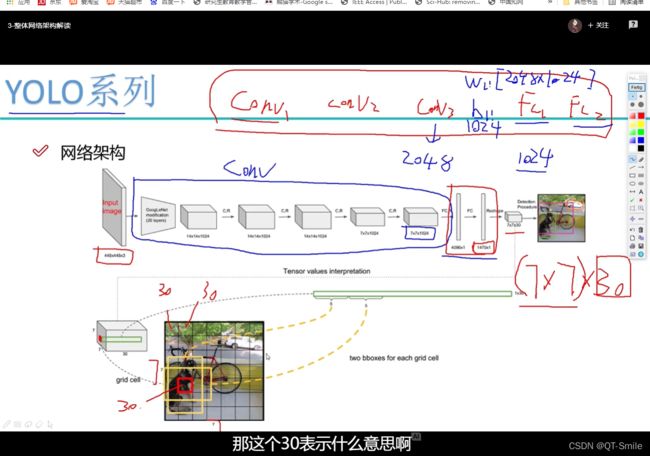
对于yolov1它的输入图片的大小是固定的,在使用是不能随意改变,

12…

15.
16.
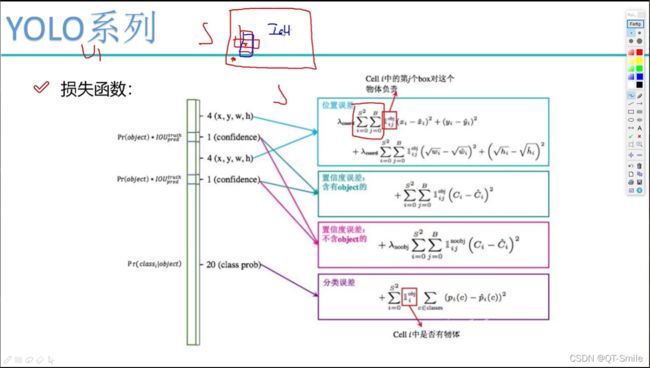
17.

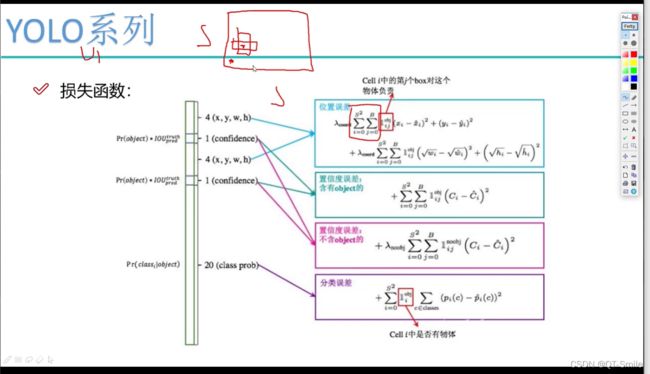
当wi比较小时,它比较敏感(斜率比较大),当wi比较大时,斜率比较小(不是很敏感)

下图框起来的是权重项,作用应该是衡量w,h 与x,y对于结果影响的程度的大小。

在一张图片中,有些是前景,有些背景,所以在讨论置信度误差时,要分开讨论,分为含有object的和不含object的。我们可以设置,前景的真实置信度为1,背景的真实置信度为0。
当某一个框和真实框之间的置信度是0.7(如下图中的黑色框,红色框是正式的目标框),但是框有很多,现在又有一个绿色的框,它和红色的框的置信度是0.6.我们设置置信度阈值是0.5.那么在这里由于有两个框都和真实框有重叠部分,我们在计算置信度误差时就只算置信度最高的0.7的黑色框,把绿色框舍去。
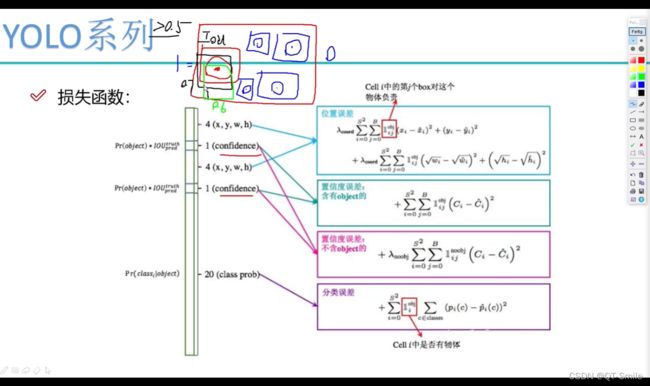
当置信度低于0.5的,我们在程序逻辑设计就已经认为这里不存在物体,所以置信度直接就设置为0。
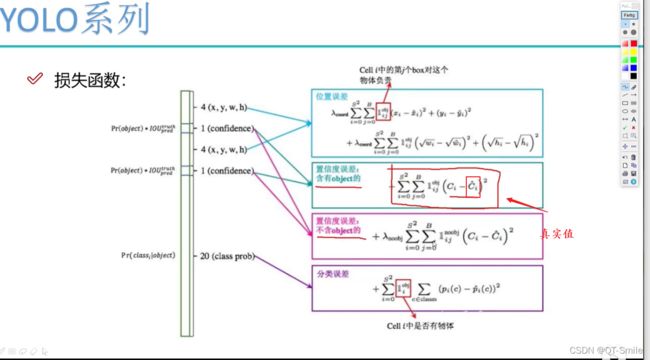
20.
之所以在下图红色框中加速权重,使用为在实际使用中,图片一般背景多,儿前景少,如果不加权重参数,那么损失函数很大程度被背景影响,那么这个损失函数最终实现的目的就是迫使网络模型去寻找背景,但是我们设计这个网络模型的目的是找物体,所以损失函数应该受前景的影响更大,所以这里需要设置一个权重参数。
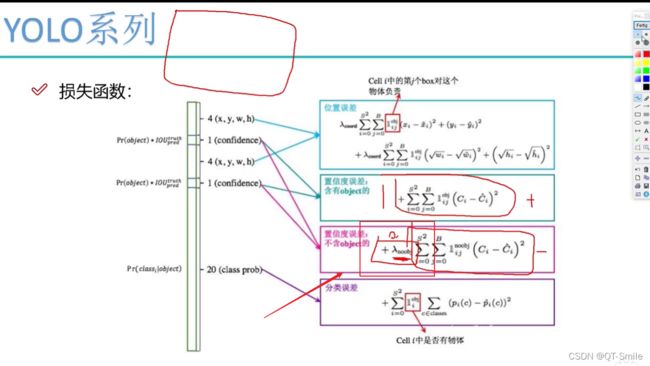
21.
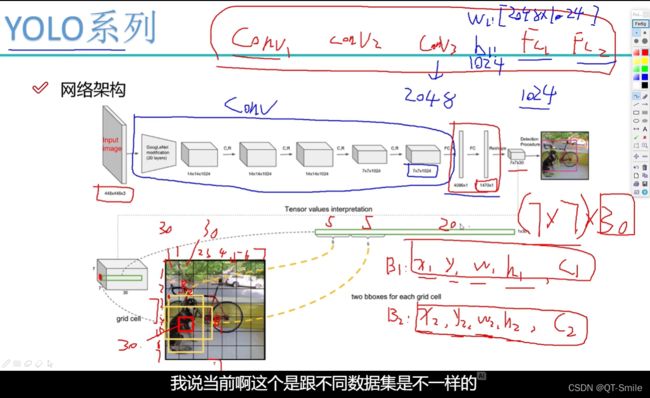
网络架构:

损失函数:

22.
yolo测试的时候,当你设置一个置信度阈值之后,大于置信度阈值的候选框可能会有很多个,但是由于它们检测到的都是同一个物体,所以我们对同一个物体的所有候选款置信度之间排序,选择置信度最大的候选框显示即可。

23.

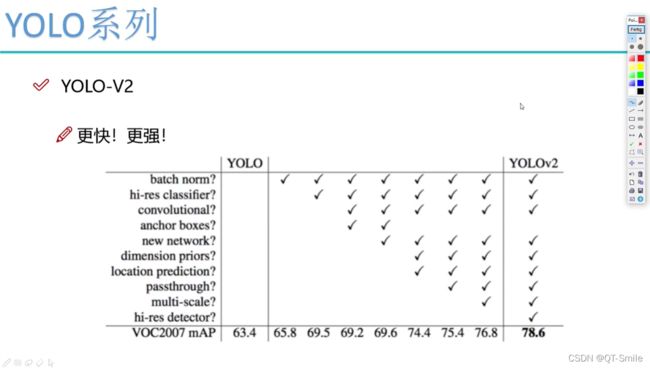
二、yolov2
yolov2中没有全连接层了
2.
每次卷积之后都加了batch normalization

3.

4.

5.
6.
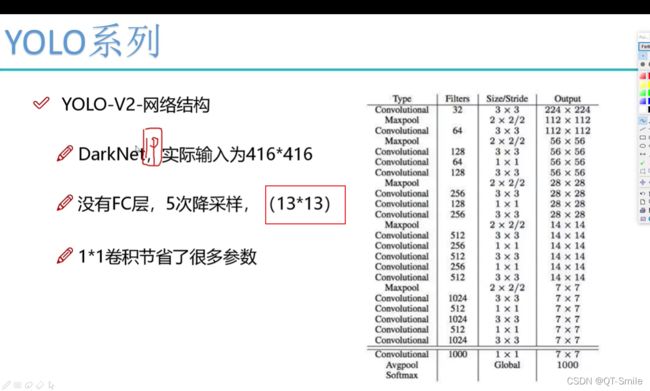
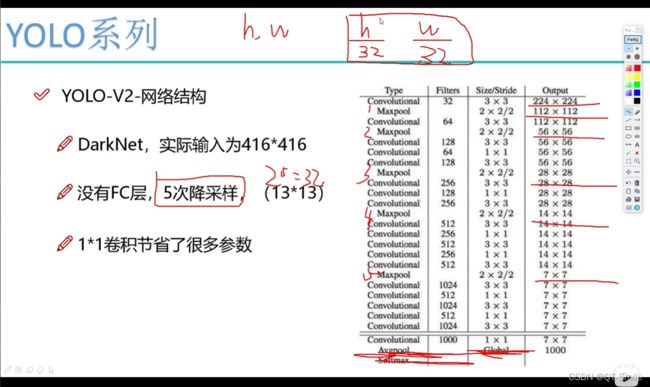
上图的1313,就是下面最后的把yolov1的77换成13*13,这样相同的一张图片yolov2得到的方框会更多,检测到的物体也会更多,也更加容易检测到小物体。
7.
8.
9.
10.
11.
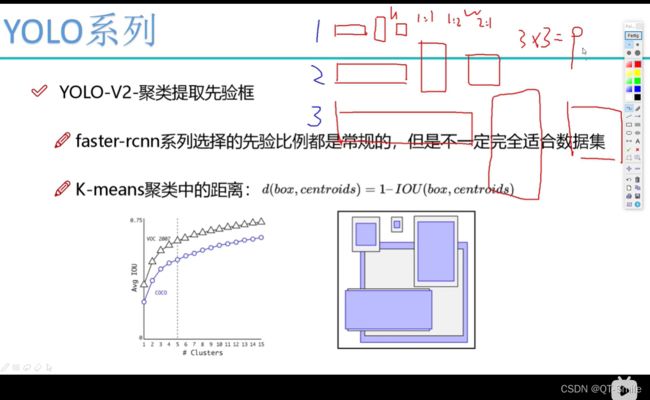
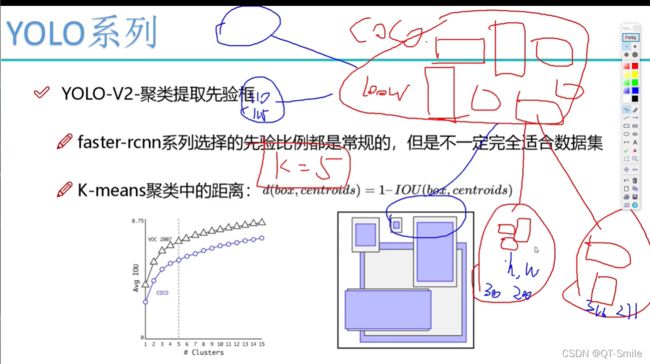
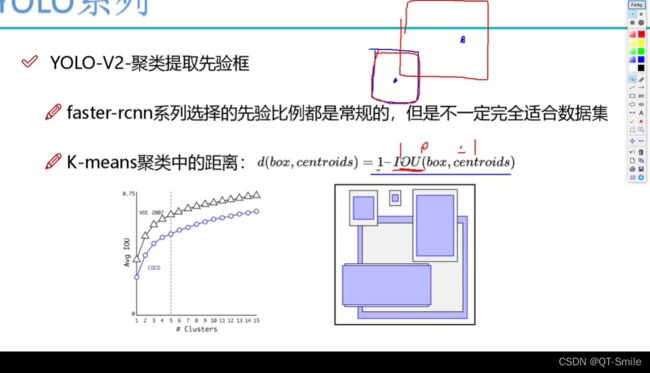
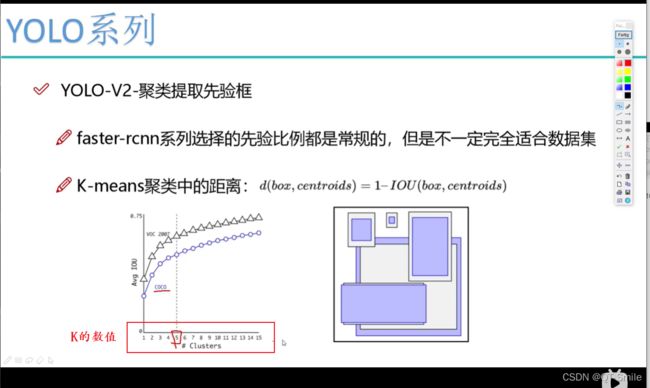
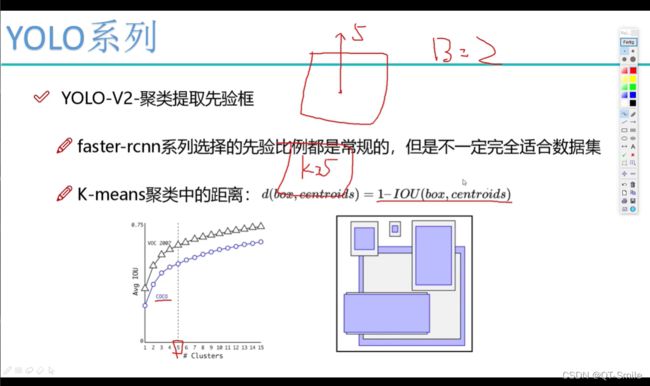
通过下面的实验就得出yolov2中一个框,会有5个候选款比较合适,并且通过聚类,聚类的k=5,所以每一个框有5个候选框,且每一个候选框的大小就是聚类的中心x,y。
12.
recall:;对于一张图中标记的物体,recall越高,表示模型能够检测到的物体越多。


下面这张图是在讲解yolov1的缺点。需要改进的地方。

15.

16.
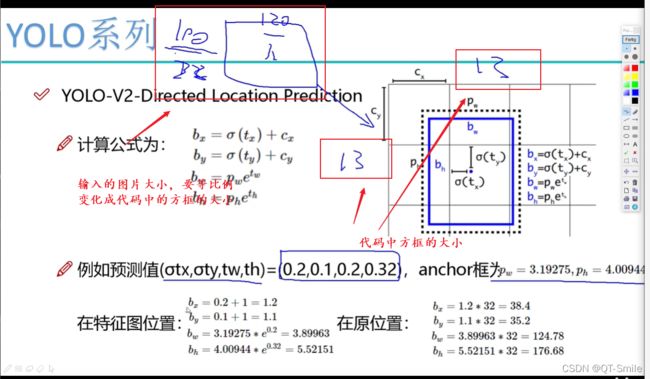
方框中的数值,是通过之前进行k聚类得到的宽和高的数值大小。

17.

18.
19.
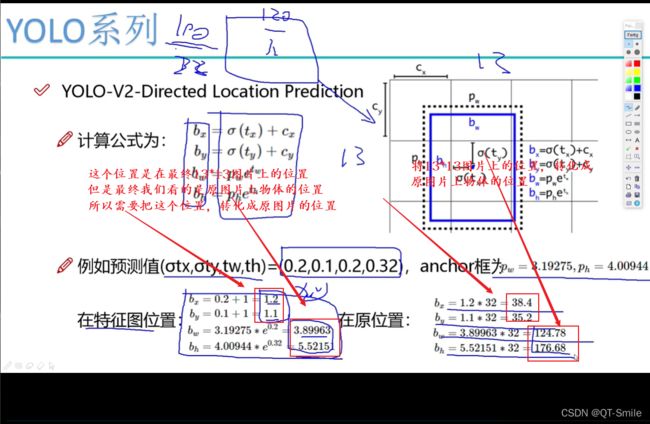
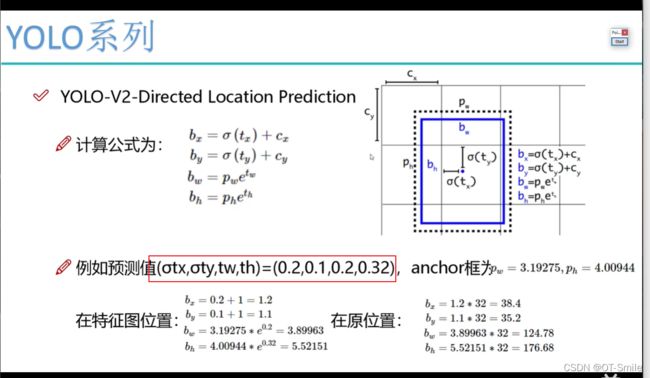
在yolov1中模型预测的直接的移动位置,而在yolov2中预测的是相对位置,且这个相对位置逃不出一个13*13中的小方框,也就是下面的红色方框中的值会在一个小方框中,不会出这个小方框
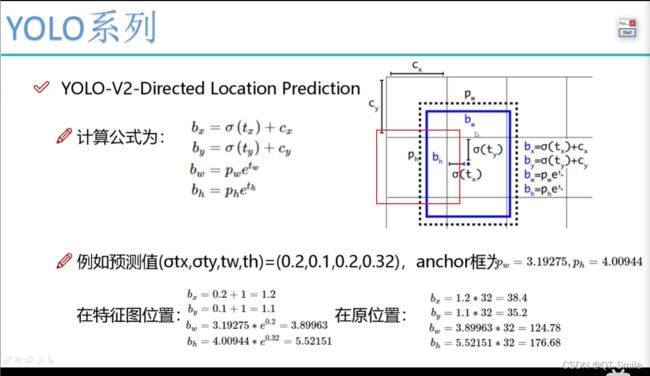
20.
21.

22.

23.
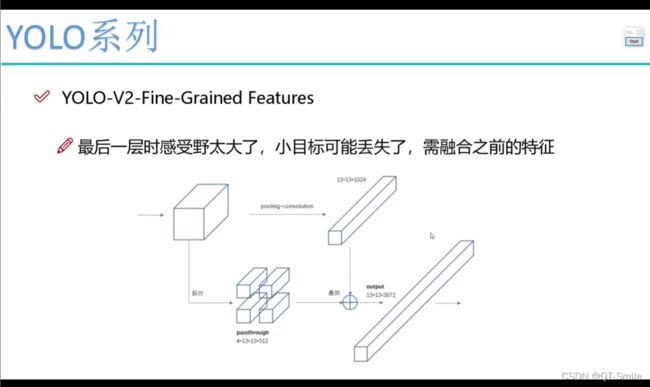
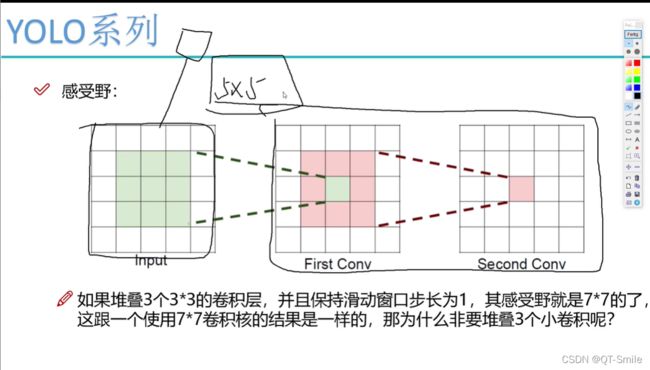
由于之间的感受野太大,导致一些小目标会被忽略,所以进行了改进,下面这个在上面的卷积后会得到大目标,而下面的残差结构会结合小目标,这样就即考虑了大目标也考虑了小目标。
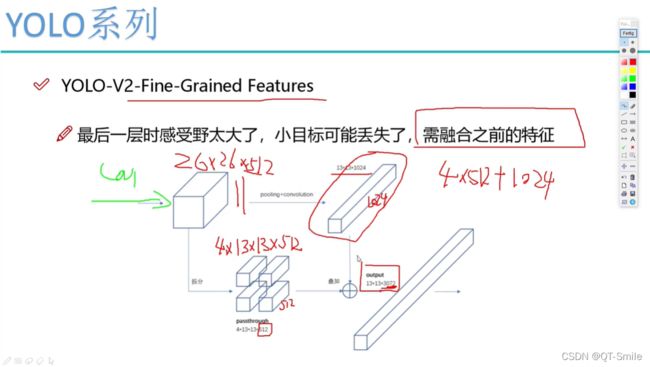
24.
由于实际应用中,输入图片的大小难以统一,并且统一的图片,可能对于结果的影响很大,所以对于yolov2就设置成输入的图片大小可以是不同的。

三、YOLOV3

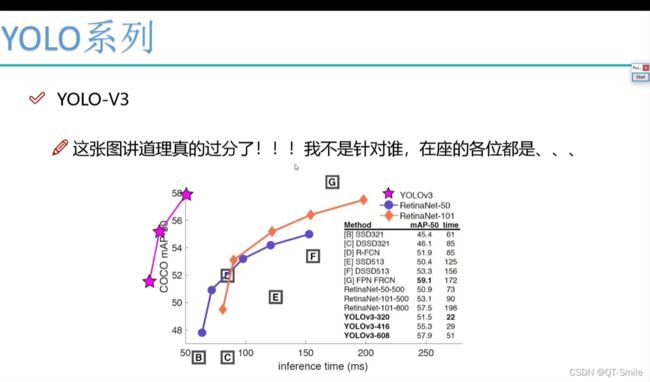
2.

3.
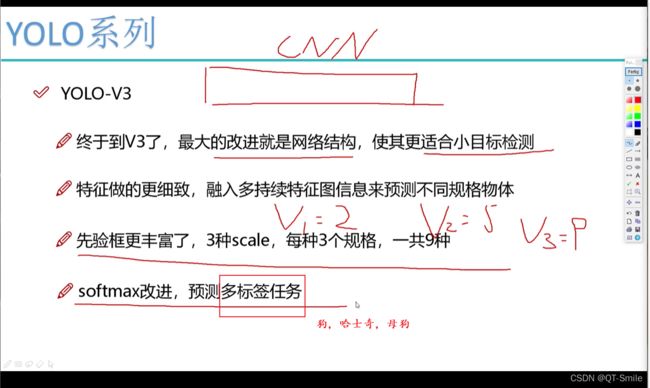
4.

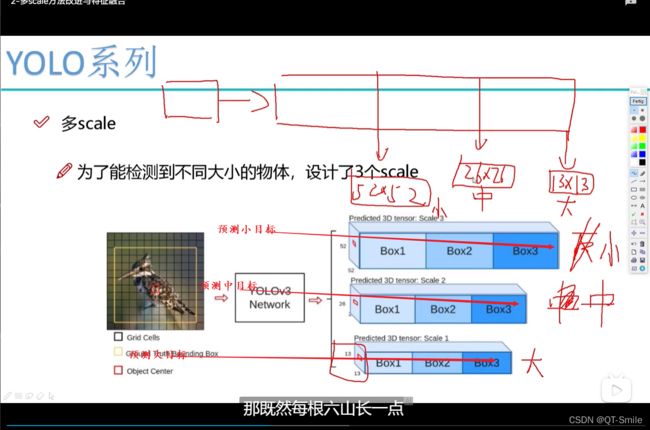
6.

7.
左边的图像金字塔,它需要把原始图片先resize成三种不同的尺寸,但是resize三种不同的尺寸,相当于要做三次,那么这样会让我们的模型的速度变得很慢,而在yolov中速度是第一位的,所以这是不被允许的。

YOLOV3网络模型取名叫做darknet-53

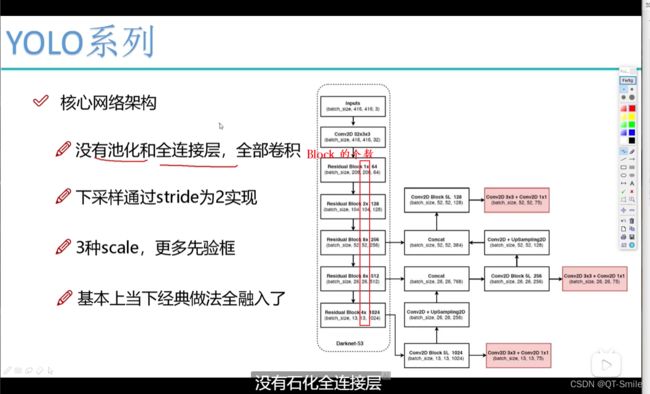
10.
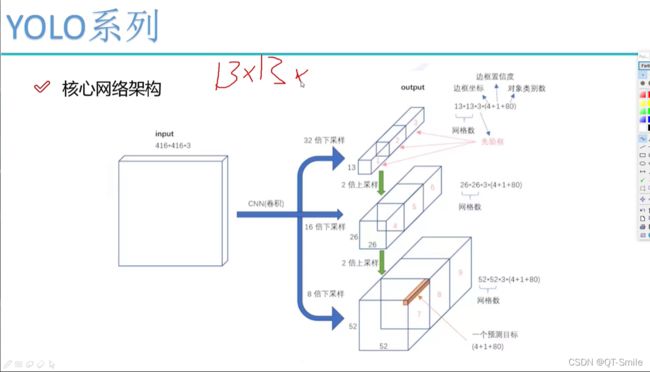
11.
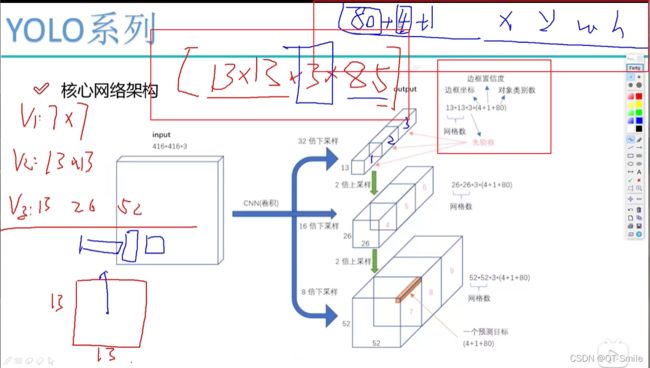

13.

14.
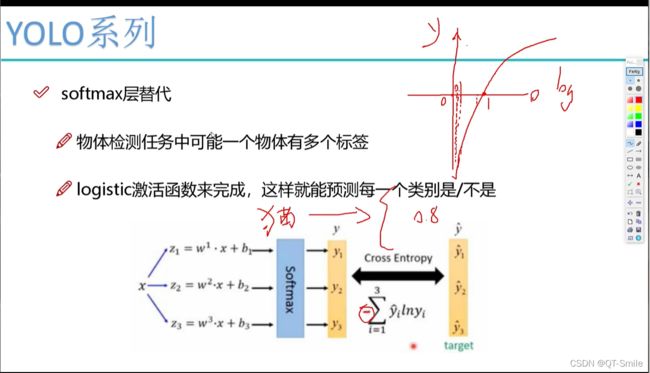
由于是多标签,这里最后使用的是二分类方法去实现。

15.