AutoML并非全能神器!新综述爆火,网友:了解深度学习领域现状必读
羿阁 萧箫 发自 凹非寺
量子位 | 公众号 QbitAI
如今深度学习模型开发已经非常成熟,进入大规模应用阶段。
然而,在设计模型时,不可避免地会经历迭代这一过程,它也正是造成模型设计复杂、成本巨高的核心原因,此前通常由经验丰富的工程师来完成。

之所以迭代过程如此“烧金”,是因为在这一过程中,面临大量的开放性问题 (open problems)。
这些开放性问题究竟会出现在哪些地方?又要如何解决、能否并行化解决?
现在一篇论文综述终于对此做出介绍,发出后立刻在网上爆火。
作者严谨地参考了接近300篇文献,对大量应用深度学习中的开放问题进行分析,力求让读者一文了解该领域最新趋势。

网友们纷纷在评论区留言“码住”、“了解深度学习领域现状必读”。

一起来看看内容。
这篇论文要研究什么?
众所周知,当我们拿到一个机器学习问题时,通常处理的流程分为以下几步:收集数据、编写模型、训练模型、评估模型、迭代、测试、产品化。
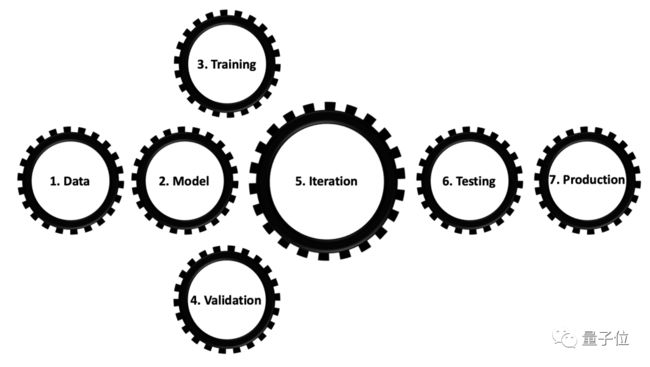
在这篇论文中,作者把上述这些流程比作一个双层次的最佳化问题。
内层优化回路需要最小化衡量模型效果评估的损失函数,背后是为了寻求最佳模型参数而进行的深入研究的训练过程。
而外层优化回路的研究较少,包括最大化一个适当选择的性能指标来评估验证数据,这正是我们所说的“迭代过程”,也就是追求最优模型超参数的过程。
论文中用数学符号表示如下:
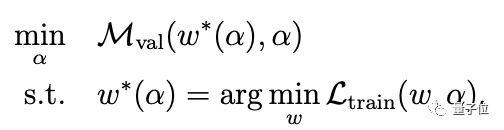
其中,Mval表示一个性能指标,如精度,平均精度等。Ltrain表示损失函数,w表示模型参数。
这样一来,仅用一个清晰统一的数学公式就能解释迭代的步骤。
不过,值得注意的是,面对不同的问题,它的解也需要特定分析,有时候情况甚至会非常复杂。
例如,评估度量Mval是一个离散且不可微的函数。它并未被很好地定义,有时候甚至在某些自我监督式和非监督式学习以及生成模型问题中不存在。
同时,你也可能设计了一个非常好的损失函数Ltrain,结果发现它是离散或不可微的,这种情况下它会变得非常棘手,需要用特定方法加以解决。
因此,本篇论文的研究重点就是迭代过程中遇到的各种开放性问题,以及这些问题中可以并行解决优化的部分案例。
开放性问题,不能那么轻易地只用一个简单的“是”、“不是”或者其他一个简单的词或数字来回答的问题。
机器学习中开放问题有哪些?
论文将开放性问题类型分为监督学习和其他方法两大类。
值得一提的是,无论是监督学习还是其他方法,作者都贴心地附上了对应的教程地址:

如果对概念本身还不了解的话,点击就能直接学到他教授的视频课程,不用担心有困惑的地方。
首先来看看监督学习。
这里我们不得不提到AutoML。作为一种用来降低开发过程中迭代复杂度的“偷懒”方法,它目前在机器学习中已经应用广泛了。
通常来说,AutoML更侧重于在监督学习方法中的应用,尤其是图像分类问题。
毕竟图像分类可以明确采用精度作为评估指标,使用AutoML非常方便。
但如果同时考虑多个因素,尤其是包括计算效率在内,这些方法是否还能进一步被优化?
在这种情况下,如何提升性能就成为了一类开放性问题,具体又分为以下几类:
大模型、小模型、模型鲁棒性、可解释AI、迁移学习、语义分割、超分辨率&降噪&着色、姿态估计、光流&深度估计、目标检测、人脸识别&检测、视频&3D模型等。
这些不同的领域也面临不同的开放性问题。
例如大模型中的学习率并非常数、而是函数,会成为开放问题之一,相比之下小模型却更考虑性能和内存(或计算效率)的权衡这种开放性问题。
其中,小模型通常会应用到物联网、智能手机这种小型设备中,相比大模型需求算力更低。
又例如对于目标检测这样的模型而言,如何优化不同目标之间检测的准确度,同样是一种复杂的开放性问题。
在这些开放性问题中,有不少可以通过并行方式解决。如在迁移学习中,迭代时学习到的特征会对下游任务可泛化性和可迁移性同时产生什么影响,就是一个可以并行研究的过程。
同时,并行处理开放性问题面临的难度也不一样。
例如基于3D点云数据同时施行目标识别、检测和语义分割,比基于2D图像的目标识别、检测和分割任务更具挑战性。
再来看看监督学习以外的其他方法,具体又分为这几类:
自然语言处理(NLP)、多模态学习、生成网络、域适应、少样本学习、半监督&自监督学习、语音模型、强化学习、物理知识学习等。
以自然语言处理为例,其中的多任务学习会给模型带来新的开放性问题。
像经典的BERT模型,本身不具备翻译能力,因此为了同时提升多种下游任务性能指标,研究者们需要权衡各种目标函数之间的结果。
又如生成模型中的CGAN(条件GAN),其中像图像到图像翻译问题,即将一张图片转换为另一张图片的过程。
这一过程要求将多个独立损失函数进行加权组合,并让总损失函数最小化,就又是一个开放性问题。
其他不同的问题和模型,也分别都会在特定应用上遇到不同类型的开放性问题,因此具体问题依旧得具体分析。
经过对各类机器学习领域进行分析后,作者得出了自己的一些看法。
一方面,AI表面上是一种“自动化”的过程,从大量数据中产生自己的理解,然而这其中其实涉及大量的人为操作,有不少甚至是重复行为,这被称之为“迭代过程”。
另一方面,这些工作虽然能部分通过AutoML精简,然而AutoML目前只在图像分类中有较好的表现,并不意味着它在其他领域任务中会取得成功。
总而言之,应用深度学习中的开放性问题,依旧比许多人想象得要更为复杂。
作者介绍
本篇论文的作者为Maziar Raissi,目前在科罗拉多大学博德分校应用数学系担任助理教授。
Raissi在马里兰大学帕克分校获得了应用数学和统计学博士学位,并在布朗大学应用数学系完成了博士后研究,有过在英伟达做高级软件工程师的工作经历。

研究方向是概率机器学习、深度学习和数据驱动的科学计算的交叉点,以及大数据分析、经济学和金融学等等。
论文的链接如下,感兴趣的小伙伴们可以自取~
论文地址:
https://arxiv.org/abs/2301.11316