【论文/视频学习】Attention Is All You Need
Transformer 原论文。学习于Transformer论文逐段精读【论文精读】_哔哩哔哩_bilibili。
摘要
主流的序列转换模型(例如机器翻译)主要依赖于复杂的CNN或RNN,网络架构有encoder 和 decoder,并且有着注意力机制。
Transformer是一个简单的模型,只依赖注意力机制。
这个模型在机器翻译上的效果很好。
结论
Transformer不同于其他模型的点是,它把被广泛运用在encoder-decoder结构上的循环层(recurrent layer)换成了多头自注意力机制。
他们觉得transformer能够在其他领域和任务上应用得很好。
导言
在序列模型中,主流的模型是RNN中的 long short-term memory(LSTM) 和 gated recurrent (GRU)。在这其中,有两个主流的模型,语言模型和编码器-解码器的架构,这个架构通常被用于输出的结构化信息比较多的时候。
在RNN中,它是一个词接着一个词的输出,它们生成当前词的隐藏状态,是根据当前词的输入和前一个词的隐藏状态,这使得它能够时序化地生成。
问题在于,这样一个时序化的过程无法并行,计算性能就会比较差;另外,在生成后面的词的隐藏状态时,前面的词的隐藏状态可能会丢掉,如果不想丢掉,可能需要做一个比较大的隐藏状态,这加剧了内存开销。虽然有着很多的研究与改进,但没有解决这些问题。
Transformer纯基于注意力机制,因此可以并行,计算性能更高。
相关工作
已经发表的很多工作意图用卷积神经网络代替循环神经网络,但是卷积神经网络很难对一个长序列建模,因为卷积每一次都只看一个很小的窗口,如果想要同时看到很远的两个位置,需要很深的卷积层才能实现。如果使用Transformer就能够很轻易的同时看到。卷积神经网络的一个优势在于它可以有很多的输出通道,每一个输出通道都可以识别一个模式,Transformer的多头注意力机制可以模仿这个效果。
自注意机制在前人的工作中就已经提出。但transformer是第一个只基于注意力机制的编码器-解码器模型
模型
编码器会将序列输入 ( x 1 , … , x n ) (x_1,\dots,x_n) (x1,…,xn) (每一个 x i x_i xi代表一个词)转换为序列 z = ( z 1 , … , z n ) z=(z_1,\dots, z_n) z=(z1,…,zn) (每一个 z i z_i zi是对 x i x_i xi的向量表示)
解码器拿到 z z z后,会输出序列 ( y 1 , … , y m ) (y_1,\dots,y_m) (y1,…,ym),注意输出序列的长度与编码器的输出长度可能不一致,而且这个输出只能一个一个生成,这是一个auto-regressive(自回归)的过程,即过去时刻的输出,也会作为当前输出的输入。
Transformer也是编码器-解码器的架构,结构如下:

模型左边是编码器,右边是解码器。解码器的输入端其实是以前时刻的输出,所以名为Outputs, shifted right意为解码器输出和输入都是一个一个向右移的
编码器和解码器
编码器
它用了N=6的六个块(原文中称为layer),每一层中有两个子层,多头自注意力机制和position-wise fully connected feed-forward network,后面这个网络其实就是MLP。每一子层再作残差链接,并作layer normalization,即 L a y e r N o r m ( x + S u b l a y e r ( x ) ) LayerNorm(x+Sublayer(x)) LayerNorm(x+Sublayer(x))。由于残差连接要求向量长度一样,因此它让每一个子层的输出维度都是 d m o d e l = 512 d_{model}=512 dmodel=512
(这个简单设计使得Transformer相比于CNN等模型具有更少的超参数,它一般只调整上述的两个超参数)
batch normalization vs. Layer nomalization
考虑一个二维输入的情况,x是一个batch,shape(x)=m,n,每一行代表一个样本,每一列代表一个特征。batch norm把每一个特征在一个mini-batch里作标准化,即把每一列的均值变为0,方差变为1。而作预测时会将全局的均值和方差记录下来
同样一个二维输入,layer norm对每一行作标准化,不需要记录全局的均值和方差
transformer里的输入一般是三维的(batch, 序列,向量),此时列表示的是序列的长度。
在时序模型里,样本的长度可能不一致,如果样本的长度变化较大,由于batch norm时按照特征维度作标准化,batch norm算出来的均值和方差抖动会比较大;而layer norm由于是对每一个样本作标准化,因此没有这样的问题

解码器
N=6的层构成,但相比于编码器里的层,解码器里多了一个子层。注意力机制的特点是,它能够一次性地看到完整的输入,但是序列生成模型,在逻辑上来所,生成当前时刻的输出时不应该看到之后的输出。为了实现这个效果,解码器使用了一个带掩码的多头注意力机制(Masked multi-head attention)
Scaled Dot-Product Attention
Transformer的self-attention的相似函数是最常见的dot-product。
它的query,key的维度都等于 d k d_k dk,value维度是 d v d_v dv,输出是value的加权和所以和value等长。
它计算attention score(权重)的公式如下 A t t e n t i o n ( Q , K , V ) = s o f t m a x ( Q K T d k ) V Attention(Q,K,V) = softmax(\frac{QK^T}{\sqrt d_k})V Attention(Q,K,V)=softmax(dkQKT)V
Q,K,V是query,key,value分别组成的矩阵
它的这个方法和常见的dot-product注意力机制相比,多了一个scaled的步骤,即除以 d k \sqrt d_k dk。 d k d_k dk很大的时候,即两个向量很长的时候,就会导致它们的运算结果在经过softmax后很接近1,而其它的权重更接近于0,此时计算梯度,会发现梯度比较小,模型训练速度很慢。由于该模型的 d k = 512 d_k=512 dk=512比较大,所以做一个scale.
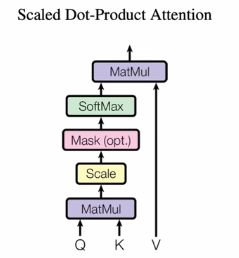
Masked
注意力机制会看到所有的输入,而masked只想要当前时刻和以前时刻的输入,因此在计算权重的时候不使用后面的值即可。
具体实现方法是,在 Q K T d k \frac{QK^T}{\sqrt d_k} dkQKT之后,对于以后时刻的输出值,将它们替换成一个很大的负数(例如-e10),经过softmax后,对应的权重值会变成0
Multi-Head Attention
将整个query, key, value通过投影降维 h 次,然后做h次的注意力函数,将所有函数的输出并在一起,再投影回来得到最终的输出
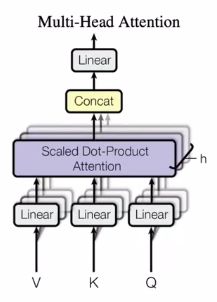
Q,K,V经过线性层降维
scaled dot-product attentino没有什么可以学习的参数,很难学习到识别不同模式的方法
而muti-head attention,线性层的w是可以学习的,也就是说,有h次机会让多头注意力在投影到的那个度量空间中学习到匹配不同模式的函数
它学习的公式如下:
M u l t i H e a d ( Q , K , V ) = C o n c a t ( h e a d 1 , … , h e a d h ) W o w h e r e h e a d i = A t t e n t i o n ( Q W i Q , K W i K , V W i V ) \begin{align} MultiHead(Q,K,V) = Concat(head_1, \dots,head_h)W^o\\ where\ head_i = Attention(QW^Q_i,KW^K_i,VW^V_i) \end{align} MultiHead(Q,K,V)=Concat(head1,…,headh)Wowhere headi=Attention(QWiQ,KWiK,VWiV)
原文实现中,h=8,投影之后的维度 d k = d v = d m o d e l / h = 64 d_k=d_v=d_{model}/h=64 dk=dv=dmodel/h=64.
Applications of Attention in Transformer
编码器的输入是n x d的向量,
注意力层的输入有三个,分别是key, query, value,输出可见上述公式
解码器的输出是 n x d的向量
解码器的掩码注意力层如前文所述,它的输出是 m x d的向量
另一个注意力层比较特殊,它的key和value来自于编码器的输出,query来自于解码器的下面的注意力层的输出。也就是说,这一层是把编码器里的输出中有用的信息拎出来,实现了编码器与解码器间的信息传递
Position-wise Feed Forward Networks
它就是一个MLP,特点是它把MLP对每一个词作用一次,对每一个词起作用的是同一个MLP
F F N ( x ) = m a x ( 0 , x W 1 + b 1 ) W 2 + b 2 FFN(x) = max(0,xW_1+b_1)W_2+b_2 FFN(x)=max(0,xW1+b1)W2+b2
x的维度是512,w1会把维度变回2048,w2把维度变回512
Attention vs. RNN 传递序列信息
考虑最简单的情况,没有残差连接,单头attention,解码器的结构如下:

attention的作用就是把整个序列中的信息抓取出来,得到的每一个输出都有它想要的信息,因此可以用MLP单独将每一个输出映射到对应的语义空间中的向量
作为对比考虑RNN的情况,第一层是MLP,将前一个输入经过mlp得到的输出作为当前mlp的输入,如下:

Embedding and Softmax
embedding就是说对于每一个词,希望学习到一个向量去表示它
两个embedding层的权重以及最后一个线性层的权重是一样的,但最后embedding的权重会乘上一个 d m o d e l \sqrt{d_{model}} dmodel ,因为一般学到的权重会做L2 norm,如果维度较大,权重值就会很小。乘上一个常数之后,在与positional encoding相加时两个的scale大小差不多
Positional Encoding
attention没有时序信息,它不会注意单词的位置,也就是说对于同一个序列,任意打乱之后再经过attention,得到的结果的顺序会变,但是值是一样的,因此要加入时序信息
positional encoding会在输入中加入时序信息,公式是sin,cos的复合函数,会生成维度与输入一致为512的,值在[-1,+1] 抖动的向量,最后加上embedding层的输出
Why self-attention
比较了自注意力、循环曾、卷积层、构造出来的受限的自注意力的性能表现
第二列表示并行度,第三列表示得到两个点之间的关系需要的计算量

循环层和自注意力的时间复杂度是差不多的,由于是时序性地,因此序列操作是O(n),同样,传递信息也是时序性的
卷积的时间复杂度和循环层差不多,一次卷积就能完成,每一次检查信息是通过一个宽度为k的窗口看,如果两个点不在同一个窗口内,就要多层才能看到两个点的信息,因此是 O ( l o g k ( n ) ) O(log_k(n)) O(logk(n))
受限的自注意力,query只跟r个邻居去计算
由上表的比较可知,self-attention的性能看起来更好
但在实际中,由于self-attention对模型的假设做得更少,因此要用更大的模型和更多的数据才能训练出来和CNN和RNN同样的效果,所以基于Transformer的模型一般都很贵
Traning
暂时不需要了解训练细节