ACL21 - Making Pre-trained Language Models Better Few-shot Learners
Gao T, Fisch A, Chen D. Making pre-trained language models better few-shot learners[J]. ACL 2021.
Github:https://github.com/princeton-nlp/LM-BFF
摘要
GPT3效果很好,但是太大了,不实用。
受启发于GPT3 使用 prompt 做 Few-shot 任务表现不错,本文提出 LM-BFF 模型,能更好的 微调 few-shot 语言模型。模型包括:
- 能够自动生成 prompt 的基于 prompt 和 fine-tuning 的 pipeline 方法
- 一种改进策略,能动态地和可选择性地将演示合并到上下文中
和之前任务不太一样的是,本文可以自动生成 prompt ,并将 prompt 应用到微调中。
介绍
更实用的场景假设:
- 用一些适度的模型 BERT 或者 RoBERTa
- 数据量少
基于 prompt 的预测将下游任务当成 masked language modeling 问题处理,设计合适的 prompt 需要领域专家出手,因此本文将手工设计的 prompt 当作次优选择,最好是能自动生成 prompt。
本文提出的自动生成 prompt 包括:优化的暴力搜索最佳工作词,和拥有新的解码目标能自动生成 prompt的 generative T5 模型。方法都是基于小样本的。
在给定少量的训练样本的情况下,实验证明:
- 基于prompt的方法进行微调比直接微调的效果好很多
- 自动生成的 prompt 不输手工 prompt
- 合并示范(incorporating demonstrations)在微调的时候有效,能够增强 few-shot 表现
相关工作
之前的方法有要么不是自动生成 prompt,要么生成的 prompt 比不过手工 prompt。本文提出的 自动生成 prompt 效果不输于手工 prompt。
还有一部分工作关注于更好的微调语言模型,主要是提出更好的优化技术和正则化技术。本文使用的是标准优化技术,将精力集中在 few-shot 的 prompt 和微调。
Prompt-based Fine-tuning
在标准的微调方案中,通常输入句子为 [CLS]sentence1[SEP]或者成对的句子 [CLS]sentence1[SEP]sentence2[SEP],然后在[CLS]部分添加一个额外的分类器(线性层+softmax)。这种方法会引入新的参数,且在训练过程中会导致局部最优。
一种缓解的方法是,采用prompt-based fine-tuning,将下游任务视为一种mask language model的auto-completion任务。例如输入的句子是:
x prompt = [ C L S ] x 1 It was [ M A S K ] ⋅ [ S E P ] x_{\text {prompt }}=[C L S] x_{1} \text { It was }[M A S K] \cdot[S E P] xprompt =[CLS]x1 It was [MASK]⋅[SEP]
其中 x 1 x_1 x1 表示输入的句子,后面的 It was [MASK]则表示一个prompt(提示模板),其中[MASK]部分则为一个标签词,其作为当前句子所属类的标签的代替词,(例如对于电影评论类任务(二分类),其包含positive和negative,则可以分别使用great和terrible两个词作为两个类的标签词)。
当作为分类任务时:

我们可以发现,其将分类问题完全的转化为mask language model。原始是给定一个输入句子,其属于对应某个类的概率。而转化后的问题,即给定一个输入句子 x i n x_{in} xin 时,其提示prompt中[MASK]为对应标签 y 的标签词 M ( y ) M(y) M(y) 时的概率。其中预测 y 的概率转化为预测其映射的标签词 M ( y ) M(y) M(y) 的概率。
作者发现,生成不同的模板或不同的标签词,都会对预测的结果产生很大的影响,如图所示:
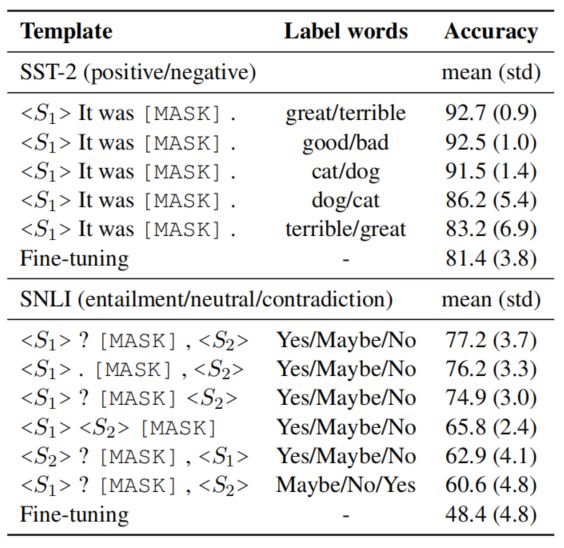
例如。对于同一个标签词,如果prompt的模板不同(删除某一个标点符号),会产生较大的影响;或者当选择不同的标签词时,对预测的结果也会产生影响。作者归结于这是人工设计模板和标签词的缺陷。因此作者提出一种自动创建模板的方法。
Automatic Prompt Generation
自动选择label words
通过验证集的方法,对所有候选的标签词进行验证,挑选输出概率最高的:
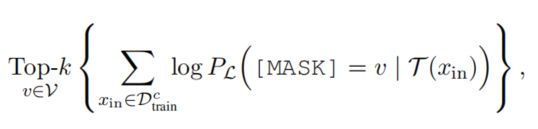
自动生成模板
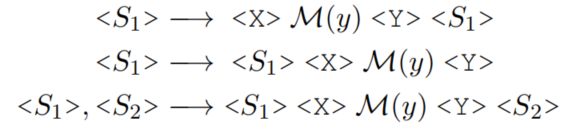
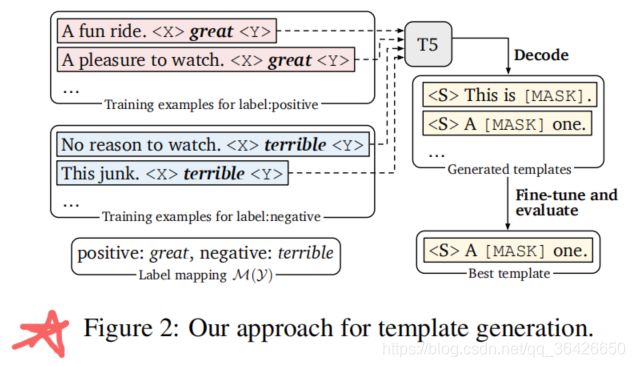
模板生成方法步骤(如下图所示):
(1)给定获得的候选标签词(例如great或terrible等可以作为二分类任务中代表的词);
(2)并在标签词前后添加填充位或(作者列出了三种填充位的方法,如上图),然后将其喂入T5模型中,自动为和生成序列。
(3)最后将标签词(great或terrible)转换为[MASK]标签,形成多个模板
(4)采用集束搜索来解码生成多个候选模板,然后对每一个候选模板利用dev集微调、选择其中一个最佳模板。
Fine-tuning with demonstrations
除了引入prompt外,作者还加入了一些in-context信息。这里也是参考GPT-3模型。GPT-3采用添加上下文样本示例进行微调,其随机挑选32个训练样本,以上下文的形式直接拼接到输入样本句子上,其存在两个问题:
- 样本示例的数量会受到模型最大输入长度的限制;
- 不同类型的大量随机示例混杂在一起,会产生很长的上下文,不利于模型学习。
in-context demonstration方法:
对于每一个输入句子 x i n x_{in} xin,从训练样本中的每一类随机采样一个样本,并得到该类的代表性的标签词,然后通过T5为其生成一个模板,并与该样本拼接形成prompt。每个类都会得到这样的prompt,全部与输入样本拼接,拼接后如下图所示。
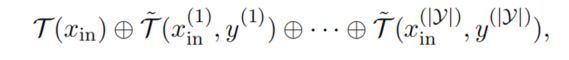
在挑选时,作者发现只需要对每一个类挑选一个样本即可,而挑选多个发现效果没有提升。另外为了保证挑选出来的句子与输入句子更加相似,作者事先对输入句子与每个样本计算了余弦相似度,并取前50%的样本中随机挑选。
实验效果
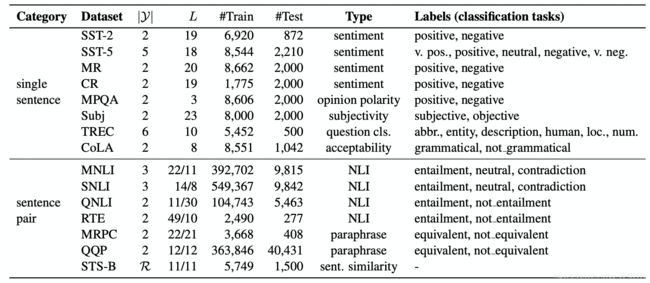
作者在诸多个数据集上进行了测试,数据集如图所示:
实验结果如下:

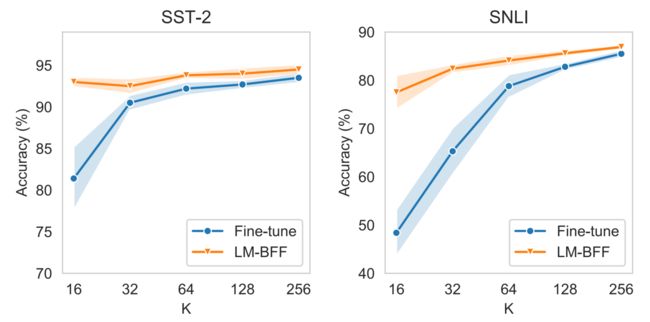
作者进行了大量的实验,此处只列出一个针对小样本场景下的,基于prompt和in-context的微调方法(LM-BFF)与标准的微调方法对比,可知,在只有少量样本(数量 K KK 很小时),LM-BFF就可以达到很好的微调效果了。
总结
优点:
(1)提出prompt-based微调策略,并自动化生成prompt模板;
(2)动态选择样本示例,用于in-context训练。
缺点:
(1)LM-BFF仍落后基于全量标注数据的标准微调方法
(2)仅适用少量类别,句子模板长度受限等
参考博客:
论文解读:Making Pre-trained Language Models Better Few-shot Learners(LM-BFF)