【集成学习系列教程2】AdaBoost回归算法原理及sklearn应用
文章目录
-
- 4 AdaBoost回归算法
-
- 4.1 概要
- 4.2 算法步骤
- 4.3 sklearn中的AdaBoost回归
-
- 4.3.1 原型
- 4.3.2 参数
- 4.3.3 属性
- 4.3.4 常用方法
- 4.4 实例3:使用AdaBoostRegressor完成回归任务
-
- 4.4.1 数据集的创建与可视化
- 4.4.2 不同参数的AdaBoost回归器拟合效果对比
4 AdaBoost回归算法
4.1 概要
AdaBoost算法不仅可以用于分类任务,还可以用于回归任务。由于回归预测得到的结果是连续数值,如股票价格,由于股票价格走势曲线是连续的,所以股票价格在实数范围内有非常多可能的数值,不像分类任务中的类别标签一样仅仅只有若干个固定的整数值。由于在分类任务中,样本权重的更新幅度与样本的类别息息相关,而在回归任务中用“目标数值”代替了分类标签,因此,AdaBoost回归算法更新样本权重的方式与AdaBoost分类算法有较大差异。下面将对AdaBoost回归算法做详细介绍。
4.2 算法步骤
假设有一个如下数据集,它由 m m m个样本组成:
D = { ( x 1 , y 1 ) , ( x 2 , y 2 ) , . . . , ( x m , y m ) } D= \{ (\boldsymbol x_1,y_1),(\boldsymbol x_2,y_2),...,(\boldsymbol x_m,y_m)\} D={(x1,y1),(x2,y2),...,(xm,ym)}
其中, x i ∈ R d \boldsymbol x_i\in\mathbb{R}^d xi∈Rd(每一个样本数据有 d d d 个特征), y i y_i yi为样本 x i \boldsymbol x_i xi的目标数值 。AdaBoost回归算法的具体步骤如下:
-
初始化权重。记初始状态下的数据集样本分布为 D i s t 1 Dist_1 Dist1,对每一个样本 x i \boldsymbol x_i xi的权重均初始化为 1 / m 1/m 1/m,则 D i s t 1 ( x i ) = 1 / m Dist_1(\boldsymbol x_i)=1/m Dist1(xi)=1/m。 D i s t 1 Dist_1 Dist1分布用于第一个弱分类器 h 1 h_1 h1的训练, D i s t t Dist_t Distt分布用于第一个弱分类器 h t h_t ht的训练,其他同理;
-
循环进行 T T T 轮迭代,记每一轮迭代中弱分类器的编号为 t t t,且 t ∈ { 1 , 2 , 3 , . . . , T } t \in \{1,2,3,...,T\} t∈{1,2,3,...,T}。以该步骤作为循环体,循环体中的步骤进一步细分为:
-
在样本分布为 D i s t t ( x ) Dist_t(\boldsymbol x) Distt(x)的基础上,在数据集 D D D上训练弱分类器 h t h_t ht;
-
计算分类器 h t h_t ht在训练集 D D D上的最大误差 E t E_t Et,计算公式为:
E t = m a x ∣ y i − h t ( x i ) ∣ , i = 1 , 2 , . . . , m E_t=max|y_i-h_t(\boldsymbol x_i)|, \quad i=1,2,...,m Et=max∣yi−ht(xi)∣,i=1,2,...,m
其中, h t ( x i ) h_t(\boldsymbol x_i ) ht(xi)表示弱分类器 h t h_t ht对样本 x i \boldsymbol x_i xi的预测结果, y i y_i yi表示样本 x i \boldsymbol x_i xi的目标数值; -
根据上面求得的 h t h_t ht的最大误差 E t E_t Et,计算 h t h_t ht对每个样本的相对误差,其计算方法有很多种,这里以平方误差为例:
e t i = ( y i − h t ( x i ) ) 2 E t 2 , i = 1 , 2 , . . . , m e_{ti}=\frac {\bold(y_i-h_t(\boldsymbol x_i)\bold)^2}{E_t^2}, \quad i=1,2,...,m eti=Et2(yi−ht(xi))2,i=1,2,...,m -
根据上一步求得的样本相对误差 e t i e_{ti} eti,计算出当前弱分类器 h t h_t ht的误差率:
e t = ∑ i = 1 m D i s t t ( x i ) e t i e_t= \sum_{i=1}^mDist_t(\boldsymbol x_i)e_{ti} et=i=1∑mDistt(xi)eti
即数据集中所有样本的权重与误差之乘积的和; -
更新当前弱分类器 h t h_t ht的权重,计算公式为:
w t = e t 1 − e t w_t = \frac{e_t}{1-e_t} wt=1−etet- 更新数据集样本的权重分布,对于样本 x i \boldsymbol x_i xi,更新权重的计算公式为:
D i s t t + 1 ( x i ) = D i s t t ( x i ) Z t w t 1 − e t i Dist_{t+1}(\boldsymbol x_i)=\frac{Dist_t(\boldsymbol x_i)}{Z_t}w_t^{1-e_{ti}} Distt+1(xi)=ZtDistt(xi)wt1−eti
其中, Z t Z_t Zt为归一化因子,其计算公式为:
Z t = ∑ i = 1 m D i s t t ( x i ) w t 1 − e t i Z_t = \sum_{i=1}^mDist_t(\boldsymbol x_i)w_t^{1-e_{ti}} Zt=i=1∑mDistt(xi)wt1−eti
- 更新数据集样本的权重分布,对于样本 x i \boldsymbol x_i xi,更新权重的计算公式为:
-
令 t : = t + 1 t := t+1 t:=t+1,回到循环体中的步骤1。
-
-
结束 T T T轮迭代,最终得到强回归器如下:
H ( x ) = ∑ i = 1 m l n ( 1 w t ) f ( x ) = [ ∑ i = 1 m l n ( 1 w t ) ] f ( x ) H(\boldsymbol x)=\sum_{i=1}^mln(\frac{1}{w_t})f(\boldsymbol x)=\bold [\sum_{i=1}^mln(\frac{1}{w_t})\bold ]f(\boldsymbol x) H(x)=i=1∑mln(wt1)f(x)=[i=1∑mln(wt1)]f(x)
其中, f ( x ) f(\boldsymbol x) f(x)是所有 w t h t ( x ) w_th_t(\boldsymbol x) wtht(x) ( t = 1 , 2 , . . . , T ) (t=1,2,...,T) (t=1,2,...,T)的中位数,即所有弱学习器的加权输出结果的中位数。这样就完成了AdaBoost算法的全过程。
4.3 sklearn中的AdaBoost回归
sklearn中的AdaBoostRegressor类对AdaBoost回归算法进行了实现,供用户使用。下面将对这个类进行详细介绍。
4.3.1 原型
原型如下:
class sklearn.ensemble.AdaBoostRegressor(base_estimator=None, *, n_estimators=50, learning_rate=1.0, loss='linear', random_state=None)[source]
4.3.2 参数
上述原型中各参数的解释如下,其中一些参数的含义与AdaBoostClassifier类的一致,因此对这些参数就不做详细介绍,读者可以翻到1.4小节查阅。
-
base_estimator: 对象类型,默认值为None
该参数不指定时,使用DecisionTreeRegressor(max_depth=3)作为基学习器,即默认使用深度为3的回归决策树。 -
n_estimators: 整型,默认值为50
基学习器的最大迭代次数(即最大的基学习器个数)。 -
learning_rate: 浮点型,默认为1.0
表示每个基学习器的权重缩减系数。 -
loss:可选项为 {‘linear’, ‘square’, ‘exponential’},默认为‘linear’定义误差函数(即1.7.2小节中的 e t i e_{ti} eti),各个选项的含义如下:
- ‘linear’:线性损失函数
- ‘square’:平方损失函数
- ‘exponential’:指数损失函数
-
random_state: 整型,默认为None
为每个基学习器设置相同的随机数种子,确保多次运行所生成的随机数状态均一致,便于调参与观察。
4.3.3 属性
AdaBoostingRegressor类的全部属性只有5个,比AdaBoostingClassifier类少。如下:
base_estimator_:返回基学习器(包括种类、详细参数等信息)。estimators_:返回对数据集进行拟合之后的所有基学习器所组成的列表。estimator_weights_:返回每个基学习器所对应权重所组成的列表。estimator_errors_:返回每个基学习器的回归损失所组成的列表。feature_importances_:返回数据集中每个特征的权重的组成的列表。
4.3.4 常用方法
AdaBoostingRegressor类的常用方法如下:
fit(X,y,[,sample_weight]:拟合数据集。get_params([deep]): d e e p deep deep参数指定为 T r u e True True 时,返回集成回归器的各项参数值。predict(X):对样本数据集 X X X进行回归预测,返回预测出的数值。staged_predict(X):获取对数据集 X X X的阶梯测试准确率(1.6.3小节对这个概念已有介绍)。staged_score(X):获取对数据集 X X X的阶梯训练准确率(1.6.3小节对这个概念已有介绍)。set_params(**params):以字典的形式传入参数**params,设置集成学习器的各项参数。
4.4 实例3:使用AdaBoostRegressor完成回归任务
接下来将演示如何使用AdaBoostRegressor类完成一个简单的回归任务,并对不同参数取值下的拟合效果进行可视化,使得读者可以直观感受到各个参数的作用。
4.4.1 数据集的创建与可视化
这里选择叠加正弦曲线,并加上高斯噪声的方式来创建数据集。这样的数据集非常适合用来测试、对比和可视化回归算法的性能。代码如下:
# 创建随机数种子
rng = np.random.RandomState(111)
# 训练集X为300个0到10之间的随机数
X = np.linspace(0, 10, 300)[:, np.newaxis]
# 定义训练集X的目标变量
y = np.sin(1*X).ravel() + np.sin(2*X).ravel() + np.sin(3* X).ravel()+np.cos(3*X).ravel() +rng.normal(0, 0.3, X.shape[0])
plt.figure(figsize=(10, 6))
plt.scatter(X, y, c='k', label='data', s=10, zorder=1, edgecolors=(0, 0, 0))
plt.xlabel("X")
plt.ylabel("y", rotation=0)
plt.show()
输出结果如下:
4.4.2 不同参数的AdaBoost回归器拟合效果对比
接下来将从两个方面对比不同参数取值下AdaBoost回归器的回归效果。
1 固定基学习器最大深度
固定基学习器(回归决策树)的最大深度为4,调节迭代次数分别为1、10和100,对比拟合效果。
代码如下:
# 定义不同迭代次数的AdaBoost回归器模型
adbr_1 = AdaBoostRegressor(DecisionTreeRegressor(max_depth=4), n_estimators=1, random_state=123)
adbr_2 = AdaBoostRegressor(DecisionTreeRegressor(max_depth=4), n_estimators=10, random_state=123)
adbr_3 = AdaBoostRegressor(DecisionTreeRegressor(max_depth=4), n_estimators=100, random_state=123)
# 拟合上述三个模型
adbr_1.fit(X, y)
adbr_2.fit(X, y)
adbr_3.fit(X, y)
# 读取各个模型的最大迭代次数
adbr_1_n_estimators = adbr_1.get_params(True['n_estimators']
adbr_2_n_estimators = adbr_2.get_params(True['n_estimators']
adbr_3_n_estimators = adbr_3.get_params(True)['n_estimators']
# 预测
y_1 = adbr_1.predict(X)
y_2 = adbr_2.predict(X)
y_3 = adbr_3.predict(X)
# 画出各个模型的回归拟合效果
plt.figure(figsize=(10, 6))
# 画出训练数据集(用黑色表示)
plt.scatter(X, y, c="k", s=10, label="Training Samples")
# 画出adbr_1模型(最大迭代次数为1)的拟合效果(用红色表示)
plt.plot(X, y_1, c="r", label="n_estimators=%d" % adbr_1_n_estimators, linewidth=1)
# 画出adbr_2模型(最大迭代次数为10)的拟合效果(用绿色表示)
plt.plot(X, y_2, c="g", label="n_estimators=%d" % adbr_2_n_estimators, linewidth=1)
# 画出adbr_3模型(最大迭代次数为100)的拟合效果(用蓝色表示)
plt.plot(X, y_3, c="b", label="n_estimators=%d" % adbr_3_n_estimators, linewidth=1)
plt.xlabel("data")
plt.ylabel("target")
plt.title("AdaBoost_Regressor Comparison with different n_estimators when max_depth=3")
plt.legend()
plt.show()
输出结果如下:
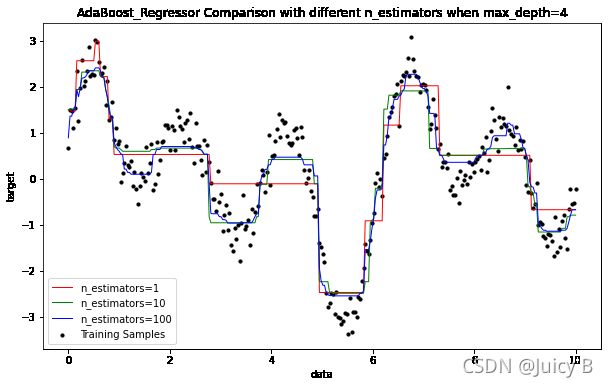
可以看到,随着迭代次数的增加,AdaBoost回归器对数据的拟合效果变得越来越好,但是在迭代次数呈指数级增加的情况下,拟合效果并没有得到很明显的提升。由此可以推测,在基学习器的深度不够大的情况下,大幅增加迭代次数对缓解欠拟合的帮助并不大。接下来,我们尝试改变基学习器的最大深度,看看效果如何。
2 固定迭代次数
固定迭代次数为100,调节基学习器(回归决策树)的最大深度,分别为4、5、6,对比拟合效果。
代码如下:
# 拟合不同基学习器深度的回归模型
adbr_4 = AdaBoostRegressor(DecisionTreeRegressor(max_depth=4), n_estimators=100, random_state=123)
adbr_5 = AdaBoostRegressor(DecisionTreeRegressor(max_depth=5), n_estimators=100, random_state=123)
adbr_6 = AdaBoostRegressor(DecisionTreeRegressor(max_depth=6), n_estimators=100, random_state=123)
# 拟合上述3个模型
adbr_4.fit(X, y)
adbr_5.fit(X, y)
adbr_6.fit(X, y)
# 预测
y_4 = adbr_4.predict(X)
y_5 = adbr_5.predict(X)
y_6 = adbr_6.predict(X)
# 画出各个模型的回归拟合效果
plt.figure(figsize=(10, 6))
# 画出训练数据集(用黑色表示)
plt.scatter(X, y, c="k", s=10, label="Training Samples")
# 画出adbr_4模型(基学习器深度为3)的拟合效果(用红色表示)
plt.plot(X, y_4, c="r", label="max_depth=4" , linewidth=1)
# 画出adbr_5模型(基学习器深度为4)的拟合效果(用绿色表示)
plt.plot(X, y_5, c="g", label="max_depth=5" , linewidth=1)
# 画出adbr_6模型(基学习器深度为5)的拟合效果(用蓝色表示)
plt.plot(X, y_6, c="b", label="max_depth=6" , linewidth=1)
plt.xlabel("data")
plt.ylabel("target")
plt.title("AdaBoost_Regressor Comparison with different max_depth when n_estimators=100")
plt.legend()
plt.show()
输出结果如下:
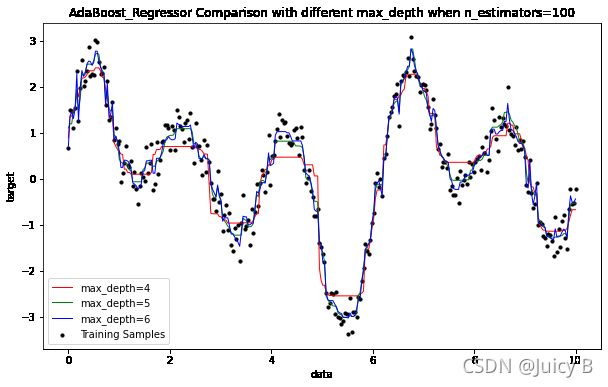
可以看到,在固定迭代次数为100的情况下,增加基学习器的最大深度对提升拟合效果的帮助非常大。所以,实际使用中,在控制拟合时间的前提下,读者应该尽量将基学习器回归决策树的最大深度设置得大一点,然后再在此基础上尝试对n_estimators等参数进行调参。