ImageNet Classification with Deep Convolutional Neural Networks
ImageNet Classification with Deep Convolutional Neural Networks
原文:http://xanadu.cs.sjsu.edu/~drtylin/classes/cs267_old/ImageNet%20DNN%20NIPS2012(2).pdf
翻译:https://www.jianshu.com/p/ea922866e3be
一、理解文章
1、背景知识
ReLU:https://blog.csdn.net/lee813/article/details/80993355
LRN:https://blog.csdn.net/yangdashi888/article/details/77918311
Pooling:https://blog.csdn.net/mao_kun/article/details/50507376?readlog
Dropout:http://www.cnblogs.com/ocean1100/articles/9370557.html & https://www.jianshu.com/p/b5e93fa01385
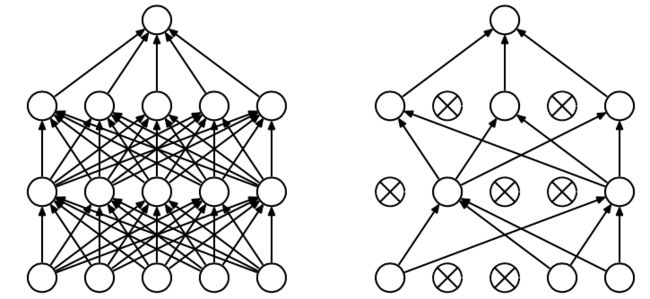
Dropout为什么高效:https://blog.csdn.net/stdcoutzyx/article/details/49022443
momentum:https://blog.csdn.net/u013989576/article/details/70241121/
Softmax:https://blog.csdn.net/red_stone1/article/details/80687921
Generalization:https://developers.google.cn/machine-learning/crash-course/generalization/video-lecture?hl=zh-cn
泛化是指从训练集中学习得到的模型参数在测试集中是不是也好用,好用则泛化好,不好用则泛化不好。
2、文章脉络
本文主要贡献如下:
1. 我们在ImageNet上训练了一个卷积神经网络,并且取得了目前最高的准确率
2. 我们写了一个基于2D卷积的GPU优化实施方案,并开源了它
3. 用了 ReLU,多 GPU 训练,局部泛化来提升性能并缩短训练时间
4. 用了 Dropout,数据增广来防止过拟合
5. 使用了5层卷积加3层全连接层,结构也很重要,减少网络深度性能会变差
(因为计算能力的限制,用了2块3GB的 GTX580 GPU 训练了5-6天)
摘自:https://blog.csdn.net/Chris_zhangrx/article/details/78795420
3、模型架构
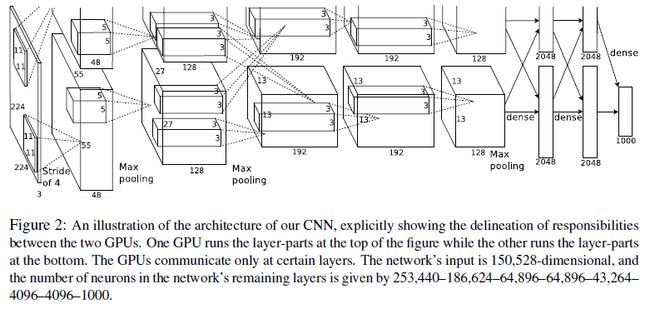

网络数据规模:https://blog.csdn.net/yihaizhiyan/article/details/26962607
网络数据分析:https://blog.csdn.net/sun_28/article/details/52134584
4、具体理解
1)问题和动机:
To learn about thousands of objects from millions of images, we need a model with a large learning capacity.
(ImageNet数据集出现之后,需要一个学习能力强大的网络,然而,大型网络必然面临极大的复杂度以及对硬件的挑战,随着CNN的出现以及可并行的GPU出现,使得该问题可以真正本研究,本文基于ImageNet LSVRC-2010比赛,提出一系列网络改进方法,以提高计算效率节约时间并防止过拟合,提高泛化能力)
2)解决方法:
a、采用ReLU非线性激活函数(non-saturating的)而不采用sigmoid、tanh非线性激活函数(saturating的)来提高学习速度,因为ReLU激活函数(f(x)=max(0,x))在非负区间梯度为常数,不存在梯度消失问题,而sigmoid、tanh函数存在饱和区,饱和区的梯度几乎无变化,所以在反向传播时变化非常小,无疑增加了训练次数。
b、采用并行双GPU训练数据集来减少运行时间,提高效率(见模型架构中图一),并行GPU可以不必通过主机直接读写内存(?不是很懂),但是文章中提及“The two-GPU net takes slightly less time to train than the one-GPU net”,文章给出的解释是“The one-GPU net actually has the same number of kernels as the two-GPU net in the final convolutional layer. This is because most of the net’s parameters are in the first fully-connected layer, which takes the last convolutional layer as input. So to make the two nets have approximately the same number of parameters, we did not halve the size of the final convolutional layer (nor the fully-conneced layers which follow). Therefore this comparison is biased in favor of the one-GPU net, since it is bigger than “half the size” of the two-GPU net.”(实际上,在最终的卷积层中,1 - gpu网络与2 - gpu网络拥有相同数量的内核。这是因为网络的大部分参数都在第一个完全连接的层中,它以最后一个卷积层作为输入。因此,为了使这两个网络具有大约相同数量的参数,我们没有将最终卷积层的大小减半(也没有将随后的完全连接层的大小减半)。因此,这种比较偏向于one-GPU网络,因为它大于two-GPU网络的“一半大小”。)
c、局部响应归一化(加入LRN层)增强泛化能力,防止过拟合。top-1、top-5降低了1.4%、1.2%。公式如下:
(k,n,alpha,beta是超参,a是第i个核在位置(x,y)用ReLU非线性化的输出,n控制相邻局部大小,N是kernal总数)
该方法模仿生物神经学的“侧抑制”,被激活的神经元抑制相邻神经元。
d、重叠池化(Overlapping Pooling)稍微防止过拟合,重叠池化即stride≠size(kernal)。top-1、top-5降低了0.4%、0.3%。
e、数据增广(Data Augmentation)增加数据量,防止过拟合,top-1降低1%。本文主要通过两种方法来增加数据集样本量,“The first form of data augmentation consists of generating image translations and horizontal reflections.”(一种方法是:通过对原图像翻转得到第二幅图,取窗口小于整幅图片的patch在这两幅图的左上、右上、左下、右下、中间切取小图,这样就由原来的一幅图变为了十幅图)。“The second form of data augmentation consists of altering the intensities of the RGB channels in training images. Specifically, we perform PCA on the set of RGB pixel values throughout the ImageNet training”(第二种方法是通过改变RGB通道值,在这个过程中用到了PCA,?不是很懂)
f、前两个全连接层加入Dropout,防止过拟合,效果显著。感觉Dropout就是利用了数据的稀疏性,每次只取其中一部分数据,数据少了,自然不会过拟合。具体实现时HIton在2012年A simple way to prevent neural networks from overfitting[J]. The Journal of Machine Learning Research一文中有提及。
3)评价:(?实验没有看很懂)
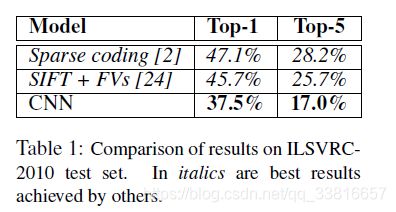
用在不同模型上Top-1和Top-5的错误率:
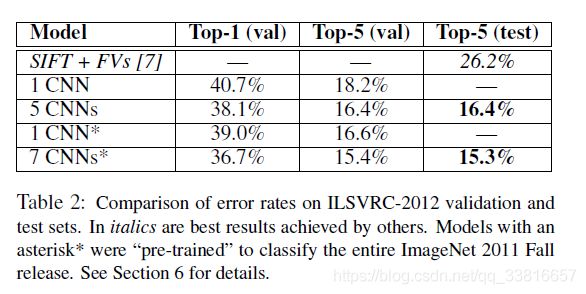
不同个数CNN的实验结果:


4)结论:
“It is notable that our network’s performance degrades if a single convolutional layer is removed”CNN模型的卷积层数很重要,任何卷积层减少都会影响最终效果,文中提及的方法可以防止过拟合,Dropout方法尤见其优。
作者未来工作:“we would like to use very large and deep convolutional nets on video sequences where the temporal structure provides very helpful information that is missing or far less obvious in static images”,将这种大型深度CNN用于处理视频序列。
5、分析
该文章提出多种方法来防止过拟合,提高泛化能力,错误率的大幅度降低是所有方法累计后的结果,因为该文章是在参加比赛后写的,所以有大量的实验结果对比,通过这些对比也可以比较清晰的看出每种方法提高泛化能力的大小。
看完之后的问题:文章只提及到了卷积层数对降低错误率至关重要(降低中间层,有2%的误差),但是没有说卷积层数究竟是如何取的,也就是对于某一种问题来说,网络规模究竟取多大合适?对于不同问题(比如这个问题是识别1000类,如果识别一个2000类的呢?),一旦确定一个较好的网络规模后,这个网络规模是否具有普适性?