Pytorch初探
什么是Pytorch
Facebook的Pytorch和Google 的TensorFlow一样,也是一款深度学习库,TensorFlow主要应用于工业生产领域之中,GitHub上的深度学习工具也多基于TensorFlow;而Pytorch在研究领域被广泛使用,越来越多的论文和新技术都基于Pytorch开发。
工业场景比研究领域相对置后,且近年来Pytorch的研究论文有逐渐增加的趋势,随着前沿技术的应用,Pytorch也可能成为一种趋势。目前常用的模型也都有对应的Pytorch版本,具体请见后面参考部分。
本篇就来学习一下Pytorch。Pytorch是Facebook开源的包含GPU加速的神经网络框架。Pytorch是torch的Python版本,也提供C++的接口。
相关概念
Pytorch不像TensorFlow加入了Scope、Session等新概念以及复杂的调用方法,有较高的学习成本,Pytorch只有三个重要概念Tensor(张量)、variable(变量)、Module(模块),它的易用性类似于Keras(Keras是更上层的API,可调用TensorFlow,Theano和CNTK),但比Keras更加灵活。
Tensor
Tensor被译为张量或者标量,它类似于numpy的array。
Variable
Variable被译为变量,可以将它看作Tensor的扩展,它带有自动求导(autogard)功能,一般通过backward()计算梯度后,通过其grad属性查看梯度。创建Variable时需要设置requires_grad=True,才能计算梯度。
Module
Module可以用于定义层,也可以用于定义整个神经网络。它是神经网络的基类,一般构建网络都需要继承Module,并在构造函数init()中定义自己的网络结构,以及实现前向算法forward()。
Function
Function针对单个功能,它不像Module可以保存数据,一般Function只需要实现init()、forward()、backward()三个函数。
DataSet
DataSet是用于读取数据的工具类,对于较为复杂的数据,通常需要继承DataSet实现自己的数据类。
optim
optimizer译为优化器,pytorch.optim.*中实现了多种优化算法,可以直接调用。 使用时,首先,需要选择一种优化算法,在创建时指定具体参数如学习率,然后在训练模型时使用优化器更新参数(调用其step方法)。优化器用于调整网络参数,其本身不存储数据,只保存优化算法及其参数和指向网络参数的指针。 Pytorch可以对不同的层设置不同的优化参数。
动态计算图
计算图指构建的神经网络结构。TensorFlow使用静态计算图机制,一旦建立,训练过程中不能被修改, 静态计算在效率方面有更大的优化空间。Pytorch 使用动态计算图机制,每一次训练,都会销毁图并重新创建,这样占用了更多资源,但是更加灵活。
安装
普通安装
不同的操作系统,Python版本和不同硬件(是否支持GPU)安装方法不同,具体方法见https://pytorch.org/,如下图所示:
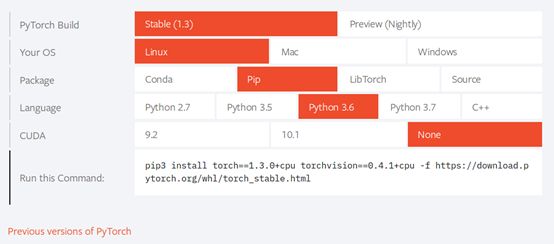
安装好之后,用以下方法,可查看torch版本:
import torch
print(torch.__version__)
下载源码
$ git clone --recursive [https://github.com/pytorch/pytorch](https://github.com/pytorch/pytorch) # 下载源码
$ git clone [https://github.com/pytorch/examples.git](https://github.com/pytorch/examples.git) # 下载例程
实例
pytorch/examples/中包括各种例程,其中mnist手写数字识别是深度学习中最常用的示例数据,其Pytorch例程只有百余行,核心代码在50行左右。 下面将讲解其核心函数。
首先,它实现了基于Module的类,用于描述神经网络,其中构造函数init()定义了网络结构,函数forward()描述了前向传播的方法。
class Net(nn.Module): # 定义神经网络
def __init__(self): # 构建网络
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 20, 5, 1) # 卷积层,输入为1,输出为20,卷积核5x5
self.conv2 = nn.Conv2d(20, 50, 5, 1)
self.fc1 = nn.Linear(4*4*50, 500) # 全连接层,输入为4*4*50,输出为500
self.fc2 = nn.Linear(500, 10)
def forward(self, x): # 前向传播
x = F.relu(self.conv1(x)) # 激活函数
x = F.max_pool2d(x, 2, 2) # 最大池化
x = F.relu(self.conv2(x))
x = F.max_pool2d(x, 2, 2)
x = x.view(-1, 4*4*50) # 改变形状,将数据展开
x = F.relu(self.fc1(x))
x = self.fc2(x)
return F.log_softmax(x, dim=1)
然后,分别实现了训练train和测试test两个函数,train将整体数据分块batch代入模型训练,再用损失函数计算误差,求梯度,并用优化器调整网络参数。
def train(args, model, device, train_loader, optimizer, epoch):
model.train()
for batch_idx, (data, target) in enumerate(train_loader): # 整体数据分块训练
data, target = data.to(device), target.to(device)
optimizer.zero_grad() # 清空了grad,而非params
output = model(data)
loss = F.nll_loss(output, target) # 误差函数将output与target设入loss
loss.backward() # 反向传播,修改了网络参数中的grad
optimizer.step() # 根据反向传播梯度更新网络参数
if batch_idx % args.log_interval == 0:
print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(epoch, batch_idx * len(data), len(train_loader.dataset), 100\. * batch_idx / len(train_loader), loss.item()))
主程序根据迭代次数(epoch),多次调用train和test训练模型。
model = Net().to(device)
optimizer = optim.SGD(model.parameters(), # 神经网络参数设置给优化器
lr=args.lr, momentum=args.momentum)
for epoch in range(1, args.epochs + 1): # 所有数据训练多次
train(args, model, device, train_loader, optimizer, epoch)
test(args, model, device, test_loader)
总结
Pytorch的难度介于keras和TensorFlow之间,最重要的是,它的顺序结构,让程序员对流程一目了然。 相对于看原理和论文,很多时候,程序员看代码效果更好,Pytorch的数据处理过程与原理契合度很高。而且预训练、对抗网络的例程也很多,公式完全能落实到代码中。
参考
PyTorch流行的预训练模型和数据集列表pytorch-playground
https://ptorch.com/news/171.html
PyTorch-动态计算图
https://blog.csdn.net/zhouchen1998/article/details/89562423