SpringBoot集成Kafka+Kafka优化问题
SpringBoot集成Kafka+Kafka优化问题
前置知识:
Kafka概述及使用
通过Java操作Kafka
1 SpringBoot集成Kafka
①创建boot工程,导入kafka依赖
<!--引入kafka依赖-->
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>
②编写配置文件
此处我使用的是Kafka集群
server:
port: 8080
spring:
kafka:
bootstrap-servers: 192.168.145.13:9092, 192.168.145.13:9093, 192.168.145.13:9094 # kafka地址
producer: # 生产者
retries: 3 # 重试次数
batch-size: 16384
buffer-memory: 33554432
acks: 1
# 指定消息key和消息体的编码解码方式
key-serializer: org.apache.kafka.common.serialization.StringSerializer
value-serializer: org.apache.kafka.common.serialization.StringSerializer
consumer: # 消费者
group-id: default-group
enable-auto-commit: false
auto-offset-reset: earliest
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
value-deserializer: org.apache.kafka.common.serialization.StringDeserializer
max-poll-records: 500 # 一次最多拉500条消息
listener: # 配置监听
ack-mode: MANUAL_IMMEDIATE
③编写producer(生产者)
@RestController
@RequestMapping("/msg")
public class KafkaController {
private final static String TOPIC_NAME = "my-replicated-topic";
@Autowired
private KafkaTemplate<String, String> kafkaTemplate;
@GetMapping("/send")
public String sendMsg(){
kafkaTemplate.send(TOPIC_NAME, 0, "key", "this is a message!");
return "send msg success";
}
}
④编写消费者
@Component
public class MyConsumer {
@KafkaListener(topics = "my-replicated-topic", groupId = "MyGroup1")
public void listenGroup(ConsumerRecord<String, String> record, Acknowledgment ack){
String value = record.value();
System.out.println(value);
System.out.println(record);
//手动提交offset【如果不提交offset,会导致消息重复消费】
ack.acknowledge();
}
}
测试:
启动boot项目,访问地址:http://localhost:8080/msg/send, 发送消息,查看控制台打印信息
this is a message!
ConsumerRecord(topic = my-replicated-topic, partition = 0, leaderEpoch = 4, offset = 10,
CreateTime = 1668158942418, serialized key size = 3, serialized value size = 18, headers =
RecordHeaders(headers = [], isReadOnly = false), key = key, value = this is a message!)
2 Kafka中的其他概念与配置
2.1 消费者中配置消费主题、分区和偏移量
@KafkaListener(groupId = "testGroup", topicPartitions = {
@TopicPartition(topic = "topic1", partitions = {"0", "1"}),
@TopicPartition(topic = "topic2", partitions = "0",
partitionOffsets = @PartitionOffset(partition = "1",
initialOffset = "100"))
}, concurrency = "3")
//concurrency就是同组下的消费者个数,就是并发消费数,建议⼩于等于分区总数
public void listenGroupPro(ConsumerRecord<String, String> record,
Acknowledgment ack) {
String value = record.value();
System.out.println(value);
System.out.println(record);
//⼿动提交offset
ack.acknowledge();
}
- ack.acknowledge()提交配置:
"MANUAL":当每⼀批poll()的数据被消费者监听器(ListenerConsumer)处理之后,
⼿动调⽤Acknowledgment.acknowledge()后提交
"MANUAL_IMMEDIATE":⼿动调⽤Acknowledgment.acknowledge()后⽴即提交,⼀般使⽤这种
# 最后取决于自己在配置文件中配置的listener的ack-mode模式
ack-mode: MANUAL_IMMEDIATE
2.2 Kafka集群中的controller、rebalance、HW
- controller
- 集群中谁来充当controller
每个broker启动时会向zk创建一个临时序号节点,获得的序号最小的那个broker将会作为集群中的controller,主要负责这么几件事:
- 当集群中有一个副本的leader挂掉,需要在集群中选举出一个新的leader,选举的规则是从ISR集合中最左边获得
- 当集群中有broker新增或减少,controller会同步信息给其他的broker
- 当集群中有分区新增或减少,controller会同步信息给其他broker
- rebalance机制
前提:消费组中的消费者没有指明分区来消费
触发的条件:当消费组中的消费者和分区关系发生变化的时候
分区分配的策略:在rebalance之前,分区怎么分配会有这么三种策略:
- range:根据公式计算得到每个消费者消费哪几个分区:前面的消费者实时分区总数/消费者数量+1,后面的消费者是分区总数/消费者数量
- 轮询:大家轮着来
- sticky:粘合策略,如果需要rebalance,会在之前已分配的基础上调整,不会改变之前的分配情况。如果这个策略没有打开,那么就要进行全部的重新分配。【建议开启】
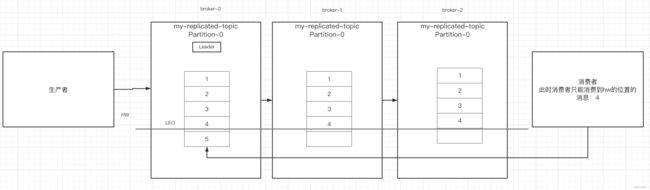
- HW和LEO
LEO是某个副本最后消息的消息位置(log-end-offset)
HW(High Watermark,高水位)是已完成同步的位置。消息在写入broker时,且每个broker完成这条消息的同步后,hw才会变化。在这之前消费者是消费不到这条消息的。在同步完成之后,HW更新之后,消费者才能消费到这条消息,这样的目的是防止消息的丢失。
3 Kafka中的优化
3.1 防止消息丢失
- 生产者:
1)使用同步发送
2)把ack设置为1或者all(多副本间leader已经收到消息/所有的broker已经收到消息) - 消费者:把自动提交改为手动提交
3.2 如何防止重复消费
在防止消息丢失的方案中,如果生产者发送完消息后,因为网络抖动,没有收到ack,但实际上broker已经收到了。
此时生产者会进行重试,于是broker就会收到多条相同的消息,而造成消费者的重复消费。
解决方案:
- 生产者关闭重试:会造成丢消息【不建议】
- 消费者解决非幂等性问题:
幂等性:多次访问的结果是一样的。
对于Rest的请求来说:
- get:幂等
- post:非幂等
- put:幂等
- delete:幂等
解决办法:
- 在数据库中创建主键
- 使用分布式锁,以业务id为锁。保证只有一条记录能够创建成功。
拓展:常见解决幂等性方案
- 数据库唯一主键
- 数据库乐观锁
- 防重Token令牌
- 下游传递唯一序列号
四种幂等性解决方案
3.3 顺序消费
- 生产者:保证消息按顺序消费,且消息不丢失— —使用同步的发送,ack设置成非0的值
- 消费者:主题只能设置一个分区,消费组中只能有一个消费者
Kafka的顺序消费使用场景不多,因为牺牲了性能。【Rocketmq在顺序消费这一块有专门的功能,已经设计好】
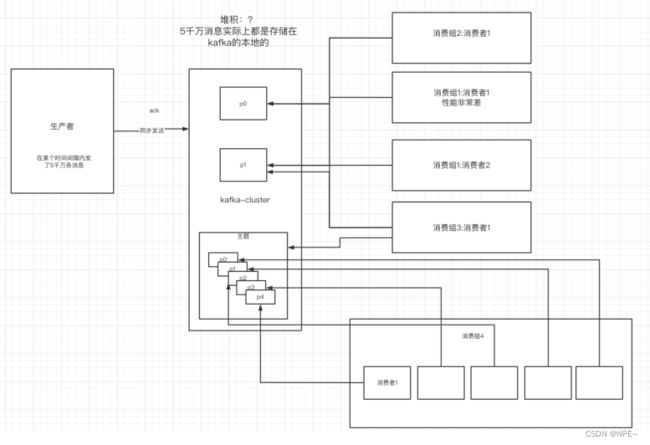
3.4 解决消息积压

1)消息积压问题的出现
消费者的消费速度远远赶不上生产者的生产速度,导致kafka中有大量的数据没有被消费。随着没有被消费的数据越来越多,消费者寻址的性能会越来越差。最后导致整个kafka对外提供服务的性能很差,从而造成其他服务的访问速度也变慢,导致服务雪崩。
2)解决方案
- 在这个消费者中,使用多线程,充分利用机器的性能进行消费消息。
- 通过业务的架构设计,提升业务层面消费的性能。
- 创建多个消费组,多个消费者,部署到其他机器上,一起消费,提高消费者的消费速度。
- 创建一个消费者,该消费者在Kafka另建一个主题,配上多个分区,多个分区再配上多个消费者。该消费者将poll下来的消息,不进行消费,直接转发到新建的主题上(中转站作用)。此时,新的主题的多个分区的多个消费者就开始一起消费了。— — 不常用
3.5 延时队列
- 应用场景:订单创建后,超过30分钟没有支付,则需要取消订单,这种场景可以通过延时队列来实现
- 具体方案
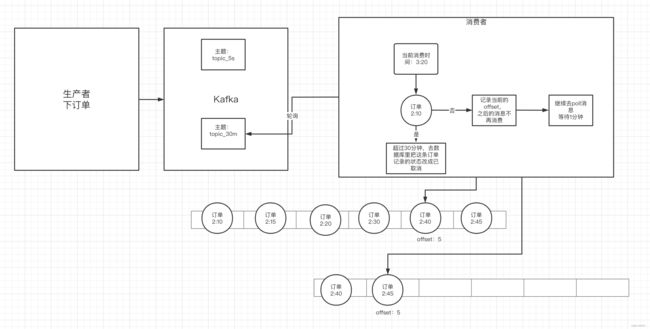
- kafka中创建相应的主题
- 消费者消费该主题的消息(轮询)
- 消费者消费时判断该消息的创建时间和当前时间是否超过30分钟(前提是订单没支付)
- 如果是(超过30分钟):去数据库中修改订单状态为已取消
- 如果否:记录当前消息的offset,并不再继续消费之后的消息。等待1分钟之后,再次向kafka中拉取该offset及之后的消息,继续进行判断,以此反复。
4 Kafka-eagle监控平台
4.1 搭建
- 去kafka-eagle官网下载压缩包:http://download.kafka-eagle.org/
- 选择一台虚拟机
- 虚拟机中安装jdk
- 解压缩kafka-eagle
- 给kafka-eagle配置环境变量
export KE_HOME=/usr/local/kafka-eagle
export PATH=$PATH:$KE_HOME/bin
配置完环境变量之后记得刷新
source /etc/profile
- 修改kafka-eagle内部的配置文件:system-config.properties
修改⾥⾯的zk的地址和mysql的地址
- 启动kafka-eagle
进入bin目录
./ke.sh start
4.2 平台的使用