Edge AI: On-Demand Accelerating Deep Neural Network Inference via Edge Computing
题目:Edge AI: On-Demand Accelerating Deep Neural Network Inference via Edge Computing
边缘智能:通过边缘计算按需加速深度神经网络推理
在深度学习中,推理是指将一个预先训练好的神经网络模型部署到实际业务场景中,如图像分类、物体检测、在线翻译等。 由于推理直接面向用户,因此推理性能至关重要,尤其对于企业级产品而言更是如此。 衡量推理性能的重要指标包括延迟(latency)和吞吐量(throughput)。 延迟是指完成一次预测所需的时间,吞吐量是指单位时间内处理数据的数量。 低延迟和高吞吐量能够保证良好的用户体验和工业生产要求。
作者:En Li, Liekang Zeng, Zhi Zhou, Member , IEEE and Xu Chen, Member , IEEE
摘要:As a key technology of enabling Artificial Intelligence (AI) applications in 5G era, Deep Neural Networks(DNNs) have quickly attracted widespread attention.However,it is challenging to run computation-intensive DNN-based tasks on mobile devices due to the limited computation resources.What’s worse, traditional cloud-assisted DNN inference is heavily hindered by the significant wide-area network latency, leading to poor real-time performance as well as low quality of user experience.To address these challenges, in this paper, we propose Edgent, a framework that leverages edge computing for DNN collaborative inference through device-edge synergy.Edgent exploits two design knobs: (1) DNN partitioning that adaptively partitions computation between device and edge for purpose of coordinating the powerful cloud resource and the proximal edge resource for real-time DNN inference; (2) DNN right-sizing that further reduces computing latency via early exiting inference at an appropriate intermediate DNN layer.In addition, considering the potential network fluctuation in real-world deployment, Edgent is properly design to specialize for both static and dynamic network environment. Specifically, in astatic environment where the bandwidth changes slowly, Edgent derives the best configurations with the assist of regression-based prediction models, while in a dynamic environment where the bandwidth varies dramatically, Edgent generates the best execution plan through the online change point detection algorithm that maps the current bandwidth state to the optimal configuration. We implement Edgent prototype based on the Raspberry Pi and the desktop PC and the extensive experimental evaluations demonstrate Edgent’s effectiveness in enabling on-demand low-latency edge intelligence.
作为在5G时代人工智能应用的关键技术,深度神经网络很快得到了广泛关注。 然而,因为有限的计算资源,在移动设备上执行基于DNN的计算密集型任务是很有挑战性的。 更糟糕的是,传统的云辅助DNN推理收到广域网延迟的严重影响,导致实时性差、用户体验差。 为了应对这些挑战,在这篇文章,我们提出了Edgent,一种通过协同设备和边缘利用边缘计算进行DNN协同推理的框架。Edgent有两个设计关键:(1)DNN划分,即自适应地对设备和边缘之间的计算进行划分,以协调强大的云资源和近端边缘资源,实现实时的DNN推理。(2)DNN合理规模,通过在合适的DNN中间层提前退出推理,更大程度减少计算延迟。此外,考虑到在实际部署过程中存在的潜在网络波动,Edgent针对静态和动态的网络进行了专门的设计。具体来说,在带宽的变化非常缓慢的静态环境下,Edgent借助于基于回归的预测模型得到了最优的配置;在带宽剧烈变化的动态环境下,Edgent通过在线变点检测算法生成了最优的执行策略,该算法将当前带宽状态映射到最优配置中。我们实现了基于树莓派和桌面PC的Edgent,大量的实验评估证明了Edgent在按需低时延边缘智能方面的有效性。
Index Terms—Edge intelligence, edge computing, deep learning, computation offloading.
关键词:边缘智能、边缘计算、深度学习、计算卸载
设计了Edgent,那Edgent是个啥?
是一个框架。通过协同设备和边缘,利用边缘计算,进行DNN协同推理的框架。
什么是DNN推理呢?
DNN推理是将一个预先训练好的DNN模型部署到实际业务场景中,如图像检测、物体检测、在线翻译。
设计Edgent的目的是为了解决什么?
资源有限,在移动设备上执行基于DNN的计算密集型任务有困难;云辅助DNN推理受到广域网延迟的影响,实时性差。
设计DNN的关键点是什么?
DNN划分和DNN合理规模。
一、介绍
AS the backbone technology supporting modern intelligent mobile applications, Deep Neural Networks (DNNs) represent the most commonly adopted machine learning technique and have become increasingly popular. Benefited by the superior performance in feature extraction, DNN have witnessed widespread success in domains from computer vision [2],speech recognition [3] to natural language processing [4] and big data analysis [5]. Unfortunately, today’s mobile devices generally fail to well support these DNN-based applications due to the tremendous amount of computation required by DNN-based applications
作为支持现代智能移动应用的骨干技术,深度学习网络代表了最常用的机器学习技术并且变得越来越流行。得益于其优秀的特征提取能力,DNN在计算机视觉[2]、语音识别[3]、自然语言处理[4]和大数据分析[5]领域得到了广泛的成功。不幸的是,现在的移动设备通常不能支持那些基于DNN的应用,因为基于DNN的应用需要巨大的算力。
In response to the excessive resource demand of DNNs,traditional wisdom resorts to the powerful cloud datacenter for intensive DNN computation. In this case, the input data generated from mobile devices are sent to the remote cloud datacenter, and the devices receive the execution result as the computation finishes.However, with such cloud-centric approaches, a large amount of data (e.g., images and videos)will be transferred between the end devices and the remote cloud datacenter backwards and forwards via a long wide-area network, which may potentially result in intolerable latency and extravagant energy. To alleviate this problem, we exploit the emerging edge computing paradigm. The principal idea of edge computing [6]–[8] is to sink the cloud computing capability from the network core to the network edges (e.g.base stations and WLAN) in close proximity to end devices[9]–[14]. This novel feature enables computation-intensive and latency-critical DNN-based applications to be executed in a real-time responsive manner (i.e., edge intelligence) [15].By leveraging edge computing, we can design an on-demand low-latency DNNs inference framework for supporting real-time edge AI applications.
为了应对DNN过量的资源需求,传统智慧是求助于强大的云计算平台进行密集的DNN计算。在这种情况下,移动设备上产生的输入数据发送到远程云数据中心,计算完毕后,设备再接受执行结果。然而,在这种以云为中心的方法中,大量的数据(图片/视频)将在终端与远程云数据中心之间通过长广域网来回传输,这可能导致难以忍受的延迟和巨大的能量消耗。为了缓解这一问题,我们利用了新兴的边缘计算范式。 边缘计算的核心思想就是[6]-[8]将云计算能力从核心网络下沉到边缘网络[9]-[14]。这个新特征使计算密集的和对延迟要求高的基于DNN的应用能够以实时响应的方式被执行[15]。通过利用边缘计算,我们可以设计一个支持实时边缘人工智能应用的按需低延迟DNN推理框架。
On this issue, in this paper, we exploit the edge computing paradigm and propose Edgent, a low-latency co-inference framework via device-edge synergy. Towards low-latency edge intelligence, Edgent pursues two design knobs. The first is DNN partitioning, which adaptively partitions DNN computation between mobile devices and the edge server according to the available bandwidth so as to utilize the computation capability of the edge server. However, it is insufficient to meet the stringent responsiveness requirement of some mission-critical applications since the execution performance is still restrained by the rest of the model running on mobile devices.Therefore, Edgent further integrate the second knob, DNNright-sizing, which accelerates DNN inference by early exiting inference at an intermediate DNN layer. Essentially, the early-exit mechanism involves a latency-accuracy tradeoff. To strike a balance on the tradeoff with the existing resources, Edgent makes a joint optimization on both DNN partitioning and DNN right-sizing in an on-demand manner. Specifically, for mission-critical applications that are typically with a predefined latency requirement, Edgent maximizes the accuracy while promising the latency requirement.
为了应对这一问题,本文利用边缘计算范式,提出了一种基于设备-边缘协同的低延迟协同推理框架:Edgent。面对低延迟的边缘智能,Edgent追求两个设计关键:第一个是DNN划分,根据可用带宽自适应地将DNN计算在移动设备和边缘服务器之间划分,以利用边缘服务器的计算能力。然而,它不足以满足一些任务关键型应用程序的严格响应要求,因为执行性能仍受一些在移动设备上运行的模型的其余部分的限制。因此,Edgent进一步整合了第二个设计关键:DNN合理规模。DNN合理规模通过在合适的DNN层提前退出推理来加速DNN推理过程的。本质上,提前退出机制包含延迟和精度之间的权衡。为了在现有资源的权衡中得到平衡,Edgent以按需方式对DNN划分和DNN合理规模进行了联合优化。具体地说,对于任务关键型应用程序,通常有预定义延迟的需求,Edgent在保证预定义延迟需求的同时保证了精度最大化。
Considering the versatile network condition in practical deployment, Edgent further develops a tailored configuration mechanism so that Edgent can pursue better performance in both static network environment and dynamic network environment. Specifically, in a static network environment (e.g.,local area network with fiber or mmWave connection), we regard the bandwidth as stable and figure out a collaboration strategy through execution latency estimation based on the current bandwidth. In this case, Edgent trains regression models to predict the layer-wise inference latency and accordingly derives the optimal configurations for DNN partitioning and DNN right-sizing. In a dynamic network environment (e.g., 5G cellular network, vehicular network), to alleviate the impact of network fluctuation, we build a look-up table by profiling and recording the optimal selection of each bandwidth state and specialize the runtime optimizer to detect the bandwidth state transition and map the optimal selection accordingly.Through our specialized design for different network environment, Edgent is able to maximize the inference accuracy without violating the application responsiveness requirement.The prototype implementation and extensive evaluations based on the Raspberry Pi and the desktop PC demonstrate Edgent’s effectiveness in enabling on-demand low-latency edge intelligence.
考虑到在实际部署中多变的网络环境,Edgent进一步开发了定制配置机制,这使Edgent可以在静态网络环境和动态网络环境中都能追求更好的性能。具体地说,在静态网络环境里(由光纤/毫米波链接的局域网络),我们认为带宽是稳定的,并且根据当前贷款预估执行延迟,得到协作策略。在这种情况下,Edgent训练回归模型来预测分层推理延迟,并据此得出DNN划分和合理规模的最佳配置。在动态网络环境下(5G蜂窝网络、汽车网络),为了减轻网络波动带来的影响,我们通过分析构建了一个查找表,并且记录下每个带宽状态的最优选择,并且用运行时优化器去检测带宽状态转换和映射相应的最优选择。通过我们对不同网络环境进行的专门设计,Edgent在达到应用程序相应需求的基础上可以最大化推理精度。原型实现和基于树莓派、桌面PC的广泛评估证明了Edgent在按需实现低延迟边缘智能方面的有效性。
To summarize, we present the contribution of this paper as follows:
综上所述,本文的贡献如下:
• We propose Edgent, a framework for on-demand DNN collaborative inference through device-edge synergy, in which we jointly optimize DNN partitioning and DNN right-sizing to maximize the inference accuracy while promising application latency requirement.
我们提出了Edgent,一个通过设备-边缘协同作用,按需DNN协同推理框架,我们协同优化了DNN划分和DNN合理规模取在达到应用程序延迟响应的基础上最大化精度。
• Considering the versatile network environments (i.e.,static network environment and dynamic network environment), we specialize the workflow design for Edgent to achieve better performance.
考虑到多样的网络环境(静态网络环境和动态网络环境),我们对Edgent的工作流程设计了定制配置机制以达到更好的性能。
• We implement and experiment Edgent prototype with a Raspberry Pi and a desktop PC. The evaluation results based on the real-world network trace dataset demonstrate the effectiveness of the proposed Edgent framework.
我们通过树莓派和桌面PC实现和实验了Edgent原型。基于真实网络跟踪数据集的评价结果验证了该框架的有效性。
The rest of this paper is organized as follows. First, we review the related literature in Sec. II and present the background and motivation in Sec. III. Then we propose the design of Edgent in Sec. IV. The results of the performance evaluation are shown in Sec. V to demonstrate the effectiveness of Edgent. Finally, we conclude in Sec. VI.
本文的其余部分组织如下。首先,我们在第二节回顾了相关文献,并在第三节介绍了背景和动机。然后我们在第四章提出了Edgent的设计。性能评价的结果在第五章中展示,以证明Edgent的有效性。最后,我们在第六节结束。
这篇文章介绍自己做啥了?
它说自己构建了一个结构叫Edgent。
Edgent联合优化了DNN划分和DNN合理规模,对于任务关键型应用程序,通常有预定义延迟的需求,在保证预定义延迟需求的同时保证了精度最大化。
Edgent还进一步开发了定制配置机制,可以在静态网络环境和动态网络环境中都能追求更好的性能。
最后做了基于树莓派和PC的仿真工作。
二、相关工作
Discussions on the topic of mobile DNN computation have recently obtained growing attention. By hosting artificial intelligence on mobile devices, mobile DNN computation deploys
DNN models close to users in order to achieve more flexible execution as well as more secure interaction [15]. However, it is challenging to directly execute the computation-intensive DNNs on mobile devices due to the limited computation resource. On this issue, existing efforts dedicate to optimize the DNN computation on edge devices.
近年来,关于移动DNN计算的讨论越来越受人们的关注。通过在移动设备上安放人工智能,移动DNN计算将DNN模型部署在更靠近用户的位置,是为了实现更灵活的执行和更安全的交互[15]。然而,由于计算资源受限,直接在移动设备上执行计算密集型DNN是有很大挑战性的。为了解决这个问题,现在努力致力于在边缘设备上执行DNN计算。
Towards low-latency and energy-efficient mobile DNN computation, there are mainly three ways in the literature: runtime management, model architecture optimization and hardware acceleration. Runtime management is to offload computation from mobile devices to the cloud or the edge server, which utilizes external computation resource to obtain better performance. Model architecture optimization attempts to develop novel DNN structure so as to achieve desirable accuracy with moderate computation [17]–[21]. For example, aiming at reducing resource consumption during DNN computation, DNN models are compressed by model pruning [22]–[24]. Recent advance in such kind of optimization has turned to Network Architecture Search (NAS) [25]–[27]. Hardware acceleration generally embraces basic DNN computation operations in hardware level design [28]–[30] while some works aim at optimizing the utilization of the existing hardware resources[31]–[33].
面向低延迟和能效高的移动DNN计算,在文献中主要有三种方式:运行时间管理、模型结构优化和硬件加速。运行时间管理是将计算从移动设备卸载到云或边缘服务器,利用外部的计算资源取得到更好的性能。模型结构优化试图取开发新的DNN结构以达到理想的精度[17]-[21]。比如,为了减少在DNN计算中的资源消耗,对DNN模型进行了剪枝压缩。这类优化的最新进展已经转向了网络架构搜索(NAS)[25]-[27]。硬件加速在硬件级设计[28]-[30]中通常包含基本的DNN计算操作,也有一些操作目的是优化现有硬件资源的利用率[31]-[33]。
As one of the runtime optimization methods, DNN partitioning technology segments specific DNN model into some successive parts and deploys each part on multiple participated devices. Specifically, some frameworks [34]–[36] take advantage of DNN partitioning to optimize the computation offloading between the mobile devices and the cloud, while some framework target to distribute computation workload among mobile devices [37]–[39]. Regardless of how many devices are involved, DNN partitioning dedicates to maximize the utilization of external computation resources so as to accelerate the mobile computation. As for DNN right-sizing, it focuses on adjusting the model size under the limitation of the existing environment. On this objective, DNN right-sizing appeals to specialized training technique to generate the deuterogenic branchy DNN model from the original standard DNN model. In this paper, we implement the branchy model with the assist of the open-source BranchyNet [40] framework and Chainer [41] framework.
作为运行时间优化的方法之一,他将特定的DNN模型分段成一些连续的部分,并将每个部分部署在多个参与的设备上。具体来说,一些框架[34]-[36]利用DNN分区在移动设备和云之间来优化计算卸载,同时一些框架目标是在移动设备之间分配计算卸载[37]-[39]。不管有多少设备,DNN分区都致力于最大化外部计算资源的利用率来加速移动计算。DNN合理规模致力于在现存环境的限制下调整模型大小。基于这一目标,DNN合理规模需要通过专门的训练技术从原有标准的模型上来产生衍生分枝DNN模型。在这篇文章中,我们借助开源的BranchyNet框架[40]和Chainer框架[41]来实现分枝模型。
Compared with the existing work, the novelty of our framework is summarized in the following three aspects. First of all, given the pre-defined application latency requirement, Edgent maximizes the inference accuracy according to the available computation resources, which is significantly different from the existing studies. This feature is essential for practical deployment since different DNN-based applications may require different execution deadlines under different scenarios. Secondly, Edgent integrates both DNN partitioning and DNN right-sizing to maximize the inference accuracy while promising application execution deadline. It is worth noting that neither the model partitioning nor the model right-sizing can well address the timing requirement challenge solely. For model partitioning, it does reduce the execution latency, whereas the total processing time is still restricted by the part on the mobile device. For model right-sizing, it acceleratesthe inference processing through the early-exit mechanism, but the total computation workload is still dominated by the original DNN model architecture and thus it is hard to finish the inference before the application deadline.
与现存的工作相比,我们设计的架构的创新点有以下三个方面。首先,在给定预定义应用程序延迟要求的情况下,Edgent根据可获得的计算资源最大化推理精度,这和现有的工作明显不同。这个特点对实际部署非常重要,因为不同的基于DNN的应用程序模型在不同的环境下可能有不同的执行期限。第二,Edgent在给定应用程序执行期限的情况下,联合优化DNN模型划分和DNN合理规模以最大化推理的准确性。值得注意的是单独优化模型分割或模型合理规模都不可以很好地解决时间需求问题。对于模型划分来说,它减少了推理时延,但是但是总的执行时间仍受限于在移动设备上执行的那部分。对于模型合理规模来说,它通过提前退出机制加速推理进程,但是总计算工作量仍受限于原始DNN模型结构,并且很难在有应用程序时限之内完成推理任务
Therefore, we propose to integrate these two approaches to expand the design space. The integration of model partitioning and model right-sizing is not a one-step effort, and we need to carefully design the decision optimization algorithms to fully explore the selection of the partition point and the exiting point and thus to strike a good balance between accuracy and latency in an on-demanded manner. Through these efforts, we can achieve the design target such that given the predefined latency constraint, the DNN inference accuracy is maximized without violating the latency requirement. Last but not least, we specialize the design of Edgent for both static and dynamic network environments while existing efforts (e.g., [38]) mainly focus on the scenario with stable network. Considering the diverse application scenarios and deployment environments in practice, we specialize the design of the configurator and the runtime optimizer for the static and dynamic network environments, by which Edgent can generate proper decisions on the exit point and partition point tailored to the network conditions.
因此,我们提出将两种方法结合起来以提高设计空间。模型划分和模型合理规划的结合不能一步到位,我们应该小心的设计决策优化算法来完全探索模型划分点和推出点,并且以按需的方式在精度和延迟之间找到一个平衡。通过这些努力,我们可以达到设计目标,在给定的延迟约束下,可以在不违延迟需求的情况下,最大化DNN推理精度。最后一点,我们为静态和动态的网络环境进行了定制设计,而现有的工作都是假设稳定的网络(比如[38])。考虑到实际中各种各样的应用场景和配置环境,我们针对动态场景和静态场景的配置器和运行时间优化器进行了专门的设计,使Edgent能够根据网络环境,对划分点和推出点做出更优的决策。
面向低延迟和能效高的移动DNN计算,在文献中主要有三种方式:运行时间管理、模型结构优化和硬件加速。分别介绍了一些写这方面知识的文献
本文的创新点是:联合优化模型划分和模型合理规模,优化其中一点不能达到目的。还分别对动态和静态网络环境下的配置器和运行时间优化器进行了专门的设计。
三、背景和动机
In this section, we first give a brief introduction on DNN. Then we analyze the limitation of edge- or device-only methods, motivated by which we explore the way to utilize DNN partitioning and right-sizing to accelerate DNN inference with device-edge synergy.
在这一章节中,我们首先对DNN进行了简要的介绍。然后我们分析了仅边缘和仅设备方式的局限性,在此基础上,我们探讨了如何利用DNN划分和适当调整尺寸来加速设备-边缘协同的DNN推理。
A、对DNN的简要说明
With the proliferation of data and computation capability, DNN has served as the core technology for a wide range of intelligent applications across Computer Vision (CV) [2] and Natural Language Processing (NLP) [4]. Fig. 1 shows a toy DNN for image recognition that recognizes a cat. As we can see, a typical DNN model can be represented as a directed graph, which consists of a series of connected layers where neurons are connected with each other. During the DNN computation (i.e., DNN training or DNN inference), each neuron accepts weighted inputs from its neighborhood and generates outputs after some activation operations. A typical DNN may have dozens of layers and hundreds of nodes perlayer and the total number of parameters can easily reach to the millions level, thus a typical DNN inference demands a large amount of computation. In this paper, we focus on DNN inference rather than DNN training since the training process is generally delay-tolerant and often done offline on powerful cloud datacenters.
随着数据和计算能力的增长,DNN被看作是计算技视觉[2]、自然语言进程(NLP)[4]等广泛的智能应用的核心技术。图一展示了一个用于猫的图像识别的简单的DNN。我们可以看出,典型的DNN模型可以用有向图来表示,这个有向图由一系列的连接层来表示,在这些层中,神经元互相连接。在DNN计算(比如DNN训练或DNN推理)过程中,每个神经元从其邻域接受加权输入,在经过一些激活操作后产生输出。一个典型的DNN可能有数十层,每层有数十个节点,总参数可能达到百万级别,所以一个典型的DNN需要大量的计算。在这篇文章里,我们致力于DNN推理而不是DNN训练,因为训练过程通常可以容忍延迟的并且是在计算能力强大的云数据中心离线执行。

B、仅设备或仅边缘的DNN推理缺陷
Traditional mobile DNN computation is either solely performed on mobile devices or wholly offloaded to cloud/edge servers. Unfortunately, both approaches may lead to poor performance (i.e., high end-to-end latency), making it difficult to meet real-time applications latency requirements [10]. For illustration, we employ a Raspberry Pi and a desktop PC to emulate the mobile device and edge server respectively, and perform image recognition task over cifar-10 dataset with the classical AlexNet model [42]. Fig. 2 depicts the end-to-end latency subdivision of different methods under different bandwidths on the edge server and the mobile device (simplified as Edge and Device in Fig. 2). As shown in Fig. 2, it takes more than 2s to finish the inference task on a resource constrained mobile device. As a contrast, the edge server only spends 0.123s for inference under a 1Mbps bandwidth. However, as the bandwidth drops, the execution latency of the edge-only method climbs rapidly (the latency climbs to 2.317s when the bandwidth drops to 50kbps). This indicates that the performance of the edge-only method is dominated by the data transmission latency (the computation time at server side remains at ∼10ms) and is therefore highly sensitive to the available bandwidth. Considering the scarcity of network bandwidth resources in practice (e.g., due to network resource contention between users and applications) and the limitation of computation resources on mobile devices, device- and edge-only methods are insufficient to support emerging mobile applications in stringent real-time requirements.
传统的移动DNN计算不是仅在移动终端计算就是完全卸载到云/边缘服务器上。不幸的是,两种方式都可能导致较差的性能(高端到端的延迟),这很难满足实时应用的延迟需求。为了说明这一点,我们使用树莓派和桌面PC分别模拟移动设备和边缘服务器,并使用经典的AlexNet模型[42]在ciremote -10数据集上执行图像识别任务。图2描述了在边缘服务器和移动设备上不同带宽下不同方法的端到端时延细分(图2将仅边缘和仅设备简化成边缘和设备)。如图2所示,在资源受限的移动设备至少需要2秒来完成模型推理。相比之下,边缘层在1Mbps的带宽下只花了0.123秒。然而,随着带宽的下降,仅边缘方法的执行延迟迅速上升(当带宽降到50bps时延迟上升到了2.317s)。这表明仅边缘方法的性能受数据传输延迟的限制(服务端的计算时间保持在10毫秒)。考虑到实际中缺少带宽资源(比如用户与应用程序之间抢夺带宽资源)和移动设备计算资源的限制,仅设备或仅边缘方法不足以支撑新型的对实时性有严格要求的应用程序。

C、面向边缘智能的DNN分区和DNN合理规模
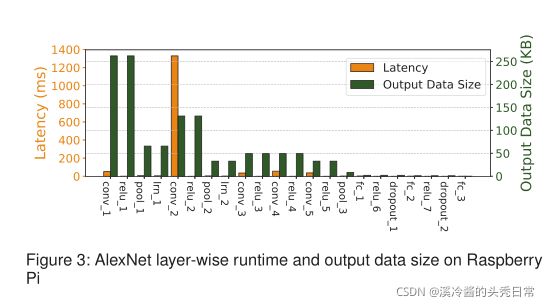
DNN Partitioning: To better understand the performance bottleneck of DNN inference, in Fig. 3 we refine the layer-wise execution latency (on Raspberry Pi) and the intermediate output data size per layer. Seen from Fig. 3, the latency and output data size of each layer show great heterogeneity, implying that a layer with a higher latency may not output larger data size. Based on this observation, an intuitive idea is DNN partitioning, i.e., dividing DNN into two parts and offloading the computation-intensive part to the server at a low transmission cost and thus reducing total end-to-end execution latency. As an illustration, we select the second local response normalization layer (i.e., lrn_2) in Fig. 3 as the partition point and the layers before the point are offloaded to the server side while the rest remains on the device. Through model partitioning between device and edge, hybrid computation resources in proximity can be in comprehensive utilization towards low-latency DNN inference.
DNN划分:为了更好的理解DNN推理性能上的瓶颈,图3我们细化了层延迟(在树莓派上)和每层的中间数据输出大小。如图3我们可以看出每层的延迟和输出数据大小都有很大的差异性,这意味着延迟越大的层输出数据的大小不一定大。基于这个观察结果,一种直观的思想就是DNN划分,将DNN分成两部分,将计算密集的那部分以低的传输开销卸载到服务器,这样可以减少总体的端到端执行延迟。作为说明,我们选用图3中的第二个本地响应归一化层(即Irn_2)作为划分点,并将该点和之前的层卸载到服务器端而其余部分留在设备上。通过在设备和边缘之间的模型划分,综合利用邻近的混合计算资源,实现低时延DNN推断。
DNN Right-Sizing: Although DNN partitioning can significantly reduce the latency, it should be noted that with the optimal DNN partitioning, the inference latency is still constrained by the remaining computation on the mobile device. To further reduce the execution latency, the DNN right-sizing method is employed in conjunction with DNN partitioning. DNN right-sizing accelerates DNN inference through the early-exit mechanism. For example, by training DNN models with multiple exit points, a standard AlexNet model can be derived as a branchy AlexNet as Fig. 4 shows, where a shorter branch (e.g., the branch ended with the exit point 1) implies a smaller model size and thus a shorter runtime. Note that in Fig. 4 only the convolutional layers (CONV) and the fully connected layers (FC) are drawn for the ease of illustration. This novel branchy structure demands novel training methods. In this paper, we implement the branchy model training with the assist of the open-source BranchyNet [40] framework.
DNN合理规模:尽管DNN划分可以显著降低时延,但需要注意的是,在最优DNN划分下,推理延迟仍受到移动设备上剩余计算的限制。为了进一步降低执行时延,将DNN合理规模与DNN分区结合起来。DNN合理规模通过提前退出机制来达到加速DNN推理的目的。举个例子,通过训练具有多个出口的DNN模型,一个标准的AlexNet模型能够派生为如图4所示的AlexNet分支,其中更短一点的分支(比如以出口1结束的分支)意味着更小的模型大小和更短的运行时间。请注意,为了便于分析图4仅列出了卷积层和全连接层。这种新颖的分支结构需要新颖的训练方法。在这篇文章中,我们在开源BranchyNet框架的帮助下实现了分支模型的训练 。

Problem Definition: Clearly, DNN right-sizing leads to a latency-accuracy tradeoff, i.e., while the early-exit mechanism reduces the total inference latency, it hurts the inference accuracy. Considering the fact that some latency sensitive applications have strict deadlines but can tolerate moderate precision losses, we can strike a good balance between latency and accuracy in an on-demand manner. In particular, given the pre-defined latency requirement, our framework should maximize accuracy within the deadline. More precisely, the problem addressed in this paper can be summarized as how to make a joint optimization on DNN partitioning and DNN right-sizing in order to maximize the inference accuracy without violating the pre-defined latency requirement
问题定义:显然,DNN合理规划导致了延迟-准确性权衡,当提前退出机制减少总的推理时延,它也降低了推理的准确性。考虑到一些延迟敏感型应用程序有严格的延迟期限但是能够忍受适度的精度缺失,我们可以以按需方式在延迟和精度上有一个很好的权衡。特别是,给定预先定义的延迟需求,我们的框架应该在延迟时间内内最大化准确性。更准确地说,本文要解决的问题可以总结为:在唯有违背实验要求的前提下,通过联合优化DNN划分和DNN合理规划来最大化推理精度。
AlexNet的结构和特点:

四、框架与设计
In this section, we present the design of Edgent, which generates the optimal collaborative DNN inference plan that maximizes the accuracy while meeting the latency requirement in both the static and dynamic bandwidth environment.
在这一章节,我们提出了Edgent,它可以生成最优的协作DNN推理方案,无论是在静态网络环境还是在动态网络环境都可以在达到时延需求的基础上,最大化推理精度。
A、框架概述
Edgent aims to pursue a better DNN inference performance across a wide range of network conditions. As shown in Fig. 5, Edgent works in three stages: offline configuration stage, online tuning stage and co-inference stage.
Edgent目的是在广泛的网络环境中追求一个更好的DNN推理性能。如图5展示的那样,Edgent有3各阶段分别是:离线配置阶段、在线调优阶段和协同推理阶段。

At the offline configuration stage, Edgent inputs the employed DNN to the Static/Dynamic Configurator component and obtains the corresponding configuration for online tuning. To be specific, composed of trained regression models and branchy DNN model, the static configuration will be employed where the bandwidth keeps stable during the DNN inference
(which will be detailed in Sec. IV-B), while composed of the trained branchy DNN and the optimal selection for different bandwidth states, the dynamic configuration will be used adaptive to the state dynamics (which will be detailed in Sec.IV-C).
在离线配置阶段,Edgent将所使用的DNN配置到静态/动态网络配置器组件上,并且获得相应的配置进行在线调优。具体来说,由训练过的回归模型和分支DNN模型组成的静态配置将在DNN推断过程中带宽趋于稳定的环境中使用(具体细节将在第四章的B段介绍)。由训练过的分支DNN模型和不同带宽状态的最佳选择组成的动态配置将会去自适应动态状态(具体细节会在第四章C段介绍)。
At the online tuning stage, Edgent measures the current bandwidth state and makes a joint optimization on DNN partitioning and DNN right-sizing based on the given latency requirement and the configuration obtained offline, aiming at maximizing the inference accuracy under the given latency requirement.
在线上调优阶段,Edgent测量当前的带宽状态,根据给定的延迟需求和在离线状态下得到的配置,联合优化DNN划分和DNN合理规模,目的是在给定的延迟需求下获得最大的推理精度。
At the co-inference stage, based on the co-inference plan (i.e., the selected exit point and partition point) generated at the online tuning stage, the layers before the partition point will be executed on the edge server with the rest remaining on the device.
在协同推理阶段,基于在线调优环节产生的协同推理计划(选出退出点和划分点),在划分点之前的层会在边缘服务器执行,剩下的继续在终端设备执行。
During DNN inference, the bandwidth between the mobile device and the edge server may be relatively stable or frequently changing. Though Edgent runs on the same workflow in both static and dynamic network environments, the function of Configurator component and Runtime Optimizer component differ. Specifically, under a static bandwidth environment, the configurator trains regression models to predict inference latency and the branchy DNN to enable early-exit mechanism. The static configuration generated offline includes the trained regression models and the trained branchy DNN, based on which the Runtime Optimizer will figure out the optimal co-inference plan. Under a dynamic bandwidth environment, the dynamic configurator creates a configuration map that records the optimal selection for different bandwidth state via the change point detector, which will then be input to the Runtime Optimizer to generate the optimal co-inference plan. In the following, we will discuss the specialized design of the configurator and optimizer for the static and dynamic environments, respectively.
在DNN推理中,移动设备和边缘服务器之间的带宽可能相对稳定也可能频繁变化。虽然Edgent在静态或动态的网络环境上都以相同的工作方式运行,但是它们的配置器组件和运行时间优化组件是不一样的。具体地说,在静态带宽环境下,配置器训练回归模型来预测推理时延并训练分支DNN去实现提前退出机制。离线生成的静态配置包括训练后的回归模型和训练后的分支DNN,运行时优化器将根据这些模型计算出最优的协同推断方案。在动态带宽环境下,动态配置器通过变更点检测器创建一个配置映射,该配置映射记录了对不同带宽状态的最优选择,然后将其输入到运行时优化器以生成最优协同推断计划。下面,我们将分别讨论静态环境和动态环境的配置器和优化器的专门设计。
B、静态环境下的Edgent
As a starting point, we first consider our framework design in the case of the static network environment. The key idea of the static configurator is to train regression models to predict the layer-wise inference latency and train the branchy model to enable early-exit mechanism. The configurator specialized for the static bandwidth environment is shown in Fig. 6.
作为起点,我们先考虑静态网络环境下的结构设计。静态配置器的关键是训练回归模型来预测每一层的推理时延,并且训练分支模型来实现提前退出机制。为静态带宽环境专门设计的配置器如图6所示。

At the offline configuration stage, to generate static configuration, the static configurator initiates two tasks: (1) profile layer-wise inference latency on the mobile device and the edge server respectively and accordingly train regression models for different kind of DNN layer (e.g., Convolution, Fully-Connected, etc.), (2) train the DNN model with multiple exit points via BranchyNet framework to obtain branchy DNN. The profiling process is to record the inference latency of each type of layers rather than that of the entire model. Base on the profiling results, we establish the prediction model for each type of layers by performing a series of regression models with independent variables shown in Table.I. Since there are limited types of layers in a typical DNN, the profiling cost is moderate. Since the layer-wise inference latency is infrastructure-dependent and the DNN training is application-related, for a specific DNN inference Edgent only needs to initialize the above two tasks for once.
在离线配置阶段,为了产生静态配置,静态配置器启动了两个任务:(1)分别在移动设备和边缘服务器上构建分层推理延迟,并据此训练不同类型的DNN层(如卷积、全连接等)的回归模型。(2)通过BranchyNet框架训练具有多个出口点的DNN模型,得到分支DNN。这个分析过程是记录每一种类型的层的推理延迟,而不是记录整个模型的。基于分析结果,我们通过表1中独立自变量的一系列回归模型,建立每种类型的层的预测模型。因为在一个典型DNN中有有限种层,分析的成本适中。因为分层推理延迟依赖于基础设施,而DNN训练是与应用程序相关的,因此对于特定的DNN推理仅需要初始化上述两个任务一次。

At the online tuning stage, using the static configuration (i.e., the prediction model and the branchy DNN), the Runtime Optimizer component searches the optimal exit point and partition point to maximize the accuracy while ensuring the execution deadline with three inputs: (1) the static configuration, (2) the measured bandwidth between the edge server andthe end device and (3) the latency requirement. The search process of joint optimization on the selection of partition
point and exit point is described in Algorithm 1. For a DNN model with M exit points, we denote that the branch of i-th exit point has Nilayers and Dpis the output of the p-th layer. We use the abvoe-mentioned regression models to predict the latency E Djof the j-th layer running on the device and the latency E Sjof the j-th layer running on the server. Under a certain bandwidth B, fed with the input data Input, we can calculate the total latency Ai,p by summing up the computation latency on each side and the communication latency for transferring input data and intermediate execution result. We denote p-th layer as the partition point of the branch with the i-th exit point. Therefore, p = 1 indicates that the total inference process will only be executed on the device side (i.e., E Sp= 0, Dp−1/B = 0, Input/B = 0) whereas p = Ni means the total computation is only done on the server side (i.e., E Dp= 0, Dp−1/B = 0). Through the exhaustive search on points, we can figure out the optimal partition point with the minimum latency of the i-th exit point. Since the model partitioning does not affect the inference accuracy, we can successively test the DNN inference with different exit layers (i.e., with different precision) and find the model with the maximum accuracy while satisfying the latency requirement at the same time. As the regression models for layer-wise latency prediction have been trained in advance, Algorithm 1 mainly involves linear search operations and can be completed very quickly (no more than 1ms in our experiment).
在在线调优阶段,使用静态配置(即预测模型和分支DNN),运行时间优化器组件搜索最优退出点和划分点,在保证三个输入的执行期限的同时,最大限度地来提高精度:(1)静态配置(2)边缘服务器和终端设备之间的带宽测量(3)延迟需要。在算法1中描述了搜索分割点和出口点选择的联合优化过程。一个有 个退出点的DNN模型,我们表示第
个退出点的DNN模型,我们表示第 个出口点的分支有
个出口点的分支有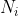 层,
层,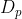 是第
是第 层的输出。我们使用上述回归模型来预测第
层的输出。我们使用上述回归模型来预测第 层运行在设备上的延迟
层运行在设备上的延迟![]() ,以及第层运行在服务器上的延迟
,以及第层运行在服务器上的延迟![]() 。在已经确定的带宽B下,以输入数据
。在已经确定的带宽B下,以输入数据![]() 为馈源,通过将每一边的计算延迟和传输输入数据的通信延迟以及中间的执行结果相加,我们可以计算得到总延迟
为馈源,通过将每一边的计算延迟和传输输入数据的通信延迟以及中间的执行结果相加,我们可以计算得到总延迟![]() 。我们将第层看作是带有第个出口点的分支的划分点。因此,
。我们将第层看作是带有第个出口点的分支的划分点。因此,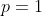 代表所有的推理进程只在终端设备进行(此时,
代表所有的推理进程只在终端设备进行(此时,![]() ,
,![]() ,
,![]() );当
);当![]() 时,所有的计算只在边缘服务器进行(此时,
时,所有的计算只在边缘服务器进行(此时,![]() ,
,![]() )。通过穷举搜索点,我们可以求出第i个出口点的延迟最小的划分点。因为模型划分不影响推理精度,我们能够依次用不同的出口层(即不同精度)来测试DNN推理进行测试,并且找到在满足延迟要求的同时找到精度最大的模型。由于用于预测每层延迟的回归模型已经提前训练好了,算法1主要包含线性搜索操作,完成速度非常快(在我们的实验中时间不超过1毫秒)。
)。通过穷举搜索点,我们可以求出第i个出口点的延迟最小的划分点。因为模型划分不影响推理精度,我们能够依次用不同的出口层(即不同精度)来测试DNN推理进行测试,并且找到在满足延迟要求的同时找到精度最大的模型。由于用于预测每层延迟的回归模型已经提前训练好了,算法1主要包含线性搜索操作,完成速度非常快(在我们的实验中时间不超过1毫秒)。

There are two basic assumptions for our design. One is that we assume the existing DNN inference on mobile devices cannot satisfy the application latency requirement and there is an edge server in proximity that is available to be employed to accelerate DNN inference through computation offloading. The other assumption is that the regression models for performance prediction are trained based on the situation that the computation resources for the DNN model execution on the mobile device and the edge server are fixed and allocated beforehand. Nevertheless, these assumptions can be further relaxed, since we can train more advanced performance prediction models (e.g., using deep learning models) by taking different resource levels into account.
在我们的设计里有两个基本假设,一个是我们假设了在移动设备上现有的DNN推理不能满足应用程序延迟的需要并且边缘服务器可以通过近似卸载加速DNN推理。另一个假设就是,对性能进行预测的回归模型是基于用于DNN模型的计算资源预先在边缘服务器和终端设备上固定和分配好的情况下进行训练的。尽管如此,这些假设可以进一步放宽,因为我们能通过考虑不同等级的资源来训练更先进的预测模型(比如使用深度学习模型)。
C、动态环境下的Edgent
The key idea of Edgent for the dynamic environment is to exploit the historical bandwidth traces and employ Configuration Map Constructor to generate the optimal co-inference plans for versatile bandwidth states in advance. Specifically, under the dynamic environment Edgnet generates the dynamic configuration(i.e., a configuration map that records the optimal selections for different bandwidth states) at the offline stage, and at the online stage Edgent searches for the optimal partition plan according to the configuration map. The configurator specialized for the dynamic bandwidth environment is shown in Fig. 7.
动态环境下的Edgent核心是利用历史带宽轨迹和配置映射构造器来提前生成动态带宽环境下的最优协同推理策略。具体来说,在动态环境下,Edgent在离线状态生成动态配置(一个记录不同带宽状态下的最优选择的配置图),并且在在线调优阶段,Edgent根据配置图搜索最有分区方案。专门为动态带宽环境设计的配置器如图7所示。

At the offline configuration stage, the dynamic configurator performs following initialization: (1) sketch the bandwidth states (noted as s1, s2,· · ·) from the historical bandwidth traces and (2) pass the bandwidth states, latency requirement and the employed DNN to the static Edgent to acquire the optimal exit point and partition point for the current input. The representation of the bandwidth states is motivated by the existing study of adaptive video streaming [43], where the throughput of TCP connection can be modeled as a piece-wise stationary process where the connection consists of multiple non-overlapping stationary segments. In the dynamic configurator, it defines a bandwidth states as the mean of the throughput on the client side in a segment of the underlying TCP connection. With each bandwidth state, we acquire the optimal co-inference plan by calling the Configuration Map Constructor and record that in a map as the dynamic configuration.
在离线配置阶段,动态配置器执行如下初始化:(1)根据历史带宽轨迹绘制带宽状态(记为s1,s2 ···)(2)将带宽状态、延迟需求和用到的DNN上传给静态Edgent来获得当前输入的最佳退出点和划分点。带宽状态的表示源于已有的自适应视频流的研究,其中TCP连接的吞吐量能被建模为一个分段平稳过程,其中连接由多个不重叠的稳定段组成。在动态配置器中,带宽状态被定义成一段底层TCP连接的客户端的吞吐量的平均值。对于每个带宽状态,我们通过调用配置映射构造函数来获得最优的协同推理策略并将其记录在映射中作为动态配置。
The configuration map construction algorithm run in Configuration Map Constructor is presented in Algorithm 2. The key idea of Algorithm 2 is to utilize the reward function to evaluate the selection of the exit point and partition point. Since our design goal is to maximize the inference accuracy while promising the application latency requirement, it is necessary to measure whether the searched co-inference strategy can meet the latency requirement and whether the inference accuracy has been maximized. Therefore, we define a reward to evaluate the performance of each search step as follow:
![]() (1)
(1)
在算法2中给出了在配置映射构造器中运行的配置映射构造函数。算法2的核心是利用奖励函数来评估退出点和划分点选择的好坏。因为我们的设计目标是在保证应用程序延迟需求的基础上最大化推理精度,这就有必要去衡量搜索的协同推理策略能不能满足延迟需求和能不能达到最大化推理精度。因此,我们定义了一个回报来评估每个搜索步骤的性能,如下:
![]() (1)
(1)
where tstep is the average execution latency in the current search step (i.e., the selected exit point and partition point in the current search step), which equals to throughput. The conditions of Equation (1) prioritizes that the latency requirement treq should be satisfied, otherwise the reward will be set as 0 directly. Whenever the latency requirement is met, the reward of the current step will be calculated as exp(acc)+throughput, where acc is the accuracy of current inference. If the latency requirement is satisfied, the search emphasizes on improving the accuracy and when multiple options have the similar accuracy, the one with the higher throughput will be selected. In Algorithm 2, si represents a bandwidth state extracted from the bandwidth traces and Cjis a co-inference strategy (i.e., a combination of exit point and partition point ) indexed by j. R(Cj) denotes the reward of the co-inference strategy Cj, which can be obtained by calculating Equation (1) according to the accuracy and the throughput of Cj.
其中![]() 是当前搜索步骤(当前搜索步骤所挑选的退出点和划分点)的平均执行延迟,相当于吞吐量的倒数
是当前搜索步骤(当前搜索步骤所挑选的退出点和划分点)的平均执行延迟,相当于吞吐量的倒数 ![]() 。根据式(1)的条件,应优先满足延迟需求
。根据式(1)的条件,应优先满足延迟需求![]() ,否则奖励直接设为0.当延迟要求被满足时,当前步骤的奖励可以设成
,否则奖励直接设为0.当延迟要求被满足时,当前步骤的奖励可以设成![]() ,其中
,其中![]() 是当前推理的精度。如果延迟需求被满足,搜索强调提升准确度,并且当多个选项具有相似的准确性时,选择吞吐量更大的那个。在算法2中,
是当前推理的精度。如果延迟需求被满足,搜索强调提升准确度,并且当多个选项具有相似的准确性时,选择吞吐量更大的那个。在算法2中,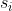 代表从历史带宽轨迹中提取出来的带宽状态,
代表从历史带宽轨迹中提取出来的带宽状态, 是由索引的协同推理策略(退出点和划分点的结合)。
是由索引的协同推理策略(退出点和划分点的结合)。![]() 表示协同推理策略策略的奖励值,根据精度
表示协同推理策略策略的奖励值,根据精度![]() 和策略 的吞吐量由计算公式(1)可得。
和策略 的吞吐量由计算公式(1)可得。

At the online tuning stage, the Runtime Optimizer component selects the optimal co-inference plan according to the dynamic configuration and real-time bandwidth measurements. Algorithm 3 depicts the whole process in Runtime Optimizer. Note that Algorithm 3 calls the change point detection function D(B1,···,t) [44] to detect the distributional state change of the underlying bandwidth dynamics. Particularly, when the sampling distribution of the bandwidth measurement has changed significantly, the change point detection function records a change point and logs a bandwidth state transition. Then with find(state) function, the Runtime Optimizer captures the corresponding co-inference strategy to the current bandwidth state (or the closest state) in the dynamic configuration and accordingly guides the collaborative inference process at the co-inference stage.
在线上调优阶段,运行时间优化器组件选择根据动态配置和实时带宽测量选择最优协同推理策略。算法3描述了运行时间优化器的整个进程。值得注意的是,算法3调用了变点检测函数![]() [44]来检测底层带宽动态的分布状态的变化。特别是当带宽测量的采样分布发生显著变化时,变点检测函数记录变化点和带宽状态转换。然后使用
[44]来检测底层带宽动态的分布状态的变化。特别是当带宽测量的采样分布发生显著变化时,变点检测函数记录变化点和带宽状态转换。然后使用 ![]() 函数,运行时间优化器捕获在动态配置中的当前的带宽状态(或者最近的状态)的相应的协同推理策略,并据此指导协同推理阶段的协同推理过程。
函数,运行时间优化器捕获在动态配置中的当前的带宽状态(或者最近的状态)的相应的协同推理策略,并据此指导协同推理阶段的协同推理过程。

五、性能评估
在本节中,我们将介绍我们的Edgent的实现和评估结果。
A、实验装置
We implement a prototype based on the Raspberry Pi and the desktop PC to demonstrate the feasibility and efficiency of Edgent. Equipped with a quad-core 3.40 GHz Intel processor and 8 GB RAM, a desktop PC is served as the edge server. Equipped with a quad-core 1.2 GHz ARM processor and 1 GB RAM, a Raspberry Pi 3 is used to act as a mobile device.
我们实现了一个基于树莓派和桌面PC的Edgent原型,以证明Edgent的可行性和有效性。搭载英特尔四核3.40 GHz处理器和8gb内存的台式电脑是边缘服务器。树莓派3配备了四核1.2 GHz ARM处理器和1gb RAM,可作为移动设备使用。
To set up a static bandwidth environment, we use the WonderShaper tool [45] to control the available bandwidth. As for the dynamic bandwidth environment setting, we use the dataset of Belgium 4G/LTE bandwidth logs [46] to emulate the online dynamic bandwidth environment. To generate the configuration map, we use the synthetic bandwidth traces provided by Oboe [43] to generate 428 bandwidth states range from 0Mbps to 6Mbps.
为了建立一个静态的带宽环境,我们使用WonderShaper工具来控制带宽。为了建立动态带宽环境,我们使用比利时4G/LTE带宽日志[46]数据集来模拟在线动态带宽环境。为了产生配置图,我们使用由Oboe提供的合成带宽轨迹来产生从0Mbps到6Mbps的428种带宽状态。
To obtain the branchy DNN, we employ BranchyNet [40] framework and Chainer [41] framework, which can well support multi-branchy DNN training. In our experiments we take the standard AlexNet [42] as the toy model and train the AlexNet model with five exit points for image classification over the cifar-10 dataset [47]. As shown in Fig. 4, the trained branchy AlexNet has five exit points, with each point corresponds to a branch of the standard AlexNet. From the longest branch to the shortest branch, the number of layers in each exit point is 22, 20, 19, 16 and 12, respectively.
为了获得分支DNN,我们采用BranchyNet框架和Chainer框架,这样可以很好地支持多分支DNN的训练。在我们的实验中采用标准AlexNet作为基本模型,在ciremote -10数据集[47]上训练带有5个出口点的AlexNet模型进行图像分类。如图4所示,经过训练的分支AlexNet有5个出口点,每个出口点对应标准AlexNet的一个分支。。从最长的分支到最短的分支,每个出口点的层数分别为22、20、19、16和12层。

B、静态带宽环境下的实验
In the static configurator, the prediction model for layer-wise prediction is trained based on the independent variables presented in Table. I. The branchy AlexNet is deployed on both the edge server and the mobile device for performance evaluation. Specifically, due to the high-impact characteristics of the latency requirement and the available bandwidth during the optimization procedure, the performance of Edgent is measured under different pre-defined latency requirements and varying available bandwidth settings.
在静态配置器,分层预测的预测模型主要是根据表一里的独立变量来训练的。对分支AlexNet部署在边缘服务器和终端上以进行更好的性能评估。具体来说,在优化过程中,由于延迟需求和可用带宽的高影响特性,Edgent的性能是在不同的预定义延迟需求和不同的可用带宽设置下测量的。
We first explore the impact of the bandwidth by fixing the latency requirement at 1000ms and setting the bandwidth from 50kbps to 1.5Mbps. Fig. 8(a) shows the optimal co-inference plan (i.e., the selection of partition point and exit point) generated by Edgent under various bandwidth settings. Shown in Fig. 8(a), as bandwidth increases, the optimal exit point becomes larger, indicating that a better network environment leads to a longer branch of the employed DNN and thus higher accuracy. Fig. 8(b) shows the inference latency change trend where the latency first descends sharply and then climbs abruptly as the bandwidth increases. This fluctuation makes sense since the bottleneck of the system changes as the bandwidth becomes higher. When the bandwidth is smaller than 250kbps, the optimization of Edgent is restricted by the poor communication condition and prefers to trade the high inference accuracy for low execution latency, for which the exit point is set as 3 rather than 5. As the bandwidth rises, the execution latency is no longer the bottleneck so that the exit point climbs to 5, implying a model with larger size and thus higher accuracy. There is another interesting result that the curve of predicted latency and the measured latency is nearly overlapping, which shows the effectiveness of our regression-based prediction. Next, we set the available bandwidth at 500kbps and vary the latency requirement from 1000ms to 100ms for further exploration. Fig. 8(c) shows the optimal partition point and exit point under different latency requirements. As illustrated in Fig. 8(c), both the optimal exit point and partition point climb higher as the latency requirement relaxes, which means that a later execution deadline will provide more room for accuracy improvement.
我们通过将延迟需求固定在1000毫秒和将带宽设定在50Kbps到15Mpbs来探索带宽的影响。图8(a)展示了当Edgent在不同带宽设置下产生的最优协同推理策略(选择划分点和退出点)。如图8(a)所示,随着带宽的增长,最优退出点变大,这表示网络环境越好,所采用的DNN的分支越长,精度越高。图8(b)为推理延迟变化趋势,随着带宽的上升,延迟先急剧下降,然后再上升。这种波动是说得通的,因为系统的瓶颈会随着带宽的增加而变化。当带宽比250kbps小的时候,Edgent受到通信条件差的限制,倾向于以高推理精度来换取低执行延迟,因此退出点设为3而不是5 。随着带宽的增加,推理延迟不再是瓶颈,所以退出点涨到5,这意味着模型规模更大了精度也更高了。这里有另一个有趣的结果是预测延迟的曲线和测量延迟的曲线几乎重叠。另外,我们将可用带宽设置在500Kbps,并将延迟要求调整到1000ms到100ms以进行进一步的探索。图8(c)展示了在不同延迟需求下带宽最佳划分点和最佳退出点。对图8(c)进行分析,随着延迟需求的放松,最佳退出点和划分点都在增大,这意味着延迟截止时间越长,精度提升的空间越大。

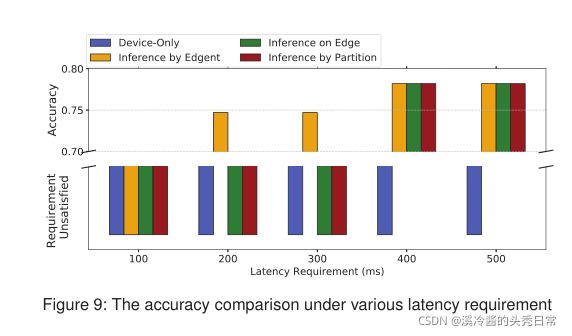
Fig. 9 shows the model inference accuracy of different methods under different latency requirement settings (the bandwidth is fixed as 400Kbps). The accuracy is described in negative when the method cannot satisfy the latency requirement. As Fig. 9 shows, given a tightly restrict latency requirement (e.g., 100ms), all the four methods fail to meet the requirement, for which all the four squares lay below the standard line. However, as the latency requirement relaxes, Edgent works earlier than the other three methods (at the requirements of 200ms and 300ms) with the moderate loss of accuracy. When the latency requirement is set longer than 400ms, all the methods except for device-only inference successfully finish execution in time.
图9给出了不同延迟需求设置(带宽固定为400kbps)下不同方法的模型推理精度。当该方法不能满足延迟要求时,准确度为负值。如图9所示,当给出一个非常严格的延迟时间(比如100毫秒),四种方法都不能满足需求,因为四个柱形都位于标准线的下方。然而,随着延迟时间的放宽,Edgent比其他方法工作的要早(在延迟需求是200毫秒~300毫秒之间的时候),精度损失更小。当延迟需求放宽到400毫秒时,所有的方法除了仅设备推理都可以在规定时间内执行完任务。
C、动态带宽环境下的实验
For the configuration map generation, we use the bandwidth traces provided in Oboe [43]. Each bandwidth trace in the dataset consists of 49 pairs of data tuple about download chunks, including start time, end time and the average bandwidth. We calculate the mean value of all the average bandwidth in the same bandwidth trace to represent the bandwidth state fluctuation, from which we obtain 428 bandwidth states range from 0Mbps to 6Mbps. According to the Algorithm 2, through the exhaustive search, we figure out the optimal selection of each bandwidth state. The latency requirement in this experiment is also set to 1000ms.
为了产生配置图,我们使用Oboe提供的带宽轨迹。数据集中的每个带宽轨迹由49对关于下载块的数据元组组成,包括开始时间、结束时间和平均带宽。我们在同一带宽轨迹中计算所有平均带宽的平均值来表示带宽波动,从0Mbps~6Mbps我们选出428个带宽状态。根据算法2,通过穷举搜索,我们找出每个带宽状态的最优选择。实验时我们仍将延迟需求设置在1000毫秒。
For online change point detection, we use the existing implementation [48] and integrate it with the Runtime Optimizer. We use the Belgium 4G/LTE bandwidth logs dataset [46] to perform online bandwidth measurement, which records the bandwidth traces that are measured on several types of transportation: on foot, bicycle, bus, train or car. Additionally, Since that most of the bandwidth logs are over 6Mbps and in some cases even up to 95Mbps, to adjust the edge computing scenario, in our experiment, we scale down the bandwidth of the logs and limit it in a range from 0Mbps to 10Mbps.
对于变点检测,我们使用现有设施[48]并和运行时间优化器结合起来。我们使用比利时4G/LTE带宽记录数据集[46]进行在线带宽测量,它记录了在几种不同的交通工具上测量的带宽轨迹:走路、自行车、公交车、火车或汽车。此外,因为大多数带宽记录超过6Mbps,一些甚至达到了95Mbps,为了调整边缘计算的假设,我们将带宽记录缩小到0Mbps~6Mbps。
In this experiment Edgent runs in a dynamic bandwidth environment emulated by the adjusted Belgium 4G/LTE bandwidth logs. Fig. 10(a) shows an example bandwidth trace on the dataset that is recorded on a running bus. Fig. 10(b) shows the DNN model inference throughput results under the bandwidth environment showed in Fig. 10(a). The corresponding optimal selection of the exit point and partition point is presented in Fig. 10(c). Seen from Fig. 10(c), the optimal selection of model inference strategy varies with the bandwidth changes but the selected exit point stays at 5, which means that the network environment is good enough for Edgent to satisfy the latency requirement though the bandwidth fluctuates. In addition, since the exit point remains invariable, the inference accuracy also keeps stable. Dominated by our reward function design, the selection of partition points approximately follows the traces of the throughput result. The experimental results show the effectiveness of Edgent under the dynamic bandwidth environment.
在这个实验里,Edgent运行在一个由调整后的比利时4G/LTE带宽记录模拟的动态的带宽环境中。图10(a)是在运动的公交车上记录的数据集上的带宽轨迹示例。图10(b)是在图10(a)所示的带宽环境下的DNN模型推理吞吐量结果。图10(c)是相应的退出点和划分点的最优选择结果。从图10(c)可以看出,在带宽变化的环境中,模型推理决策的最优选择多种多样但退出点保持在5,这意味着尽管带宽发生波动,但网络环境足够好,使得Edgent能够满足延迟需求。此外,因为退出点保持不变,推理精度也保持稳定。在奖励函数设计的主导下,划分点的选择大致遵循吞吐量结果的轨迹。实验结果表明了Edgent在动态带宽环境下的有效性。

We further compare the static configurator and the dynamic configurator under the dynamic bandwidth environment in Fig. 11. We set the latency requirement as 1000ms and record the throughput and the reward for the two configurators, base on which we calculate the Cumulative Distribution Function (CDF). Seen from Fig. 11(a), under the same CDF level, Edgent with the dynamic configurator achieves higher throughput, demonstrating that under the dynamic network environment the dynamic configurator performs co-inference with higher efficiency. For example, set CDF as 0.6, the dynamic configurator makes 27 FPS throughput while the static configurator makes 17 FPS. In addition, the CDF curve of dynamic configurator rises with 11 FPS throughput while the static configurator begins with 1 FPS, which indicates that the dynamic configurator works more efficiently than the static configurator at the beginning.
我们在如图11所示的动态带宽环境下,进一步对比静态配置器和动态配置。我们将延迟设置在1000毫秒并且记录两种配置器的吞吐量和奖励,以此计算累积分布函数(CDF)。如图11(a)所示,在相同的CDF级别下,有动态配置器的Edgent有更高的吞吐量,说明在动态网络的环境下,动态配置器有更高的协同推理效率。比如,将CDF设置在0.6时,动态配置器的吞吐量为27FPS,而静态配置器的吞吐量为17FPS。此外,动态配置器的CDF曲线以11FPS的吞吐量上升,而静态配置器的CDF曲线以1FPS的吞吐量开始,说明动态配置器的工作效率高于静态配置器的工作效率。
累积分布函数(Cumulative Distribution Function),又叫分布函数,是概率密度函数的积分,能完整描述一个随机变量X的概率分布。
Fig. 11(b) presents the CDF results of reward. Similarly, under the same CDF level, the dynamic configurator acquires higher reward than the static configurator and the CDF curve of the dynamic configurator rises latter again. However, in Fig. 11(b) the two curves is closer than in Fig. 11(a), which means that the two configurators achieve nearly the same good performance from the perspective of reward. This is because the two configurators make similar choices in the selection of exit point (i.e., in most cases both of them select exit point 5 as part of the co-inference strategy). Therefore the difference of the reward mainly comes from the throughput result. It demonstrates that the static configurator may perform as well as the dynamic configurator in some cases but the dynamic configurator is better in general under the dynamic network environment.
图11(b)展示了奖励的CDF结果。相似的,在同样的CDF等级下,动态配置器比静态配置器有更高的回报并且动态配置器的曲线在后期仍然上升。然而,在图11(b)中两条曲线比在图11(a)中更相近,这意味着从奖励的角度来看,两个配置者的表现几乎相同。这是因为两个配置器在选择出口点时做出了类似的选择(即,在大多数情况下,它们都选择出口点5作为协同推断策略的一部分)。因此,经奖励的不同主要是因为吞吐量大小的不同。这说明在某些情况下,静态配置器的性能可以和动态配置器一样好,但在动态网络环境下,动态配置器的性能通常更好。

六、结论
In this work, we propose Edgent, an on-demand DNN co-inference framework with device-edge collaboration. Enabling low-latency edge intelligence, Edgent introduces two design knobs to optimize the DNN inference latency: DNN partitioning that enables device-edge collaboration, and DNN right-sizing that leverages early-exit mechanism. We introduce two configurators that are specially designed to figure out the collaboration strategy under static and dynamic bandwidth environments, respectively. Our prototype implementation and the experimental evaluation on Raspberry Pi shows the feasibility and effectiveness of Edgent towards low-latency edge intelligence. For the future work, our proposed framework can be further combined with existing model compression techniques to accelerate DNN inference. Besides, we can extend our framework to support multi-device application scenarios by designing efficient resource allocation algorithms. We hope to stimulate more discussion and efforts in the society and fully realize the vision of edge intelligence.
在这项工作里,我们提出了Edgent,一个设备-边缘协作的按需DNN协同推理框架。为了支持低延迟边缘智能,Edgent介绍了两个技术关键来优化DNN推理延迟:让设备-边缘协作的DNN划分以及利用提早退出机制实现DNN合理规划。我们介绍了两个配置器,分别用于计算静态和动态带宽环境下的协作策略。我们的原型实现和在Raspberry Pi上的实验评估表明了edge在低延迟边缘智能方面的可行性和有效性。在未来的工作里,我们可以进一步结合现有的模型压缩技术来加速DNN推理。此外,通过设计高效的资源分配算法,我们可以将框架扩展到支持多设备应用场景。我们希望在社会上引发更多的讨论和努力,充分实现边缘智能的愿景。
总结:
