面试无忧:源码+实践,讲到MySQL调优的底层算法实现
面试无忧:源码+实践,讲到MySQL调优的底层算法实现 2020-11-30 10:40·代码熬夜敲 不知道大家有没有参与过系统重构或者代码调优的工作,有幸,最近我接触了一个公司N久前的一个项目的重构工作,目的就是为了提升一下响应速度,然后我们小组拿到这个项目的源代码之后,大呼:WC,这NM谁写的代码啊,太不讲究了吧,这SQL都写了些什么玩意啊,其实在这些年的工作中,这样的问题已经不是第一次遇见了,老是被提需求说性能有问题,拿到代码之后发现问题很简单,90%都是SQL的问题,当时赶进度,能查询出来结果就可以,稍微一优化SQL性能就能提升很多,虽然现在有很多SQL审核平台,但是,在面试的过程中,需要你回答的更加深入一些,那这里,我就结合代码给你讲解到算法的层次,在遇到优化,不在惧怕任何挑战 SQL优化基础概念 说到SQL优化,大家首先想到的就是创建索引,但创建索引需要了解相关基础概念。 1. 索引 我们知道,MySQL中的索引通常采用B-Tree结构,那么首先就要清楚B-Tree和B+Tree 结构的区别

在InnoDB中索引是B+Tree结构的,在该结构中叶子节点包含了非叶子节点的所有数据,并且叶子节点之间会通过指针连接。 之所以采用B+Tree结构,是因为数据库中有>、<、between … and这类范围查询语句,直接扫描叶子节点即可。 2. 聚集索引(主键索引) InnoDB的所有的表都是索引组织表,主键与数据存放在一起。InnoDB选择聚集索引遵循以下原则: • 在创建表时,如果指定了主键,则将其作为聚集索引。 • 如果没有指定主键,则选择第一个NOT NULL的唯一索引作为聚集索引。 • 如果没有唯一索引,则内部会生成一个6字节的rowid作为主键。 聚集索引是将主键与行记录存储在一起的,当根据主键进行查询时, 可直接在表中获取到数据,不用回表查询。

3. 二级索引(也称辅助索引) 二级索引的叶子节点存储了索引值+rowid(主键值)。熟悉MySQL 的读者在MySQL中创建表时最好自己指定一个显式的自增主键,这样做的好处是:显式指定的主键可以是普通的int类型,这样存储的空间就是4字节,在二级索引的叶子节点中存储主键值所占用的空间就会变小。这时可能有人会问:二级索引的叶子节点为何不存储主键的指针呢?原因是:如果主键位置发生了变化,则需要修改二级索引的叶子节点对应存储的指针;但是如果二级索引的叶子节点本身存储的是主键的值,则不会出现这种情 况。

4. 基数、选择性、回表 • 基数是字段distinct后的值,主键或非NULL的唯一索引的基数等于表的总行数。 • 选择性是指基数与总行数的比值乘以100%,选择性通常表示在字段上是否适合创建索引。 • 当要查询的字段不能在索引中完全获得时,则需要回表查询取出所需要的数据。这几点很重要,因为SQL优化最重要的就是要减少SQL语句的扫描行数,看下面这个例子。 mysql> create table t1 (id int , cl char(20),c2 chaz(20),c3 char(20)) ; Query OK,0 rows affected (0.02 sec) mysql> insert into t1 values (10,'a','b', 'C'); Query OK,1 row affected (0.01 sec) mysql> insert into t1 values (10,'a','b', 'c'); Query OK,1 row affected (0.01 sec) mysql> insert into t1 values (10,'a', 'b' , 'c'); Query OK,1 row affected (0.01 sec) mysql> insert into t1 values (10,'a','b', 'c'); Query OK, 1 row affected (0.01 sec) mysql> insert into t1 values (10,'a', 'b', 'c'); Query OK, 1 row affected (0.01 sec) mysql> insert into t1 values (10,'a', 'b', 'c'); Query OK,1 row affected (0.01 sec) mysql> create index idx_c1 on t1 (c1); Query OK,o rows affected (0.02 sec) Records: 0 Duplicates: 0 warnings: o 创建表,在c1字段插入重复数据,并在c1字段创建索引,我们通过执行计划看一下 cost值的消耗。 mysql> explain format=json select * from t1 where c1 = 'a'; "query_block" :{ "select_id": 1,"cost_info":{ "query_cost": "1.10" ) 删除索引,并通过执行计划查看cost值的消耗。 mysql> drop index idx_c1 on t1; Query OK,0 rows affected (0.02sec)Records: 0 Duplicates: 0 warnings: o mysql> explain format=json select * from t1 where c1 = 'a';( "query_block":{ "select_id":1,"cost_info" :{ "query_cost":"0.85" ) ) 两次查询的cost值不同,通过索引查询的cost值比全表扫描的cost值大。这是因为当通过索引查询时索引数据都是重复的(基数很低),所以要做一个索引全扫描;还因 为“SELECT *”扫描完索引后要回表查询id, c2,c3这几个字段。就好比你要读完一本书,不会先把目录全部读一遍,然后再把后面的内容都读一遍。 如果将c1字段的值改成不重复的,我们再来看一下。 mysql> insert into t1 values (10, 'a', 'b', 'c'); Query OK, 1 row affected (0.01 sec) mysql> insert into t1 values (10,'b','b','c'); Query OK,1 row affected (0.01 sec) mysql> insert into t1 values (10,'c','b','c'); Query OK, 1 row affected (0.01 sec) mysql> insert into t1 values (10,'d','b', 'c'); Query OK, 1 row affected (0.00 sec) mysql> insert into t1 values (10,'e', 'b','c'); Query OK,1 row affected (0.01 sec) mysql> explain format=json select * from t1 where c1 = 'a'; "query_block" :{ "select_id": 1,"cost_info":{ "query_cost": "0.35" } mysql> drop index idx_c1 on t1; Query OK,0 rows affected (0.02 sec) Records: 0 Duplicates: 0 warnings:0 mysql>explain format=json select * from t1 where c1 = 'a'; "query_block": { "select_id": 1,"cost_info":( "query_cost":"0.75" ) 这次c1字段的值不重复(基数较高),则通过索引查询的cost值比全表扫描的cost值小。 这里可能没有体现出选择性,我们说基数高比较好,但是要有一个衡量目标。例如, 某一字段的基数是几十万条,但是表中数据有几十亿条,在这个字段上创建索引就不是很合适,因为选择性比较低,通过索引查询在索引中可能就要扫描上亿条数据。 通常在创建索引时要考虑以上内容(回表、基数、选择性),在MySQL中可以通过系统表innodb_index_stats来查看索引选择性如何,并且可以看到组合索引中每一个字段的选择性如何,还可以计算索引的大小 SELECT stat_value AS pages, index_name , stat_value * @@innodb_page_size / 1024/ 1024 AS size FROM mysql.innodb_index_stats WHERE(table_name = 'sbtest1' AND database_name = 'sbtest' AND stat_description = 'Number of pages in the index' AND stat_name = 'size') GROUP BY index_name; 如果是分区表,则使用下面的语句。 SELECT stat_value AS pages, index_name ,SUM(stat_value)* @@innodb_page_size / 1024 / 1024 AS size FROM mysql .innodb_index_stats WHERE(table_name LIKE 't#P%' AND database_name = 'test' AND stat_description = 'Number of pages in the index' AND stat_name = 'size') GROUP BY index_name; 也可以通过show index from table_name 查看Cardinality字段的值,以及字段的基数是多少。 MySQL中的Join算法 这是一个世纪难题,很多文章或者文档或者公司规范都是说尽量不要使用join方法,但是原因讲解都比较粗一些,今天就来看一下他的算法实现是怎么样的,为什么要尽量减少使用频率 1. Nested-Loop Join Algorithm(嵌套循环Join算法) 最简单的Join算法及外循环读取一行数据,根据关联条件列到内循环中匹配关联,在这种算法中,我们通常称外循环表为驱动表,称内循环表为被驱动表。 Nested-Loop Join算法的伪代码如下: for each row in t1 matching range { for each row in t2 matching reference key { for each row in t3 { if row satisfies join conditions,send to client) ) 2. Block Nested-Loop Join Algorithm(块嵌套循环Join算法,即BNL算法) BNL算法是对Nested-Loop Join算法的优化。 具体做法是将外循环的行缓存起来,读取缓冲区中的行,减少内循环表被扫描的次数。例如,外循环表与内循环表均有100行记录,普通的嵌套内循环表需要扫描100次,如果使用块嵌套循环,则每次外循环读取10行记录到缓冲区中,然后把缓冲区数据传递给下一个内循环,将内循环读取到的每行和缓冲区中的10行进行比较,这样内循环表只需要扫描10次即可完成,使用块嵌套循环后内循环整体扫描次数少了一个数量级。使用块嵌套循环,内循环表扫描方式应是全表扫描,因为是内循环表匹配Join Buffer中的数据的。使用块嵌套循环连接,MySQL会使用连接缓冲区(Join Buffer),且会遵循下面一些原则: • 连接类型为ALL、index、range,会使用到Join Buffer。 • Join Buffer是由join_buffer_size 变量控制的。 • 每次连接都使用一个Join Buffer,多表的连接可以使用多个Join Buffer。 • Join Buffer只存储与查询操作相关的字段数据,而不是整行记录。 BNL算法的伪代码如下: for each row in t1 matching range { for each row in t2 matching reference key { store used columns from t1, t2 in join buffer if buffer is full { for each row in t3 { for each t1,t2 combination in join buffer { if row satisfies join conditions,send to client } } empty join buffer } } } if buffer is not empty{for each row in t3{ for each t1, t2 combination in join buffer { if row satisfies join conditions,send to client } } } 对上面的过程解释如下: ①将t1、t2的连接结果放到缓冲区中,直到缓冲区满为止。 ②遍历t3,与缓冲区内的数据匹配,找到匹配的行,发送到客户端。 ③清空缓冲区。 ④重复上面的步骤,直至缓冲区不满。 ⑤处理缓冲区中剩余的数据,重复步骤②。 假设S是每次存储t1、t2组合的大小,C是组合的数量,则t3被扫描的次数为:(S * C)/join_buffer_size+ 1。 由此可见,随着join_buffer_size的增大,t3被扫描的次数会减少,如果join_buffer_size 足够大,大到可以容纳所有t1和t2连接产生的数据,那么t3只会被扫描一次。 MySQL中的优化特性 1. Index Condition Pushdown(ICP,索引条件下推) ICP是MySQL针对索引从表中检索时的一种优化特性,在没有ICP时处理过程如图21- 4所示。 ①根据索引读取一条索引记录,然后使用索引的叶子节点中的主键值回表读取整个表行。 ②判断这行记录是否符合where条件。

有ICP后处理过程

①根据索引读取一条索引记录,但并不回表取出整行数据。 ②判断记录是否满足where条件的一部分,并且只能使用索引字段进行检查。如果不满足条件,则继续获取下一条索引记录。 ③如果满足条件,则使用索引回表取出整行数据。 ④再判断where条件的剩余部分,选择满足条件的记录。 ICP的意思就是筛选字段在索引中的where条件从服务器层下推到存储引擎层,这样可以在存储引擎层过滤数据。由此可见,ICP可以减少存储引擎访问基表的次数和MySQL服务器访问存储引擎的次数。 ICP的使用场景如下: • 组合索引(a,b)where条件中的a字段是范围扫描,那么后面的索引字段b则无法使用到索引。在没有ICP时需要把满足a字段条件的数据全部提取到服务器层,并且会有大量的回表操作;而有了ICP之后,则会将b字段条件下推到存储引擎层,以减少回表次数和返回给服务器层的数据量。 • 组合索引(a,b)的第一个字段的选择性非常低,第二个字段查询时又利用不到索引(%b%),在这种情况下,通过ICP也能很好地减少回表次数和返回给服务器层的数据量。 ICP的使用限制如下: • 只能用于InnoDB和MyISAM。 • 适用于range、ref、eq_ref和ref_or_null访问方式,并且需要回表进行访问。 • 适用于二级索引。 • 不适用于虚拟字段的二级索引。 2. Multi-Range Read(MRR) 如果通过二级索引扫描时需要回表查询数据,那么此时由于主键顺序与二级索引的顺序不一致会导致大量的随机I/O。而通过Multi-Range Read特性,MySQL会将索引扫描到的数据根据rowid进行一次排序,然后再回表查询。此方式的好处是将回表查询从随机I/O 转换成顺序I/O。 在没有MRR时,通过索引查询到数据之后回表形式

从图中可以看到,当通过二级索引扫描完数据之后,根据rowid(或者主键)回表查询,但是这个过程是随机访问的。如果表数据量非常大,在传统的机械硬盘中IOPS 不高的情况下性能会很差。 有了MRR之后,回表形式
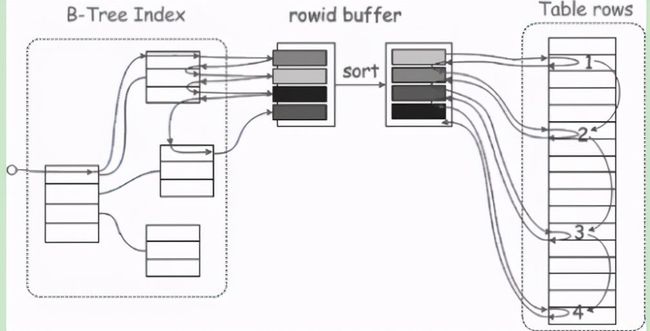
根据索引查询完之后会将rowid放到缓冲区中进行排序,排序之后再回表访问,此时是顺序I/O。这里排序所用到的缓冲区是由参数read_rnd_buffer_size所控制的。 3. Batched Key Access(BKA) BKA是对BNL算法的更一步扩展及优化,其作用是在表连接时可以进行顺序I/O,所以BKA是在MRR基础之上实现的,同时BKA支持内连接、外连接和半连接操作。 当两个表连接时,在没有BKA的情况下如图所示,可以看到访问t2表时是随机I/O。
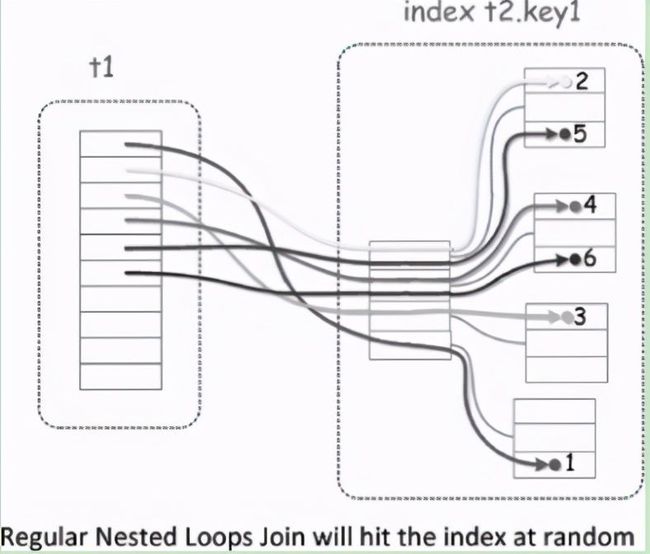
有了BKA之后如图21-9所示,可以看到对t2表进行连接访问时,先将t1中相关的字段放入Join buffer中,然后利用MRR特性接口进行排序(根据rowid),排序之后即可通过rowid到t2表中进行查找。

这里也有一个隐含的条件,就是就是关联字段需要有索引,否则还是会使用BNL算法的。