kaggle篇章二,新手入门泰坦尼克号的幸存者预测实验的超详细全过程记录
看到全部是英文,我的内心咯噔一声,瞬间没有想看的欲望了,但是,得努力跑完代码,我也只能努把力耐心地往下看。
以下是我的学习之旅
第一步是导入数据。
kaggle网站里的代码是下面这样的
# Load data
##### Load train and Test set
train = pd.read_csv("../input/train.csv")
test = pd.read_csv("../input/test.csv")
IDtest = test["PassengerId"]我一开始直接就复制到我的文档里,但是运行不出结果。上网查看攻略后,我发现,导入的话是要改变括号里的参数。
train = pd.read_csv('C:\\Users\\train.csv')
test = pd.read_csv('C:\\Users\\test.csv')
IDtest = test["PassengerId"]但是还是不行,他会出现下面的问题
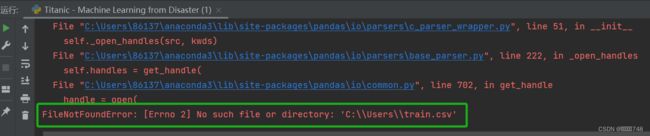
就算我把这两个文件放入默认路径里或者参数里只写“train.csv”仍然是出现上述的情况。
上网搜索后,得知可能是因为没有下载pandas安装包,可是我下载完后,仍然是这样的情况。
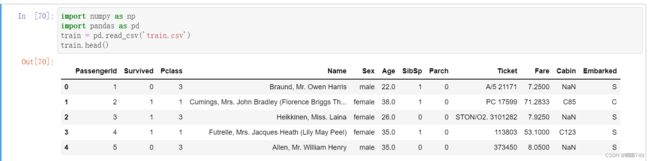
因此我就想着在上学期python公选课中用jupyter notebook中运行,结果我发现是可以的。如下图,成功导入了数据。
但是我还是想在pycharm上面导入数据。学习我小组内某位成员的做法,我把数据拖入在pycharm新建的文件夹里,如下图。

之后出现下图情况
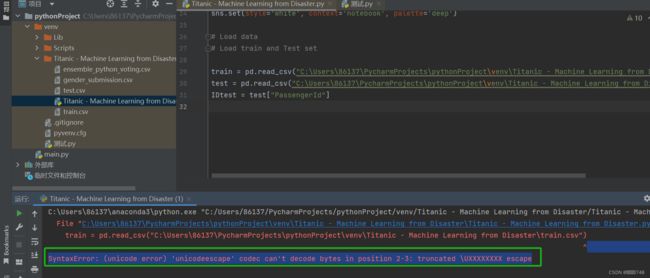
按着syntaxerror: (unicode error) 'unicodeescape' codec can't decode bytes in pos_曾牛的博客-CSDN博客_(unicode error)'unicodeescape的解决办法,终于!让我导入进去了!仅仅是导入就花费了我三四个小时查找解决办法。
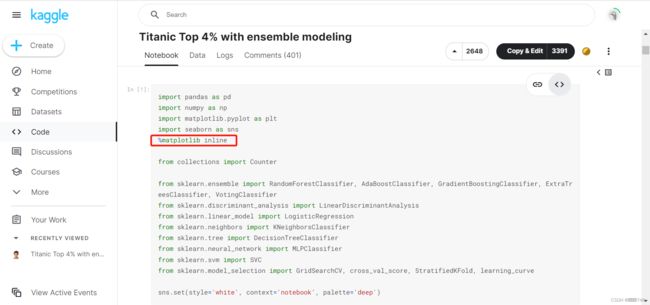
顺便提一下,下图圈起来的需要注释掉,它的意思是将matplotlib的图表直接嵌入到Notebook之中,但是只能在ipython或jupyter notebook中用。
之后按着kaggle上面的步骤,我到达下面这步。
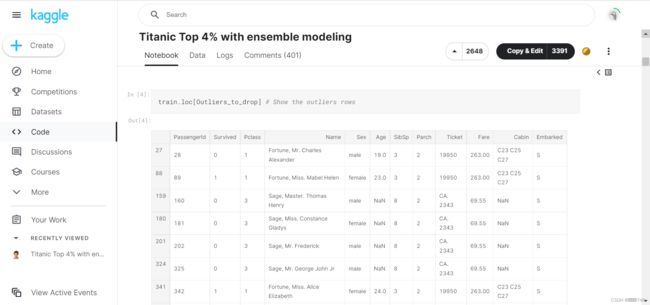
在pycharm这里,并没有出现如图的表格,只有“进程已结束,退出代码0”的字样,于是我复制到jupyter notebook中,运行后出现了如图的表格。pycharm看不了表格,我不太明白是为啥。
再然后到达下列代码,我运行了没有这段代码和有这段代码,发现没有省略的地方是完全一样的,有点不太明白这段是干什么用的。
# Drop outliers
train = train.drop(Outliers_to_drop, axis = 0).reset_index(drop=True)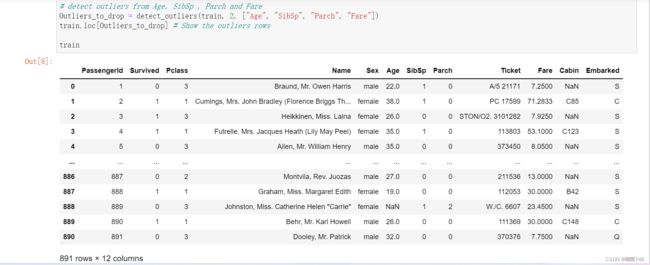
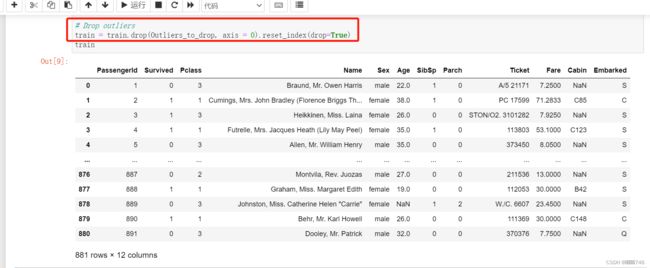
要想展示出表格,组里同学说要用print,这里说明了pycharm需要稍微改动一下kaggle里的原代码
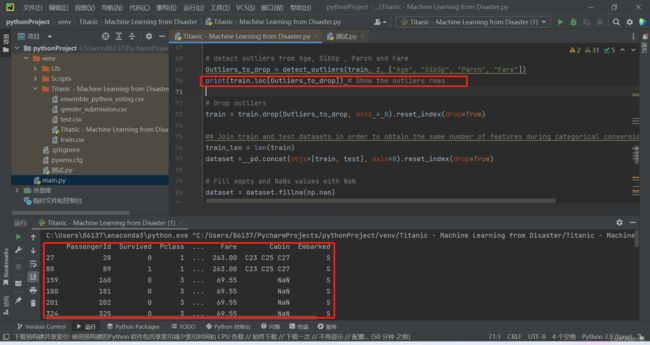
做题步骤:
对于大部分步骤不理解的可以移步大佬介绍Kaggle比赛系列: (3) Titanic-2_sapienst的博客-CSDN博客如果函数不理解的 可以移步另一位大佬的介绍任务一 Titanic Top 4% with ensemble modeling_Heihei_study的博客-CSDN博客
如果和我一样需要更详细一点的代码注释可以移步知乎大佬的介绍[数据挖掘与分析]Kaggle实战技巧总结 - 知乎 (zhihu.com)
当我对某一行不理解的代码进行搜索时,偶然发现一位知乎大佬的总结,解决了我对这个项目大部分的疑难问题,大家可以移步Kaggle机器学习之泰坦尼克号生还预测 - 知乎 (zhihu.com)我看完后觉得受益匪浅!这是这几个链接里最详细最系统的注释了!
源代码中所用到的函数 入口:泰坦尼克号幸存者预测所用函数_ᝰꫛꪮꪮꫜ748的博客-CSDN博客
1、异常值检测
定义一个函数,根据Tukey方法,获取特征的数据帧df,并返回与包含n个以上异常值的观察值相对应的索引列表(此处采用四分位数)
关于代码块的理解:
outlier_list_col = df[(df[col] < Q1 - outlier_step) | (df[col] > Q3 + outlier_step )].indexPandas中的df[df[col] > 0.5]函数的作用是选择col列的值大于0.5的行。
multiple_outliers = list( k for k, v in outlier_indices.items() if v > n )Python 字典 items() 函数作用:以列表返回可遍历的(键, 值) 元组数组。
丢弃掉缺失值超过两个的所在行,然后重置索引。
2、合并训练集和测试集
使用concat函数,按行拼接,紧接着重置索引
3、对数值型数据进行处理
①将空值和缺失值全部填充为缺失值(ps:NaN是缺失值,缺失值含义入口:缺失值 - MBA智库百科,空值理解入口:空值 null 的含义_LinsFay的博客-CSDN博客_空值null
②统计每一列空值的数量,使用下面两个函数查看每列的缺失值情况。
train.info()
train.isnull().sum()③大致了解数据集的整体情况
train.head() #查看下train训练集前五列信息
train.dtypes #查看下train训练集各列的数据类型
train.describe() #对每列数据进行统计汇总,这里自动识别具有int类型的列
(ps:https://zhuanlan.zhihu.com/p/33054078)4、对每一列特征列进行分析
①采用下列函数生成热力图,看每一个特征列与Survived之间的关系。
g = sns.heatmap(train[["Survived","SibSp","Parch","Age","Fare"]].corr(),annot=True, fmt = ".2f", cmap = "coolwarm")②采用类似下面函数分别画出SibSp,Parch分别与Survived之间的关系
g = sns.factorplot(x="SibSp",y="Survived",data=train,kind="bar", size = 6 ,
palette = "muted")
g.despine(left=True)
g = g.set_ylabels("survival probability")③探索Age,Fare分别与Survived之间的关系
对于年龄,首先使用密度函数来探索Age和Survived之间的关系,之后利用核密度估计再来探究下年龄的分布。
对于费用,如果有缺失值,可以用中位数填充,之后用直方图展示Fare的分布情况,可根据它的分布情况取对数化,使分布更加均匀。
5、对非数值型数据进行处理
①性别,利用树状图分析性别与生还的关系
②Pclass,探寻头等舱、二等舱与生还的关系
③进一步探寻,在不同的Pclass中,性别与生还的关系
④Embarked,分析从不同地方上船的乘客是否会有不一样结果。先查看是否有缺失值,如果很少,则选择把它填充为最常出现的。
⑤根据图表进行假设,来自某一地点的乘客舱位分布可能利于生还。
6、预测年龄
①分析Age和Sex,Parch,Pclass ,SibSP之间的关系
②绘制热力图,取与年龄相关系数较大的相同的几大特征量的中位数对年龄缺失值进行填充,如果没有,则取所在行的中位数进行填充
③再分析年龄与生还的关系
7、特征列分析转换处理
①姓名,查看前五行,找出相同部分,进行截取,覆盖原表,之后统计姓名的频率,将出现次数少的统分为一类,之后转换成int型,把它定义成新的一类,并且分析其与生还之间的关系
②家庭成员规模,推测家庭的大小会很大程度的影响生还的可能。新增Fsize(family size),Fsize=SibSp+Parch+1,分析Fsize列和Survived之间的关系。根据家庭成员的个数新增几列不同的特征列,再分别探讨其与生还之间的关系。
③Cabin,船舱号分析,计算空值的数量,将缺失值全部换成“x”,查看各种类型的分布情况,并分析其与生还之间的关系。因为缺少此数据的乘客过多,所以不作为判断乘客生还的依据。
dataset["Cabin"][dataset["Cabin"].notnull()].head()
#不是很理解为什么可以连续有两个中括号④Ticket,Ticket前缀相同应该来自同一Cabin,根据Ticket前缀进行划分,将所有前缀信息进行处理化成纯数字,之后使用get_dummies进行one-hot编码,去掉无关特征量。
8、模型的选择
单一模型训练:将train和test分开,将train中的survived列与其他列分开,考虑使用以下常用的机器学习算法:
- SVC
- Decision Tree
- AdaBoost
- Random Forest
- Extra Trees
- Gradient Boosting
- Multiple layer perceprton (neural network)
- KNN
- Logistic regression
- Linear Discriminant Analysis
交叉验证:
①设置kfold
②汇总不同模型算法,同时进行初始化
③不同机器学习交叉验证结果汇总
④取每个模型获取的cv_results的平均数以及标准偏差
⑤查看下cv_res
⑥通过图表来看下不同算法的表现情况,综合以上模型表现,考虑选择SVC, AdaBoost, RandomForest , ExtraTrees 和 the GradientBoosting classifiers 应用到组合模型当中去
9、模型最优参数调整
①综合以上模型表现,考虑选择SVC, AdaBoost, RandomForest , ExtraTrees 和 the GradientBoosting classifiers 应用到组合模型当中去
②优化ExtraTrees 的参数
③优化RandomForest的参数
④优化GradientBoosing的参数
⑤优化SVC的参数
⑥绘制不同模型学习曲线
⑦利用上面函数对不同算法模型进行学习曲线的绘制
⑧查看不同模型使用特征值权重,通过绘制图表来具体看下不同的算法对应不同特征值的权重
传入参数soft,把五个模型组合起来,预测并提交预测结果。
ps:后面这些模型训练我都看不懂。