万能的Seq2Seq:基于Seq2Seq的阅读理解问答

作者丨苏剑林
单位丨追一科技
研究方向丨NLP,神经网络
个人主页丨kexue.fm
今天给 bert4keras [1] 新增加了一个例子:阅读理解式问答(task_reading_comprehension.py [2]),语料跟之前一样,都是用 WebQA 和 SogouQA [3],最终的得分在 0.75 左右(单模型,没精调)。
方法简述
由于这次主要目的是给 bert4keras 增加 demo,因此效率就不是主要关心的目标了。这次的目标主要是通用性和易用性,所以用了最万能的方案——seq2seq 来实现做阅读理解。
用 seq2seq 做的话,基本不用怎么关心模型设计,只要把篇章和问题拼接起来,然后预测答案就行了。此外,seq2seq 的方案还自然地包括了判断篇章有无答案的方法,以及自然地导出一种多篇章投票的思路。总而言之,不考虑效率的话, seq2seq 做阅读理解是一种相当优雅的方案。
这次实现 seq2seq 还是用 UNILM 的方案,如果还不了解的读者,可以先阅读从语言模型到Seq2Seq:Transformer如戏,全靠Mask了解相应内容。
模型细节
用 UNILM 方案搭建一个 seq2seq 模型在 bert4keras 中基本就是一行代码的事情,所以这个例子的主要工作在并不在模型的建立上,而是在输入输出的处理上面。
输入格式
首先是输入,输入格式很简单,一张图可以表达清楚:
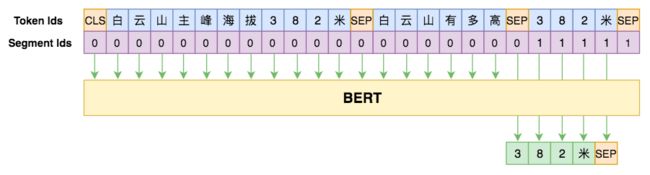
▲ 用seq2seq做阅读理解的模型图示
输出处理
如果输入单个篇章和单个问题进行回答,那么直接按照 seq2seq 常规的处理方案——即 beam search——来解码即可。
但是,WebQA 和 SogouQA 面对的是搜索场景,即同时存在多篇文章来对同一个问题进行回答,这就涉及到投票方案的选择了。一种朴素的思路是:每个篇章结合问题单独用 beam search 解码,并且给出置信度,最后再按照基于CNN的阅读理解式问答模型:DGCNN的投票方式进行。这种方式的困难之处在于对每个答案给出一个合理的置信度,它相比我们后面给出的思路则显得不够自然,并且效率也稍低些。
这里我们给出一种跟 beam search 更加“契合”的方案:先排除没有答案的篇章,然后在解码答案的每一个字时,直接将所有篇章预测的概率值(按照某种方式)取平均。
具体来说,所有篇章分别和问题拼接起来,然后给出各自的第一个字的概率分布。那些第一个字就给出 [SEP] 的篇章意味着它是没有答案的,排除掉它们。排除掉之后,将剩下的篇章的第一个字的概率分布取平均,然后再保留 topk(beam search 的标准流程)。预测第二个字时,每个篇章与 topk 个候选值分别组合,预测各自的第二个字的概率分布,然后再按照篇章将概率平均后,再给出 topk。依此类推,直到出现 [SEP]。其实就是在普通的 beam search 基础上加上按篇章平均,如果实在弄不明白,那就只能去看源码了。
此外,生成答案的方式应该有两种,一种是抽取式的,这种模式下答案只能是篇章的一个片段,另外一种是生成式的,即不需要考虑答案是不是篇章的片段,直接解码生成答案即可。这两种方式在本文的解码中都有相应的判断处理。
实验代码
代码链接:
https://github.com/bojone/bert4keras/blob/master/examples/task_reading_comprehension.py
最终在 SogouQA 自带的评估脚本 [4] 上,valid 集的分数大概是 0.75,单模型成绩轻松超过了之前的《开源一版DGCNN阅读理解问答模型(Keras版)》[3] 模型。当然,提升是有代价的——预测速度大大降低,每秒只能预测 2 条数据左右。
模型没精细调优,估计还有提升空间,当前还是以 demo 为主。
文章小结
本文主要是给出了一个基于 bert 和 seq2seq 思路的阅读理解例子,并且给出了一种多篇章投票的 beam search 策略,供读者参考和测试。
相关链接
[1] https://github.com/bojone/bert4keras
[2] https://github.com/bojone/bert4keras/blob/master/examples/task_reading_comprehension.py
[3] https://kexue.fm/archives/6906
[4] https://github.com/bojone/dgcnn_for_reading_comprehension

点击以下标题查看作者其他文章:
当Bert遇上Keras:这可能是Bert最简单的打开姿势
玩转Keras之Seq2Seq自动生成标题 | 附开源代码
一文读懂「Attention is All You Need」| 附代码实现
基于CNN的阅读理解式问答模型:DGCNN
基于DGCNN和概率图的轻量级信息抽取模型
ICLR 2019最佳论文 | 用有序神经元表达层次结构
 #投 稿 通 道#
#投 稿 通 道#
让你的论文被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学习心得或技术干货。我们的目的只有一个,让知识真正流动起来。
???? 来稿标准:
• 稿件确系个人原创作品,来稿需注明作者个人信息(姓名+学校/工作单位+学历/职位+研究方向)
• 如果文章并非首发,请在投稿时提醒并附上所有已发布链接
• PaperWeekly 默认每篇文章都是首发,均会添加“原创”标志
???? 投稿邮箱:
• 投稿邮箱:[email protected]
• 所有文章配图,请单独在附件中发送
• 请留下即时联系方式(微信或手机),以便我们在编辑发布时和作者沟通
????
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。

▽ 点击 | 阅读原文 | 查看作者博客