注意力机制(Attention):Seq2Seq模型的改进
1. 前言
本文讲解Seq2Seq模型改进方法:注意力机制(Attention)。
本人全部文章请参见:博客文章导航目录
本文归属于:自然语言处理系列
本系列实践代码请参见:我的GitHub
前文:Sequence-to-Sequence模型原理
后文:自注意力机制(Self-Attention):从Seq2Seq模型到一般RNN模型
2. Seq2Seq模型缺点
Seq2Seq模型有一个Encoder(编码器),和Decoder(解码器)。由于输入和输出均为序列数据,在深度学习时间中Encoder和Decoder一般均为结构相同的RNN。Encoder RNN对输入序列进行处理,将输入序列信息压缩到一个向量中。Encoder最后一个状态是整个输入序列的概要,包含了整个输入序列的信息。
Decoder RNN的初始状态 s 0 s_0 s0等于Encoder RNN最后一个状态 h m h_m hm。 h m h_m hm包含了输入序列的信息,Decoder RNN可以通过 h m h_m hm知道输入序列的信息。Decoder RNN可以将 h m h_m hm中包含的信息解码,逐个元素地生成输出序列。
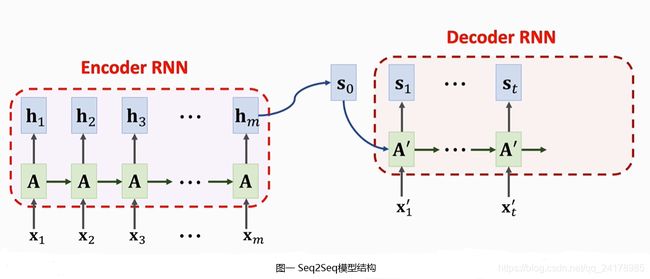
由于Encoder为一个RNN,因此在输入序列很长时,Encoder会或多或少遗忘输入序列中的部分信息。在机器翻译等经典Seq2Seq模型应用实践中,如果输入句子部分信息被遗忘,则Decoder显然无法生成正确的翻译。
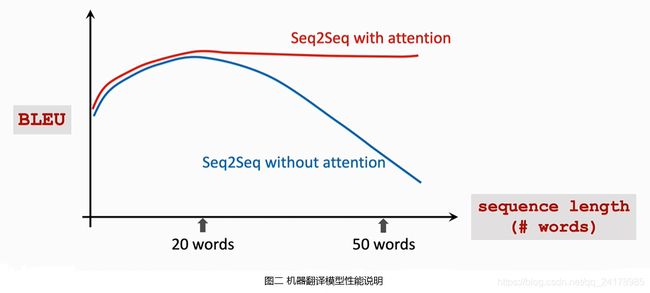
如下图所示,因为RNN存在遗忘问题,使用Seq2Seq模型实现机器翻译,当输入句子长度超过20个单词时,BLEU 会逐渐减小。
3. 注意力机制(Attention)
解决Seq2Seq模型最有效的方法是Attention,Attention第一篇论文发表在2015年,用于改进Seq2Seq模型,可以大幅提高机器翻译的准确率。Attention使得Decoder每次更新状态时会查看Encoder所有状态,从而避免RNN遗忘的问题,而且可以让Decoder关注Encoder中最相关的信息,这也是Attention名字的由来。
3.1 SimpleRNN + Attention
在Encoder对输入序列编码结束后,Attention与Decoder同时开始工作。Decoder的初始状态 s 0 s_0 s0是Encoder的最后一个状态 h m h_m hm。
使用Attention需要保留Encoder所有状态 h 1 , h 2 , ⋯ , h m h_1,h_2,\cdots,h_m h1,h2,⋯,hm,在Encoder生成输出序列的每一个元素之前,需要计算Encoder当前状态 s t s_t st与Encoder所有状态的相关性(权重) α t 1 , α t 2 , ⋯ , α t m \alpha_{t1},\alpha_{t2},\cdots,\alpha_{tm} αt1,αt2,⋯,αtm。
α t i = a l i g n ( h i , s t ) ( 1 ) \alpha_{ti}=align(h_i,s_t)~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~(1) αti=align(hi,st) (1)
α t i , ( i = 1 ∼ m ) \alpha_{ti},(i=1\sim m) αti,(i=1∼m)均是介于 0 ∼ 1 0\sim 1 0∼1之间的实数, ∑ i = 1 m α t i = 1 \sum_{i=1}^m\alpha_{ti}=1 ∑i=1mαti=1。
得到与Encoder所有状态 h 1 , h 2 , ⋯ , h m h_1,h_2,\cdots,h_m h1,h2,⋯,hm对应的权重 α t 1 , α t 2 , ⋯ , α t m \alpha_{t1},\alpha_{t2},\cdots,\alpha_{tm} αt1,αt2,⋯,αtm之后,可以对Encoder所有状态向量求加权平均,得到Context Vector,记为 c t c_t ct, c t = α t 1 h 1 + α t 2 h 2 + ⋯ + α t m h m c_t=\alpha_{t1}h_1+\alpha_{t2}h_2+\cdots+\alpha_{tm}h_m ct=αt1h1+αt2h2+⋯+αtmhm。
每一个Context Vector均会与一个Decoder状态相对应, c 0 c_0 c0对应Decoder状态 s 0 s_0 s0, c 1 c_1 c1对应Decoder状态 s 1 s_1 s1, c t c_t ct对应Decoder状态 s t s_t st。
如图一所示,Decoder读入向量 x t ′ x_t^\prime xt′,将状态从 s t − 1 s_{t-1} st−1更新为 s t s_t st。根据简单循环神经网络(Simple RNN)原理与实战一文可知,在不使用Attention的情况下,Simple RNN通过如下公式更新状态:
s t = t a n h ( A ′ ⋅ [ s t − 1 x t ′ ] + b ) ( 2 ) s_t=tanh(A^\prime \cdot {s_{t-1}\brack x_t^\prime}+b)~~~~~~~~~~~~~~~~~~~~~~~~~~~(2) st=tanh(A′⋅[xt′st−1]+b) (2)
Simple RNN在更新状态时只需知道新的输入 x t ′ x_t^\prime xt′与上一个时刻的状态 s t − 1 s_{t-1} st−1,并不会去查看Encoder的状态。使用Attention,更新Decoder状态时需要用到Context Vector,在使用Attention情况下,通过如下公式更新状态:
s t = t a n h ( A ′ ⋅ [ s t − 1 x t ′ c t − 1 ] + b ) ( 3 ) s_t=tanh\Big(A^\prime \cdot \begin{bmatrix} s_{t-1}\\ x_t^\prime\\ c_{t-1} \end{bmatrix} +b\Big)~~~~~~~~~~~~~~~~~~~~~~~~~~~(3) st=tanh(A′⋅⎣⎡st−1xt′ct−1⎦⎤+b) (3)
c t − 1 c_{t-1} ct−1是Encoder所有状态 h 1 , h 2 , ⋯ , h m h_1,h_2,\cdots,h_m h1,h2,⋯,hm的加权平均,所以 c t − 1 c_{t-1} ct−1包含Encoder输入序列完整信息,Decoder新状态 s t s_t st依赖于 c t − 1 c_{t-1} ct−1,因此Decoder知道Encoder完整的输入,于是Attention通过这种方式解决了RNN中存在的遗忘问题。
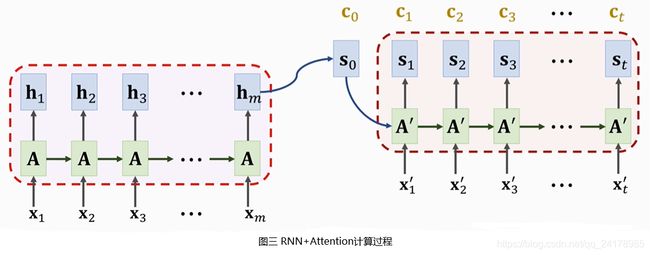
使用Attention,Decoder生成输出序列过程如图三所示。先计算Context Vector c 0 c_0 c0,然后根据公式(3)将状态从 s 0 s_0 s0更新为 s 1 s_1 s1。再计算 c 1 c_1 c1,然后根据公式(3)将状态从 s 1 s_1 s1更新为 s 2 s_2 s2。如此直至生成最后一个状态 s T s_T sT。
如图二所示,Attention解决了RNN中存在的遗忘问题,使用Seq2Seq with attention模型实现机器翻译,BLEU 不会随着输入句子长度变大而逐渐减小。
3.2 权重计算方法
有很多种方法计算 h i h_i hi与 s t s_t st的相关性(权重) α t i \alpha_{ti} αti,本文介绍其中两种方法。
方法一:
第一种方法如图四所示,将 h i h_i hi与 s t s_t st拼接,然后左乘参数矩阵 W W W,得到一个向量。将双曲正切函数 t a n h tanh tanh作用于得到的向量的每一个元素上,将向量的每一个元素值调整到 − 1 ∼ + 1 -1\sim +1 −1∼+1之间,得到一个新向量。最后计算参数向量 V V V与新向量的内积,记为 α ~ t i \tilde{\alpha}_{ti} α~ti。其中矩阵 W W W和 V V V是参数矩阵,需要从训练数据中学习。
计算出 α ~ t 1 , α ~ t 2 , ⋯ , α ~ t m \tilde{\alpha}_{t1},\tilde{\alpha}_{t2},\cdots,\tilde{\alpha}_{tm} α~t1,α~t2,⋯,α~tm之后,进行 S o f t m a x Softmax Softmax变化,将输出结果记为 α t 1 , α t 2 , ⋯ , α t m \alpha_{t1},\alpha_{t2},\cdots,\alpha_{tm} αt1,αt2,⋯,αtm,即 [ α t 1 , α t 2 , ⋯ , α t m ] = S o f t m a x ( [ α ~ t 1 , α ~ t 2 , ⋯ , α ~ t m ] ) [\alpha_{t1},\alpha_{t2},\cdots,\alpha_{tm}]=Softmax([\tilde{\alpha}_{t1},\tilde{\alpha}_{t2},\cdots,\tilde{\alpha}_{tm}]) [αt1,αt2,⋯,αtm]=Softmax([α~t1,α~t2,⋯,α~tm])。

这种计算相关性计算方法在Attention的第一篇论文中被提出。
方法二:
第二种计算 h i h_i hi与 s t s_t st的相关性 α t i \alpha_{ti} αti的方法如下:
- 分别用两个参数矩阵 W K W_K WK和 W Q W_Q WQ对 h i h_i hi和 s t s_t st做线性变换,得到向量 k i k_i ki与 q t q_t qt;
k i = W K ⋅ h i , f o r i = 1 t o m k_i=W_K\cdot h_i,~for~i=1~to~m ki=WK⋅hi, for i=1 to m
q t = W Q ⋅ s t , f o r t = 1 t o T q_t=W_Q\cdot s_t,~for~t=1~to~T qt=WQ⋅st, for t=1 to T - 计算向量 k i k_i ki与 q t q_t qt的内积,得到 α ~ t i \tilde{\alpha}_{ti} α~ti;
α ~ t i = k i T q t , f o r i = 1 t o m , t = 0 t o T \tilde{\alpha}_{ti}=k_i^Tq_t,~for~i=1~to~m,~t=0~to~T α~ti=kiTqt, for i=1 to m, t=0 to T - 对 α ~ t 1 , α ~ t 2 , ⋯ , α ~ t m \tilde{\alpha}_{t1},\tilde{\alpha}_{t2},\cdots,\tilde{\alpha}_{tm} α~t1,α~t2,⋯,α~tm进行 S o f t m a x Softmax Softmax变换,把输出记作 α t 1 , α t 2 , ⋯ , α t m \alpha_{t1},\alpha_{t2},\cdots,\alpha_{tm} αt1,αt2,⋯,αtm。
[ α t 1 , α t 2 , ⋯ , α t m ] = S o f t m a x ( [ α ~ t 1 , α ~ t 2 , ⋯ , α ~ t m ] ) [\alpha_{t1},\alpha_{t2},\cdots,\alpha_{tm}]=Softmax([\tilde{\alpha}_{t1},\tilde{\alpha}_{t2},\cdots,\tilde{\alpha}_{tm}]) [αt1,αt2,⋯,αtm]=Softmax([α~t1,α~t2,⋯,α~tm])
这种计算相关性 α t i \alpha_{ti} αti的方法现在更常用,该方法被Transformer模型采用,Transformer模型是当前许多NLP问题的SOTA(state of the art,最高水平)。
3.3 Attention时间复杂度分析
假设输入序列长度为 m m m,输出序列长度为 t t t。标准的Seq2Seq模型只需让Encoder读取一遍输入序列,Decoder根据当前状态产生下一个状态,不会查看Encoder的输入或状态。因此标准的Seq2Seq模型时间复杂度为 O ( m + t ) O(m+t) O(m+t)。
如果使用Attention,Decoder每次更新状态之前须读取一遍Encoder所有状态来计算Context Vector。Decoder总共进行 t t t次状态更新操作,因此使用Seq2Seq+Attention模型的时间复杂度为 O ( m t ) O(mt) O(mt)。
使用Attention可以避免RNN遗忘问题,从而大幅提升Seq2Seq模型效果,但是代价是巨大的计算量。
4. 参考资料链接
- https://www.youtube.com/watch?v=XhWdv7ghmQQ&list=PLvOO0btloRnuTUGN4XqO85eKPeFSZsEqK&index=8