CUDA C编程入门
cuda 程序的基本步骤如下:
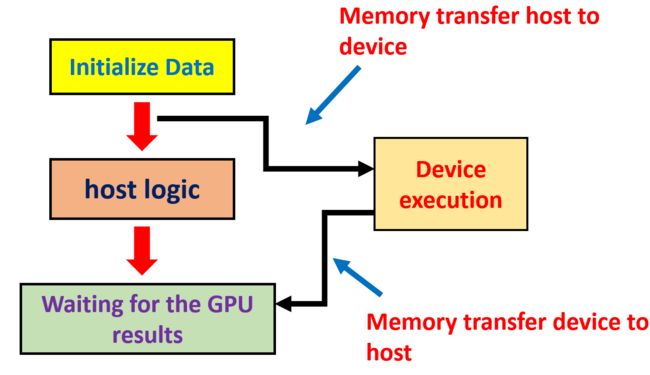
- 在 cpu 中初始化数据
- 将输入 transfer 到 GPU 中
- 利用分配好的 grid 和 block 启动 kernel 函数
- 将计算结果 transfer 到 CPU 中
- 释放申请的内存空间
从上面的步骤可以看出,一个 CUDA 程序主要包含两部分,第一部分运行在 CPU 上,称作 Host code,主要负责完成复杂的指令;第二部分运行在 GPU 上,称作 Device code,主要负责并行地完成大量的简单指令(如数值计算);
2. 基本设施
运行在 GPU 中地函数称作 kernel,该函数有这么几个要求:
- 声明时在返回类型前需要添加 "__globol__" 的标识
- 返回值只能是 void
__global__ void addKernel(int *c, const int *a, const int *b)
{
int i = threadIdx.x;
c[i] = a[i] + b[i];
}
这就是一个合规的核函数。
除了声明时的不同,和函数的调用也是不一样的,需要以 “kernel_name <<<>>>();” 的形式调用。而在尖括号中间,则是定义了启用了多少个 GPU 核,学习这一参数的使用,我们还需要知道下面几个概念:
- dim3:一种数据类型,包含 x,y,z 三个 int 类型的成员,在初始化时一个 dim3 类型的变量时,成员值默认为 1
- grid : 一个 grid 中包含多个 block
- block: 一个 block 包含多个 thread
我们以一种更抽象的方式来理解 GPU 中程序的运行方式的话,可以这么看:
GPU 中的每个核可以独立的运行一个线程,那我们就使用 thread 来代表 GPU 中的核,但一个 GPU 中的核数量很多,就需要有更高级的结构对全部用到的核进行约束、管理,这就是 block (块),一个块中可以包含多个核,并且这些核在逻辑上的排布可以是三维的,在一个块中我们可以使用一个 dim3 类型的量 threadIdx 来表示每个核所处的位置,threadIdx.x、threadIdx.y、threadIdx.z 分别表示在三个维度上的坐标;此外,每个块还带有一个 dim3 类型的属性 blockDim,blockDim.x、blockDim.y、blockDim.z 分别表示该 block 三个维度上各有多少个核,这个 block 中的总核数为 blockDim.x * blockDim.y * blockDim.z;
我们一次使用的多个 block,最好能使用一个容器把他们都包起来,这就是 grid,类比于上文中 thread 和 block 的关系,block 和 grid 也有相似的关系。我们使用 blockIdx.x、blockIdx.y、blockIdx.z 表示每个 block 在 grid 中的位置;同样,grid 也具有 gridDim.x、gridDim.y 和 gridDim.z 三个属性以及三者相乘的总 block 数。
知道了上面这些知识后,我们可以对 “kernel_name <<<>>>();” 中尖括号中的参数做一个更具体的解释,它应该被定义为在 GPU 中执行这一核函数的所有核的组织形式,以 "kernel_name <<< number_of_blocks, thread_per_block>>> (arguments)" 的形式使用,一个典型的示例如下:
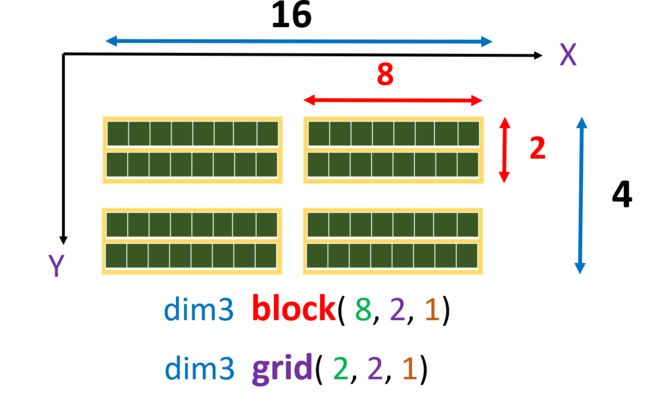
int nx = 16;
int ny = 4;
dim3 block(8, 2); // z默认为1
dim3 grid(nx/8, ny/2);
addKernel << > >(c, a, b);
这一示例中创建了一个有 (2*2) 个 block 的 grid,每个 block 中有 (8*2) 个 thread,下图给出了更直观的表述:
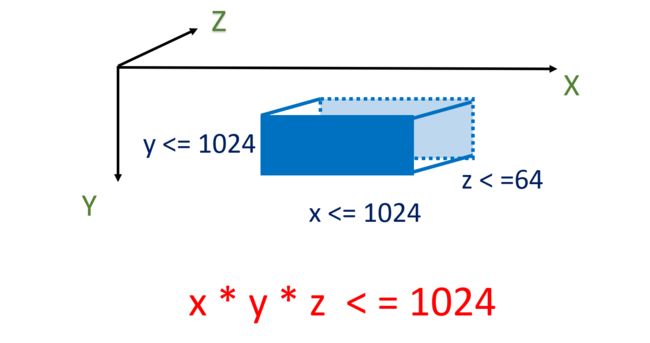
需要注意的是,对 block、grid 的尺寸定义并不是没有限制的,一个 GPU 中的核的数量同样是有限制的。对于一个 block 来说,总的核数不得超过 1024,x、y 维度都不得超过 1024,z 维度不得超过 64,如下图
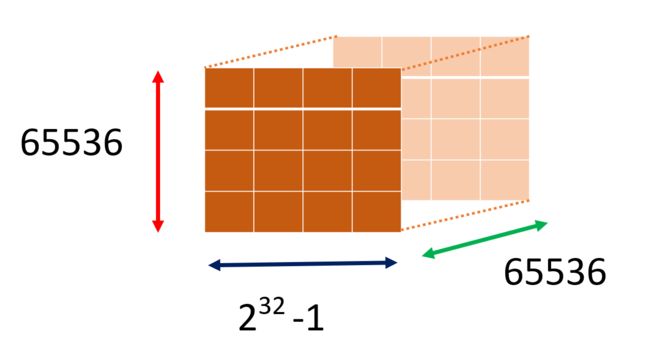
对于整个 grid 而言,x 维度上不得有超过 232−1232−1 个 thread,注意这里是 thread 而不是 block,在其 y 维度和 z 维度上 thread 数量不得超过 65536.
在 cuda 编程中我们经常会把数组的每一个元素分别放到单独的一个核中处理,我们可以利用核的索引读取数组中的数据进行操作,但由于 block、grid 的存在,索引的获取需要一定的计算,在 exercise2 中给出了一个 3D 模型中取值的训练,实现如下
__global__ void print_array(int *input)
{
int tid = (blockDim.x*blockDim.y)*threadIdx.z + blockDim.x*threadIdx.y + threadIdx.x;
int xoffset = blockDim.x * blockDim.y * blockDim.z;
int yoffset = blockDim.x * blockDim.y * blockDim.z * gridDim.x;
int zoffset = blockDim.x * blockDim.y * blockDim.z * gridDim.x * gridDim.y;
int gid = zoffset * blockIdx.z + yoffset * blockIdx.y + xoffset * blockIdx.x + tid;
printf("blockIdx.x : %d, blockIdx.y : %d, blockIdx.z : %d,gid : %d, value: %d\n", blockIdx.x, blockIdx.y, blockIdx.z, gid, input[gid]);
}
3. 数据在 host 和 device 之间的迁移
我们前边提到,cuda 的编程步骤是将数据移入 GPU,待计算完成后将其取出,官方对可能涉及到的内存操作类的操作都给出了接口。
首先是 cudaMemCpy 函数,其定义为
cudaError_t cudaMemcpy ( void* dst, const void* src, size_t count, cudaMemcpyKind kind )
该函数是将数据从 CPU 移入到 GPU 或者从 GPU 移出到 CPU 中,参数 0 指向目标区域的地址,参数 1 指向数据的源地址,参数 2 表示要移动的数据的字节数,最后一个参数表示数据的移动方向(cudaMemcpyHostToDevice、cudaMemcpyDeviceToHost 或 cudaMemcpyDeviceToDevice)
此外,对应 C 语言的内存空间操作,cuda 也推出了 CudaMalloc, CudaMemset, CudaFree 三个接口
cudaError_t cudaMalloc ( void** devPtr, size_t size );
cudaError_t cudaMemset ( void* devPtr, int value, size_t count );
cudaError_t cudaFree ( void* devPtr );
这里需要注意的一个点是 cudaMalloc 的第一参数的数据类型为 void**,这一点怎么理解呢?
这里我们结合一个示例进行解释:
int *d_input;
cudaMalloc((void **) &d_input, bytesize);
之所以使用 void,是因为这一步只管分配内存,不考虑如何解释指针,所以只需要传入待分配内存的地址,不需要传入具体的类型,其他 API 中的 void* 也是同理。为什么是两个 * 呢,这是因为我们在定义 d_input 时是定义了主存中的一个指针,它指向主存中的一个地址;而 & d_input 则是取得了存储该指针值的地址,cudaMalloc 利用这一地址将在 GPU 中分配给该缓冲区的首地址赋值给 d_input。
利用上述的几个接口函数,我们就可以实现一个基本的 cuda 程序的主函数:
int main()
{
const int arraySize = 64;
const int byteSize = arraySize * sizeof(int);
int *h_input,*d_input;
h_input = (int*)malloc(byteSize);
cudaMalloc((void **)&d_input,byteSize);
srand((unsigned)time(NULL));
for (int i = 0; i < 64; ++i)
{
if(h_input[i] != NULL)h_input[i] = (int)rand()& 0xff;
}
cudaMemcpy(d_input, h_input, byteSize, cudaMemcpyHostToDevice);
int nx = 4, ny = 4, nz = 4;
dim3 block(2, 2, 2);
dim3 grid(nx/2, ny/2, nz/2);
print_array << < grid, block >> > (d_input);
cudaDeviceSynchronize();
cudaFree(d_input);
free(h_input);
return 0;
}
其中 cudaDeviceSynchronize (); 的作用是在此处等待 GPU 中计算完成后再继续执行后续的代码。
4 错误处理
在 C++ 中,可以使用异常机制处理运行时错误,而 cuda 编程中由于 Host 和 Device 共同使用,难以利用异常机制,因此,cuda 提供了检测运行时错误的机制。
看上面的 API 时会发现,每个函数的返回值类型都是 cudaError_t ,这正是 cuda 提供的错误检测机制,如果返回值是 cudaSuccess 则说明执行正确,否则就是出现了错误。可以使用 cudaGetErrorString ( error ) 获取返回值的代表的错误的文本。前面的代码中没有使用这一机制主要是为了便于阅读,但实际的使用中这一机制是必不可少的,也会看到 VS 生成的 demo 代码中就包含着大量的错误检测代码
cudaStatus = cudaSetDevice(0);
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaSetDevice failed! Do you have a CUDA-capable GPU installed?");
goto Error;
}
cudaStatus = cudaMalloc((void**)&dev_c, size * sizeof(int));
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaMalloc failed!");
goto Error;
}
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaMalloc failed!");
goto Error;
}
cudaStatus = cudaMalloc((void**)&dev_a, size * sizeof(int));
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaMalloc failed!");
goto Error;
}
...
...
5 其他
-
不同的 block_size 计算耗时会不同,可以多尝试后选择计算的更快的参数(学 DL 的调参是吧,这也搞黑盒?);考虑 GPU 的计算时间时要考虑数据移入移出 GPU 的时间。
-
不同的 GPU 有不同的性质,设备中也可能存在多个 GPU,在设计程序时需要考虑这些问题,cuda 也提供了访问这些信息的接口
// 获取设备数量 int deviceCount = 0; cudaGetDeviceCount(&deviceCount); //获取第一个设备的各项性质 int devNo = 0; cudaDeviceProp iProp; cudaGetDeviceProperties(&iprop, devNo);