干货!基于层次适应的零样本学习
点击蓝字

关注我们
AI TIME欢迎每一位AI爱好者的加入!

针对视觉-语义异构特征难对准的问题,我们提出一种层次视觉-语义层次适应的学习模型,通过同时进行结构对准和分布对准,学习一个具有结构和分布一致性的公共子空间,避免当前学习模型只进行分布对准而造成视觉和语义分布在不同的子流形上,从而有效提高零样本学习识别精度。并为其他visual-language 学习系统进行多模态表示提供了新的研究视野。
本期AI TIME PhD直播间,我们邀请到华中科技大学电信学院2019级博士生——陈使明,为我们带来报告分享《基于层次适应的零样本学习》。

陈使明:
华中科技大学电信学院2019级博士生。他以第一作者在NeurIPS, ICCV, AAAI等人工智能和机器学习领域顶级会议中发表过多篇学术论文。他的主要研究方向是生成建模与学习,零样本学习。指导老师为尤新革教授。
根据生物学家研究表明,人类能够辨别的物体数量多达3万个。然而在机器学习之中,我们很难去收集如此大的数据集去训练一个机器学习模型。此外,我们现实世界的类类别数目会不断增加,直接限制了当前智能模型的学习。
那么,我们如何将机器学习模型从已见类推广到未见类?零样本学习于2008年首次提出。
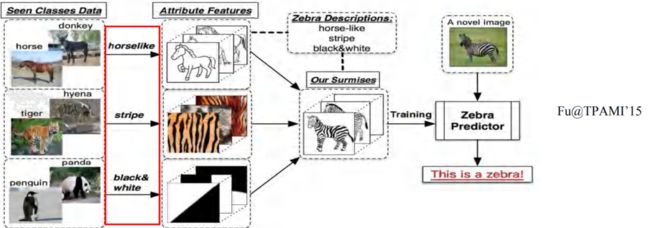
举例:假设学生们见过马和老虎,但是没有见过斑马。但是老师告诉学生们,斑马是一种较小的马且具有和老虎一样的条纹。那么,学生见到斑马的时候能快速地认出斑马。老师的描述信息,就是我们能够快速获取到的语义信息。
零样本学习形式化表示:
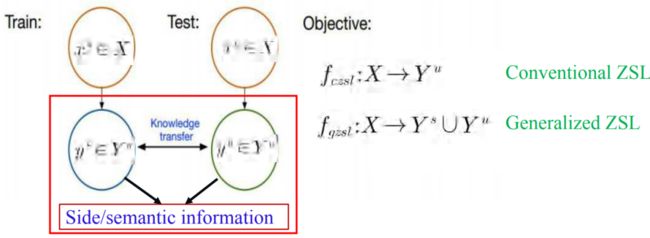
在已见类上训练一个模型,在未见类上进行测试。为实现上述过程,我们需要一个Side information连接已见类和未见类,从而实现知识迁移。零样本学习根据分类范围可以分为:广义的样本学习和传统的样本学习。
传统的样本学习在测试的时候只对未见类进行分类;
广义的样本学习在测试的时候会对已见类和未见类都进行分类。
零样本学习的关键目标是保证从已见类到未见类发生好的知识迁移。关键任务是对视觉和语义进行准确的交互。
通常进行有效视觉-语义交互的就是公共空间学习,如下图所示:
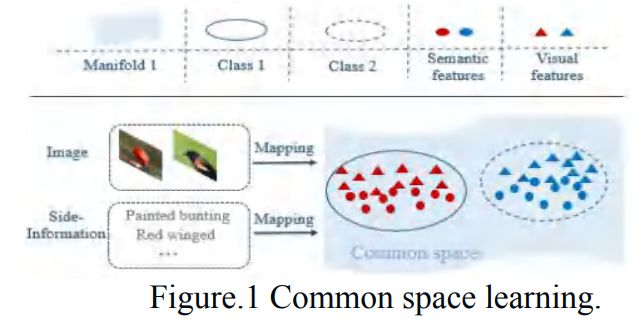
公共空间学习就是指将视觉和语义同时映射到一个公共空间,然后在学习出这个mapping之后对未见类的语义映射到公共空间,进而生成大量的未见类样本。最后,将这些样本与已见类样本一起训练一个分类器并进行测试。这样,我们就完成了将一个零样本学习问题转化成了一个有监督的分类问题。
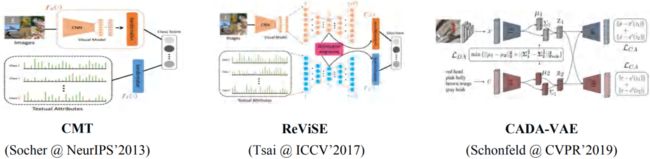
已经有大量的工作基于公共空间学习进行零样本学习表示。
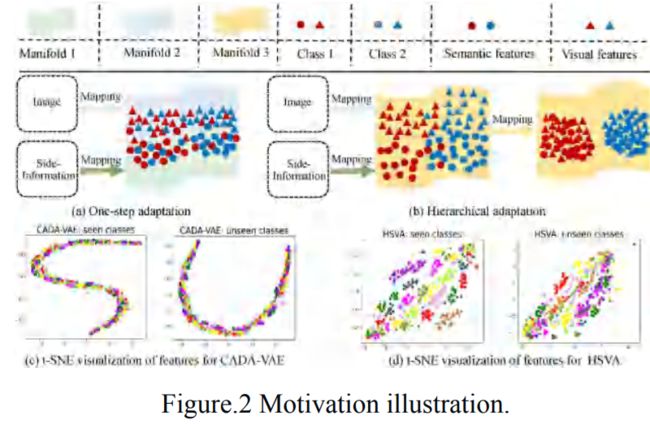
当前工作通常只进行单步预适应,即将视觉和语义特征进行分步对准。然而视觉和语义为异构特征表示,二者具有分布和结构的差异性。
为此,由于单步域适应的不全面,使得视觉和语义分布在不同的子流形上,如图2(c)。为解决此问题,我们可否只学习一个本真的公共空间,同时进行分布和结构的对准,最终获得一个较好的公共空间,如图2(d)?我们提出一种层次域适应(Hierarchical adaptation)的方法来实现此目的。
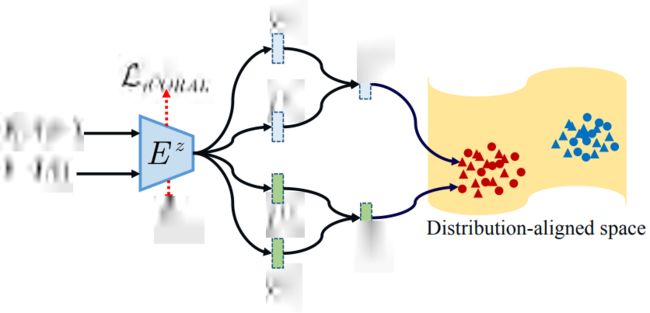
我们提出一个Hierarchical Semantic-Visual Adaptation (HSVA)方法。该方法包含了结构适应与分布适应两个过程。
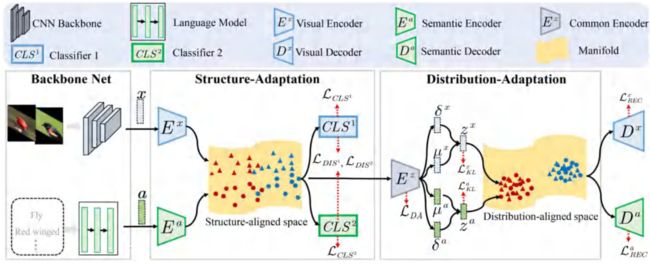
整个模型由两个局部对准的自编码器组成:视觉编码器、语义编码器、公共编码器和两个解码器。
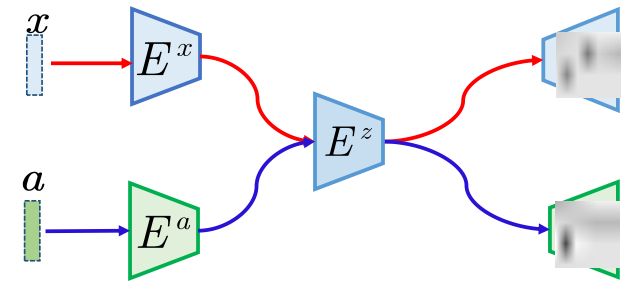
我们利用两个VAE损失以及跨重构损失进行优化。
为实现结构预适应,我们提出一个自监督的对抗差异性学习方法。
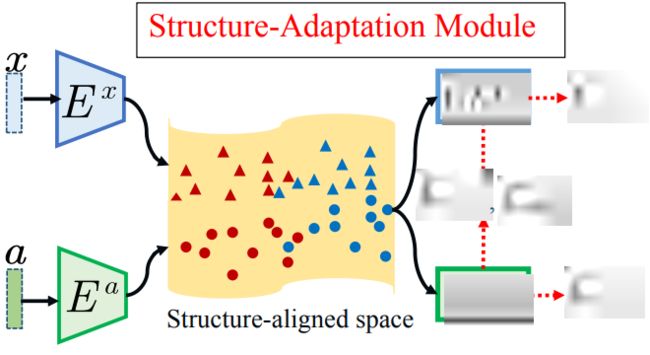
我们希望Ex与Ea的映射尽可能地一致。我们通过两个分类器去度量视觉与语义映射到公共空间的差异性,从而通过最小化差异性而实现不同类别视觉和语义重叠的问题。对于分类器而言,我们需要最大化他们的差异性。对于编码器而言,我们希望他们的差异性尽可能地小,从而形成对抗优化的过程。该过程包括3个优化:
(1)对分类器进行分类初始化
(2)对分类器进行差异性最大化
(3)对编码器进行差异性最小化。从而将不同类别的视觉和语义尽可能地重叠。
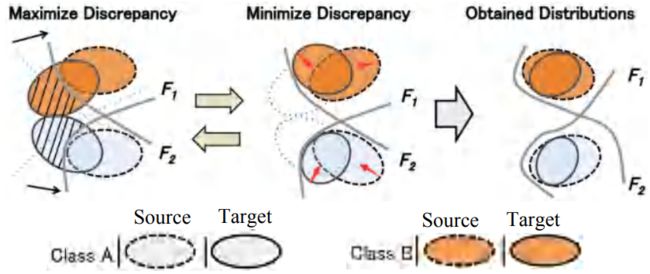
在分布预适应的过程中,我们采用的方法与已有的方法类似,即通过视觉与语义的均值和协方差进行对准的过程,通过最小化Wasserstein Distance的方式.由于在广义零样本学习中,未见类常常会过拟合到已见类,我们提出Inverse CORAL这样一个损失约束,使得未见类和已见类尽可能地分开。
实验
数据集:Fine-grained datasets (CUB, SUN), Coarse-grained datasets (AWA2)
评价指标:
在传统的零样本学习任务中:
acc: Top-1 accuracy on unseen classes
在广义零样本学习任务中:
S: Top-1 accuracy on seen classes
U: Top-1 accuracy on unseen classes
H: S and U的调和平均数
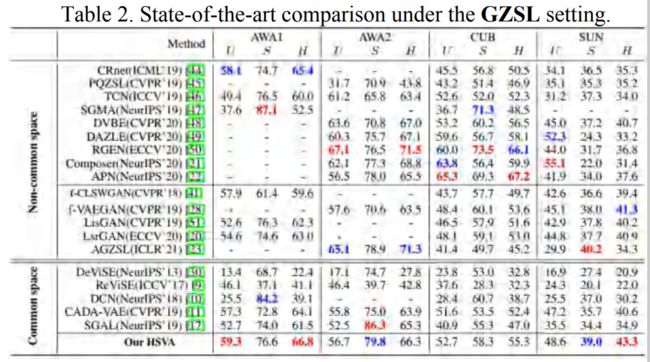
实验对比
在传统零样本学习之中,我们的方法与其他已有的公共空间学习方法相比具有明显优势。

在广义零样本学习中,我们对多种不同范式方法对比,也能发现我们的方法具有较优效果。
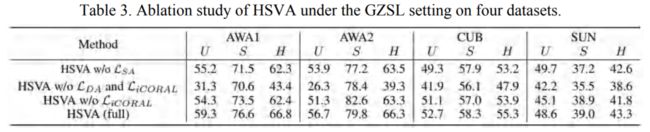
我们进一步做了消融实验,验证不同模块的损失效果。
下面我们给出在没有分布和结构预适应的情况下,视觉和语义特征的t-SNE可视化:

不同颜色表示不同类,◯表示视觉,×表示语义;在没有分布预适应的时候,不同类别可以分得开。不过语义会不断重叠,因为没有抽样过程。在没有结构预适应的时候,类似于已有的传统公共空间学习方法,使得视觉与语义分布在不同的子流形上。
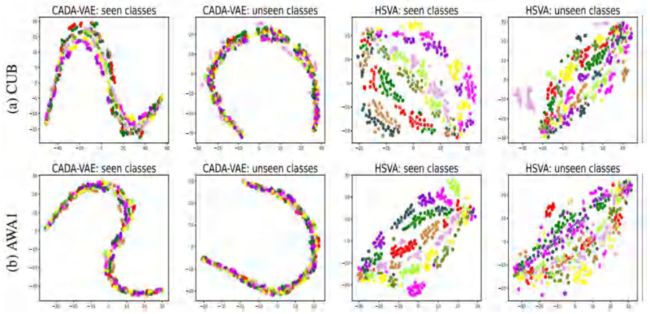
CADA-VAE是当前比价流行的公共子空间学习方法,HSVA是我们提出的方法。可以看出我们的方法得到的视觉特征更具有判别性,不同类别的视觉和语义重叠的很好,而且具有差异性。
结论
我们描述了异构特征表示包含结构和分布变化的事实。它将有助于开发更强大的视觉和语言学习系统,如ZSL、VQA、Image Captioning、异构域适应等。
我们提出了一种分层的语义-视觉适应方法来学习ZSL的公共子空间。
我们进行了大量的实验来验证我们模型的有效性。
提
醒
论文题目:
HSVA: Hierarchical Semantic-Visual Adaptation for Zero-Shot Learning
论文链接:
https://proceedings.neurips.cc/paper/2021/file/8b0d268963dd0cfb808aac48a549829f-Paper.pdf
点击“阅读原文”,即可观看本场回放
整理:林则
审核:陈使明
往期精彩文章推荐

记得关注我们呀!每天都有新知识!
关于AI TIME
AI TIME源起于2019年,旨在发扬科学思辨精神,邀请各界人士对人工智能理论、算法和场景应用的本质问题进行探索,加强思想碰撞,链接全球AI学者、行业专家和爱好者,希望以辩论的形式,探讨人工智能和人类未来之间的矛盾,探索人工智能领域的未来。
迄今为止,AI TIME已经邀请了550多位海内外讲者,举办了逾300场活动,超120万人次观看。

我知道你
在看
哦
~
![]()
点击 阅读原文 查看回放!