Flink专题二:Flink DataStream API 介绍及使用
由于工作需要最近学习flink
现记录下Flink介绍和实际使用过程
这是flink系列的第二篇文章
Flink DataStream API 介绍及使用
- Flink 中的 API
- DataStream 介绍
- DataStream API 程序剖析
-
- 获取一个执行环境
- 加载/创建初始数据
- 指定数据相关的转换
- 指定计算结果的存储位置
- 触发程序执行
Flink 中的 API
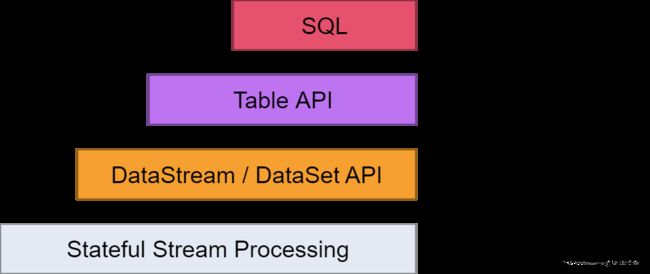
这里介绍我们常用的DataStream API:
Flink API 第二层抽象是 Core APIs。实际上,许多应用程序不需要使用到上述最底层抽象的 API,而是可以使用 Core APIs 进行编程:其中包含 DataStream API(应用于有界/无界数据流场景)和 DataSet API(应用于有界数据集场景)两部分。Core APIs 提供的流式 API(Fluent API)为数据处理提供了通用的模块组件,例如各种形式的用户自定义转换(transformations)、联接(joins)、聚合(aggregations)、窗口(windows)和状态(state)操作等。此层 API 中处理的数据类型在每种编程语言中都有其对应的类。
DataStream 介绍
DataStream API 得名于特殊的 DataStream 类,该类用于表示 Flink 程序中的数据集合。你可以认为 它们是可以包含重复项的不可变数据集合。这些数据可以是有界(有限)的,也可以是无界(无限)的,但用于处理它们的API是相同的。
DataStream 在用法上类似于常规的 Java
集合,但在某些关键方面却大不相同。它们是不可变的,这意味着一旦它们被创建,你就不能添加或删除元素。你也不能简单地察看内部元素,而只能使用
DataStream API 操作来处理它们,DataStream API 操作也叫作转换(transformation)。
你可以通过在 Flink 程序中添加 source 创建一个初始的 DataStream。然后,你可以基于 DataStream 派生新的流,并使用 map、filter 等 API 方法把 DataStream 和派生的流连接在一起。
DataStream API 程序剖析
Flink 程序看起来像一个转换 DataStream 的常规程序。每个程序由相同的基本部分组成:
- 获取一个执行环境(execution environment);
- 加载/创建初始数据;
- 指定数据相关的转换;
- 指定计算结果的存储位置;
- 触发程序执行。
获取一个执行环境
StreamExecutionEnvironment 是所有 Flink 程序的基础。你可以使用
StreamExecutionEnvironment 的如下静态方法获取 StreamExecutionEnvironment:
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
通常,你只需要使用 getExecutionEnvironment() 即可,因为该方法会根据上下文做正确的处理:如果你在 IDE 中执行你的程序或将其作为一般的 Java 程序执行,那么它将创建一个本地环境,该环境将在你的本地机器上执行你的程序。如果你基于程序创建了一个 JAR 文件,并通过命令行运行它,Flink 集群管理器将执行程序的 main 方法,同时 getExecutionEnvironment() 方法会返回一个执行环境以在集群上执行你的程序。
加载/创建初始数据
为了指定 data sources,执行环境提供了一些方法,可以使用任何第三方提供的 source。
这里介绍使用最多的Flink提供的kafka连接器,加入下方依赖后及可使用。
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka_2.11</artifactId>
<version>1.14.3</version>
</dependency>
Properties properties = new Properties();
properties.setProperty("bootstrap.servers", "localhost:9092");
properties.setProperty("group.id", "test");
DataStream<String> stream = env
.addSource(new FlinkKafkaConsumer<>("topic", new SimpleStringSchema(), properties));
同时也可以使用union合并多个流,新的流包含所有流的数据。
DataStream<Map> dataStream = null;
dataStream = dataStream .union(mapStream1);
dataStream = dataStream .union(mapStream2);
指定数据相关的转换
得到了 DataStream后,你可以在上面应用转换(transformation)来创建新的派生 DataStream。
你可以调用 DataStream 上具有转换功能的方法来应用转换。
DataStream<String> input = ...;
DataStream<Integer> parsed = input.map(new MapFunction<String, Integer>() {
@Override
public Integer map(String value) {
return Integer.parseInt(value);
}
});
具体哪些方法可以参考下 我的下一篇博客 Flink专题三:Flink DataStream 算子介绍及使用
指定计算结果的存储位置
一旦你有了包含最终结果的 DataStream,你就可以通过创建 sink 把它写到外部系统。下面是一些用于创建 sink 的示例方法:
storeDataStream.addSink(new ClickHouseSink(SinkDbUtils.getDbConnParam()))
.setParallelism(2))
.name("clickhouse-sink");
一个Flink程序由多个Operator(source、transformation和 sink)组成。
一个Operator可以由多个并行的Task(线程)来执行,
一个Operator的并行Task(线程)数目就被称为该Operator(任务)的并行度(Parallel)
一个算子、数据源和sink的并行度可以通过调用 setParallelism()方法来指定
触发程序执行
一旦指定了完整的程序,需要调用 StreamExecutionEnvironment 的 execute() 方法来触发程序执行。根据 ExecutionEnvironment 的类型,执行会在你的本地机器上触发,或将你的程序提交到某个集群上执行。
env.execute("DataStream-test");