word2vec原理(三): 基于Negative Sampling的模型
目录
1. Hierarchical Softmax的缺点与改进
2. Negative Sampling(负采样) 概述
3. 基于Negative Sampling的模型梯度计算
4. Negative Sampling负采样方法
5. 基于Negative Sampling的CBOW模型
6. 基于Negative Sampling的Skip-Gram模型
7. Negative Sampling的模型源码和算法的对应
1. Hierarchical Softmax的缺点与改进
在讲基于Negative Sampling的word2vec模型前,我们先看看Hierarchical Softmax的的缺点。的确,使用霍夫曼树来代替传统的神经网络,可以提高模型训练的效率。但是如果我们的训练样本里的中心词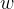 是一个很生僻的词,那么就得在霍夫曼树中辛苦的向下走很久了。能不能不用搞这么复杂的一棵霍夫曼树,将模型变的更加简单呢?
是一个很生僻的词,那么就得在霍夫曼树中辛苦的向下走很久了。能不能不用搞这么复杂的一棵霍夫曼树,将模型变的更加简单呢?
Negative Sampling就是这么一种求解word2vec模型的方法,它摒弃了霍夫曼树,采用了Negative Sampling(负采样)的方法来求解,下面我们就来看看Negative Sampling的求解思路。
2. Negative Sampling(负采样) 概述
既然名字叫Negative Sampling(负采样),那么肯定使用了采样的方法。采样的方法有很多种,比如之前讲到的大名鼎鼎的MCMC。我们这里的Negative Sampling采样方法并没有MCMC那么复杂。
比如我们有一个训练样本,中心词是,它周围上下文共有![]() 个词,记为
个词,记为![]() 。由于这个中心词的确和
。由于这个中心词的确和![]() 相关存在,因此它是一个真实的正例。通过Negative Sampling采样,我们得到neg个和不同的中心词
相关存在,因此它是一个真实的正例。通过Negative Sampling采样,我们得到neg个和不同的中心词![]() ,i=1,2,..neg,这样
,i=1,2,..neg,这样![]() 和
和![]() 就组成了neg个并不真实存在的负例。利用这一个正例和neg个负例,我们进行二元逻辑回归,得到负采样对应每个词
就组成了neg个并不真实存在的负例。利用这一个正例和neg个负例,我们进行二元逻辑回归,得到负采样对应每个词![]() 的模型参数
的模型参数![]() ,和每个词的词向量。(和
,和每个词的词向量。(和![]() 都是中心词)
都是中心词)
从上面的描述可以看出,Negative Sampling由于没有采用霍夫曼树,每次只是通过采样neg个不同的中心词做负例,就可以训练模型,因此整个过程要比Hierarchical Softmax简单。
不过有两个问题还需要弄明白:1)如果通过一个正例和neg个负例进行二元逻辑回归呢? 2) 如何进行负采样呢?
我们在第三节讨论问题1,在第四节讨论问题2.
3. 基于Negative Sampling的模型梯度计算
Negative Sampling也是采用了二元逻辑回归来求解模型参数,通过负采样,我们得到了neg个负例![]() )。为了统一描述,我们将正例定义为
)。为了统一描述,我们将正例定义为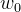 。
。


4. Negative Sampling负采样方法
现在我们来看看如何进行负采样,得到neg个负例。word2vec采样的方法并不复杂,如果词汇表的大小为![]() ,那么我们就将一段长度为1的线段分成
,那么我们就将一段长度为1的线段分成![]() 份,每份对应词汇表中的一个词。当然每个词对应的线段长度是不一样的,由词的个数占比确定,高频词对应的线段长,低频词对应的线段短:
份,每份对应词汇表中的一个词。当然每个词对应的线段长度是不一样的,由词的个数占比确定,高频词对应的线段长,低频词对应的线段短:

在采样前,我们将这段长度为1的线段划分成 等份,这里
等份,这里![]() ,这样可以保证每个词对应的线段都会划分成对应的小块。而份中的每一份都会落在某一个词对应的线段上。在采样的时候,我们只需要从个位置中采样出neg个位置就行,此时采样到的每一个位置对应到的线段所属的词就是我们的负例词。
,这样可以保证每个词对应的线段都会划分成对应的小块。而份中的每一份都会落在某一个词对应的线段上。在采样的时候,我们只需要从个位置中采样出neg个位置就行,此时采样到的每一个位置对应到的线段所属的词就是我们的负例词。

在word2vec中,M取值默认为![]() 。
。
5. 基于Negative Sampling的CBOW模型

6. 基于Negative Sampling的Skip-Gram模型

7. Negative Sampling的模型源码和算法的对应
这里给出上面算法和word2vec源码中的变量对应关系。
在源代码中,基于Negative Sampling的CBOW模型算法在464-494行,基于Hierarchical Softmax的Skip-Gram的模型算法在520-542行。大家可以对着源代码再深入研究下算法。
在源代码中,neule对应我们上面的e, syn0对应我们的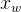 , syn1对应我们的
, syn1对应我们的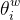 , layer1_size对应词向量的维度,window对应
, layer1_size对应词向量的维度,window对应 。negative对应我们的neg, table_size对应我们负采样中的划分数。
。negative对应我们的neg, table_size对应我们负采样中的划分数。
另外,vocab[word].code[d]指的是,当前单词word的,第d个编码,编码不含Root结点。vocab[word].point[d]指的是,当前单词word,第d个编码下,前置的结点。这些和基于Hierarchical Softmax的是一样的。
以上就是基于Negative Sampling的word2vec模型。
例子:
词典V大小之所以会在目标函数中出现,是因为中心词w c生成背景词w o的概率P ( w o ∣ w c )使用了softmax,而softmax正是考虑了背景词可能是词典中的任一词,并体现在softmax的分母上。
我们不妨换个角度,假设中心词wc生成背景词w o由以下相互独立事件联合组成来近似中心词 w c 和背景词 w o 同时出现在该训练数据窗口中心词 w c 和第1个噪声词 w 1 不同时出现在该训练数据窗口(噪声词 w 1 按噪声词分布 P ( w ) 随机生成,假设一定和 w c 不同时出现在该训练数据窗口)…中心词 w c 和第k个噪声词 w K 不同时出现在该训练数据窗口(噪声词 w K 按噪声词分布 P ( w ) 随机生成,假设一定和 w c 不同时出现在该训练数据窗口)
我们可以使用σ ( x ) = 1 / ( 1 + exp ( − x ) )函数来表达中心词w c和背景词w o同时出现在该训练数据窗口的概率:

当我们把K取较小值时,每次随机梯度下降的梯度计算开销将由O ( | V | )降为O ( K )。

同样地,当我们把K取较小值时,每次随机梯度下降的梯度计算开销将由O ( | V | )降为O ( K )。
层序softmax补充
层序softmax利用了二叉树。树的每个叶子节点代表着词典V中的每个词。每个词w i相应的词向量为v i。我们以下图为例,来描述层序softmax的工作机制。

假设l( w )为从二叉树的根到代表词w的叶子节点的路径上的节点数,并设n( w , i )为该路径上第i个节点,该节点的向量为u n ( w , i )。以上图为例,l( w 3 ) = 4。那么,跳字模型和连续词袋模型所需要计算的任意词w i生成词w的概率为:

我们可以使用随机梯度下降在跳字模型和连续词袋模型中不断迭代计算字典中所有词向量v和非叶子节点的向量u。每次迭代的计算开销由O ( | V | )降为二叉树的高度O ( log | V | )。