ROS+Gazebo强化学习从虚拟训练到实车部署全流程分析
也学ros这个东西学了好长时间了,但是在ROS中进行强化学习并最终部署到实车这个过程一直都出现各种问题,实验室也没什么相关的积累,自己一个人搞就很痛苦。这次看论文时候看到别人公布的源码,于是去学习了一下别人怎么做的这个流程,真的是受益匪浅。
最终也能够实现从虚拟训练到实车部署这整个过程了!
现在把整个流程总结下来,后面关键部分的描述都在注释里面,希望实验室之后的学弟学妹们能轻松做实验带带学长发文章,也希望能够帮到各位刚接触ROS的同学们~!
(另外不知道为啥直接上传的md文件还会出现一些奇怪的格式问题,但也懒得处处改了,各位担待着看吧)
一 、运行一个示例
1、前提准备
(1)下载代码
使用了 Goal-Driven Autonomous Exploration Through Deep Reinforcement Learning 这篇论文作为例子,上面的流程可以给我们一个很好的示范,其github网址为:
https://github.com/reiniscimurs/DRL-robot-navigation
将其解压,我们可以得到如下的文件结构:
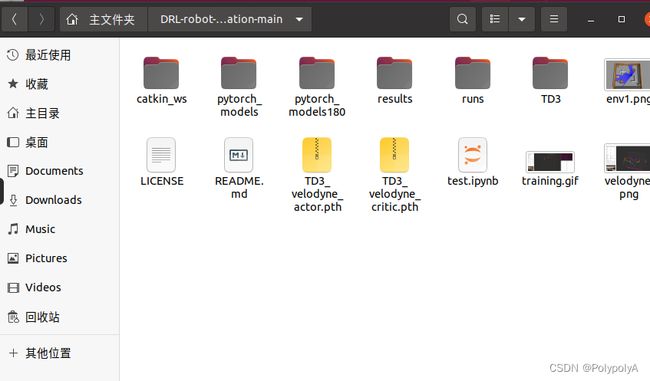
其中 **catkin_ws **为ROS工作空间,包含了gazebo仿真环境、p3dx小车模型、velody激光雷达模型等。但其主要任务就是打开一个仿真环境
TD3 中包含了文章中介绍的算法,其内部结构如下:

velodyne_env 是发送订阅数据、处理数据、获取状态、计算奖励等功能的代码,相当于gym中的环境部分
train_velodyne_td3 是训练代码,其中包括了网络结构以及训练部分。
(2)python环境
我们需要在Ubuntu环境中安装Anaconda,创建虚拟环境,安装好如pytorch之类的库,这部分想必各位既然已经开始做ROS了都有经验,不再赘述。
(3)ROS环境
用ROS当然需要安装ROS环境!我这里用的是Ubuntu 20.04 +ROS1 noetic版本
2、 进行仿真训练
(1)对工作空间进行编译
进入到catkin_ws工作空间内,打开一个终端
cd ~/DRL-robot-navigation-main/catkin_ws
catkin_make
在编译过程中,可能会出现各种各样的库缺失,具体缺失的内容可以读取报错信息,然后安装
sudo apt install ros-noetic-$ 你缺失的库 $
(2)运行训练文件
进入到TD3文件夹下,打开终端,cd到路径,python运行,这里会发现可能还是会缺少很多的库,这里我们使用pip install 安装
python train_velodyne_td3.py
按照其github上面所说,这样就可以进行训练了。但实际操作过程中发现这样无法打开gazebo,也会出现各种奇怪的报错,于是对其进行了如下更改
(3)更改部分
①手动创建launch文件
cd ./DRL-robot-navigation-main/catkin_ws/src/multi_robot_scenario/launch
我们可以看到这里面的文件,TD3.world,这里面就是其gazebo 的仿真环境文件,我们可以创建一个新的launch文件,用于打开这个.world文件
创建一个新的launch文件,命名为 TD3_world.launch
在其中输入如下内容
<launch>
<include file="$(find gazebo_ros)/launch/empty_world.launch">
<arg name="world_name" value="$(find multi_robot_scenario)/launch/TD3.world"/>
<arg name="paused" value="false"/>
<arg name="use_sim_time" value="true"/>
<arg name="gui" value="true"/>
<arg name="headless" value="false"/>
<arg name="debug" value="false"/>
include>
launch>
②打开环境
打开一个新的终端
cd DRL-robot-navigation-main/catkin_ws/
catkin_make
source devel/setup.sh
roslaunch multi_robot_scenario TD3_world.launch

那么我们就能够打开这个仿真环境了,但是我们发现这里并没有我们需要的机器人模型,所以我们还需要打开launch文件夹下的pioneer3dx.gazebo.launch文件,则新建一个终端
cd DRL-robot-navigation-main/catkin_ws/
source devel/setup.sh
roslaunch multi_robot_scenario pioneer3dx.gazebo.launch
那么我们就可以在仿真环境内看到移动机器人了
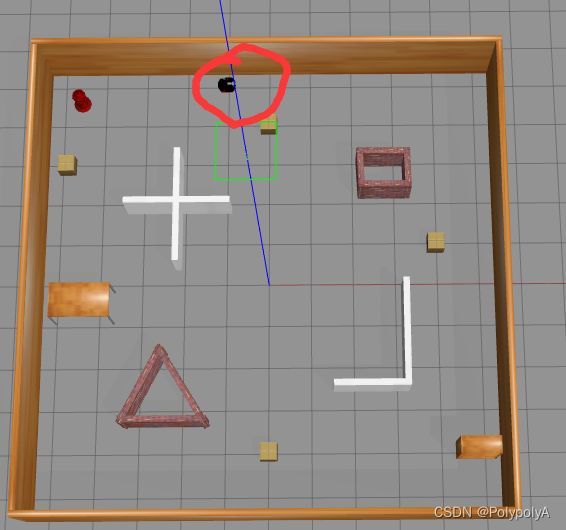
③修改velody_env.py文件
接下来我们 python运行 train_velody_td3.py时候会发现,依旧会报一堆乱七八糟的错误。
我们需要对如下内容进行更改:
a: 将文件中所有的**"r1"改为“p3dx”**
包括82行、116行、130行
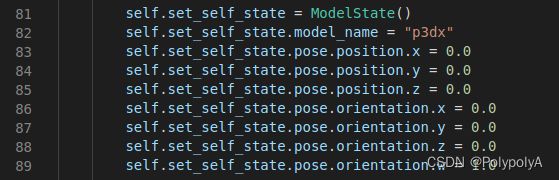

这是由于如果不修改的话,他会将机器人命名为r1,但是我们直接打开,机器人是p3dx,当然也可以在打开过程中修改他的名字r1,但是对于初学者来说直接修改可能更容易理解。
b:注释掉它文件中打开launch文件的部分
主要是98行-113行,但是注意104行初始化节点不要注释

(4)开始训练
接下来就可以愉快的训练了!我个人更喜欢直接在vscode中训练
这里需要选择相应的环境
然后直接run就行了,我们发现它可以运行了!
二、具体部分分析
1、Gazebo仿真环境部分
按照第一大部分运行Gazebo后,通过rostopic list 可以看到目前有如下的话题在ROS中存在

gazebo仿真环境如图所示:

2、velody_env.py文件
(1)init 关键部分
rospy.init_node("gym", anonymous=True) #初始化ros节点
#--------------------------发布内容----------------------------
self.vel_pub = rospy.Publisher("/p3dx/cmd_vel", Twist, queue_size=1) #用于发布移动机器人的控制信息
self.set_state = rospy.Publisher(
"gazebo/set_model_state", ModelState, queue_size=10) #用于设置移动机器人的位置、角度信息
self.publisher = rospy.Publisher("goal_point", MarkerArray, queue_size=3) #用于发布目标点
self.publisher2 = rospy.Publisher("linear_velocity", MarkerArray, queue_size=1) #线速度 MarkerArraty算法中无实际作用
self.publisher3 = rospy.Publisher("angular_velocity", MarkerArray, queue_size=1) #角速度 MarkerArray算法中无实际作用
#--------------------------服务内容----------------------------
self.unpause = rospy.ServiceProxy("/gazebo/unpause_physics", Empty) #恢复仿真
self.pause = rospy.ServiceProxy("/gazebo/pause_physics", Empty) #暂停仿真
self.reset_proxy = rospy.ServiceProxy("/gazebo/reset_world", Empty) #重置仿真环境
#--------------------------订阅内容----------------------------
self.velodyne = rospy.Subscriber(
"/velodyne_points", PointCloud2, self.velodyne_callback, queue_size=1) #订阅激光雷达发布的点云
self.odom = rospy.Subscriber(
"/p3dx/odom", Odometry, self.odom_callback, queue_size=1) #订阅里程计信息
(2)step部分
def step(self, action):
target = False
# 发布机器人的动作,这里的step输入是action,action[0]是线速度,action[1]是角速度
vel_cmd = Twist()
vel_cmd.linear.x = action[0]
vel_cmd.angular.z = action[1]
self.vel_pub.publish(vel_cmd)
self.publish_markers(action)
#这里要注意了!!!!!
# 首先unpause,发布消息后,开始仿真
rospy.wait_for_service("/gazebo/unpause_physics")
try:
self.unpause()
except (rospy.ServiceException) as e:
print("/gazebo/unpause_physics service call failed")
# 接下来需要停一小段时间,让小车以目前的速度行驶一段时间,TIME_DELTA = 0.1
time.sleep(TIME_DELTA)
# 然后我们停止仿真,开始观测目前的状态
rospy.wait_for_service("/gazebo/pause_physics")
try:
pass
self.pause()
except (rospy.ServiceException) as e:
print("/gazebo/pause_physics service call failed")
# 检测碰撞
done, collision, min_laser = self.observe_collision(self.velodyne_data)
# 雷达状态
v_state = []
v_state[:] = self.velodyne_data[:]
laser_state = [v_state]
# 从里程计信息中获取小车朝向
self.odom_x = self.last_odom.pose.pose.position.x
self.odom_y = self.last_odom.pose.pose.position.y
quaternion = Quaternion(
self.last_odom.pose.pose.orientation.w,
self.last_odom.pose.pose.orientation.x,
self.last_odom.pose.pose.orientation.y,
self.last_odom.pose.pose.orientation.z,
)
euler = quaternion.to_euler(degrees=False)
angle = round(euler[2], 4)
# 计算到目标点的距离
distance = np.linalg.norm(
[self.odom_x - self.goal_x, self.odom_y - self.goal_y]
)
# 计算偏离角度
skew_x = self.goal_x - self.odom_x
skew_y = self.goal_y - self.odom_y
dot = skew_x * 1 + skew_y * 0
mag1 = math.sqrt(math.pow(skew_x, 2) + math.pow(skew_y, 2))
mag2 = math.sqrt(math.pow(1, 2) + math.pow(0, 2))
beta = math.acos(dot / (mag1 * mag2))
if skew_y < 0:
if skew_x < 0:
beta = -beta
else:
beta = 0 - beta
theta = beta - angle
if theta > np.pi:
theta = np.pi - theta
theta = -np.pi - theta
if theta < -np.pi:
theta = -np.pi - theta
theta = np.pi - theta
# 判断是否到达了目标点
if distance < GOAL_REACHED_DIST:
target = True
done = True
# 输出机器人状态
robot_state = [distance, theta, action[0], action[1]]
state = np.append(laser_state, robot_state)
# 计算奖励
reward = self.get_reward(target, collision, action, min_laser)
# 返回状态、奖励、是否结束、是否到达目标点
return state, reward, done, target
那么我们可以总结出来step的流程
①发布cmd_vel控制话题
②开始仿真,运行0.1s(也可以更改),停止仿真
③获取目前的状态信息
④计算奖励
⑤返回状态、奖励、是否结束等信息
(3)reset部分
def reset(self):
# 重置环境
rospy.wait_for_service("/gazebo/reset_world")
try:
self.reset_proxy()
except rospy.ServiceException as e:
print("/gazebo/reset_simulation service call failed")
angle = np.random.uniform(-np.pi, np.pi)
quaternion = Quaternion.from_euler(0.0, 0.0, angle)
object_state = self.set_self_state
x = 0
y = 0
position_ok = False
while not position_ok:
x = np.random.uniform(-4.5, 4.5)
y = np.random.uniform(-4.5, 4.5)
position_ok = check_pos(x, y)
# 下面通过 /gazebo/set_model_state 话题更改移动机器人的初始位置
object_state.pose.position.x = x
object_state.pose.position.y = y
# object_state.pose.position.z = 0.
object_state.pose.orientation.x = quaternion.x
object_state.pose.orientation.y = quaternion.y
object_state.pose.orientation.z = quaternion.z
object_state.pose.orientation.w = quaternion.w
self.set_state.publish(object_state)
self.odom_x = object_state.pose.position.x
self.odom_y = object_state.pose.position.y
# 更改一个目标点
self.change_goal()
# 更改环境中的小方块障碍物
self.random_box()
self.publish_markers([0.0, 0.0])
#开始仿真
rospy.wait_for_service("/gazebo/unpause_physics")
try:
self.unpause()
except (rospy.ServiceException) as e:
print("/gazebo/unpause_physics service call failed")
#执行一段时间
time.sleep(TIME_DELTA)
#停止仿真,获得目前的状态
rospy.wait_for_service("/gazebo/pause_physics")
try:
self.pause()
except (rospy.ServiceException) as e:
print("/gazebo/pause_physics service call failed")
v_state = []
v_state[:] = self.velodyne_data[:]
laser_state = [v_state]
distance = np.linalg.norm(
[self.odom_x - self.goal_x, self.odom_y - self.goal_y]
)
skew_x = self.goal_x - self.odom_x
skew_y = self.goal_y - self.odom_y
dot = skew_x * 1 + skew_y * 0
mag1 = math.sqrt(math.pow(skew_x, 2) + math.pow(skew_y, 2))
mag2 = math.sqrt(math.pow(1, 2) + math.pow(0, 2))
beta = math.acos(dot / (mag1 * mag2))
if skew_y < 0:
if skew_x < 0:
beta = -beta
else:
beta = 0 - beta
theta = beta - angle
if theta > np.pi:
theta = np.pi - theta
theta = -np.pi - theta
if theta < -np.pi:
theta = -np.pi - theta
theta = np.pi - theta
robot_state = [distance, theta, 0.0, 0.0]
state = np.append(laser_state, robot_state)
#返回状态值
return state
那么我们可以总结出来step的流程
①使用 /gazebo/reset_world 重置仿真环境
②设置环境中的小车、障碍物等的位置
③开始仿真,运行0.1s(也可以更改),停止仿真
④获取目前的状态信息
⑤返回状态信息
(4)reward部分
@staticmethod
def get_reward(target, collision, action, min_laser):
if target:
return 100.0
elif collision:
return -100.0
else:
r3 = lambda x: 1 - x if x < 1 else 0.0
return action[0] / 2 - abs(action[1]) / 2 - r3(min_laser) / 2
这里即计算reward的部分,我们可以自己设定奖励函数,返回reward
(5)总结
那么我们在env部分最关键的代码就介绍完了!
这一部分其实本质上和在gym中没有什么不同,唯一的区别就是这里通过话题的订阅发布获取了环境状态信息。
同时有一个最重要的部分是,我们需要在每一次执行action的时候,让这个action运行那么0.1或者0.05秒,这样我们的小车才能够正常的运行一段距离。如果不设置这个运行时间的话,小车的action就会以最快的速度发布,那么根本就没有办法正常运行,step也会瞬间爆炸。
3、train_velodyne_td3.py文件
这一部分就是训练网络参数的python文件了。
其中的1-287行是TD3网络结构以及各种参数设定,这部分就不介绍了。
从288行的while是训练的主要部分,这部分本质上和在gym中也没有什么不同。拿出其中最重要的流程说一下。
#291
if done:
''''''
#314
state = env.reset()
done = False
# 这部分是当结束本回合后的重置部分,使用env.reset()重置环境,给小车和障碍物重新分配位置,并对其他变量初始化
''''''
#325
action = network.get_action(np.array(state))
#这部分是将我们观测获得的状态输入到神经网络之中,从中获取动作
''''''
#348
a_in = [(action[0]+1)/2,action[1]]
next_state, reward, done, target = env.step(a_in)
#这里我们将动作输入到环境之中,进行step操作,step函数返回next_state,reward,done,target
那么我们可以看到这其实和任何强化学习中的训练步骤都基本一样,最后保存网络参数即可。
三、如何部署到实车上
(1)仿真训练得到好的网络

经过仿真训练后,能够得到ac网络各自的网络参数
(2)网络参数载入
class Actor(nn.Module):
def __init__(self, state_dim, action_dim):
super(Actor, self).__init__()
self.layer_1 = nn.Linear(state_dim, 800)
self.layer_2 = nn.Linear(800, 600)
self.layer_3 = nn.Linear(600, action_dim)
self.tanh = nn.Tanh()
def forward(self, s):
s = F.relu(self.layer_1(s))
s = F.relu(self.layer_2(s))
a = self.tanh(self.layer_3(s))
return a
# TD3 network
class TD3(object):
def __init__(self, state_dim, action_dim):
# Initialize the Actor network
self.device = torch.device("cuda" if torch.cuda.is_available() else "cpu") # cuda or cpu
self.actor = Actor(state_dim, action_dim)
self.actor.load_state_dict(torch.load("/home/polya/DRL-robot-navigation-main/pytorch_models180/TD3_final_actor.pth"))
self.actor = self.actor.to(self.device)
self.max_action = 1
def get_action(self, state):
# Function to get the action from the actor
state = torch.Tensor(state.reshape(1, -1)).to(self.device)
action = self.actor(state).cpu().data.numpy().flatten()
action = action.clip(-self.max_action,self.max_action)
linear_v = (action[0]+1)/2
angle_v = action[1]
return linear_v,angle_v
def load(self, filename, directory):
self.actor.load_state_dict(
torch.load("%s/%s_actor.pth" % (directory, filename))
)
这里我们其实只需要一个actor网络就可以了,函数则只需要一个get_action
当然也可以直接按照之前的网络来写,这样你还可以顺便收集实际数据,进行进一步训练。
(3)实车信息获取与处理
#-------------------Pub and Sub--------------
self.GoalPub = rospy.Publisher("/GoalPoint",Marker,queue_size=10)
self.LaserSub = rospy.Subscriber("/scan",LaserScan,self.LaserScanCallBack)
self.OdomSub = rospy.Subscriber("/odom",Odometry,self.OdomCallBack)
self.goalxSub = rospy.Subscriber("/goal_x",Float32,self.goalxCallBack)
self.goalySub = rospy.Subscriber("/goal_y",Float32,self.goalyCallBack)
这里我是用了一个Publisher 发布/GoalPoint 话题,这个就是把目标点做成Marker发出去,仅仅是为了在Rviz中进行显示
订阅:1、/scan 激光雷达信息,这里我用的是一个2D激光雷达,获取的扫描信息转成了PointCloud2点云信息并用于后面的计算,当然我在训练过程中也用的是一个2D激光雷达进行的训练
2、/odom 里程计信息,用于实时获取实车目前的位置和速度,当然这里你也可以换成什么gps imu之类的信息,只需要最后都转变成为训练时对应的状态输入
3、/goal_x和/goal_y 。 这里是接收我们目标位置的坐标,因为偷懒直接写了两个float32 Subscriber来接收,后面可以改成自定义信息或者什么里程计信息
接下来是整合信息,返回state状态数组
def GetStates(self): #其实这里和之前的velody_env.py中获取信息的方式大同小异
target =False
v_state = []
v_state[:] = self.velodyne_data[:]
#雷达状态输入
laser_state = [v_state]
self.odom_x = self.last_odom.pose.pose.position.x
self.odom_y = self.last_odom.pose.pose.position.y
quaternion = Quaternion(
self.last_odom.pose.pose.orientation.w,
self.last_odom.pose.pose.orientation.x,
self.last_odom.pose.pose.orientation.y,
self.last_odom.pose.pose.orientation.z,
)
euler = quaternion.to_euler(degrees=False)
angle = round(euler[2], 4)
distance = np.linalg.norm(
[self.odom_x - self.goal_x, self.odom_y - self.goal_y]
)
skew_x = self.goal_x - self.odom_x
skew_y = self.goal_y - self.odom_y
dot = skew_x * 1 + skew_y * 0
mag1 = math.sqrt(math.pow(skew_x, 2) + math.pow(skew_y, 2))
mag2 = math.sqrt(math.pow(1, 2) + math.pow(0, 2))
beta = math.acos(dot / (mag1 * mag2))
if skew_y < 0:
if skew_x < 0:
beta = -beta
else:
beta = 0 - beta
theta = beta - angle
if theta > np.pi:
theta = np.pi - theta
theta = -np.pi - theta
if theta < -np.pi:
theta = -np.pi - theta
theta = np.pi - theta
self.dis = distance
if distance < GOAL_REACHED_DIST:
target = True
#机器人状态输入
robot_state = [distance, theta, self.last_odom.twist.twist.linear.x,self.last_odom.twist.twist.angular.z]
print(self.dis)
print(distance)
print(robot_state)
state = np.append(laser_state,robot_state)
# 最后我们返回小车的状态输入,包括雷达输入和机器人状态输入以及是否到达了目标位置
return state,target
(4)简单的执行部分
rospy.init_node("my_car") #初始化节点
car = mycar() #实例化实车信息获取类
# --------偷懒的目标点发布---------------
xpub = rospy.Publisher("/goal_x",Float32,queue_size=10)
ypub = rospy.Publisher("/goal_y",Float32,queue_size=10)
xpub.publish(2.5)
ypub.publish(0.5)
network = TD3(24,2) #实例化TD3网络
pub = rospy.Publisher("/cmd_vel",Twist,queue_size=10) #/cmd_vel发布,用于控制小车的运动
rate = rospy.Rate(10) #等待频率,相当于仿真环境中的DELTA_TIME
while not rospy.is_shutdown():
state,target = car.GetStates() #获取状态信息
if not target:
linear_x,angular_z = network.get_action(np.array(state)) #将状态输入到网络之中,输出线速度和角速度
cmd_vel = Twist() #将速度放到Twist中发布
cmd_vel.linear.x = linear_x/5 #这里发现最快1m/s的话还是太快了,所以又手动降为最大0.2
cmd_vel.angular.z = angular_z/5
pub.publish(cmd_vel) #发布消息
if state[20]<COLLISION_DIST: #简易判断碰撞
pub.publish(Twist())
break
if target: #简易判断是否到达目标点
pub.publish(Twist())
break
rate.sleep() #停止一段时间,让这里设置为0.1s,那么控制频率就是10hz
然后运行,我们可以打开rviz,看到小车的移动了!
不过这里我用的小车其实仿真环境中的不是一个小车,em但是他们的控制方式也比较相似吧,最后也能实现相应的效果,最正确的方式是将你们自己小车的urdf导入到gazebo中进行仿真!
对了,这里用的是jupyter来写的,我发现在jupyter里面搞ROS的算法部分真的是很方便啊!值得一试!