HALCON 20.11:深度学习笔记(12)---语义分割
HALCON 20.11:深度学习笔记(12)--- 语义分割
HALCON 20.11.0.0中,实现了深度学习方法。
本章解释了如何使用基于深度学习的语义分割,包括训练和推理阶段。
通过语义分割,我们使用深度学习(DL)网络将输入图像的每个像素分配到一个类。

语义分割的例子:输入图像的每个像素都被分配给一个类,但是类“apple”的三个不同实例和类“orange”的两个不同实例都不是不同的对象。
语义分割的结果是一个输出图像,其中的像素值表示输入图像中对应像素的指定类别。因此,在HALCON中,输出图像与输入图像大小相同。对于一般的DL网络,更深层次的特征映射代表更复杂的特征,通常比输入图像小(参见深度学习中的“网络和训练过程”一节)。为了获得与输入相同大小的输出,HALCON使用了包含两个组件的分割网络:一个编码器和一个解码器。编码器确定输入图像的特征已经完成,例如,用于基于深度学习的分类。由于该信息是以压缩格式“编码”的,因此解码器需要将信息重构为所需的结果,在这种情况下,就是将每个像素赋值给一个类。请注意,在对像素进行分类时,同一个类的重叠实例不会被区分为截然不同的。
深度学习的语义分割是在更通用的HALCON深度学习模型中实现的。有关后者的更多信息,请参阅深度学习/模型一章。为了应用深度学习,具体的系统要求请参考HALCON“安装指南”。
以下部分介绍了语义分割所需的一般工作流程,涉及到的数据和参数的相关信息,以及对评价措施的解释。
一般工作流程
本节我们描述了基于深度学习的语义分割任务的一般工作流程,具体分为数据预处理、模型训练、训练模型评价和新图像推理四个部分。因此,我们假设您的数据集已经被标记,请参见下面的“数据”一节。看看HDevelop示例系列segment_pill_defects_deep_learning中的一个应用程序。
预处理数据
这部分说明如何预处理数据。HDevelop示例segment_pill_defects_deep_learning_1_preprocess.hdev中也显示了单个步骤。
- 由函数read_dl_dataset_segmentation传入训练数据集图像中需要找到的信息并创建了一个字典DLDataset,它作为数据库并存储关于数据的所有必要信息。有关数据及其传输方式的更多信息,请参见下面的“数据”一节和“深度学习/模型”一章。
- 使用函数split_dl_dataset拆分字典DLDataset表示的数据集。分割结果将保存在DLDataset的每个示例条目中的键split之上。
- 使用函数preprocess_dl_dataset预处理数据集。本程序还提供了如何实现自定义预处理过程的指导。要使用这个函数,要指定预处理参数,例如,图像大小。对于后者,你应该选择尽可能小的图像大小,这样要分割的区域仍然可以很好地识别。可以使用create_dl_preprocess_param函数将所有参数及其值存储在一个DLPreprocessParam字典中。我们建议将这个字典保存为DLPreprocessParam,以便以后在推断阶段能够访问预处理参数值。在数据集的预处理过程中,也会通过preprocess_dl_dataset为训练数据集生成图像weight_image。它们为每个类分配其像素在训练期间获得的权重(“类权重”)(参见下面的“模型参数和超参数”一节)。
模型训练
这一部分说明如何训练一个DL语义分割模型。在HDevelop示例segment_pill_defects_deep_learning_2_train.hdev中也显示了单个步骤。
- 通过函数read_dl_model读取网络。
- 通过函数set_dl_model_param设置模型参数。例如,'image_dimensions'和'class_ids',请参阅get_dl_model_param的文档。始终可以使用函数get_dl_model_param检索当前参数值。
- 使用函数create_dl_train_param设置训练参数并将其存储在字典'TrainingParam'中。这些参数包括:
超参数,请参阅下面的“模型参数和超参数”一节和深度学习一章;
可能的数据增强参数(可选)
训练期间的评估参数
训练结果可视化参数
序列化参数。 - 使用函数train_dl_model训练模型。这个函数包括:
模型句柄DLModelHandle
包含数据信息DLDataset的字典
包含训练参数'TrainParam'的字典
训练要进行多少个epoch的信息。
在使用train_dl_model过程的情况下,总损失和可选的评价措施是可视化的。
评估训练模型
这一部分说明如何评价语义分割模型。在HDevelop示例segment_pill_defects_deep_learning_3_evaluate.hdev中也显示了单个步骤。
- 使用函数set_dl_model_param设置可能影响计算的模型参数,例如'batch_size'。
- 利用函数evaluate_dl_model可以方便地进行评价。
- 字典EvaluationResults保存所要求的评价措施。您可以使用函数dev_display_segmentation_evaluation可视化您的评估结果。
新图像推理
本部分介绍DL语义分割模型的应用。HDevelop示例segment_pill_defects_deep_learning_4_infer.hdev中也显示了单个步骤。
- 使用操作符set_dl_model_param设置参数,如'batch_size'。
- 使用函数gen_dl_samples_from_images为每个图像生成一个数据字典DLSample。
- 使用函数preprocess_dl_samples像训练时那样对图像进行预处理。在预处理步骤中保存字典DLPreprocessParam时,可以直接使用它作为输入来指定所有参数值。
- 使用函数apply_dl_model应用模型。
- 从字典'DLResultBatch'中检索结果。特定类的区域可以通过在分割图像上使用算子阈值来选择。
数据
我们区分用于培训和评估的数据和用于推断的数据。后者由裸图像组成。第一类是包含图片及其信息和ground truth注释的图片。您将为每个像素提供定义它属于哪个类的信息(在segmentation_image上,参见下面的进一步解释)。
作为基本概念,模型通过字典处理数据,这意味着它通过字典DLSample接收输入数据,并分别返回字典DLResult和DLTrainResult。关于数据处理的更多信息可以在深度学习/模型一章找到。
为训练和评估提供数据
训练数据用于为您的特定任务训练网络。数据集由图像和相应的信息组成。它们必须以模型能够处理它们的方式提供。关于图像要求,请在下面的“图像”部分找到更多信息。关于图像及其ground truth注释的信息通过字典DLDataset提供,对于每个样本都提供相应的segmentation_image,并为每个像素定义类。
类
不同的类别是由网络划分的集合或类别。它们在字典DLDataset中设置,并通过操作符set_dl_model_param传递给模型。
在语义切分中,我们提醒你注意两种特殊情况:类“background”和类声明为“ignore”:
'background'类:网络将background类视为其他类。没必要一定有一个背景类。但是如果你对你的数据集中的类不感兴趣,虽然他们必须通过网络学习,你可以设置他们所有的“背景”。因此,类背景将会更加多样化。有关更多信息,请参阅preprocess_dl_samples过程。
'ignore'类:可以声明一个或多个类为'ignore'。赋给‘ignore’类的像素会被损失以及所有度量和评估所忽略。请参阅深度学习章节中的“网络和训练过程”一节,了解更多关于损失的信息。网络不会将任何像素分类到声明为“ignore”的类中。同样,被标记为属于这个类的像素将被网络像其他像素一样分类到一个非“忽略”类。在下面的图片中给出的例子中,这意味着网络也将对类“border”的像素进行分类,但它不会将任何像素分类到类“border”中。可以使用set_dl_model_param的参数“ignore_class_ids”将类声明为“ignore”。
DLDataset
这个字典作为一个数据库,它存储了所有关于网络数据的必要信息,例如,图片的名称和路径,类,…关于一般概念和关键条目,请参阅深度学习/模型的文档。键segmentation_image只适用于语义分割的关注(见下面的条目)。通过键segmentation_dir和segmentation_file_name,您可以提供它们的命名方式和保存位置的信息。
segmentation_image
为了让网络能够学习不同类的成员看起来如何不同,需要告诉训练数据集中每幅图像的每个像素它属于哪个类。这是通过将类编码为像素值的输入图像的每个像素存储在相应的segmentation_image中来实现的。这些批注就是ground truth批注。
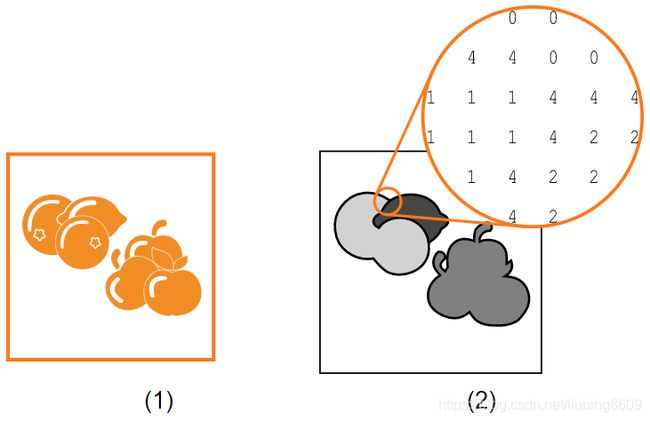
segmentation_image模式。对于可见性,灰色值被用来表示数字
(1)输入图像
(2)相应的segmentation_image提供类注释,0:background(白色),1:orange, 2: lemon, 3: apple,和4:border(黑色)作为一个单独的类,所以我们可以声明它为“ignore”
您需要足够的训练数据来将其分成三个子集,一个用于训练,一个用于验证,一个用于测试网络。这些子集最好是独立且同分布的(参见深度学习章节中的“数据”一节)。对于分割,可以使用split_dl_data_set函数。
图像
无论应用程序是什么,网络都会对图像的尺寸、灰度值范围和类型提出要求。具体的值取决于网络本身,有关不同网络的具体值,请参阅read_dl_model的文档。对于加载的网络,可以使用get_dl_model_param来查询它们。为了满足这些要求,您可能需要对图像进行预处理。整个样本的标准预处理,也在preprocess_dl_samples中实现。本程序还提供了如何实现自定义预处理过程的指导。
网络输出
作为训练输出,操作符将返回一个字典DLTrainResult,其中包含总损失的当前值以及模型中包含的所有其他损失的值。
作为推理和求值输出,网络将为每个样本返回一个字典DLResult。对于语义分割,本字典将为每个输入图像包含以下两张图像的句柄:
segmentation_image:图像,其中每个像素都有一个值,对应于它对应的像素被分配给的类(见下图)。
segmentation_confidence:图像,其中每个像素都有输入图像中对应像素分类后的置信度值(见下图)。
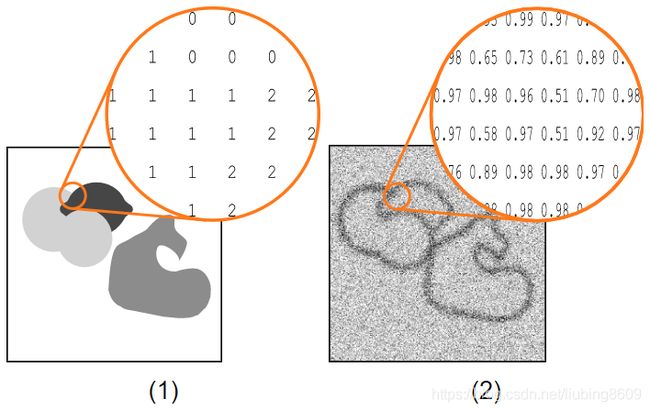
weight_image模式。对于可见性,灰色值被用来表示数字
(1) segmentation_image为图像中的每个像素定义类,0:background(白色),1:orange, 2: lemon, 3: apple,和4:border(黑色),声明为'ignore'
(2)提供类权重的相应weight_image, background: 1.0, orange: 30.0, lemon: 75.0。声明为‘ignore’的类的像素(这里是类边界)将被忽略,并获得权重0.0
对语义分割后的数据进行评价
对于语义分割,HALCON支持以下评估措施。注意,为计算图像的这种度量,需要相关的ground truth信息。下面解释的单个图像的所有测量值(例如,mean_iou)也可以计算任意数量的图像。为此,想象一个单独的,由输出图像集合形成的大图像,为其计算度量。注意,声明为'ignore'的类的所有像素在度量值的计算中都会被忽略。
pixel_accuracy
像素精度只是用正确的类标签预测的所有像素与像素总数的比率。
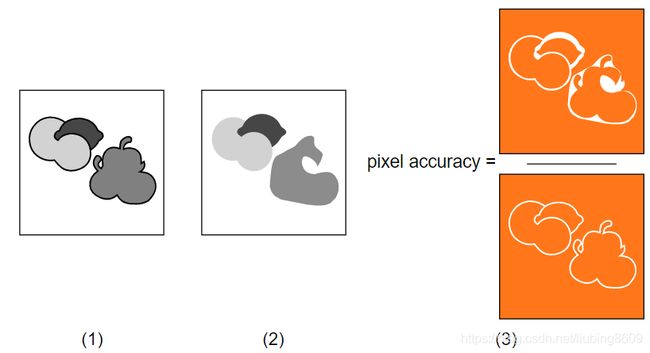
pixel_accuracy的可视化示例
(1)segmentation_image为每个像素定义ground truth类(参见上面的“数据”部分),声明为“ignore”的类的像素被画成黑色
(2)输出图像,也像素类声明为“忽略”得到分类
(3)像素精度是总橙色区域之间的比率。注意,标记为'ignore'类的一部分的像素会被忽略
class_pixel_accuracy
每类像素精度只考虑单个类的像素。它被定义为正确预测的像素与使用该类标记的像素总数之间的比率。
如果一个类没有出现,它将获得class_pixel_accuracy值-1,并且不会影响平均值mean_accuracy。
mean_accuracy
平均精度定义为所有发生的类的每类平均像素精度class_pixel_accuracy。
class_iou
交并比(IoU)给出了一个特定类的正确预测像素与注释和预测像素的并集的比率。从视觉上看,这是区域的交集和并集之间的比率,见下图。
如果一个类没有出现,它将得到一个class_iou值-1,并且不会对mean_iou做出贡献。

每个类的IoU的可视示例class_iou,这里仅用于类apple
(1)为每个像素定义ground truth类的segmentation_image(见“数据”部分)。声明为“ignore”的类的像素被画成黑色
(2)输出图像,也像素类声明为“忽略”得到分类
(3)交集在并集上的交集是苹果像素面积的交集与并集的比率。注意,标记为'ignore'类的一部分的像素会被忽略
mean_iou
平均IoU定义为所有发生类的平均每类IoU。请注意,每个出现的类都对这个度量有相同的影响,这与它们包含的像素数无关。
frequency_weighted_iou
对于平均IoU,首先计算每类IoU。但是,每个出现的类对这个度量的贡献是由属于该类的像素的比例加权的。注意,具有许多像素的类可以主导这个度量。
pixel_confusion_matrix
在“深度学习”一章的“监督训练”一节中解释了混淆矩阵的概念。它适用于实例为单个像素的语义分割。