python之web自动化<二>
python之web自动化<一> 戳这里
一、鼠标操作
由selenium的ActionChains来模拟鼠标操作,主要的操作流程。
1. ActionChains 库 储存鼠标的操作
ActionChains下的perform()方法 比较特殊,先将操作村放在一个列表中,然后用perform方法去全部执行列表中的操作。
ActionChains 引用库:
from selenium.webdriver.common.action_chains import ActionChains
from selenium.webdriver.common.keys import Keys
简写亦可
from selenium.webdriver import ActionChains
from selenium.webdriver import Keys
ActionChains方法列表,支持的操作如下:
ActionChains方法列表
click(on_element=None) ——单击鼠标左键
click_and_hold(on_element=None) ——点击鼠标左键,不松开
context_click(on_element=None) ——点击鼠标右键
double_click(on_element=None) ——双击鼠标左键
drag_and_drop(source, target) ——拖拽到某个元素然后松开 拖拽操作,左键按住拖动某一个元素到另外一个区域,然后释放按键
# source 目标元素,target释放元素
drag_and_drop_by_offset(source, xoffset, yoffset) ——拖拽到某个坐标然后松开
key_down(value, element=None) ——按下某个键盘上的键 要发送的修改器键。值在“Keys”类中定义
key_up(value, element=None) ——松开某个键 要发送的修改器键。值在“Keys”类中定义
move_by_offset(xoffset, yoffset) ——鼠标从当前位置移动到某个坐标
move_to_element(to_element) ——鼠标移动到某个元素,也叫做鼠标悬停
move_to_element_with_offset(to_element, xoffset, yoffset) ——移动到距某个元素(左上角坐标)多少距离的位置
# to_element 定位的元素 xoffset,yoffset:x,y 下面有介绍
perform() ——执行链中的所有动作 比如:
# 连续点击 ActionChains(driver).move_to_element(menu).click(hidden_submenu).perform()
release(on_element=None) ——在某个元素位置松开鼠标左键
send_keys(*keys_to_send) ——发送某个键到当前焦点的元素 举例2↓
send_keys_to_element(element, *keys_to_send) ——发送某个键到指定元素
pause(seconds) ——暂停 单位秒
举个例子0:鼠标悬停 (也可以理解为 鼠标移动)
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from selenium.webdriver import ActionChains
import time
def Action():
driver_file_path = '..\data\chromedriver.exe'
options = webdriver.ChromeOptions()
options.add_experimental_option("excludeSwitches", ["enable-automation"])
driver_obj = Service(driver_file_path)
driver = webdriver.Chrome(service=driver_obj, options=options)
driver.maximize_window()
driver.get('https://www.baidu.com/')
# 实现悬浮的操作分解 方式一 和 方式二 都可
# 方式一
ActionChains(driver).move_to_element(driver.find_element(By.NAME, 'tj_briicon')).perform()
# 方式二:对上一行代码的分解
# Step1: 先找到鼠标要操作的元素
ele = driver.find_element(By.NAME, 'tj_briicon')
# Step2: 实例化ActionChains类
ac = ActionChains(driver)
# Step3: 将鼠标添加到action中去
ac.move_to_element(ele)
# Step4: 调用perform
ac.perform()
time.sleep(5)
if __name__ == '__main__':
Action()
运行方式一和方式二都是一样的,如图:鼠标就停留在这页面了

但是如果想要点击这个翻译按钮。那么在原代码后面加上一行代码是:后面如图
ActionChains(driver).move_to_element(driver.find_element(By.NAME, 'tj_fanyi')).click().perform()

运行完就自动点击翻译按钮了。
其实ActionChains(driver).move_to_element(driver.find_element(By.NAME, 'tj_fanyi')).click().perform()这段代码跟方式一是一样的,只是多了一步 .click() 点击的操作。我们可以看看官方代码示例。
# 官方方法举例
menu = driver.find_element(By.CSS_SELECTOR, ".nav")
hidden_submenu = driver.find_element(By.CSS_SELECTOR, ".nav #submenu1")
# Step1: 实例化ActionChains类
actions = ActionChains(driver)
# Step2: 将鼠标添加到action中去 移动悬浮 方法
actions.move_to_element(menu)
# Step3: 点击操作 点击某某元素
actions.click(hidden_submenu)
# Step4: 调用perform 执行
actions.perform()
其实我们看了官方的代码可以得出,一行代码就能搞定鼠标悬浮和点击的操作:
ActionChains(driver).move_to_element(driver.find_element(By.NAME, 'tj_briicon')).click(driver.find_element(By.NAME, 'tj_fanyi')).perform()
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from selenium.webdriver import ActionChains
import time
def Action():
driver_file_path = '..\data\chromedriver.exe'
options = webdriver.ChromeOptions()
options.add_experimental_option("excludeSwitches", ["enable-automation"])
driver_obj = Service(driver_file_path)
driver = webdriver.Chrome(service=driver_obj, options=options)
driver.maximize_window()
driver.get('https://www.baidu.com/')
ActionChains(driver).move_to_element(driver.find_element(By.NAME, 'tj_briicon')).click(driver.find_element(By.NAME, 'tj_fanyi')).perform()
time.sleep(5)
if __name__ == '__main__':
Action()
举个例子1:鼠标悬停,注意鼠标悬停仅仅是鼠标悬停,不包括点击操作,例子0后面包括了点击操作。
def moveto_ele(self,loc): # loc为定位的某个元素
try: # 写法1:
ActionChains(self.driver).move_to_element(self.find_ele(loc)).perform()
return 0
except Exception as e:
self.log.logMsg(3,e)
return 1
# 鼠标移动
# 写法2:
actions = ActionChains(driver)
actions.move_to_element(loc)
actions.perform()
举个例子2,鼠标悬停之后点击,规规矩矩写法,与上面例子0实现功能一样
from selenium import webdriver
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from selenium.webdriver import ActionChains
import time
def Action():
driver_file_path = '..\data\chromedriver.exe'
options = webdriver.ChromeOptions()
options.add_experimental_option("excludeSwitches", ["enable-automation"])
driver_obj = Service(driver_file_path)
driver = webdriver.Chrome(service=driver_obj, options=options)
driver.maximize_window()
driver.get('https://www.baidu.com/')
# 鼠标悬停
ActionChains(driver).move_to_element(driver.find_element(By.NAME, 'tj_briicon')).perform()
# 鼠标点击
WebDriverWait(driver, 10).until(EC.visibility_of_element_located((By.NAME, 'tj_fanyi')))
driver.find_element(By.NAME,'tj_fanyi').click()
time.sleep(5)
if __name__ == '__main__':
Action()
举个例子3:清除操作:
def ele_clear(self, ele): # 其中 ele 为 driver 驱动对象
try:
ele.send_keys(Keys.CONTROL, 'a')
ele.send_keys(Keys.BACK_SPACE)
return 0
except Exception as e:
raise e
举个例子3:X,Y定位:
引用ActionChains类: move_by_offset 可以参考戳
get_window_size() 可以参考戳
from selenium.webdriver.common.action_chains import ActionChains
# 定位坐标
driver.get_window_size() 定位:x宽, y高
ActionChains(self.driver).move_by_offset(x, y).click().perform()
2.下拉框操作(下拉列表):
a. 如果是 Select 属性,那么就用该类操作,导入Select库。怎么判断是否是Select属性?见下图
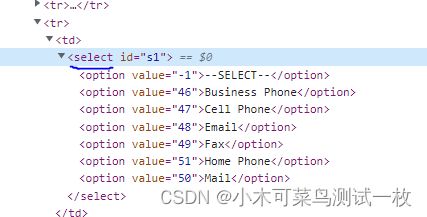
首先引入类:
from selenium.webdriver.support.ui import Select
Select 提供三种模式 定位下列列表的值
1.通过下标:elect_by_index(index)从0开始
2.通过Value属性:select_by_value(value)
1.通过文本内容:select_by_visible_text(text)
我们要进行试验的网站:http://sahitest.com/demo/selectTest.htm
针对于示例网站中的第一个select框:
<select id="s3Id">
<option></option>
<option value="o1val">o1</option>
<option value="o2val">o2</option>
<option value="o3val">o3</option>
<option value="o4val"> With spaces</option>
</select>
我们可以这样定位:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import Select
from selenium.webdriver.chrome.service import Service
import time
def Action():
driver_file_path = '..\data\chromedriver.exe'
options = webdriver.ChromeOptions()
options.add_experimental_option("excludeSwitches", ["enable-automation"])
driver_obj = Service(driver_file_path)
driver = webdriver.Chrome(service=driver_obj, options=options)
driver.maximize_window()
driver.get('http://sahitest.com/demo/selectTest.htm')
Sel = Select(driver.find_element(By.ID, 's3Id')) # 实例化 Select
# 注意 不用鼠标点击click select 可以自己获取下列选项,下列是三种切换方法
Sel.select_by_index(4) # 选择第1项选项:With spaces
Sel.select_by_value("o2val") # 选择value="o2"的项
Sel.select_by_visible_text("o3") # 选择text="o3"的值,即在下拉时我们可以看到的文本
time.sleep(5)
# driver.quit()
if __name__ == '__main__':
Action()
b. 如果是不是 Select 属性,非select标签的伪下拉框。就需要用其他的方法了。如input标签的下拉框,只需要普通的定位、点击就可以了。下面举个例子For循环处理:
# 点击激活下拉框
driver.find_element(By.XPATH, "//select[@id='s3Id']").click()
time.sleep(1)
# 提取此下拉框中的所有元素,注意这里是 elements
ele = driver.find_elements(By.XPATH, "//select[@id='s3Id']/option")
# for循环判断需要的元素在哪里,点击它
for e in ele:
if "o3" in e.text:
e.click()
break
time.sleep(2)
# _____至此 上面利用For循环下拉框已经处理完成,下面是select库处理
Sel = Select(driver.find_element(By.XPATH, "//select[@id='s1']"))
Sel.select_by_index(1)
time.sleep(5)
二、键盘操作
引入库,在文章上面也有。
from selenium.webdriver.common.keys import Keys
常用的键盘操作:
组合键
send_keys(Keys.CONTROL, 'a') 全选
send_keys(Keys.CONTROL,'c') 复制(Ctrl+C)
send_keys(Keys.CONTROL,'v') 粘贴(Ctrl+V)
send_keys(Keys.CONTROL,'x') 剪切(Ctrl+X)
send_keys(Keys.SHIFT, Keys.CONTROL) 切换输入法
非组合键
send_keys(Keys.CANCEL) 取消
send_keys(Keys.BACK_SPACE) 删除键(Backspace)
send_keys(Keys.TAB) 制表键(Tab)
send_keys(Keys.ESCAPE) 回退键(ESC)
send_keys(Keys.ENTER) 回车键(Enter)
send_keys(Keys.F5) 刷新(Ctrl+X)
send_keys(Keys.SPACE) 空格键(Space)
搭配使用最多的是: 全选 + 删除
举例1:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from selenium.webdriver import Keys
import time
def Action():
driver_file_path = '..\data\chromedriver.exe'
options = webdriver.ChromeOptions()
options.add_experimental_option("excludeSwitches", ["enable-automation"])
driver_obj = Service(driver_file_path)
driver = webdriver.Chrome(service=driver_obj, options=options)
driver.maximize_window()
driver.get('https://www.baidu.com/')
# 定位输入框元素
ele = driver.find_element(By.ID, 'kw')
time.sleep(2)
# 输入柠檬班
ele.send_keys('柠檬班')
time.sleep(2)
# 方式一 其中这里为举例 特意用键盘操作 方式二亦可
# 全选
ele.send_keys(Keys.CONTROL, 'a')
time.sleep(2)
# 删除输入的:柠檬班文本
ele.send_keys(Keys.BACK_SPACE)
time.sleep(2)
# 方式二:
# ele.clear()
# 输入
ele.send_keys('韦神')
time.sleep(2)
# 点击
ele.send_keys(Keys.ENTER)
time.sleep(10)
if __name__ == '__main__':
Action()
三、Web页面不可见区域——滚动条处理
首先滚动条不是我们web页面的元素,所以我们必须要用js来处理。
在python中方法介绍:execute_script 就是来执行Java Script代码的。
execute_script(script, *args),*args参数可以取多个,script从0开始取值 所以 arguments[0]
script:对应就是js中的方法,那 scrollIntoView 是js中的滚动滚动条的方法,element 为定位某个元素的对象
下面共有4种滚动的方法:
a.移动到定位的 element 对象 底端 与当前窗口的持平
driver.execute_script("arguments[0].scrollIntoView(false);", element)
b.移动到定位的 element 对象 顶端 与当前窗口的持平
driver.execute_script("arguments[0].scrollIntoView();", element)
c.移动到页面底部
driver.execute_script("window.scrollTo(0,document.body.scrollHeight)")
d.移动到页面顶部
driver.execute_script("window.scrollTo(document.body.scrollHeight,0)")
代码举例a:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By # 八种定位方式
import time
def Action():
driver_file_path = '..\data\chromedriver.exe'
options = webdriver.ChromeOptions()
options.add_experimental_option("excludeSwitches", ["enable-automation"])
driver_obj = Service(driver_file_path)
driver = webdriver.Chrome(service=driver_obj, options=options)
driver.maximize_window()
driver.get('https://www.baidu.com/')
# 定位输入框元素
ele = driver.find_element(By.ID, 'kw')
time.sleep(2)
# 输入柠檬班
ele.send_keys('柠檬班')
driver.find_element(By.ID, 'su').click()
# 滚动条处理:
# 1、找到想要滚动到想要定位的元素
WebDriverWait(driver, 20).until(EC.visibility_of_element_located((By.XPATH, '//a[contains(text(),"吧 - 百度贴吧")]')))
element = driver.find_element(By.XPATH, '//a[contains(text(),"吧 - 百度贴吧")]')
# 2、使用js进行滚动操作
# a.移动到定位的 element 对象 底端 与当前窗口的持平
driver.execute_script("arguments[0].scrollIntoView(false);", element)
time.sleep(20)
if __name__ == '__main__':
Action()
举例a结果图像:element 对象 底端 与当前窗口的持平

四、解决Web页面readonly或者其他不可输入属性办法
首先在我们js里面去调试,办法有两种一种是修改属性,另一种删除属性
看图:
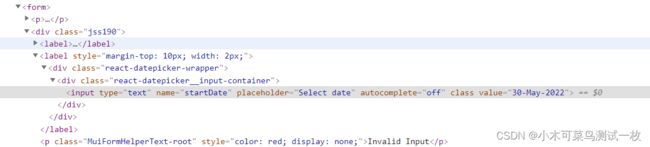
1、第一种方法
通过直接定位后删除placeholder这个参数就可以达到我们的某种目的—>变成可编辑。
代码:
document.getElementsByClassName("react-datepicker__input-container")[0].childNodes[0].removeAttribute("placeholder")
①注:在JavaScript的console中回车执行调试
②childNodes[0],表示元素节点位置
③removeAttribute(“target”),表示删除元素
执行后:
 利用execute_script 方法,在Python这样运行:
利用execute_script 方法,在Python这样运行:
from selenium import webdriver
driver=webdriver.Chrome()
driver.implicitly_wait(1)
driver.get("http://localhost/")
js = 'document.getElementsByClassName("react-datepicker__input-container")[0].childNodes[0].removeAttribute("placeholder")'
driver.execute_script(js) #调用js方法,同时执行javascript脚本
driver.find_element_by_id("username").send_keys("yonghuming") # 再去编辑
2、第二种方法
修改属性值:可以达到我们的某种目的—>变成可编辑。列如:True也可以变成False
代码:document.getElementsByClassName("react-datepicker__input-container")[0].childNodes[0].value="29-May-2022"
完整代码:
from selenium import webdriver
driver = webdriver.Chrome()
driver.implicitly_wait(1)
driver.get("http://localhost/")
js = 'document.getElementsByClassName("react-datepicker__input-container")[0].childNodes[0].value="29-May-2022"'
# js = 'return document.getElementsByClassName("react-datepicker__input-container")[0].childNodes[0].value="29-May-2022"'
# print(driver.execute_script(js)) 获取返回值
driver.execute_script(js) # 调用js方法,同时执行javascript脚本
driver.find_element_by_id("username").send_keys("yonghuming") # 再去编辑
五、上传操作
有两种情况:
1、如果是input,可以直接输入路径,那么直接调用send_keys输入路径
2、非input标签上传的,则需要借助第三方工具。以下三个选择都可。
2.1、Autolt 我们去调用生成的au3或exe文件,借助第三方软件。
2.2、SendKeys第三方库
网址:https://pypi.python.org.pypi/SendKeys
2.3、Python pywin32库,识别对话框句柄,进而操作。
2.4、pyperclip、pyautogui 库最新的用法 推荐使用。
举例:
情形一:
python3.8版本
1.需先安装依赖库 pillow== 6.2.2
2.然后安装pyautogui库
pip install pillow==6.2.2
pip install pyautogui
情形二:
非python3.8版本
直接安装pyautogui库
代码:
一、
def upload(self, filepath):
try:
pyautogui.click()
pyautogui.write(filepath, interval=0.2)
time.sleep(2)
pyautogui.press('enter', presses=2)
return 0
except Exception as e:
raise e
二、
说明:有的平台,文件路径中如果包含中文或需要切换输入法,会报错,解决办法:
import pyperclip """ pyautogui 中自带的,因此不需要单独安装 """
pyperclip.copy(r"d:\用户\文件.txt") """ 复制文件路径 """
time.sleep(2)
pyautogui.hotkey("ctrl","v") """ 类似于剪切板上面的粘贴操作 """
pyautogui.press("enter",presses=2) """ 输入两次enter键,防止出错 """
def upload(self,filepath):
try:
pyperclip.copy(filepath)
pyautogui.hotkey("ctrl","v")
# pyautogui.write(filepath, interval=0)
time.sleep(2)
pyautogui.press('enter', presses=2)
return 0
except Exception as e:
self.log.logMsg(3, e)
return 1
实例演示
下边是html代码,可以直接复制粘贴到一个新的html文件,可以拿来调试一下
html代码如下:
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>上传</title>
<script type="text/javascript" src="script/jquery-3.1.1.min.js"></script>
</head>
<body>
<form id="form1" action="uploadFile.do" target="frame1" method="post" enctype="multipart/form-data">
<input type="file" name="file">
<input type="button" value="上传" onclick="upload()">
</form>
<iframe name="frame1" frameborder="0" height="40"></iframe>
<!-- 其实我们可以把iframe标签隐藏掉 -->
<script type="text/javascript">
function upload() {
$("#form1").submit();
var t = setInterval(function() {
//获取iframe标签里body元素里的文字。即服务器响应过来的"上传成功"或"上传失败"
var word = $("iframe[name='frame1']").contents().find("body").text();
if (word != "") {
alert(word); //弹窗提示是否上传成功
clearInterval(t); //清除定时器
}
}, 1000);
}
</script>
</body>
</html>
如图:

python代码一,正常点击输入操作如下:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver import ActionChains
import time
import os
import pyautogui
def Action():
driver_file_path = "..\data\chromedriver.exe"
options = webdriver.ChromeOptions()
options.add_experimental_option("excludeSwitches", ["enable-automation"])
driver = webdriver.Chrome(executable_path=driver_file_path, chrome_options=options)
driver.maximize_window()
driver.get(os.getcwd()+r'\7788.html')
# WebDriverWait(driver, 20).until(EC.visibility_of_element_located(driver.find_element(By.NAME, 'file')))
ele = driver.find_element(By.NAME, 'file')
ActionChains(driver).click(ele).perform()
pyautogui.click()
pyautogui.write(r'C:\data\20220517.csv', interval=0.2) """ 上传文件"""
time.sleep(2)
pyautogui.press('enter', presses=2)
time.sleep(20)
if __name__ == '__main__':
Action()
python代码二,复制操作如下:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver import ActionChains
import time
import os
import pyautogui
import pyperclip
def Action():
driver_file_path = r"C:\Users\joinkwang\Documents\itrls-int-auto-wt\data\chromedriver.exe"
options = webdriver.ChromeOptions()
options.add_experimental_option("excludeSwitches", ["enable-automation"])
driver = webdriver.Chrome(executable_path=driver_file_path, chrome_options=options)
driver.maximize_window()
driver.get(os.getcwd()+r'\7788.html')
# WebDriverWait(driver, 20).until(EC.visibility_of_element_located(driver.find_element(By.NAME, 'file')))
ele = driver.find_element(By.NAME, 'file')
ActionChains(driver).click(ele).perform()
"""注意:参数的传递的后,最好是要有等待时间,不然执行可能过快就会报错!!!"""
value = r'C:\data\20220517.csv'
time.sleep(1)
pyperclip.copy(value)
pyautogui.hotkey("ctrl", "v")
time.sleep(2)
pyautogui.press('enter', presses=2)
time.sleep(20)
if __name__ == '__main__':
Action()
结果:
其他:解决下载文件弹窗问题
Selenium+Firefox的自动下载(去掉下载弹窗)借鉴:戳这里
Selenium + 火狐 设置下载路径依然弹窗解决办法:戳这里
进阶,Firefox疑难杂症设置:戳
具有chrome浏览器和firefox浏览器解析:更加专业的戳这里
有关于firefox浏览器里面的profile.set_preference方法的运用,可参照下面列举的Demo中的open_url方法下配置,或者访问这个地址:戳这里
Firefox 文件下载,对于Firefox,需要我们设置其Profile:
from selenium import webdriver
from time import sleep
profile = webdriver.FirefoxProfile()
# 指定下载路径
profile.set_preference('browser.download.dir', self.driver_file_path)
# 设置成 2 表示使用自定义下载路径;设置成 0 表示下载到桌面;设置成 1 表示下载到默认路径
profile.set_preference('browser.download.folderList', 2)
# 在开始下载时是否显示下载管理器
profile.set_preference('browser.download.manager.showWhenStarting', False)
# 对所给出文件类型不再弹出框进行询问,根据文件类型来判断
profile.set_preference('browser.helperApps.neverAsk.saveToDisk', 'application/zip')
# profile.set_preference('browser.helperApps.neverAsk.saveToDisk', 'application/zip,application/gzip')
# executable_path 为驱动的路径 举例:executable_path = .\data\geckodriver.exe
driver = webdriver.Firefox(executable_path=self.driver_file_path,firefox_profile=profile)
driver.get('http://sahitest.com/demo/saveAs.htm')
driver.find_element_by_xpath('//a[text()="testsaveas.zip"]').click()
sleep(3)
driver.quit()
关于方便调用的一些工具类
A.关于WEB端的一些动作:比如元素定位,文件上传,打开网页、滚动切图、鼠标操作(点击/清除/悬浮等)
import os
import re
from selenium.webdriver import ActionChains
from selenium.webdriver.common.by import By
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import pyautogui
import time
import datetime
from datetime import timedelta
from datetime import datetime as dt
from common.data_process import RandomInfo
import json
from web_ui_auto_lib.case_readers.case_reader_factory import *
from common.data_process import FileOperate
from common.log import Log
import pyperclip
class BaseMethod:
def __init__(self):
self.driver = None
self.log=Log()
self.driver_file_path = ConfigReader().get_value("file", "driver_file_path")
self.file_download_path = ConfigReader().get_value("file", "file_download_path")
# file_download_path = C:\\Temp\\download
self.configreader = ConfigReader()
def open_url(self, url):
if "chromedrive" in self.driver_file_path:
profile = webdriver.ChromeOptions()
""" 2为自定义下载路径,下载到后面新增的路径 'prefs'静止下载弹窗 """
exploer = {'profile.default_content_settings.popups':0,'download.default_directory':(self.file_download_path).replace("\\\\","\\")}
profile.add_experimental_option('prefs', exploer)
profile.add_experimental_option("excludeSwitches", ["enable-automation"])
self.driver = webdriver.Chrome(self.driver_file_path, chrome_options=profile)
elif "geckodriver" in self.driver_file_path:
""" 实例化 """
profile = webdriver.FirefoxProfile()
""" 设置下载存储方式,2为自定义路径、设置成 0 表示下载到桌面;设置成 1 表示下载到默认路径"""
profile.set_preference('browser.download.folderList',2)
""" 指定下载路径 """
profile.set_preference('browser.download.dir',self.file_download_path)
""" 对于未知的MIME类型文件会弹出窗口让用户处理,默认值为True,设定为False表示不会记录打开未知MIME类型文件的方式 """
profile.set_preference("browser.helperApps.alwaysAsk.force", False)
""" 在开始下载时是否显示下载管理器 """
profile.set_preference('browser.download.manager.showWhenStarting', False)
""" 默认值为True,设定为False表示不获取焦点 """
profile.set_preference('browser.download.manager.focusWhenStarting', False)
""" 下载.exe文件弹出警告,默认为True,设定为False则不会弹出警告框 """
profile.set_preference('browser.download.manager.alertOnEXEOpen', False)
""" 表示直接打开下载文件,不显示确认框,默认值为空字符串,下行代码设定了多种文件的MIME类型 """
""" 例如application/exe,表示.exe类型的文件,application/execl表示Execl类型的文件 """
profile.set_preference('browser.helperApps.neverAsk.openFile','application/exe')
""" 在开始下载时是否显示下载管理器 'application/zip,application/octet-stream' """
profile.set_preference('browser.helperApps.neverAsk.saveToDisk','application/octet-stream')
""" 设定下载文件结束后是否显示下载完成提示框,默认为True,设定为False表示下载完成后不显示提示框 """
profile.set_preference('browser.download.manager.showAlertOnComplete', False)
self.driver = webdriver.Firefox(executable_path=self.driver_file_path,firefox_profile=profile)
self.driver.get(url)
self.driver.maximize_window()
def find_element_by_type(self, search_type, value):
try:
ele = self.driver.find_element(search_type, value)
return ele
except Exception as e:
self.log.logMsg(5,e)
return None
def find_elements_by_type(self, search_type, value,values):
try:
ele = self.driver.find_element(search_type, value).find_elements(search_type, values)
return ele
except Exception as e:
self.log.logMsg(3,e)
return None
def find_ele(self, value):
try:
ele = None
ele = ele if ele is not None else self.find_element_by_type(By.ID, value)
ele = ele if ele is not None else self.find_element_by_type(By.NAME, value)
ele = ele if ele is not None else self.find_element_by_type(By.CLASS_NAME, value)
ele = ele if ele is not None else self.find_element_by_type(By.TAG_NAME, value)
ele = ele if ele is not None else self.find_element_by_type(By.LINK_TEXT, value)
ele = ele if ele is not None else self.find_element_by_type(By.PARTIAL_LINK_TEXT, value)
ele = ele if ele is not None else self.find_element_by_type(By.XPATH, value)
ele = ele if ele is not None else self.find_element_by_type(By.CSS_SELECTOR, value)
if ele is None:
self.log.logMsg(3,"NotFound:" + value)
return ele
except Exception as e:
self.log.logMsg(3,e)
return None
def find_eles(self,value,values):
try:
eles = None
eles = eles if eles is not None else self.find_elements_by_type(By.ID,value,values)
eles = eles if eles is not None else self.find_elements_by_type(By.NAME,value,values)
eles = eles if eles is not None else self.find_elements_by_type(By.CLASS_NAME,value,values)
eles = eles if eles is not None else self.find_elements_by_type(By.TAG_NAME,value,values)
eles = eles if eles is not None else self.find_elements_by_type(By.LINK_TEXT,value,values)
eles = eles if eles is not None else self.find_elements_by_type(By.PARTIAL_LINK_TEXT,value,values)
eles = eles if eles is not None else self.find_elements_by_type(By.XPATH,value,values)
eles = eles if eles is not None else self.find_elements_by_type(By.CSS_SELECTOR,value,values)
if eles is None:
self.log.logMsg(3,"NotFound" + values)
return eles
except Exception as e:
self.log.logMsg(3,e)
return None
def ele_click(self,ele): # 点击
try:
ele.click()
return 0
except Exception as e:
self.log.logMsg(3, e)
return 1
def ele_clear(self, ele): # 清除
try:
ele.send_keys(Keys.CONTROL, 'a')
ele.send_keys(Keys.BACK_SPACE)
return 0
except Exception as e:
self.log.logMsg(3,e)
return 1
def ele_input(self, ele, value): # 输入
try:
self.ele_clear(ele)
ele.send_keys(value)
return 0
except Exception as e:
self.log.logMsg(3,e)
return 1
def ele_display(self,ele): # 判断对象是否可见,即css的display属性是否为none
try:
self.driver.find_element_by_xpath(ele).is_displayed()
return 0
except Exception as e:
self.log.logMsg(3,e)
return 1
def refresh(self): # 刷新
self.driver.refresh()
def locateles(self): # 获取标签属性 每个元素都有tag(标签)属性,如搜索框的标签属性,就是最前面的input
count=self.driver.find_element_by_tag_name("table").find_elements_by_tag_name("tr")
return count
def quit(self): # 退出
self.driver.quit()
def close(self): # 关闭浏览器
windows = self.driver.window_handles
if len(windows) > 1:
self.driver.switch_to.window(windows[1 - len(windows)])
self.driver.close()
else:
self.driver.close()
def back(self): # 返回
self.driver.back()
def js_screenshotsave(self,screenshot_path,file_name,js):
self.driver.execute_script(js)
time.sleep(2)
timestr = datetime.datetime.now().strftime("%Y_%m_%d_%H_%M_%S")
self.driver.get_screenshot_as_file(f'{screenshot_path}\\{timestr}_{file_name}.png')
def getelements(self,positioningexpression,scroll):
js=None
pe_key, pe_value = str(positioningexpression).split("=")[0], str(positioningexpression).split("=")[1]
if "ClassName=" in positioningexpression:
js = (f'var q=document.getElementsByClassName("demo")[0].scrollTop=' + str(scroll)).replace("demo",pe_value)
elif "Id=" in positioningexpression:
js = (f'var q=document.getElementsById("demo").scrollTop=' + str(scroll)).replace("demo", pe_value)
elif "Name=" in positioningexpression:
js = (f'var q=document.getElementsByName("demo").scrollTop=' + str(scroll)).replace("demo", pe_value)
return js
def movedown_posit(self,positioningexpression,x,y,screenshot_path,file_name):
pe_key, pe_value = str(positioningexpression).split("=")[0], str(positioningexpression).split("=")[1]
timestr = datetime.datetime.now().strftime("%Y_%m_%d_%H_%M_%S")
self.driver.get_screenshot_as_file(f'{screenshot_path}\\{timestr}_{file_name}.png')
for i in range(1, int(pe_value) + 1):
if i == 1:
ActionChains(self.driver).move_by_offset(x,y).click().perform()
time.sleep(2)
timestr = datetime.datetime.now().strftime("%Y_%m_%d_%H_%M_%S")
self.driver.get_screenshot_as_file(f'{screenshot_path}\\{timestr}_{file_name}.png')
else:
ActionChains(self.driver).move_by_offset(0, 0.1).click().perform()
time.sleep(2)
timestr = datetime.datetime.now().strftime("%Y_%m_%d_%H_%M_%S")
self.driver.get_screenshot_as_file(f'{screenshot_path}\\{timestr}_{file_name}.png')
def screenshotsave(self, screenshot_path, file_name, positioningexpression):
scrolllist = [scroll*100 for scroll in range(2,7,2)]
size= self.driver.get_window_size()
height,width = size['height'],size['width']
x,y=(lambda x:x+16-67)(int(width)),(lambda y:y-129-30)(int(height))
windows = self.driver.window_handles
try:
if len(windows) > 1:
self.driver.switch_to.window(windows[1 - len(windows)])
timestr = datetime.datetime.now().strftime("%Y_%m_%d_%H_%M_%S")
self.driver.get_screenshot_as_file(f'{screenshot_path}\\{timestr}_{file_name}.png')
time.sleep(2)
if "movedown=" in positioningexpression:
self.movedown_posit(positioningexpression,x,y,screenshot_path,file_name)
for scroll in scrolllist:
scroll = scroll if int(height) < 600 else scroll + 100
if positioningexpression == "":
js = "var q=document.documentElement.scrollTop=" + str(scroll)
self.js_screenshotsave(screenshot_path, file_name, js)
elif "ClassName" or "Id" or "Name" in positioningexpression:
self.js_screenshotsave(screenshot_path, file_name,self.getelements(positioningexpression, scroll))
self.driver.switch_to.window(windows[0])
else:
timestr = datetime.datetime.now().strftime("%Y_%m_%d_%H_%M_%S")
self.driver.get_screenshot_as_file(f'{screenshot_path}\\{timestr}_{file_name}.png')
time.sleep(2)
if "movedown=" in positioningexpression:
self.movedown_posit(positioningexpression,x,y,screenshot_path,file_name)
scrolllist = scrolllist if int(height) < 600 else [scroll+100 for scroll in scrolllist]
for scroll in scrolllist:
if positioningexpression == "":
js = "var q=document.documentElement.scrollTop=" + str(scroll)
self.js_screenshotsave(screenshot_path, file_name, js)
elif "ClassName" or "Id" or "Name" in positioningexpression:
self.js_screenshotsave(screenshot_path, file_name,self.getelements(positioningexpression, scroll))
return 0
except Exception as e:
self.log.logMsg(3,e)
return 1
def point(self,step): # 页面切换至最新页面后点击x,y定位的坐标
x,y=step.InputValue.split(",")[0],step.InputValue.split(",")[1]
windows = self.driver.window_handles
if len(windows) > 1: # 如果有多个页面,新打开的窗口,位于最后一个
self.driver.switch_to.window(windows[1 - len(windows)]) # 那么页面切换到最新页面
else:
pass
time.sleep(3)
ActionChains(self.driver).move_by_offset(int(x),int(y)).click().perform()
def moveto_ele(self,loc): # 移动至新的坐标
try:
ActionChains(self.driver).move_to_element(self.find_ele(loc)).perform()
return 0
except Exception as e:
self.log.logMsg(3,e)
return 1
def source_find(self,text): # 获取页面的源码
try:
source_text=self.driver.page_source
if text in source_text:
return 0
else:
return 1
except Exception as e:
self.log.logMsg(3,e)
return -1
def upload(self,filepath): # 上传文件
try:
pyperclip.copy(filepath)
pyautogui.hotkey("ctrl","v")
# pyautogui.write(filepath, interval=0)
time.sleep(2)
pyautogui.press('enter', presses=2)
return 0
except Exception as e:
self.log.logMsg(3, e)
return 1
if __name__ == '__main__': # 文件上传方法的调用
BaseMethod().upload('c:\data\xxx.csv')
if __name__ == '__main__': # 滚动页面切图的调用
# 调用1:建议使用这个
file_name = 'Demo1'
screenshot_path = r'.\screenshot_path'
if not os.path.exists(self.screenshot_path):
os.mkdir(self.screenshot_path)
# 三选一
# self.bm.screenshotsave(screenshot_path, file_name,"ClassName=jss213") # ClassName定位页面元素 滚动4张切图
self.bm.screenshotsave(screenshot_path, file_name, "") # 不定位页面元素 默认滚动 切图4张
# self.bm.screenshotsave(screenshot_path, file_name,"movedown=66") movedown=滚动切换文件滚动条数 66个PDF页面 1此滚动1个PDF
# element_public_class 调用的其实是以上的方法,封装了一层,其实就是类的实例化
# step:初始化的一个EXCEL,在我EXCEL文章里面有说过
#调用2:
file_name=step.InputValue # InputValue --》excel 输入值栏位
if step.PositioningExpression == "": # 判断EXCEL中的定位表达式字段为空
reslut=element_public_class.screenshotsave(self.screenshot_path,file_name)
return 0 if reslut == 0 else 1
elif step.PositioningExpression != "": # 不为空 例如定义的一个大模块然后再执行下拉 ClassName=content
reslut = element_public_class.screenshotsave_div(self.screenshot_path, file_name, step.PositioningExpression)
return 0 if reslut == 0 else 1
B.另外一个工具类:也调用上面的类
self.publicDict 其实可以参考我另外一篇文章里面的内容:文件处理的类:戳这里
class ExecuteCase:
total=0
success=0
fail=0
def __init__(self):
self.publicDict=RandomInfo().publicDict
self.staff_file_path = ConfigReader().get_value("file","staff_file_path")
self.fileoperate=FileOperate()
self.log = Log()
self.runstatus_file_path = ConfigReader().get_value("file", "runstatus_file_path")
def relevantParams(self,data:str): # 这个函数的作用就是 在读取参数${today}后 替换成 实际值 26-May-2022 进行进一步处理
# 该方法的作用就是将 ${date} 格式的数据里面的value取出来返回 data,读取是在Excel里面读取。
inputvalueRelevantParams=re.findall(r'\${([\s\S]+?)\}',data) # 如果data = ${today} 即去掉 ${} 等于['today']
if inputvalueRelevantParams == []: # 如果data为空,Params为空列表
pass
else:
self.log.logMsg(4,"enter parameter replace")
for relevantParams in inputvalueRelevantParams: # 如果参数不为空,relevantParams 是一个列表 ['today']
if relevantParams in self.publicDict.keys(): # 有无keys()方法 其实都一样 ,如果 today 在 {'today': '26-May-2022'} 之中
strData="${%s}" % relevantParams # # {'today'} 赋值给 strData
publicRelevanValue=self.publicDict[relevantParams] # {'today': '26-May-2022'}['today'] = 26-May-2022 = publicRelevanValue
data=data.replace(strData,str(publicRelevanValue)) # 将 {'today'} 替换成 26-May-2022 赋值给 data
self.log.logMsg(4,"parameter replace success")
else:
self.log.logMsg(3,"parameter replace fail")
return data # data 实际 为 26-May-2022
def runstatus_tofile(self,runstatus_file_path,status,step): # 调用:self.ec.runstatus_tofile(self.runstatus_file_path,1,step)
""" runstatus_file_path:可以理解我csv文件的路径
status 判断状态 判断为1的话 写入文件,不为一 按照输入的数字多少写入 ,step.Step 是 EXCEL 文件的步骤,用数字表示
"""
time_runstatus,runstatus_title = datetime.datetime.now().strftime("%Y_%m_%d_%H_%M_%S"),f'RunStatus,Step'
# runstatus_title 为写入的内容 可以理解为写入标题 time_runstatus 即是 文件名称 用时间来表示
self.fileoperate.writefile(runstatus_file_path + time_runstatus + ".csv", "csv", runstatus_title,"a+")
runstatus = f'str(status),{int(step.Step)}' # 写入CSV的RunStatus,Step两列内容 1,int(step.Step)
if status==1: # status 写入数字1,是叠加在 runstatus_title 栏位
self.fileoperate.writefile(self.runstatus_file_path + time_runstatus + ".csv", "csv", str(status),"a+")
else:
self.fileoperate.writefile(self.runstatus_file_path + time_runstatus + ".csv", "csv", runstatus,"a+")
def runreslut_count(self): # 只读属性,只读csv文件
""" total 为csv的四个列标题 调用类方法,默认都为0,
null_str 为四个空栏位
"""
total=f'runresult,total:{self.total},success:{self.success},fail:{self.fail}'+"\n"
null_str=f',,,,'+"\n" # 输入为四个空列之后换行
self.fileoperate.writefile(self.filepathname + ".csv", "csv",null_str, "r+") # r+: 读写模式 写入新的 再写入之前的内容
self.fileoperate.writefile(self.filepathname + ".csv", "csv",total,"r+")
def log_output(self,step,returnvalue,actual,expected):
if returnvalue == 0 and actual == None and expected == None:
self.log.logMsg(4, "run success ")
elif returnvalue == 0 and expected != None and actual == None:
self.log.logMsg(4, f'run success ->"{expected}" in page')
elif returnvalue == 0 and expected != None and actual != None:
self.log.logMsg(4,f'run success -> actualreslut == expectedreslut -> {actual} == {expected}')
elif returnvalue == 1 and expected != None and actual == None:
if step.IgnoreErr == 1:
self.runstatus_tofile(self.runstatus_file_path,0,step)
self.runreslut_count()
raise Exception(self.log.logMsg(2, f'run fail -> "{expected}" not in page'))
else:
self.log.logMsg(2, f'run fail -> "{expected}" not in page')
elif returnvalue == 1 and expected != None and actual != None:
if step.IgnoreErr == 1:
self.runstatus_tofile(self.runstatus_file_path,0,step)
self.runreslut_count()
raise Exception(self.log.logMsg(2,f'run fail -> actualreslut != expectedreslut -> {actual} != {expected}'))
else:
self.log.logMsg(2,f'run fail -> actualreslut != expectedreslut -> {actual} != {expected}')
elif returnvalue == 1 and expected == None and actual == None:
if step.IgnoreErr == 1:
self.runstatus_tofile(self.runstatus_file_path,0,step)
self.runreslut_count()
raise Exception(self.log.logMsg(2, "run fail"))
else:
self.log.logMsg(2, "run fail")
elif returnvalue == -1:
if step.IgnoreErr == 1:
self.runstatus_tofile(self.runstatus_file_path,0,step)
if step.Behavior == "check" and step.InputValue == "source":
self.runreslut_count()
raise Exception(self.log.logMsg(2, "element find fail"))
else:
self.runreslut_count()
raise Exception(self.log.logMsg(2, "element locate fail"))
else:
if step.Behavior == "check" and step.InputValue == "source":
self.log.logMsg(2, "element find fail")
else:
self.log.logMsg(2, "element locate fail")
def casesResult(self,bm,step,fileobj,returnvalue,filepathname):
self.filepathname,self.fileobj=filepathname,fileobj
global total,success,fail
self.total+=1
if returnvalue ==0 :
self.success+=1
result = f'{int(step.Step)},{step.OperationPage},{step.Description},pass'
self.fileobj.write(result + "\n")
elif returnvalue == -1 or returnvalue ==1 :
self.fail+=1
result = f'{int(step.Step)},{step.OperationPage},{step.Description},fail'
self.fileobj.write(result + "\n")
return self.total,self.success,self.fail
def relevantInput(self,step):
input_texts=str(step.InputValue) # step.InputValue 是输入框
if type(step.InputValue) is float: # 如果输入框内容是浮点数
str_inputvalue = str(step.InputValue).split(".")[1] # 提取小数点后面的数字 如1.23 提取23给 str_inputvalue
if str_inputvalue == "0": # 判断 内容如果为0
# params = re.findall(r'\${([\s\S]+?)\}', str(str(step.InputValue).split(".")[0]))
input_texts = str(str(step.InputValue).split(".")[0]) # 提取小数点前面数字
else:
# params = re.findall(r'\${([\s\S]+?)\}', str(step.InputValue))
input_texts = str(step.InputValue) # 不为0的话,那就正常全部提取
else: # 如果是输入内容是${}格式的数据, 那提取出来赋值给 params
params = re.findall(r'\${([\s\S]+?)\}', str(step.InputValue))
if params:
input_texts = ExecuteCase().relevantParams(step.InputValue) # 提取上面 staff_file_path 的数据
elif ".json" in str(step.InputValue): # 如果输入内容包含 .json
texts_key = step.InputValue.split("||")[1] # 取值 输入内容 || 以后的内容,如果是 Password
json_file = self.fileoperate.readfile(self.staff_file_path, "json") # 调用读文件方法读取 json文件
# json内容 = {"StaffId":"ascadmin","Password":"0000abc!"}
input_texts = json_file[texts_key] # 数据则为 0000abc!
elif "today=" in step.InputValue: # 如果输入内容包含 today= ,调用 # 取值 from datetime import datetime as dt
input_texts = (dt.today()).strftime("%d-%h-%Y") # 取值当前时间 日-时-年 13-Jun-2022
elif "today-" in step.InputValue: # 如果输入内容包含 today- ,
inputnumber=step.InputValue.split("-")[1] # 取值 输入内容 - 以后的内容
if inputnumber.isdigit(): # 判断字符是否为阿拉伯数字 例如: -2
input_texts = (dt.today() + timedelta(days=-int(inputnumber))).strftime("%d-%h-%Y")
elif "today+" in step.InputValue: # 如果输入内容包含 today+ ,
inputnumber=step.InputValue.split("+")[1] # 取值 输入内容 + 以后的内容
if inputnumber.isdigit(): # 判断字符是否为阿拉伯数字 例如: +2
input_texts=(dt.today() + timedelta(days=int(inputnumber))).strftime("%d-%h-%Y")
else:
pass
step.InputValue = input_texts # 最后重新赋值给输入框
if step.OutputValue: # 例如:step.InputValue 为 staff.json||Password; 提取出来后为 0000abc!
# step.OutputValue 写为 Password 即 可以加以引用到下一个 step :引用方式:${Password}。即可提取 0000abc!
self.publicDict[step.OutputValue] = step.InputValue
def relevantTable(self, bm, step):
count_th = bm.driver.find_element_by_tag_name("table").find_elements_by_tag_name("th")
count_tr = bm.driver.find_element_by_tag_name("table").find_elements_by_tag_name("tr")
title_list = []
for coun in count_th:
text = str(coun.text).replace("\n", " ")
title_list.append(text)
text_list = []
del (count_tr[0])
for coun in count_tr:
tr_str = str(coun.text).replace("\n", "^").replace('"', '\"')
trs = tr_str.split("^")
tr_list = []
for t in range(0, len(title_list)):
tr_list.append(trs[t])
text_list.append(dict(zip(title_list, tr_list)))
i = 0
j = 1
dt_tag = []
for cr in count_tr:
i = 1
tr_td = cr.find_elements_by_tag_name("td")
b = None
c = None
td_tag_list = []
areavalue = True
selecvalue = True
for td in tr_td:
try:
areavalue = bm.driver.find_element_by_xpath(
'//*[@id="root"]' + "/div/main/div[4]/div/table/tbody/tr[" + str(i) + "]/td[" + str(
j) + "]/div/div/textarea[1]").is_displayed()
textarea_tag = td.find_element_by_xpath(
'//*[@id="root"]' + "/div/main/div[4]/div/table/tbody/tr[" + str(i) + "]/td[" + str(
j) + "]/div/div/textarea[1]").tag_name
td_tag_list.append(textarea_tag)
except:
areavalue = False
try:
selecvalue = bm.driver.find_element_by_xpath(
'//*[@id="root"]' + "/div/main/div[4]/div/table/tbody/tr[" + str(i) + "]/td[" + str(
j) + "]/div/select").is_displayed()
select_tag = td.find_element_by_xpath(
'//*[@id="root"]' + "/div/main/div[4]/div/table/tbody/tr[" + str(i) + "]/td[" + str(
j) + "]/div/select").tag_name
td_tag_list.append(select_tag)
except:
selecvalue = False
if areavalue == False and selecvalue == False:
tag = td.tag_name
td_tag_list.append(tag)
j += 1
dt_tag.append(dict(zip(title_list, td_tag_list)))
break
tag_list = []
for dt_ta in dt_tag:
for dt in dt_ta:
tag_list.append(dt)
dict_list = []
dict_pe = step.PositioningExpression
dict_pes = json.loads(dict_pe)
for dict_pe in dict_pes:
dict_list.append(dict_pe)
dict_list_last = dict_list[-1]
bijiao_count = 0
dict_pes_len = len(dict_pes)
for text_li in text_list:
for text_l in text_li:
for dict_p in dict_pes:
if text_li[text_l] == dict_pes[dict_p]:
bijiao_count += 1
if bijiao_count == dict_pes_len:
if '"' in dict_pes[dict_p]:
str(dict_pes[dict_p]).replace('"', '\"')
positioningexpression = ("//*[contains(text()," + '"' + dict_pes[dict_list_last] + '"' + ")]")
step.PositioningExpression = positioningexpression
else:
positioningexpression = ("//*[contains(text()," + '"' + dict_pes[dict_list_last] + '"' + ")]")
step.PositioningExpression = positioningexpression
break
bijiao_count = 0