AAAI 2023:清华SIGS信息学部19篇论文入选,含多模态、目标检测、语义分割等方向...
2022
点击蓝字 关注我们
关注并星标
从此不迷路
计算机视觉研究院

计算机视觉研究院专栏
作者:Edison_G
AAAI是人工智能领域最重要的顶级国际学术会议之一,旨在推动人工智能领域的研究和应用,增进大众对人工智能的了解。据悉,AAAI本年度共接收8777篇论文投稿,录取率仅为19.6%。
公众号ID|ComputerVisionGzq
学习群|扫码在主页获取加入方式
概述
11月20日,国际人工智能顶级会议国际先进人工智能协会2023年会(AAAI 2023, Association for the Advance of Artificial Intelligence,2023)论文录用结果发布。
1.《基于对比掩码自编码器的自监督视频哈希检索》(Contrastive Masked Autoencoders for Self-Supervised Video Hashing),作者:计算机技术项目2022级硕士生王煜庭(导师:夏树涛教授)
作者认为已有两阶段自监督视频哈希检索框架的训练方式过于繁琐,在实际应用中不够实用。基于此,作者提出对比掩码自编码器的单一框架。作者首先利用高度时序掩码来减少输入视频的信息量和邻接帧关联,使模型能从重建中更好地理解视频语义信息。作者进一步将重建框架与实例判别性的对比学习结合,使模型能在单一阶段内完成对视频语义信息和视频间相似性关系的同步学习。在三个基准视频数据集上的大量消融实验和对比实验证明了对比掩码自编码器框架的优越检索性能。
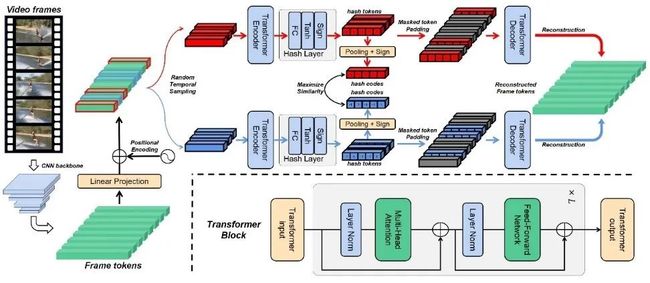
图1:对比掩码自编码器框架图
2.《基于特征域块匹配的可学习分布式图像压缩算法》(Learned Distributed Image Compression with Multi-Scale Patch Matching in Feature Domain),作者:计算机科学与技术专业2022级博士生黄钰钧(导师:夏树涛教授)
为了更好地利用分布式压缩场景下的边信息,作者提出了多尺度特征块匹配(MSFDPM),以此在解码端充分地利用边信息。具体而言,MSFDPM由一个边信息特征提取器、一个多尺度特征域块匹配模块和一个多尺度特征融合网络组成。此外,作者提出重用浅层块间的相关性以加速深层的块匹配。最后,在多尺度特征域中的块匹配与图像域块匹配方法相比,压缩率提高了约20%。
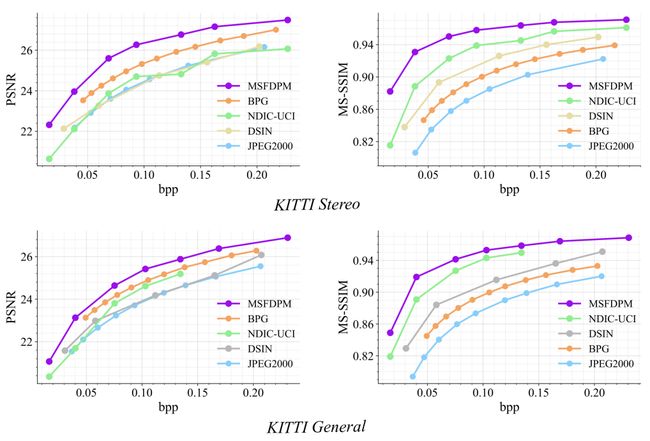
图2:不同方法的率失真曲线
3.《利用偏好冲突评分和梯度对齐对抗未知偏好》(Combating Unknown Bias with Effective Bias-Conflicting Scoring and Gradient Alignment),作者:计算机科学与技术专业2021级博士生赵博文(导师:夏树涛教授)
依赖数据集中的捷径实现既定目标的模型在鲁棒性和泛化性上表现较差。鉴定-强调范式在处理未知偏好上显示出不错的潜力。然而,作者发现这一范式仍受到两个挑战的困扰:鉴定偏好冲突样本的能力和后续的强调策略都尚不完备。作者提出了一种有效的偏好冲突评分方法(ECS)和一种基于梯度对齐(GA)的无偏模型训练方式来解决以上两个问题。不同设定下的多组数据集的实验结果表明所提出的解决方案可以有效地减轻未知偏好对模型的影响。
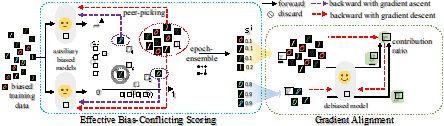
图3:整体纠偏方案示意图
4.《用于加速图像超分网络的通用频域框架》(FSR: A General Frequency-oriented Framework to Accelerate Image Super-resolution Networks),作者:计算机技术项目2022级硕士生李金敏 (导师:夏树涛教授)
作者认为当前的超分工作虽然取得了卓越的性能,但依然存在计算量过大、推理时间慢等问题,导致无法应用到移动设备端。本文提出一种通用的基于频域的加速网络,可以加速现有的大多数方法。在四种经典网络和三个公开数据集上分别验证了有效性,在保持原有方法性能的同时,平均减少了40%的计算量和50%的推理时间。本文共提出了三个创新点:转换注意力块用于提取全局特征、空间上下文块用于提取局部特征、自适应的损失权重用于权衡空域损失和频域损失。
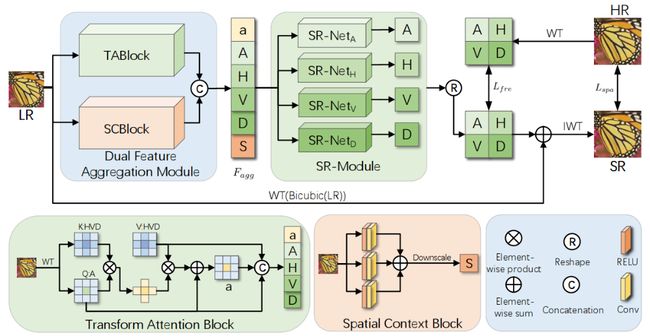
图4:所提出的FSR的整体框架
5.《基于多模态知识迁移的开放词典多标签学习》(Open-Vocabulary Multi-Label Classification via Multi-modal Knowledge Transfer),作者:人工智能项目2020级硕士生何肃南(导师:夏树涛教授)
基于图文预训练模型的开放词典(Open-Vocabulary)分类模型在单标签零样本学习上取得了显著效果,但如何将这种能力迁移到多标签场景仍是亟待探索的问题。作者提出了一种基于多模态知识迁移(Multi-modal Knowledge Transfer, MKT)框架实现了多标签的开放词典分类。作者基于图文预训练模型强大的图文匹配能力实现标签预测。为了优化标签映射和提升图像-标签映射的一致性,作者引入了提示学习(Prompt-Tuning)和知识蒸馏(Knowledge Distillation)。同时,作者提出了一个简单但是有效的双流模块来同时捕捉局部和全局特征,提高了模型的多标签识别能力。在NUS-WIDE和OpenImage两个公开数据集上的实验结果表明,该方法有效实现了多标签的开放集合学习。
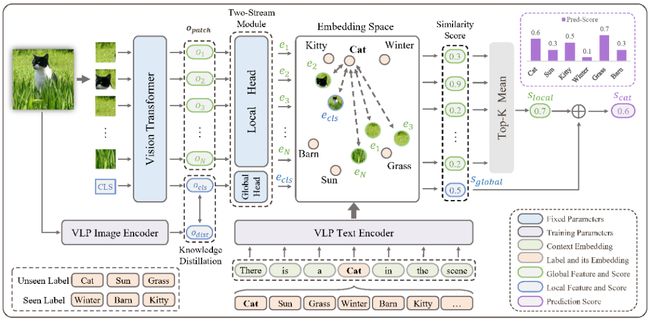
图5:MKT模型框架图
6.《基于视觉的常识获取》(Visually Grounded Commonsense Knowledge Acquisition),作者:计算机技术项目2021级硕士生余天予(导师:郑海涛副教授)
目前的常识获取方法往往只关注于文本领域的常识获取,但是这些方法受限于文本的稀疏性和报道的偏差。另一方面,视觉感知提供了真实世界中大量的常识信息,比如(人,可以抓住,瓶子)。作者提出了将视觉常识获取定义为一个远程监督的多样本学习任务,并设计了相应的框架来解决此任务。实验结果充分证明了有效性,并验证了多个模态信息的融合可以进一步提高常识获取的质量。
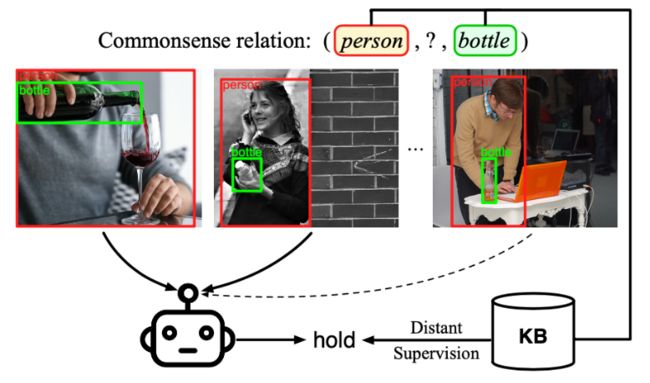
图6:常识归纳框架
7.《全局混合:用聚类消除歧义性》(Global Mixup: Eliminating Ambiguity with Clustering),作者:计算机技术项目2020级硕士生谢湘晋(导师:郑海涛副教授)
数据增强的标签确定和样本生成一直以来都是一次性完成的,这将数据增强陷入两难的困境:无法同时兼得具有较高置信度的标签以及与原始样本同质性低的样本。为了解决这一问题,本文对全局混合(Mixup)相关的数据增强方法做出改进,挖掘特征的相似性并通过聚类关系为与原始样本同质性低的增强样本重标签,消除因为线性插值所带来的歧义性。本文在文本分类任务上验证了方法的有效性,同时理论上支持任意数据增强方法的重标签。
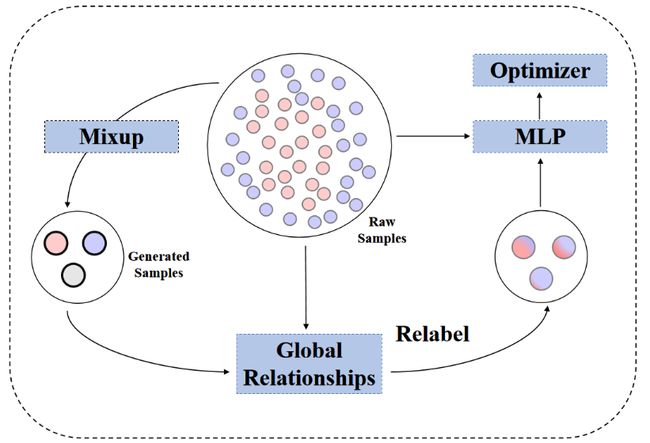
图7:全局混合流程
8.《通过全局模态重构学习语义对齐的面向检索的视频-语言预训练》(Learning Semantic Alignment with Global Modality Reconstruction for Video-Language Pre-training towards Retrieval),作者:计算机技术项目2019级硕士生李明超(导师:郑海涛副教授)
视频-语言预训练对于基于文本的视频检索任务是十分重要的。之前的预训练方法受限于语义不对齐的影响。其原因是这些方法忽略了序列对齐而关注于关键词汇的对齐。为了减轻这个问题,论文提出了学习语义对齐的视频-语言预训练方法。具体地,使用了全局模态重构和跨模态自对比方法来更好地学习序列级别的对齐关系。论文使用了详实的实验在基于文本的视频检索任务和视频时刻检索任务上证明了此方法的有效性。
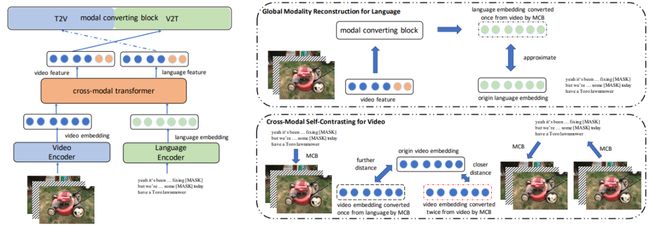
图8:FEEL结构
9.《源域缺失目标检测下的对抗域适应学习》(Adversarial Alignment for Source Free Object Detection),作者:人工智能项目2020级硕士生褚峤松(导师:李秀教授)
作者认为在源域数据缺失场景下,基于预训练模型自训练的传统域适应方法过于依赖每轮迭代的伪标签质量,因此作者将对抗学习的域适应对齐方法引入无源域数据目标检测。作者提出了一种计算目标域数据方差的度量,实验表明这种方法能够在没有标签的情况下有效估计检测结果的召回率,并将问题还原为有源的域适应目标检测。在四种迁移场景下的实验表明,该方法能有效地划分目标域数据集。
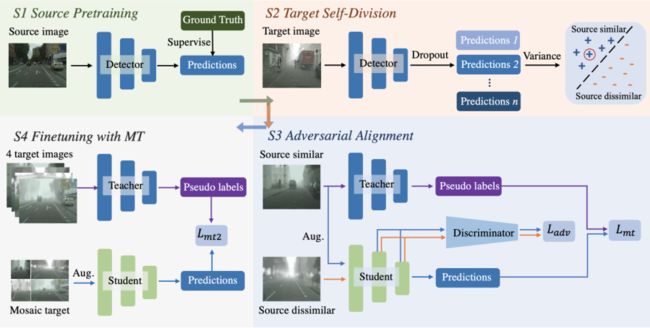
图9:多阶段模型框架图
10.《基于注意力评审团的数据高效图像质量评价算法》(Data-Efficient Image Quality Assessment with Attention-Panel Decoder)作者:人工智能项目2021级硕士生秦冠羿(导师:李秀教授)
由于质量评价数据集样本数量少,且视觉注意力模型预训练数据域和微调数据域的注意分布不同,因此,基于视觉注意力模型的图像质量评价算法无法学习出较好的泛化能力。作者在视觉注意力模型中引入解码器,并基于解码器实现了注意力评审团机制。该机制为模型提供了更多的可能特征表达,能够重新建立起适合下游任务的注意分布。通过在多个图像质量评价数据集上训练测试,该算法展示出了强大的泛化能力与数据效率。
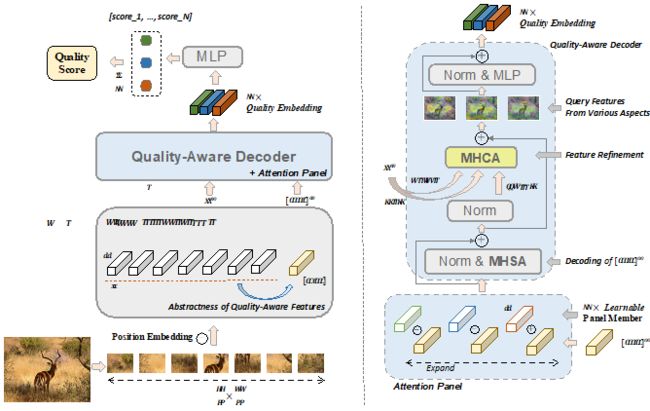
图10:模型结构图
11.《面向稀疏标注目标检测的校正教师模型》(Calibrated Teacher for Sparsely Annotated Object Detection),作者:人工智能项目2020级硕士生王颢涵(导师:王好谦教授)
稀疏标注目标检测旨在解决目标检测的训练图片中,部分实例未被标注的问题。近年来的研究采用基于伪标签的方法挖掘未被标注的实例用于训练,但选择用于筛选伪标签的置信度阈值需要大量的实验调参。作者设计了一个基于置信度校正的教师-学生网络框架,引入一个可学习的校正器,将伪标签候选框的置信度校正为无偏置信度,从而统一了不同检测器在不同训练时期下的阈值选择规律。该方法极大简化了调参工作量,并在COCO数据集下的多组稀疏标注的实验设置下取得了行业内的最佳性能。

图11:不同检测器/不同训练时期置信度校正示意图
12.《从数字病理图像进行患者级生存预测的分层视觉转换器》(HVTSurv: Hierarchical Vision Transformer for Patient-level Survival Prediction from Whole Slide Image),作者:人工智能项目2021级硕士生邵朱晨(导师:王好谦教授)
在患者级多实例学习中,基于数字病理图像的生存预测是一项具有挑战性的任务。由于患者的大量数据(一个或多个切片)和切片的不规则形状特性,模型很难在患者级包中充分探索空间、上下文和层次交互。作者提出了一个分层视觉转换器框架,使用来自癌症基因组图谱的 6 种癌症类型的 3104 名患者和 3752 个数字病理图像验证有效性。在6个数据集上,平均指标比此前的弱监督方法高2.50-11.30%。消融研究和注意力可视化进一步验证了其优越性。
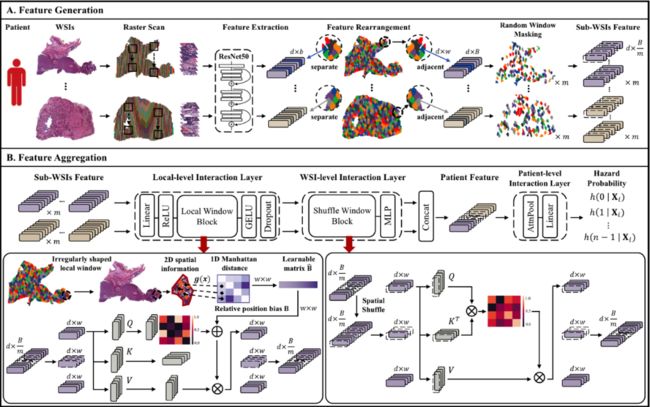
图12:特征的预处理以及分层聚合框架
13.《截断-分离-对比:一种学习噪声视频的框架》(Truncate-Split-Contrast: A Framework for Learning from Mislabeled Videos)作者:计算机技术项目2021级硕士生王子啸(导师:袁春教授)
带噪学习是一个经典问题,已有的研究大多集中于图像任务,而视频任务却少有探索,将已有的方法直接从图像迁移到视频上并不可取。本文提出了适用于视频带噪学习的两个新策略:一个名为通道截断的通道挑选方法用于基于特征的标签噪声检测;一个名为噪声对比学习的新的对比策略。实验表明,作者提出的方法显著超越已有的基线方法。通过将维度减少到原来的百分之十,所提方法在含有大量噪声(80%对称噪声)的Mini-Kinetics数据集上取得了超过0.4的噪声检测F1分数的提升以及5%的分类准确率提升。噪声对比学习还为Mini-Kinetics和Sth-Sth-V1数据集带来了平均超过1.6%的分类准确率提升。
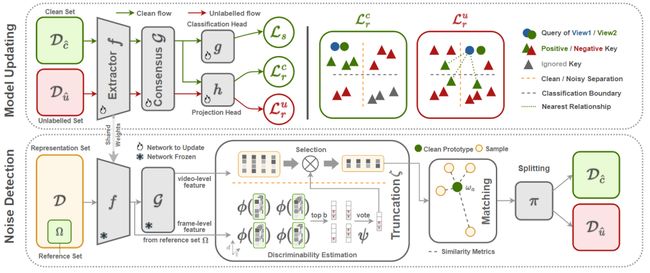
图13:提出的方法在带噪数据集上的训练流程
14.《达尔文范式模型升级:基于选择性兼容的模型进化》(Darwinian Model Upgrades: Model Evolving with Selective Compatibility),作者:数据科学和信息技术项目2019级硕士生张斌杰(导师:袁春教授)
为了解决现有兼容方法存在的新模型鉴别力与新-旧模型兼容性之间此消彼长的困境,本文提出了达尔文模型升级新范式。该范式将模型升级过程中的继承与进化阶段解耦,通过选择性后向兼容训练实现对旧特征的继承,通过一个轻量化的前向进化分支实现对旧特征的进化。
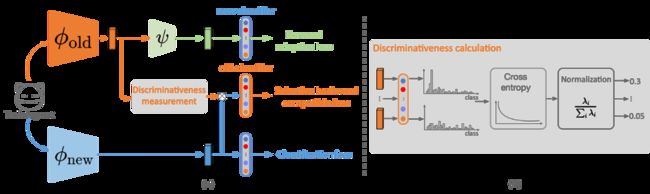
图14:达尔文范式模型升级的训练框架
15.《动态集成低保真度专家——缓解神经架构搜索“冷启动”》(Dynamic Ensemble of Low-fidelity Experts: Mitigating NAS “Cold-Start”),作者:电子与通信工程项目2021级硕士生赵俊博(导师:廖庆敏教授)
基于预测器的神经架构搜索存在严重的“冷启动”问题,因为需要大量的架构-真实性能数据才能获得一个有效的预测器。本文专注于利用低保真度信息以缓解预测器训练对大量数据的需求。为更好地融合不同类型的低保真信息提供的有益信息,本文提出了一种动态集成预测框架,在有限的数据量下大幅提升了预测器的预测能力。例如,在NDS-ResNet搜索空间中仅使用25个架构-真实性能数据,所提方法将实际性能与预测得分之间的肯德尔相关系数从0.2549提高到0.7064。此方法可以轻易地与现有的基于预测器的神经架构搜索框架结合,以发现更好的架构。
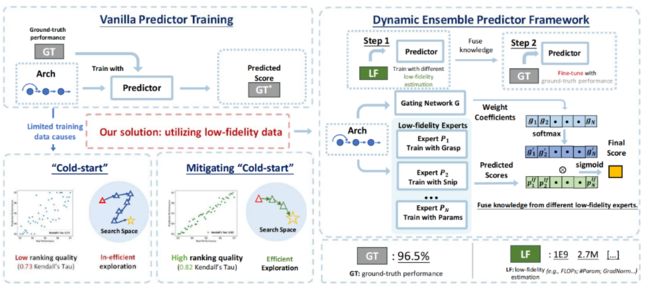
图15:方法动机与框架示意图
16.《针对安全关键任务的无模型强化学习算法评估》(Evaluating Model-free Reinforcement Learning toward Safety-critical Tasks) 作者:人工智能项目2020级硕士生张麟睿 (导师:王学谦教授)
在自主智能体的应用中,安全性至关重要,但目前尚缺乏对复杂动力学环境下满足逐状态安全约束的强化学习算法评估。在本文中,作者重新思考了先前工作并将它们分别归类为基于投影、基于恢复和基于优化的方法。此外,作者还提出了展开安全层算法。该算法结合了安全优化和安全投影的优势,通过深度展开架构强制满足硬约束,在约束策略优化和执行过程中具有显式结构优势。为了促进进一步研究,作者开源了SafeRL-Kit算法库。该算法库包含相关算法在统一的框架中的实现,为安全关键任务提供了即插即用的接口和评估基准。
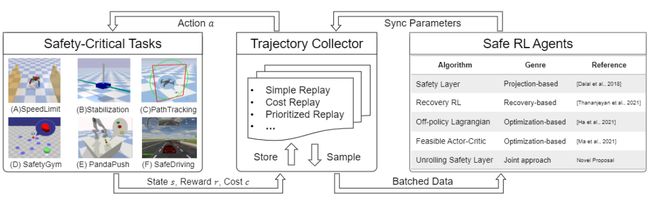
图16:本文开源的SafeRL-Kit代码库实现
17.《音由相生:从三维脸型到个性化语音》(What Does Your Face Sound Like? 3D Face Shape Towards Voice),作者:计算机技术项目2021级硕士生杨智涵(导师:吴志勇副研究员)
基于人脸生成个性化语音在影视配音、短视频创作等领域具有广泛的应用前景。作者在该领域首次引入三维脸型信息,提出了一种从三维脸型到个性化语音音色的语音生成方法。三维脸型信息与决定人类音色的骨传导特性直接相关,与语音特征有明确的解剖学关系,具有更好的可解释性;还具有独立于光照、姿态等的天然优势,可以解耦无关因素更准确控制音色。主客观实验均表明,所提方法可以生成与人脸更匹配的语音;还可以通过控制人脸脸型生成多样化、个性化的定制语音,具有更好的可解释性和可控性。感谢贾珈教授、吴昊哲师兄对论文工作的支持。
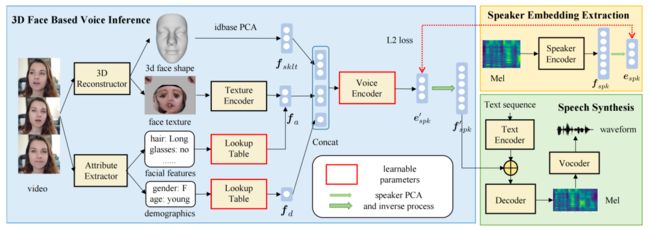
图17:基于三维脸型信息生成个性化音色语音的方法总体框架
18.《基于数据合成和特征一致性约束的组织病理图像弱监督语义分割》(Weakly-Supervised Semantic Segmentation for Histopathology Images Based on Dataset Synthesis and Feature Consistency Constraint),作者:计算机技术项目2022级硕士生方子介(导师:王智副教授)。
作者认为传统的弱监督语义分割大多基于类激活映射方法,其面临着分割边界不精准的问题。病理组织结构的同质性更强化了这一缺陷。作者提出了一种新的弱监督组织病理图像分割框架PistoSeg。首先,基于马赛克变换,提出了一种能够生成像素级掩模的数据合成方法;其次,考虑合成图像与真实图像之间的差异,设计了一种基于注意力机制的特征一致性约束,对合成的伪掩模进行进一步优化。最后,利用优化后的伪掩模训练精确分割模型进行测试。基于WSSS4LUAD和BCSS-WSSS的实验验证了所提出方法在弱监督组织病理图像分割任务上的优越性。
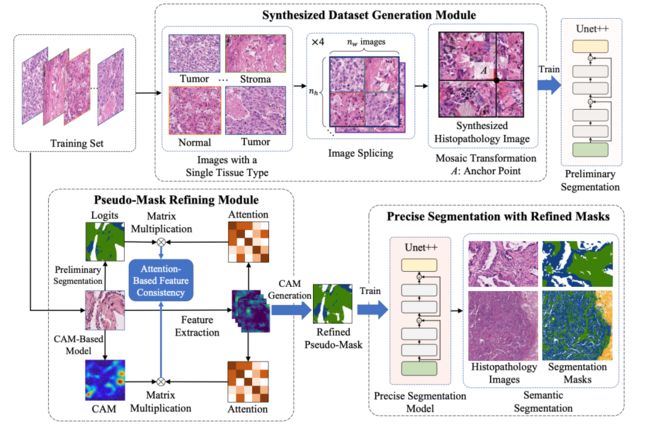
图18:PistoSeg框架的总体架构
19.《一种基于内存结构化剪枝的图像复原模型优化方法》(Memory-Oriented Structural Pruning for Efficient Image Restoration),作者:电子与通信工程2020级硕士生史祥生(导师:董宇涵副教授)
基于深度学习的图像复原(Image Restoration)模型的硬件资源开销非常庞大,限制了它们在移动端等实际场景中的应用。为了改善深度图像复原模型的峰值内存开销,作者提出了一种专注于内存优化的结构化剪枝(MOSP)方法。为了压缩长距离跳跃连接(图像复原模型内存开销的一大来源),作者在跳跃连接上引入压缩器(Compactor)模块,以解耦跳跃连接和主分支的剪枝过程。MOSP方法采用一种迭代剪枝的范式,逐步优化模型各层的内存开销。与基线剪枝方法相比,MOSP方法可在不显著影响剪枝模型任务性能的同时优化其内存开销。

图19:方法框架图
转载:SIGS信息科学与技术学部
END
转载请联系本公众号获得授权
计算机视觉研究院学习群等你加入!
ABOUT
计算机视觉研究院
计算机视觉研究院主要涉及深度学习领域,主要致力于目标检测、图像分割、模型量化、模型部署等研究方向。研究院接下来会不断分享最新的论文算法新框架,我们这次改革不同点就是,我们要着重”研究“。之后我们会针对相应领域分享实践过程,让大家真正体会摆脱理论的真实场景,培养爱动手编程爱动脑思考的习惯!
VX:2311123606
