EasyNLP集成K-Global Pointer算法,支持中文信息抽取
作者:周纪咏、汪诚愚、严俊冰、黄俊
导读
信息抽取的三大任务是命名实体识别、关系抽取、事件抽取。命名实体识别是指识别文本中具有特定意义的实体,包括人名、地名、机构名、专有名词等;关系抽取是指识别文本中实体之间的关系;事件抽取是指识别文本中的事件信息并以结构化的形式呈现出来。信息抽取技术被广泛应用于知识图谱的构建、机器阅读理解、智能问答和信息检索系统中。信息抽取的三大任务不是相互独立的关系,而是相互依存、彼此依赖的关系。命名实体识别是关系抽取、事件抽取的基础,关系抽取是事件抽取的基础。同时,关系抽取、事件抽取对命名实体识别任务有帮助,事件抽取对关系抽取任务有帮助。但目前关于仅使用一个模型完成中文信息抽取三大任务的研究相对较少,因此,我们提出K-Global Pointer算法并集成进EasyNLP算法框架中,使用户可以使用自定义数据集训练中文信息抽取模型并使用。
EasyNLP(https://github.com/alibaba/EasyNLP)是阿⾥云机器学习PAI团队基于PyTorch开发的简单易⽤且功能丰富的中⽂NLP算法框架,⽀持常⽤的中⽂预训练模型和⼤模型落地技术,并且提供了从训练到部署的⼀站式NLP开发体验。EasyNLP提供了简洁的接⼝供⽤户开发NLP模型,包括NLP应⽤AppZoo和预训练ModelZoo,同时提供技术帮助⽤户⾼效的落地超⼤预训练模型到业务。由于跨模态理解需求的不断增加,EasyNLP也⽀持各种跨模态模型,特别是中⽂领域的跨模态模型,推向开源社区,希望能够服务更多的NLP和多模态算法开发者和研究者,也希望和社区⼀起推动NLP/多模态技术的发展和模型落地。
本⽂简要介绍K-Global Pointer的技术解读,以及如何在EasyNLP框架中使⽤K-Global Pointer模型。
K-Global Pointer模型详解
Global Pointer模型是由苏剑林提出的解决命名实体识别任务的模型, n ∗ n n*n n∗n 的矩阵 A A A( n n n为序列长度), A [ i , j ] A[i,j] A[i,j]代表的是序列 i i i到序列 j j j组成的连续子串为对应实体类型的概率,通过设计门槛值 B B B即可将文本中具有特定意义的实体识别出来。
K-Global Pointer模型是在Global Pointer模型的基础之上改进的。首先我们将仅支持命名实体识别的模型拓展成支持中文信息抽取三大任务的模型。然后,我们使用了MacBERT预训练语言模型来将文本序列转换成向量序列。最后我们针对不同的任务设计了一套prompt模板,其能帮助预训练语言模型“回忆”起自己在预训练时“学习”到的内容。接下来,我们将根据中文信息抽取三大任务分别进行阐述。
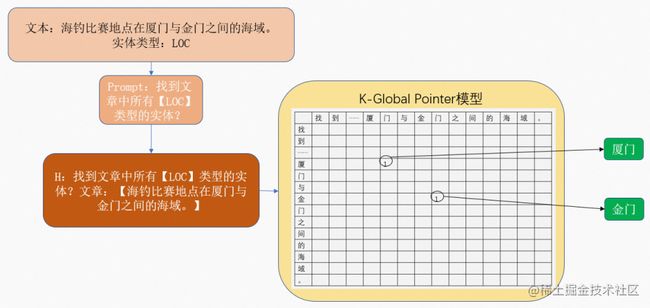
针对命名实体识别任务,我们有文本 w 1 , w 2 , w 3 , . . . , w n w_{1},w_{2},w_{3},...,w_{n} w1,w2,w3,...,wn以及需要提取的实体类型entity_type,对应的prompt为“找到文章中所有【entity_type】类型的实体?”,对应的输入模型的文本 H H H为“找到文章中所有【entity_type】类型的实体?文章:【 w 1 , w 2 , w 3 , . . . , w n w_{1},w_{2},w_{3},...,w_{n} w1,w2,w3,...,wn】”,模型经过相应的处理即可输出文本中实体类型为entity_type的实体。
针对关系抽取任务,我们有文本 w 1 , w 2 , w 3 , . . . , w n w_{1},w_{2},w_{3},...,w_{n} w1,w2,w3,...,wn以及需要提取的关系类型relation_type(subject_type-predicate-object_type),分为两步。第一步,对应的prompt为“找到文章中所有【subject_type】类型的实体?”,对应的输入模型的文本 H H H为“找到文章中所有【subject_type】类型的实体?文章:【 w 1 , w 2 , w 3 , . . . , w n w_{1},w_{2},w_{3},...,w_{n} w1,w2,w3,...,wn】”,模型经过相应的处理即可输出文本中实体类型为subject_type的实体 e 1 e_{1} e1。第二步,对应的prompt为“找到文章中所有【 e 1 e_{1} e1】的【 p r e d i c a t e predicate predicate】?”,对应的输入模型的文本 H H H为“找到文章中所有【 e 1 e_{1} e1】的【 p r e d i c a t e predicate predicate】?文章:【 w 1 , w 2 , w 3 , . . . , w n w_{1},w_{2},w_{3},...,w_{n} w1,w2,w3,...,wn】”,模型经过相应的处理即可输出实体 e 2 e_{2} e2。即可构成关系三元组( e 1 、 p r e d i c a t e 、 e 2 e_{1}、predicate、e_{2} e1、predicate、e2)。

针对事件抽取任务,我们有文本 w 1 , w 2 , w 3 , . . . , w n w_{1},w_{2},w_{3},...,w_{n} w1,w2,w3,...,wn以及需要提取的事件类型 c l a s s class class,每个 c l a s s class class包含event_type以及role_list(r_{1},r_{2},…),分为两步。第一步,对应的prompt为“找到文章中所有【event_type】类型的实体?”,对应的输入模型的文本 H H H为“找到文章中所有【event_type】类型的实体?文章:【 w 1 , w 2 , w 3 , . . . , w n w_{1},w_{2},w_{3},...,w_{n} w1,w2,w3,...,wn】”,模型经过相应的处理即可输出的实体 e e e。第二步,针对role_list中不同的 r x r_{x} rx,对应的prompt为“找到文章中所有【 e e e】的【 r x r_{x} rx】?”,对应的输入模型的文本 H H H为“找到文章中所有【 e e e】的【 r x r_{x} rx】?文章:【 w 1 , w 2 , w 3 , . . . , w n w_{1},w_{2},w_{3},...,w_{n} w1,w2,w3,...,wn】”,模型经过相应的处理即可输出实体 e x e_{x} ex。即可构成事件{event_type: e e e,role_list:{r_{1}:e_{1},r_{2}:e_{2},…}}。

K-Global Pointer模型的实现与效果
在EasyNLP框架中,我们在模型层构建了K-Global Pointer模型的Backbone,其核⼼代码如下所示:
self.config = AutoConfig.from_pretrained(pretrained_model_name_or_path)
self.backbone = AutoModel.from_pretrained(pretrained_model_name_or_path)
self.dense_1 = nn.Linear(self.hidden_size, self.inner_dim * 2)
self.dense_2 = nn.Linear(self.hidden_size, self.ent_type_size * 2)
context_outputs = self.backbone(input_ids, attention_mask, token_type_ids)
outputs = self.dense_1(context_outputs.last_hidden_state)
qw, kw = outputs[..., ::2], outputs[..., 1::2]
pos = SinusoidalPositionEmbedding(self.inner_dim, 'zero')(outputs)
cos_pos = pos[..., 1::2].repeat_interleave(2, dim=-1)
sin_pos = pos[..., ::2].repeat_interleave(2, dim=-1)
qw2 = torch.stack([-qw[..., 1::2], qw[..., ::2]], 3)
qw2 = torch.reshape(qw2, qw.shape)
qw = qw * cos_pos + qw2 * sin_pos
kw2 = torch.stack([-kw[..., 1::2], kw[..., ::2]], 3)
kw2 = torch.reshape(kw2, kw.shape)
kw = kw * cos_pos + kw2 * sin_pos
logits = torch.einsum('bmd,bnd->bmn', qw, kw) / self.inner_dim ** 0.5
bias = torch.einsum('bnh->bhn', self.dense_2(last_hidden_state)) / 2
logits = logits[:, None] + bias[:, ::2, None] + bias[:, 1::2, :, None]
mask = torch.triu(attention_mask.unsqueeze(2) * attention_mask.unsqueeze(1))
y_pred = logits - (1-mask.unsqueeze(1))*1e12
y_true = label_ids.view(input_ids.shape[0] * self.ent_type_size, -1)
y_pred = y_pred.view(input_ids.shape[0] * self.ent_type_size, -1)
loss = multilabel_categorical_crossentropy(y_pred, y_true)
为了验证EasyNLP框架中K-Global Pointer模型的有效性,我们使用DuEE1.0、DuIE2.0、CMeEE-V2、CLUENER2020、CMeIE、MSRA、People’s_Daily 7个数据集联合进行训练,并在各个数据集上分别进行验证。其中CMeEE-V2、CLUENER2020、MSRA、People’s_Daily数据集适用于命名实体识别任务,DuIE2.0、CMeIE数据集适用于关系抽取任务,DuEE1.0数据集适用于事件抽取任务。结果如下所示:
| 数据集 | DuEE1.0 | DuIE2.0 | CMeEE-V2 | CLUENER2020 | CMeIE | MSRA | People’s_Daily |
|---|---|---|---|---|---|---|---|
| 参数设置B=0.6 | 0.8657 | 0.8725 | 0.8266 | 0.889 | 0.8155 | 0.9856 | 0.9933 |
可以通过上述结果,验证EasyNLP框架中K-Global Pointer算法实现的正确性、有效性。
K-Global Pointer模型使用教程
以下我们简要介绍如何在EasyNLP框架使⽤K-Global Pointer模型。分为三种情况,分别是①用户使用数据训练模型②用户验证训练好的模型③用户使用训练好的模型完成中文信息抽取任务。我们提供了联合DuEE1.0、DuIE2.0、CMeEE-V2、CLUENER2020、CMeIE、MSRA、People’s_Daily 7个数据集的数据,可以通过sh run_train_eval_predict_user_defined_local.sh来下载获取train.tsv、dev.tsv、predict_input_EE.tsv、predict_input_NER.tsv文件,其中train.tsv文件可用于训练、dev.tsv文件可用于验证、predict_input_EE.tsv、predict_input_NER.tsv文件可用于测试。用户也可以使用自定义数据。
⽤户可以直接参考GitHub(https://github.com/alibaba/EasyNLP)上的说明安装EasyNLP算法框架。然后cd EasyNLP/examples/information_extraction。
①用户使用数据训练模型
数据准备
训练模型需要使用训练数据和验证数据。用户可以使用我们提供的数据,也可以使用自定义数据。数据表示为train.tsv文件以及dev.tsv文件,这两个⽂件都包含以制表符\t分隔的五列,第一列是标签,第二列是上文K-Global Pointer模型详解中提到的,第三列是答案的开始,第四列是答案的的结束,第五列是答案。样例如下:
People's_Daily-train-0 ['找到文章中所有【LOC】类型的实体?文章:【海钓比赛地点在厦门与金门之间的海域。】'] [29, 32] [31, 34] 厦门|金门
DuIE2.0-train-0 ['找到文章中所有【图书作品】类型的实体?文章:【《邪少兵王》是冰火未央写的网络小说连载于旗峰天下】'] [24] [28] 邪少兵王
DuIE2.0-train-1 ['找到文章中【邪少兵王】的【作者】?文章:【《邪少兵王》是冰火未央写的网络小说连载于旗峰天下】'] [28] [32] 冰火未央
DuEE1.0-train-25900 ['找到文章中所有【竞赛行为-夺冠】类型的实体?文章:【盖斯利在英国大奖赛首场练习赛中夺冠】'] [41] [43] 夺冠
DuEE1.0-train-25901 ['找到文章中【夺冠】的【冠军】?文章:【盖斯利在英国大奖赛首场练习赛中夺冠】'] [19] [22] 盖斯利
DuEE1.0-train-25902 ['找到文章中【夺冠】的【夺冠赛事】?文章:【盖斯利在英国大奖赛首场练习赛中夺冠】'] [25] [35] 英国大奖赛首场练习赛
训练模型
代码如下:
python main.py \
--mode train \
--tables=train.tsv,dev.tsv \
--input_schema=id:str:1,instruction:str:1,start:str:1,end:str:1,target:str:1 \
--worker_gpu=4 \
--app_name=information_extraction \
--sequence_length=512 \
--weight_decay=0.0 \
--micro_batch_size=2 \
--checkpoint_dir=./information_extraction_model/ \
--data_threads=5 \
--user_defined_parameters='pretrain_model_name_or_path=hfl/macbert-large-zh' \
--save_checkpoint_steps=500 \
--gradient_accumulation_steps=8 \
--epoch_num=3 \
--learning_rate=2e-05 \
--random_seed=42
训练好的模型保存在information_extraction_model文件夹中。
②用户验证训练好的模型
数据准备
验证模型需要使用验证数据。用户可以使用我们提供的数据,也可以使用自定义数据。数据表示为dev.tsv文件,这个⽂件包含以制表符\t分隔的五列,第一列是标签,第二列是上文K-Global Pointer模型详解中提到的 H H H,第三列是答案的开始,第四列是答案的的结束,第五列是答案。样例如下:
People's_Daily-train-0 ['找到文章中所有【LOC】类型的实体?文章:【海钓比赛地点在厦门与金门之间的海域。】'] [29, 32] [31, 34] 厦门|金门
DuIE2.0-train-0 ['找到文章中所有【图书作品】类型的实体?文章:【《邪少兵王》是冰火未央写的网络小说连载于旗峰天下】'] [24] [28] 邪少兵王
DuIE2.0-train-1 ['找到文章中【邪少兵王】的【作者】?文章:【《邪少兵王》是冰火未央写的网络小说连载于旗峰天下】'] [28] [32] 冰火未央
DuEE1.0-train-25900 ['找到文章中所有【竞赛行为-夺冠】类型的实体?文章:【盖斯利在英国大奖赛首场练习赛中夺冠】'] [41] [43] 夺冠
DuEE1.0-train-25901 ['找到文章中【夺冠】的【冠军】?文章:【盖斯利在英国大奖赛首场练习赛中夺冠】'] [19] [22] 盖斯利
DuEE1.0-train-25902 ['找到文章中【夺冠】的【夺冠赛事】?文章:【盖斯利在英国大奖赛首场练习赛中夺冠】'] [25] [35] 英国大奖赛首场练习赛
验证模型
代码如下:
python main.py \
--mode evaluate \
--tables=dev.tsv \
--input_schema=id:str:1,instruction:str:1,start:str:1,end:str:1,target:str:1 \
--worker_gpu=4 \
--app_name=information_extraction \
--sequence_length=512 \
--weight_decay=0.0 \
--micro_batch_size=2 \
--checkpoint_dir=./information_extraction_model/ \
--data_threads=5
③用户使用训练好的模型完成中文信息抽取任务
数据准备
测试模型需要使用测试数据。用户可以使用我们提供的数据,也可以使用自定义数据。
对于命名实体识别任务,数据表示为predict_input_NER.tsv文件,这个⽂件包含以制表符\t分隔的三列,第一列是标签,第二列是实体类型,第三列是文本。我们支持对同一个文本识别多种实体类型,仅需要在第二列中将不同的实体类型用;分隔开。样例如下:
1 LOC;ORG 海钓比赛地点在厦门与金门之间的海域。
对于关系抽取任务,数据表示为predict_input_RE.tsv文件,这个⽂件包含以制表符\t分隔的三列,第一列是标签,第二列是关系类型,第三列是文本。我们支持对同一个文本识别多种关系类型,仅需要在第二列中将不同的关系类型用;分隔开。对于一个关系类型relation_type(subject_type-predicate-object_type)表示为subject_type:predicate,样例如下:
1 图书作品:作者 《邪少兵王》是冰火未央写的网络小说连载于旗峰天下
对于事件抽取任务,数据表示为predict_input_EE.tsv文件,这个⽂件包含以制表符\t分隔的三列,第一列是标签,第二列是事件类型class,第三列是文本。我们支持对同一个文本识别多种事件类型,仅需要在第二列中将不同的事件类型用;分隔开。对于一个事件类型class包含event_type以及role_list(r1,r2,……)表示为event_type:r1,r2,……,样例如下:
1 竞赛行为-夺冠:夺冠赛事,裁员人数 盖斯利在英国大奖赛首场练习赛中夺冠
测试模型
对于命名实体识别任务,代码如下:
python main.py \
--tables=predict_input_NER.tsv \
--outputs=predict_output_NER.tsv \
--input_schema=id:str:1,scheme:str:1,content:str:1 \
--output_schema=id,content,q_and_a \
--worker_gpu=4 \
--app_name=information_extraction \
--sequence_length=512 \
--weight_decay=0.0 \
--micro_batch_size=4 \
--checkpoint_dir=./information_extraction_model/ \
--data_threads=5 \
--user_defined_parameters='task=NER'
模型输出结果见predict_output_NER.tsv文件
对于关系抽取任务,代码如下:
python main.py \
--tables=predict_input_RE.tsv \
--outputs=predict_output_RE.tsv \
--input_schema=id:str:1,scheme:str:1,content:str:1 \
--output_schema=id,content,q_and_a \
--worker_gpu=4 \
--app_name=information_extraction \
--sequence_length=512 \
--weight_decay=0.0 \
--micro_batch_size=4 \
--checkpoint_dir=./information_extraction_model/ \
--data_threads=5 \
--user_defined_parameters='task=RE'
模型输出结果见predict_output_RE.tsv文件
对于事件抽取任务,代码如下:
python main.py \
--tables=predict_input_EE.tsv \
--outputs=predict_output_EE.tsv \
--input_schema=id:str:1,scheme:str:1,content:str:1 \
--output_schema=id,content,q_and_a \
--worker_gpu=4 \
--app_name=information_extraction \
--sequence_length=512 \
--weight_decay=0.0 \
--micro_batch_size=4 \
--checkpoint_dir=./information_extraction_model/ \
--data_threads=5 \
--user_defined_parameters='task=EE'
模型输出结果见predict_output_EE.tsv文件
在阿里云机器学习PAI-DSW上进行中文信息抽取
PAI-DSW(Data Science Workshop)是阿里云机器学习平台PAI开发的云上IDE,面向不同水平的开发者,提供了交互式的编程环境(文档)。在DSW Gallery中,提供了各种Notebook示例,方便用户轻松上手DSW,搭建各种机器学习应用。我们也在DSW Gallery中上架了使用PAI-Diffusion模型进行中文信息抽取的Sample Notebook,欢迎大家体验!
未来展望
在未来,我们计划进一步改进K-Global Pointer模型,敬请期待。我们将在EasyNLP框架中集成更多中⽂模型,覆盖各个常⻅中⽂领域,敬请期待。我们也将在EasyNLP框架中集成更多SOTA模型,来⽀持各种NLP和多模态任务。此外,阿⾥云机器学习PAI团队也在持续推进中⽂NLP和多模态模型的⾃研⼯作,欢迎⽤户持续关注我们,也欢迎加⼊我们的开源社区,共建中⽂NLP和多模态算法库!
Github地址:https://github.com/alibaba/EasyNLP
Reference
- Chengyu Wang, Minghui Qiu, Taolin Zhang, Tingting Liu, Lei Li, Jianing Wang, Ming Wang, Jun Huang, Wei Lin. EasyNLP: A Comprehensive and Easy-to-use Toolkit for Natural Language Processing. EMNLP 2022
- GlobalPointer:https://kexue.fm/archives/8373
阿里灵杰回顾
- 阿里灵杰:阿里云机器学习PAI开源中文NLP算法框架EasyNLP,助力NLP大模型落地
- 阿里灵杰:预训练知识度量比赛夺冠!阿里云PAI发布知识预训练工具
- 阿里灵杰:EasyNLP带你玩转CLIP图文检索
- 阿里灵杰:EasyNLP中文文图生成模型带你秒变艺术家
- 阿里灵杰:EasyNLP集成K-BERT算法,借助知识图谱实现更优Finetune
- 阿里灵杰:中文稀疏GPT大模型落地 — 通往低成本&高性能多任务通用自然语言理解的关键里程碑
- 阿里灵杰:EasyNLP玩转文本摘要(新闻标题)生成
- 阿里灵杰:跨模态学习能力再升级,EasyNLP电商文图检索效果刷新SOTA
- 阿里灵杰:EasyNLP带你实现中英文机器阅读理解
- 阿里灵杰:EasyNLP发布融合语言学和事实知识的中文预训练模型CKBERT
- 阿里灵杰:当大火的文图生成模型遇见知识图谱,AI画像趋近于真实世界
- 阿里灵杰:PAI-Diffusion模型来了!阿里云机器学习团队带您徜徉中文艺术海洋
- 阿里灵杰:阿里云PAI-Diffusion功能再升级,全链路支持模型调优,平均推理速度提升75%以上