【自监督论文阅读笔记】What Makes for Good Views for Contrastive Learning?
Abstract
数据的多个视图之间的对比学习最近在自监督表示学习领域取得了最先进的性能。尽管取得了成功,但对不同视角选择的影响研究较少。在本文中,我们使用理论和实证分析来 更好地理解视图选择的重要性,并认为我们应该减少视图之间的互信息 (MI),同时保持任务相关信息的完整性。为了验证这一假设,我们 设计了无监督和半监督框架,旨在通过减少 MI 来学习有效视图。我们还将数据增强视为减少 MI 的一种方式,并表明 增加数据增强 确实会导致 MI 降低 并 提高下游分类准确性。作为副产品,我们在 ImageNet 分类的无监督预训练中实现了新的最先进的准确度(73% top-1 线性读数与 ResNet-50)。
1 Introduction
常识是,你如何看待一个对象并不会改变它的身份。尽管如此,豪尔赫·路易斯·博尔赫斯 (Jorge Luis Borges) 想到了另一种选择。在他关于 Funes the Memorious 的短篇小说中,这个同名的主角开始烦恼 “一只三点十四分(从侧面看)的狗应该与三点十五分(从前面看)的狗同名”[8]。富内斯的诅咒是他拥有完美的记忆力,他看待世界的每一种新方式都揭示了一种与他以前所见的事物截然不同的知觉。他无法整理这些截然不同的经历。
幸运的是,我们大多数人都没有遭受这种诅咒。我们建立了身份的心理表征,以消除诸如一天中的时间和视角之类的麻烦。建立视图不变表示的能力是丰富的多视图学习研究的核心。这些方法寻求对一系列观察条件不变的世界表示。目前,一种流行的范例是对比多视图学习,其中 同一场景的两个视图在表示空间中汇集在一起,而不同场景的两个视图被推开。
这是一个自然而有力的想法,但它留下了一个重要的问题:“我们应该对哪些观察条件保持不变?”可能会走得太远:如果我们的任务是对一天中的时间进行分类,那么我们当然不应该使用不随时间变化的表示。或者,像 Funes 一样,我们走得还不够远:独立表示每个特定的视角会削弱我们跟踪狗在场景中移动的能力。
因此,我们寻求具有足够不变性的表示,以便 对无关紧要的变化具有鲁棒性,但又不会丢弃下游任务所需的信息。在对比学习中,“视图”的选择 是 控制表示捕获的信息的因素,因为 框架会产生侧重于视图之间共享信息的表示 [53]。视图通常是不同的感官信号,如照片和声音 [3 ],或不同的图像通道[66] 或 时间切片[69],但 也可能是同一数据张量的不同“增强”版本[10 SimCLR]。如果共享信息很小,那么学习到的表示可以丢弃更多关于输入的信息,并实现更大程度的对无用变量的不变性。我们如何才能 找到恰到好处的视角平衡,只分享我们需要的信息,不多也不少?
我们通过两种方式研究这个问题:
1) 我们证明了视图的最佳选择关键取决于下游任务。如果您了解任务,通常可以设计出有效的视图。
2) 我们凭经验证明,对于许多生成视图的常见方式,在下游性能方面有一个最佳点,视图之间的互信息 (MI) 既不太高也不太低。
我们的分析提出了一个“InfoMin 原则”。一组好的视角是 那些 共享在下游任务中表现良好所必需的最少信息的视角。这个想法 与最小充分统计的想法 [61] 和 信息瓶颈理论 [ 68, 2] 的想法有关,这些理论先前已经在表示学习文献中阐述过。这一原则还 补充了已经流行的“InfoMax 原则”[45],表示学习的目标是尽可能多地捕获有关刺激的信息。我们认为,最大化信息仅在信息与任务相关时才有用。除此之外,抛出有关有害变量信息的学习表示是更可取的,因为它可以提高泛化能力 并 降低下游任务的样本复杂性 [61]。
根据我们的发现,我们 还引入了一种半监督方法来学习视图,当下游任务已知时,这些视图对于学习良好的表示是有效的。我们还证明了 InfoMin 原则可以通过简单地寻求更强的数据增强来实际应用,以 进一步朝着最佳点减少互信息。这项工作在标准基准上实现了最先进的准确性。
我们的贡献包括:
• 证明对比表示学习的最佳视角是任务相关的。
• 根据经验在各种设置中发现 互信息估计和表示质量之间的U形关系。
• 一种新的半监督方法,用于学习针对给定任务的有效视图。
• 运用我们的理解,使用 ResNet-50 在 ImageNet 线性读出基准上实现 73.0% 的最先进准确度。
2 Related Work
最近,最具竞争力的无标签学习表征方法是 自监督对比表征学习 [53、32、73、66、62、10]。这些方法通过“对比”损失来学习表示,这种损失将不同的数据对分开,同时将相似的数据对放在一起,这种想法类似于 exemplar learning 范例学习 [21]。基于对比损失的模型明显优于其他方法 [80、38、54、66、20、52、19、24、78]。
对比学习中的主要设计选择之一是如何选择相似(或正)和不同(或负)对。在没有额外注释的情况下 生成正样本对的标准方法 是为每个数据点创建多个视图。例如:亮度和色度分解 [66],,随机增强图像两次[73, 10, 6, 28, 76, 63, 81, 83],使用不同时间步长的视频 [53, 82, 59, 27, 26]、同一图像的补丁[34、53、32]、多感官数据[50、12、55]、文本及其上下文[48、75、46、41],或学生和教师模型的表示[67 ]。负样本对可以是随机选择的图像/视频/文本。从理论上讲,我们可以认为 正对来自视图的联合分布 p(v1, v2) ,而 负对来自边际的乘积 p(v1)p(v2) 。开发对比学习目标 InfoNCE [53](或 Deep InfoMax [32])以 最大化两个视图 I(v1; v2) 之间互信息的下限。这种联系已在 [57、70] 中进一步讨论。
在对比表示学习中利用标记数据已被证明可以 将表示引导到任务相关的特征,从而提高性能 [77、31、36、72]。在这里,我们使用标记数据来学习更好的视图,但仍然仅使用未标记数据执行对比学习。未来的工作可以结合这些方法来利用标签进行视图学习和表示学习。此外,之前的工作[4] 研究了不同数量图像的增强效果。
(【4】A critical analysis of self-supervision, or what we can learn from a single image.)
3 什么是对比学习的最佳视图?
在本节中,我们首先介绍标准的多视图对比表示学习公式,然后研究什么是对比学习的最佳视图。
3.1 多视图对比学习
给定两个随机变量 v1 和 v2,对比学习的目标是 学习一个参数函数 来 区分 来自经验联合分布 p(v1)p(v2|v1) 的样本 和 来自边缘乘积 p(v1)p(v2) 的样本。生成的函数是 v1 和 v2 之间互信息的估计量,InfoNCE 损失 [53] 已被证明可以最大化 I(v1; v2) 的下限。在实践中,给定一个锚点 v1,i,InfoNCE 损失被优化为正确的正样本 v2,i ∼ p(v2|v1,i) 的得分高于一组 K 干扰项 v2,j ∼ p(v2):
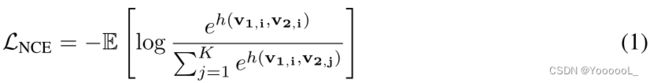
最小化此损失 等效地 最大化 I(v1; v2) 上的下限(又名 INCE(v1; v2)),即 I(v1; v2) ≥ log(K) − LNCE = INCE(v1; v2)。实际上,v1 和 v2 是数据 x 的两个视图,例如同一图像的不同增强 [73、6、28、11、10]、不同的图像通道 [66] 或视频和文本对 [65、47 , 42]。评分函数 h(·,·) 通常由两个编码器(f1 用于 v1 和 f2 用于 v2)组成,它们可能共享也可能不共享参数,具体取决于 v1 和 v2 是否来自同一域。结果表示为 z1 = f1(v1) 和 z2 = f2(v2)(见图 1a)。

定义 1.
(Sufficient Encoder 足够的编码器)当且仅当 I(v1; v2) = I(f1(v1); v2) 时,v1 的编码器 f1 在对比学习框架中是足够的。
直观地说,如果在编码过程中 v1 中关于 v2 的信息量是无损的,则编码器 f1 就足够了。换句话说,z1 保留了对比学习目标所需的所有信息。对称地,如果 I(v1; v2) = I(v1; f2(v2)),则 f2 就足够了。
定义 2.
(Minimal Sufficient Encoder 最小充分编码器)v1 的充分编码器 f1 是最小的,当且仅当 ![]() ,∀ f 是充分的。
,∀ f 是充分的。
在那些足够的编码器中,最小的编码器只提取对比任务的相关信息并丢弃其他不相关的信息。在视图 以 我们关心的所有信息 在它们之间共享 的方式 构建的情况下,这很有吸引力。
在对比框架中学习的表示通常用于单独的下游任务。为了表征哪些表示对下游任务有益,我们定义了表示的最优性。为了使符号简单,我们使用 z 来表示它可以是 z1 或 z2。
定义3.
(任务的最优表示)对于目标是从输入数据 x 预测语义标签 y 的任务 T,从 x 编码的最优表示 z* 是关于 y 的最小充分统计量。
这表示建立在 z* 之上的模型具有预测 y 所需的所有信息,就像访问 x 一样准确。此外,z*保持最小的复杂性,即除了关于 y 的信息外不包含其他信息,这使得它更具泛化性 [61]。我们建议读者参考 [61],以更深入地讨论最佳视觉表示和最小充分统计量。
3.2 信息捕获的三种机制
由于我们的表示 z1、z2 是根据我们的视角构建的,并在假设编码器最少的情况下通过对比目标学习,因此 v1 和 v2 之间共享的信息量和类型(即 I(v1; v2))决定了决定我们在下游任务上的表现。与信息瓶颈 [68] 一样,我们可以在我们的视角共享多少关于输入的信息与我们学习的表征在预测任务 y 方面的表现之间进行权衡。根据我们的视角是如何构建的,我们 可能会发现我们在丢弃相关变量的同时 保留了太多不相关的变量,从而导致信息平面上的性能不佳。或者,我们可以找到 最大化 I(v1; y) 和 I(v2; y)(关于任务标签包含多少信息)同时 最小化 I(v1; v2)(关于输入共享了多少信息,包括与任务相关和无关的信息)。
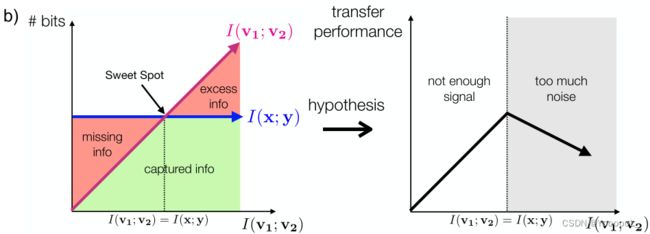
即使在这些最佳轨迹的情况下,我们也可以考虑三种性能机制,如图 1b 所示,并且之前在信息瓶颈文献 [68、2、23] 中已经讨论过:
1. 缺失信息:当 I(v1; v2) < I(x; y) 时,视图 会丢弃任务相关变量的信息,从而降低性能。
2. Sweet spot最优点:当 I(v1; y) = I(v2; y) = I(v1; v2) = I(x; y) 时,v1 和 v2 之间共享的唯一信息是任务相关的,并且有没有无关紧要的噪音。
3. 过量噪声:随着我们增加视图中共享的信息量超过 I(x; y),我们开始包含与下游任务无关的额外信息。这可能导致下游任务 [2, 60] 的泛化更差。
我们假设 性能最好的视图将接近最佳点:包含尽可能多的任务相关信息,同时尽可能多地丢弃输入中不相关的信息。更正式地说,以下 InfoMin 命题阐明了假设 我们事先知道特定的下游任务 T 哪些视图是最优的。证明在附录的 A.2 节中。
命题 3.1。
假设 f1 和 f2 是最小足够编码器。给定一个带有标签 y 的下游任务 T,从数据 x 创建的最佳视图是 (v1*, v2*) = arg minv1,v2 I(v1; v2),服从 I(v1; y) = I(v2; y) = I(x; y)。给定 v1*、v2*,通过对比学习学习的表示 z*1(或 z*2)对于 T是最优的(Def 3),这要归功于 f1 和 f2 的最小性和充分性。
与信息瓶颈不同,对于对比学习,我们通常无法访问预先指定下游任务的完全标记的训练集,因此评估训练时视图和表示中包含多少与任务相关的信息具有挑战性。相反,视图的构建通常由领域知识指导,领域知识在保留与任务相关的变量的同时改变输入。
What Makes for Good Views for Contrastive Learning - 知乎
3.4 数据增强以减少视图之间的相互信息
多个视图也可以通过以不同方式增强输入来生成。我们可以通过视图生成的角度来统一最近的几种对比学习方法:尽管在体系结构、目标和工程技巧方面存在差异,但所有最近的对比学习方法都创建了隐含遵循 InfoMin 原则的两个视图 v1 和 v2。下面,我们考虑了该框架中的几项近期工作:
InstDis [73] 和 MoCo [28]。
这两种方法通过对同一输入两次应用随机数据增强函数来创建视图:(1) 从经验分布 p(x) 中采样图像 X; (2) 从数据增强函数 T 的分布中抽取两个独立的变换 t1、t2; (3) 设 v1 = t1(X) 和 v2 = t2(X)。
CMC [66]。
CMC 进一步跨颜色通道分割图像,使得 ![]() 是 v1 的第一个颜色通道,v2cmc 是 v2 的最后两个通道。通过这种设计,理论上可以保证 I(vcmc1 ; vcmc2 ) ≤ I(v1; v2),并且我们观察到 CMC 的性能优于 InstDis。
是 v1 的第一个颜色通道,v2cmc 是 v2 的最后两个通道。通过这种设计,理论上可以保证 I(vcmc1 ; vcmc2 ) ≤ I(v1; v2),并且我们观察到 CMC 的性能优于 InstDis。
PIRL[49]。
PIRL 保持 v1pirl = v1,但使用 随机 JigSaw 洗牌 h 来转换另一个视图 v2 以获得 v2 pirl = h(v2)。类似地,我们有 I(vpirl 1 ; vpirl 2 ) ≤ I(v1; v2) ,因为 h(·) 引入了随机性。
SimCLR [10]。
尽管有其他工程技术和技巧,SimCLR 使用更强的增强类 T',这导致两个视图之间的互信息比 InstDis 更小。
CPC [53]。
与 上述在图像级别创建视图的方法 不同,CPC 从具有 强数据增强(例如 RA [15])的局部 patches 中获取视图 v1cpc 、 v2cpc ,从而导致更小的 I(v1cpc ; v2cpc )。与第 3.3 节一样,从不相交的patches 中裁剪视图也减少 I(v1cpc ; v2cpc )。
([15] Randaugment: Practical data augmentation with no separate search.)
此外,我们还分析了改变单个增强函数的大小参数是如何形成倒U形的。我们考虑 RandomResizedCrop 和 Color Jittering。对于前者,参数 c 设置低区域裁剪边界,c 越小表示增强越强。对于后者,采用参数 x 来控制强度。 ImageNet [16] 上的图如图 5 所示,我们在其中确定了 Color Jittering 的最佳位置为 1.0,RandomResizedCrop 的最佳位置为 0.2。

受InfoMin原则的启发,我们 提出了一组新的数据增强,称为 InfoMin Aug。结合PIRL [49]提出的JigSaw策略,我们的InfoMin Aug在使用ResNet-50的ImageNet线性读出基准测试中实现了73.0%的顶级精度,比SimCLR [10]高出近4%,如表1所示。此外,我们还发现,将我们的非监督预训练模型 转移到 PASCAL VOC目标检测 和 COCO实例分割 始终优于监督ImageNet预训练。更多细节和结果见附录。
无监督预训练的一个目标是学习对下游任务有益的可转移表示。过去几年许多视觉任务的快速进展可以归因于 从 ImageNet 上的监督预训练中 初始化的 微调模型 的范例。当转移到PASCAL VOC [22]和COCO [44]时,我们发现我们的 InfoMin预训练始终优于监督预训练以及其他非监督预训练方法。
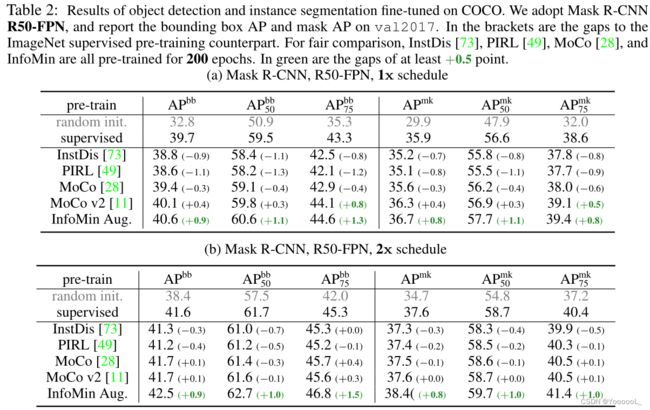
COCO 目标检测/分割。
特征归一化已被证明在微调过程中很重要 [28]。因此,我们使用同步 BN(SyncBN [56])微调主干并将 SyncBN 添加到新初始化的层(例如,FPN [43])。表 2 使用 Mask R-CNN [29] R50-FPN 管道报告了 COCO val2017 上的边界框 AP 和掩码 AP。所有结果都在 Detectron2 [71] 上报告。
我们尝试了具有各种主干的不同流行检测框架,扩展了微调时间表(例如,6x 时间表),并将在 ImageNet-1k 上训练的 InfoMin ResNeXt-152 [74] 与在 ImageNet-5k 上训练的监督式 ResNeXt-152 进行了比较(比 ImageNet-1k 大 6 倍)。在所有情况下,InfoMin 始终优于有监督的预训练。有关更详细的比较,请参阅 D 部分。
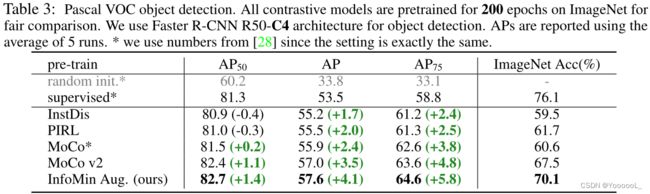
Pascal VOC 目标检测。
我们严格遵循 [28] 中介绍的设置。具体来说,我们使用具有 R50-C4 架构的 Faster R-CNN [58]。我们通过 24000 次迭代对所有层进行微调,每次迭代包含 16 张图像。结果报告在表 3 中。
4 对比学习的学习视图
手工设计的数据增强是一种有效的生成视图的方法,该视图具有减少的互信息和强大的图像传输性能。然而,随着对比学习应用于新领域,通过仔细构建数据增强策略 来生成视图 可能被证明是无效的。此外,有用的视图类型取决于下游任务。在这里,我们展示了最佳视图对简单玩具问题的任务依赖性,并提出了一种无监督和半监督学习方法来从数据中学习视图。
5 结论
我们已经在对比表征学习框架中描述了 给定任务的好视图 应该保留与任务相关的信息,同时最小化不相关的干扰,我们称之为 InfoMin原则。在此基础上,我们证明了最优视图在理论和实践上都是任务相关的。我们进一步提出了一种半倒置的方法来学习给定任务的有效视图。此外,我们从InfoMin的角度分析了最近方法中使用的数据增强,并进一步提出了一组新的数据增强,该组数据增强使用ResNet-50在ImageNet线性读出基准上实现了新的一流精度。