DenseNet论文笔记
DenseNet论文笔记
Densely Connected Convolutional Networks
Introduction中引用了Deep networks with stochastic depth,提到了resnet里很多层都学不到东西,贡献很少可以随机丢掉,解释了InceptionV4里的Scaling of the Residuals操作,Inception也是把新的缩小后再相加,不能把原来基础的feature改动太大,新的加一点。
Dense block
同一个block内的feature map尺寸不变。
每个block内的层和其之前的所有层相连,具体来说是之前所有层输出的feature maps全部做concat作为下一层输入。
每个L层的block内有(L+1)L/2个连接。
优势:通过建立前面所有层与后面层的密集连接,实现了特征在通道维度上的复用,不但减缓了梯度消失的现象,也使其可以在参数与计算量更少的情况下实现比ResNet更优的性能。
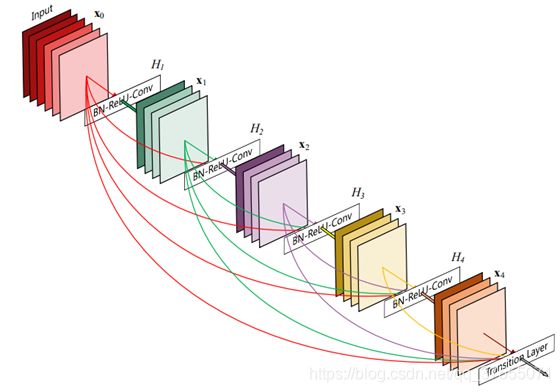
结构
通用DenseNet架构:

传统前馈网络: x l = H l ( x l − 1 ) x_{l}=H_{l}\left(x_{l-1}\right) xl=Hl(xl−1)
ResNet:
x l = H l ( x l − 1 ) + x l − 1 x_{l}=H_{l}\left(x_{l-1}\right)+x_{l-1} xl=Hl(xl−1)+xl−1
DenseNet:
x l = H l ( [ x 0 , x 1 , … , x l − 1 ] ) x_{l}=H_{l}\left(\left[x_{0}, x_{1}, \ldots, x_{l-1}\right]\right) xl=Hl([x0,x1,…,xl−1])
密集连通性:dense连接。
复合函数:指的是Hl为BN+RELU+3*3conv。
池化层:作者指出在两个dense block之间的两个层为transitional layer,具体为:BN+1* 1conv先降维+2* 2average pooling减小feature map大小,减少参数。减少冗余特征。
增长率k(growth rate):Dense block中,如果每个H_l 都额外新增 k 个特征图,那么第l层就有(l-1)k个特征图作为输入,其中 k0 表示输入层的通道数。DenseNet中k=12。k小一点效果好。
Bottleneck layers:名字应该是照resnet起的,Hl :BN-ReLU-Conv(1* 1)-BN-ReLU-Conv(3* 3),这个没压缩的版本叫DenseNet-B。
模型压缩:在transitional layer降维,if一个block输出m个特征图,让过渡层降维成θm个特征图(向下取整)。[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传θ<1的DenseNet为DenseNet-C,上述两个都有就是DenseNet-BC。实验中θ=0.5。
实现细节:在除了ImageNet外的所有数据集上,实验中使用的DenseNet都有三个dense block,每一个block都有相同的层数。在进入第一个dense block之前,输入图像先经过了16个(DenseNet-BC中是两倍的增长速率)卷积。对于3x3的卷积层,使用一个像素的零填充来保证特征图尺寸不变。在两个dense block之间的过渡层中,我们在2x2的平均池化层之后增加了1x1的卷积。在最后一个dense block之后,使用全局平均池化和softmax分类器。三个dense block的特征图的尺寸分别是32x32,16x16,8x8。
对于在ImageNet数据集上的实验,我们使用4个dense block的DenseNet-BC结构,图片的输入是224x224。最开始的卷积层有 2k(64)个卷积,卷积核是7x7,步长是2;其余所有层的特征图都设为 k 。
针对ImageNet设计的DenseNet(k=32):

实验结果:
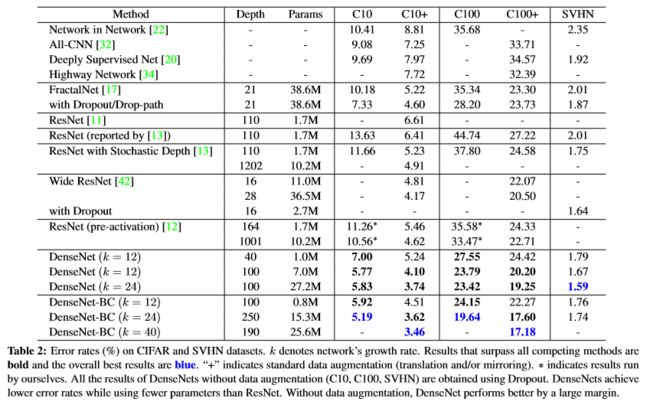
准确率:对于SVHN数据集,DenseNet-BC的结果并没有DenseNet(k=24)的效果好,作者认为原因主要是SVHN这个数据集相对简单,更深的模型容易过拟合。
Capacity:可以看出,随着L和K变大,DenseNet效果变好。
Overfitting:DenseNet不容易过拟合,可能是因为bottleneck结构和模型压缩有正则化作用。
下图是DenseNet-BC和ResNet在ImageNet数据集上的对比,左边那个图是参数复杂度和错误率的对比,可以在相同错误率下看参数复杂度,也可以在相同参数复杂度下看错误率,提升还是很明显的。右边是flops和错误率的对比,同样有效果。
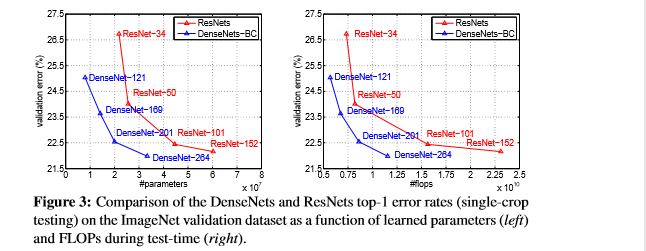
左边的图表示不同类型DenseNet的参数和error对比。中间的图表示DenseNet-BC和ResNet在参数和error的对比,相同error下,DenseNet-BC的参数复杂度要小很多,错误率也低。右边的图也是表达DenseNet-BC-100只需要很少的参数就能达到和ResNet-1001相同的结果。
这里的实验直接把ResNet里的block改成DenseNet的block,超参数用的是ResNet的

Discussion
Model compactness
reuse和压缩模型
Implicit Deep Supervision
类似DSN,DSN每层接了分类器强制中间层学有区分度的feature,densenet的分类器算是和所有层相连的,但是densenet的loss function在所有层共享。
Stochastic 和 deterministic connection
随机丢resnet层的输出和把每层都连接起来,有概率可以造成临近两个层的直接相连。densenet是直接连起来。
Feature Reuse

上面的热力图算的是 average(absolute)weight assigned,可以理解为对应层的feature map的复用率,横轴是block中的层,纵轴越红则复用率越高,黑框加粗的是两个transitional layers和classification layer。顶上第一行是block的输入的feature map。
怎么看:例如block1的第12层,纵轴有12个块分别代表12个不同层的feature map,底下的偏红说明底层的feature map复用的多。
observations:
-
所有层的feature map在后面都有被用到。就算是很早的层在后面的层也有用,只是不大。
-
即使是Transition layer也会使用到之前Denseblock中所有层的特征。
-
第2-3个Denseblock中的层对之前Transition layer利用率很低,说明transition layer输出大量冗余特征.这也为DenseNet-BC提供了证据支持,既Compression的必要性。
-
最后的分类层虽然使用了之前Denseblock中的多层信息,但更偏向于使用最后几个feature map的特征,说明在网络的最后几层,可能产生某些high-level的特征。
参考:https://www.jianshu.com/p/0b8fc900abef