SRGAN论文学习笔记
《Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network》是Christian Ledig等人于2017年发表于CVPR上的又一篇SR重建的论文,将生成对抗网络(GAN)用于图像超分辨率重建,在感知质量方面取得了巨大的进步,重建图像放大四倍后依然能够呈现清晰地纹理细节。
基于监督学习的SR算法的不足之处:
通过最小化重建后的HR图像与groundtruth图像之间的均方误差(MSE)来达到训练的目的,同时能够使峰值信噪比(PSNR)最大化,然而MSE(和PSNR)捕获感知相关差异(如高纹理细节)的能力非常有限,生成的图像过于平滑,高PSNR并不一定能反映能好的感知结果。

该文章的主要贡献:
1、设计16块深度ResNet(SRResNet)结构,在高尺度(×4)图像上具有最优的PSNR和SSIM。
2、提出SRGAN,这是基于GAN网络优化的一种新的感知损失,将基于MSE的内容损失替换为在VGG网络特征映射上计算的损失。
3、对来自三个公共基准数据集的图像进行了广泛的平均意见得分(MOS)测试,确认SRGAN是最先进的超分网络,在具有较高放大因子(×4)的图片上依然呈现出逼真的SR图像。
SRGAN网络结构:
生成器:![]() ,用于估计给定LR图像对应的HR图像,生成器由前馈CNN网络
,用于估计给定LR图像对应的HR图像,生成器由前馈CNN网络![]() 构成;
构成;
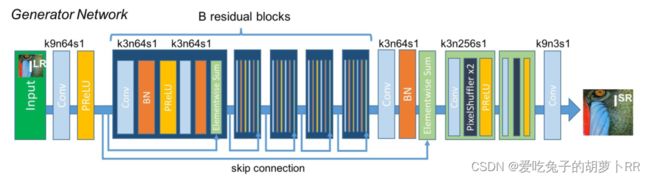
如上图所示,生成器由B个相同结构的残差块组成,每个残差块由两个如下单元组成:(kxnysz:卷积核大小为x×x,通道数为y,卷积步长为z)
- 3×3×64的卷积层
- batch-normalization层
- PReLU激活单元
- 3×3×64的卷积层
- batch-normalization层
- 跳跃连接模块
同时使用局部和全局跳跃连接来扩大感受野,在输出之前使用亚像素卷积层来进一步提高图像的分辨率。使用MSE作为目标函数的生成器网络定义为SRResnet。
判别器:![]() ,用于将重建后的高分辨率图像与原始HRlabels区分开,判别器网络表示为
,用于将重建后的高分辨率图像与原始HRlabels区分开,判别器网络表示为![]() 。
。

判别器网络包含8个卷积层,同时包含BN层与LeakyReLU激活单元(其中α=0.2),滤波器的通道数不断增加(从64增加到512),同时设置卷积步长以降低图像的分辨率。并在之后使用两个密集连接模块,密集连接模块可以融合低级和高级特征,为重建高质量细节提供更丰富的信息。最后在网络输出前使用sigmoid函数进行二分类。
感知损失函数:
![]()
其中![]() 表示内容损失,
表示内容损失,![]() 表示对抗性损失。
表示对抗性损失。
1、内容损失:

其中![]() 表示第j个卷积层(包含激活层后),第i个最大池化层前的特征图;
表示第j个卷积层(包含激活层后),第i个最大池化层前的特征图;![]() 和
和![]() 表示特征图的维度。
表示特征图的维度。
2、对抗损失
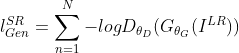
其中![]() 是重建图像
是重建图像![]() 是自然HR图像的概率。
是自然HR图像的概率。
通过训练生成器和鉴别器网络参数使得网络最优化:
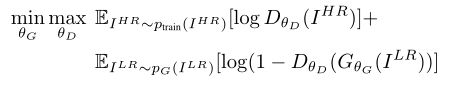
训练过程:
数据集:Set5、Set14和BSD100。
参数设置:SRResnet使用Adam优化器,β1=0.9,学习率为 ,迭代次数为
,迭代次数为 ;SRGAN以的学习率进行
;SRGAN以的学习率进行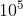 次迭代,以
次迭代,以 的学习率进行次迭代。生成器中B=16。
的学习率进行次迭代。生成器中B=16。
评价指标:使用平均意见得分(MOS),通过人工打分(1-5分)的方式对图像的感知质量进行评估。
网络实现(Pytorch):
SRResnet:
class SRResNet(nn.Module):
"""
SRResNet模型
"""
def __init__(self, large_kernel_size=9, small_kernel_size=3, n_channels=64, n_blocks=16, scaling_factor=4):
"""
:参数 large_kernel_size: 第一层卷积和最后一层卷积核大小
:参数 small_kernel_size: 中间层卷积核大小
:参数 n_channels: 中间层通道数
:参数 n_blocks: 残差模块数
:参数 scaling_factor: 放大比例
"""
super(SRResNet, self).__init__()
# 放大比例必须为 2、 4 或 8
scaling_factor = int(scaling_factor)
assert scaling_factor in {2, 4, 8}, "放大比例必须为 2、 4 或 8!"
# 第一个卷积块
self.conv_block1 = ConvolutionalBlock(in_channels=3, out_channels=n_channels, kernel_size=large_kernel_size,
batch_norm=False, activation='PReLu')
# 一系列残差模块, 每个残差模块包含一个跳连接
self.residual_blocks = nn.Sequential(
*[ResidualBlock(kernel_size=small_kernel_size, n_channels=n_channels) for i in range(n_blocks)])
# 第二个卷积块
self.conv_block2 = ConvolutionalBlock(in_channels=n_channels, out_channels=n_channels,
kernel_size=small_kernel_size,
batch_norm=True, activation=None)
# 放大通过子像素卷积模块实现, 每个模块放大两倍
n_subpixel_convolution_blocks = int(math.log2(scaling_factor))
self.subpixel_convolutional_blocks = nn.Sequential(
*[SubPixelConvolutionalBlock(kernel_size=small_kernel_size, n_channels=n_channels, scaling_factor=2) for i
in range(n_subpixel_convolution_blocks)])
# 最后一个卷积模块
self.conv_block3 = ConvolutionalBlock(in_channels=n_channels, out_channels=3, kernel_size=large_kernel_size,
batch_norm=False, activation='Tanh')
def forward(self, lr_imgs):
"""
前向传播.
:参数 lr_imgs: 低分辨率输入图像集, 张量表示,大小为 (N, 3, w, h)
:返回: 高分辨率输出图像集, 张量表示, 大小为 (N, 3, w * scaling factor, h * scaling factor)
"""
output = self.conv_block1(lr_imgs) # (16, 3, 24, 24)
residual = output # (16, 64, 24, 24)
output = self.residual_blocks(output) # (16, 64, 24, 24)
output = self.conv_block2(output) # (16, 64, 24, 24)
output = output + residual # (16, 64, 24, 24)
output = self.subpixel_convolutional_blocks(output) # (16, 64, 24 * 4, 24 * 4)
sr_imgs = self.conv_block3(output) # (16, 3, 24 * 4, 24 * 4)
return sr_imgs生成器网络:(与SRResnet网络一致)
class Generator(nn.Module):
"""
生成器模型,其结构与SRResNet完全一致.
"""
def __init__(self, large_kernel_size=9, small_kernel_size=3, n_channels=64, n_blocks=16, scaling_factor=4):
"""
参数 large_kernel_size:第一层和最后一层卷积核大小
参数 small_kernel_size:中间层卷积核大小
参数 n_channels:中间层卷积通道数
参数 n_blocks: 残差模块数量
参数 scaling_factor: 放大比例
"""
super(Generator, self).__init__()
self.net = SRResNet(large_kernel_size=large_kernel_size, small_kernel_size=small_kernel_size,
n_channels=n_channels, n_blocks=n_blocks, scaling_factor=scaling_factor)
def forward(self, lr_imgs):
"""
前向传播.
参数 lr_imgs: 低精度图像 (N, 3, w, h)
返回: 超分重建图像 (N, 3, w * scaling factor, h * scaling factor)
"""
sr_imgs = self.net(lr_imgs) # (N, n_channels, w * scaling factor, h * scaling factor)
return sr_imgs判别器网络:
class Discriminator(nn.Module):
"""
SRGAN判别器
"""
def __init__(self, kernel_size=3, n_channels=64, n_blocks=8, fc_size=1024):
"""
参数 kernel_size: 所有卷积层的核大小
参数 n_channels: 初始卷积层输出通道数, 后面每隔一个卷积层通道数翻倍
参数 n_blocks: 卷积块数量
参数 fc_size: 全连接层连接数
"""
super(Discriminator, self).__init__()
in_channels = 3
# 卷积系列,参照论文SRGAN进行设计
conv_blocks = list()
for i in range(n_blocks):
out_channels = (n_channels if i is 0 else in_channels * 2) if i % 2 is 0 else in_channels
conv_blocks.append(
ConvolutionalBlock(in_channels=in_channels, out_channels=out_channels, kernel_size=kernel_size,
stride=1 if i % 2 is 0 else 2, batch_norm=i is not 0, activation='LeakyReLu'))
in_channels = out_channels
self.conv_blocks = nn.Sequential(*conv_blocks)
# 固定输出大小
self.adaptive_pool = nn.AdaptiveAvgPool2d((6, 6))
self.fc1 = nn.Linear(out_channels * 6 * 6, fc_size)
self.leaky_relu = nn.LeakyReLU(0.2)
self.fc2 = nn.Linear(1024, 1)
# 最后不需要添加sigmoid层,因为PyTorch的nn.BCEWithLogitsLoss()已经包含了这个步骤
def forward(self, imgs):
"""
前向传播.
参数 imgs: 用于作判别的原始高清图或超分重建图,张量表示,大小为(N, 3, w * scaling factor, h * scaling factor)
返回: 一个评分值, 用于判断一副图像是否是高清图, 张量表示,大小为 (N)
"""
batch_size = imgs.size(0)
output = self.conv_blocks(imgs)
output = self.adaptive_pool(output)
output = self.fc1(output.view(batch_size, -1))
output = self.leaky_relu(output)
logit = self.fc2(output)
return logit实验结果:

PS:GAN网络损失函数
交叉熵损失函数:![]()
生成网络的损失函数:![]()
其中G表示生成网络,D表示判别网络,x表示输入数据。D(G(x))是对生成数据的判断概率,代表判断结果与1的距离。生成网络想取得良好的效果,就要做到让判别器将生成数据判别为真数据,即D(G(x))与1的距离越小越好。
判别网络的损失函数:![]()
其中x表示真实数据,H(1,D(x))代表真实数据与1的距离,H(0,D(G(x)))代表生成数据与0的距离。识别网络要想取得良好的效果,就要做到真实数据就是真实数据,生成数据就是虚假数据,即真实数据与1的距离小,生成数据与0的距离小。