shell脚本编程之循环
内容预知
1.循环的定义
2. for循环
2.1 for循环的基本用法
运用演示1:列表打印
运用演示二:分类打印
运用演示三:累加求和
2.2 for循环读取文件作为循环条件
运用演示
2.3 for循环的多线程运用
运用演示
2.4 for读取文件循环之改变分隔符
缺陷演示
解决缺陷的方案
IFS被改变,忘记备份的解决方案
3. while循环
3.1 while的取值循环用法
运用演示二:定义死循环,执行结果为真是才会退出
3.2 while读取文件作为循环条件用法
语句格式1:重定向输入读取
语句格式二: 管道传输文件
4.until循环
5. 知识补充:echo的用法和字符串截取
5.1 echo的的常用选项
5.2 截取字符串
5.2.1 通用截取方法
5. 2.2 逆向(去除末尾单个字符组合)截取方法
5.2.3 逆向(去除 除了首字符组合之外的所有字符)截取方法
5.2.4 正向(去除首个单字符组合)截取方法
5.2.5 正向(去除除了末尾字符组合外的所有字符)截取方法
5.2.6 统计字符串的长度
echo ${#变量} 注意:{}里面的表达式之间不要有空格
总结
1.循环的定义
循环是指依赖某一个条件的限制,对一串逻辑性代码,进行反复性的操作,直到能够满足预期结果进行结束循环。如果没有预期结果,不间断执行,我们称之为“死循环” 。与循环有关的三个专业性名词:遍历,迭代,递归
- 遍历(traversal) - 按规则访问非线性结构中的每一项。
- 迭代(iterate) - 按顺序访问线性结构中的每一项。
- 递归(recursion) - 在函数内调用自身, 将复杂情况逐步转化成基本情况。
本文将介绍三种常用的循环,分别为 for ,while和until
2. for循环
读取预设置的不同变量值进行循环执行语句,直到不符合设置的标准后跳出循环。是一种典型的遍历循环
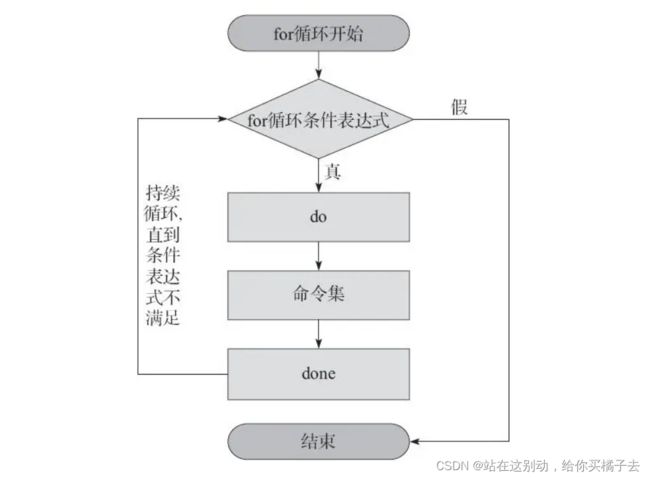
2.1 for循环的基本用法
语句格式:
for 变量名 in 取值列表
do
命令序列
done
运用演示1:列表打印
需求: 打印一份一到十的数字列表
#!/bin/bash
for i in {1..10}
do
echo $i
done

结果:

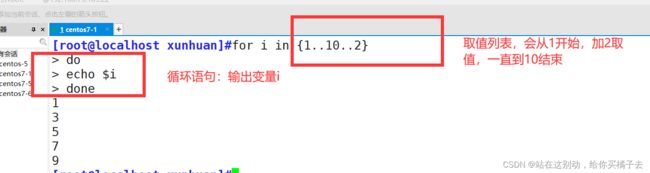
运用演示二:分类打印
需求:打印一份 0-10以内的奇数列表
[root@localhost xunhuan]#for i in {1..10..2}
> do
> echo $i
> done
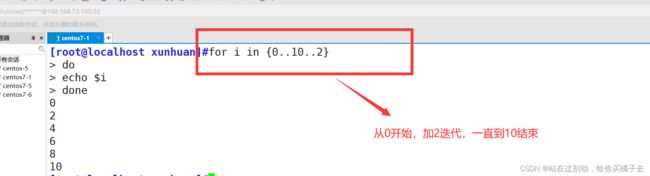
需求二:打印一份0-10以内的偶数列表
[root@localhost xunhuan]#for i in {0..10..2}
> do
> echo $i
> done
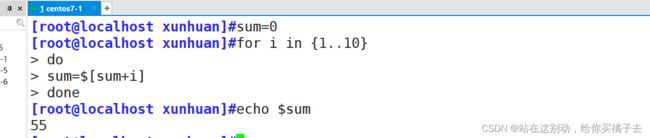
运用演示三:累加求和
需求:求从1加到10的和
[root@localhost xunhuan]#sum=0
[root@localhost xunhuan]#for i in {1..10}
> do
> sum=$[sum+i]
> done
[root@localhost xunhuan]#echo $sum
55
2.2 for循环读取文件作为循环条件
语句格式:
for 变量 in $( cat 文件的绝对路径 )
do
执行语句
done
运用演示
需求:建立一个用户文件,将用户名存放在此文件中,利用for循环判断该用户是否已经被建立
第一步:
[root@localhost xunhuan]#vim users.txt

第二步:编写相关的脚本
[root@localhost xunhuan]#vim testuser.sh
#!/bin/bash
for i in $( cat /xunhuan/users.txt )
do
id $i &>/dev/null
if [ $? -eq 0 ];then
echo "$i 用户存在!"
else
echo "$i 用户不存在!"
fi
done

结果:

2.3 for循环的多线程运用
linux系统是由c语言编写,具有很多c语言的特性,默认情况下是单线程执行语句命令,但是遇到重复量较大的循环语句,执行时间过长,我们可以调动多线程(多线程的速度取决硬件cpu的性能)执行,可以快速得到想要的结果
语句格式:
for 变量名 in 取值列表
do
{
循环语句
}&
done
wait
运用演示
需求 :要求在短暂时间内快速得到192.168.73.0/24 网段中所有主机是否在在线,并且无论是否在线都将其结果保存在一个文件中,可供浏览
[root@localhost xunhuan]#vim ping.sh
#!
for host in {1..254}
do
{
ping -c 3 -w 2 192.168.73.$host &>/dev/null
if [ $? -eq 0 ];then
echo "主机192.168.73.$host 存活!" >>/xunhuan/host_ip
else
echo "主机192.168.73.$host 关闭状态!" >>/xunhuan/host_ip
fi
}&
done
wait
cat /xunhuan/host_ip
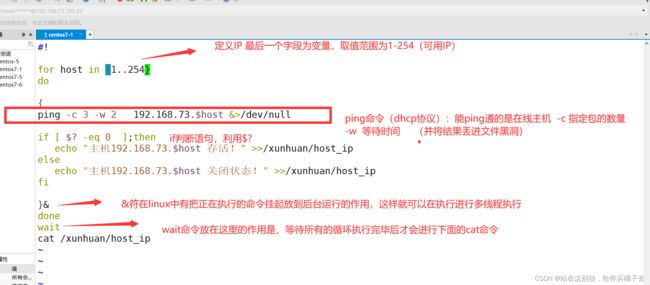
结果演示:
2.4 for读取文件循环之改变分隔符
for循环读取文件是按照分隔符IFS 来读取文件中的数据
IFS(Internal Filed Separator,内部域分隔符)是一个set变量(shell变量),默认是空格、Tab键、换行符,使用for循环读取值列表时,会根据IFS的值判断列表中值的个数。
缺陷演示
首先写一个for循环遍历文件users.txt(刚才测试的文件),进行遍历展示
[root@localhost xunhuan]#vim test.sh
#!/bin/bash
for line in $( cat /xunhuan/users.txt )
do
echo $line
done

然后再文件中插入一些信息数据
[root@localhost xunhuan]#vim users.txt
zhangsan
lisi
liuliu
wangwang
12312
34555
wangwu
[root@localhost xunhuan]#vim users.txt
zhangsan
lisi
liuliu
wangwang
12312
34555
wangwu
测试:

改变对users.txt 文件进行一个小变动

再执行脚本测试:

解决缺陷的方案
改变分隔符,让读行方式发生改变(但是一定要先备份,再改变,执行后再恢复分隔符)
[root@localhost xunhuan]#vim test.sh
#!/bin/bash
IFS_BAK=$IFS
IFS=$'\n'
for line in $( cat /xunhuan/users.txt )
do
echo $line
done
IFS=$IFS_BAK
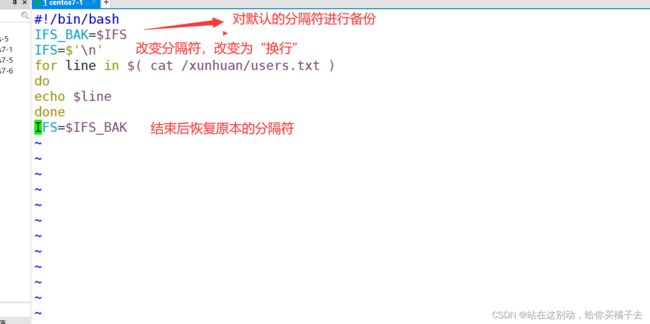
结果测试:

IFS被改变,忘记备份的解决方案
万一不小心把IFS值设置错了,也可通过如下赋值方式使其恢复到默认值
IFS=$' \t\n'
3. while循环
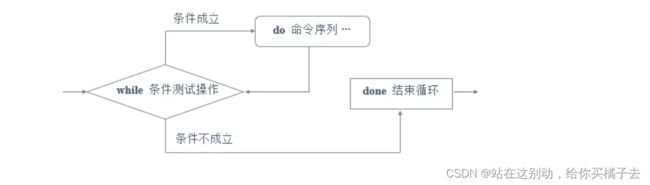
while循环是一种初始只用设置条件的循环语句,再命令执行过程中用变量计数来完成迭代,直到非循环条件才会跳出循环,也是一种遍历性质的循环
3.1 while的取值循环用法
语句格式:
while 条件测试操作
do
命令序列
done
运用演示一:打印列表
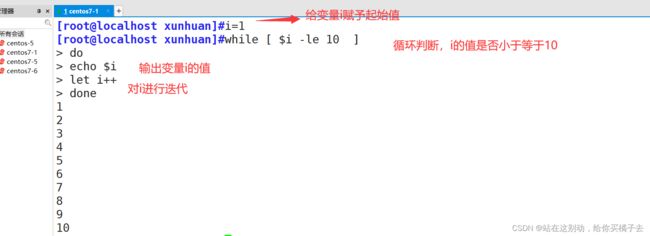
需求:打印1到10的数字列表
[root@localhost xunhuan]#i=1
[root@localhost xunhuan]#while [ $i -le 10 ]
> do
> echo $i
> let i++
> done
运用演示二:定义死循环,执行结果为真是才会退出
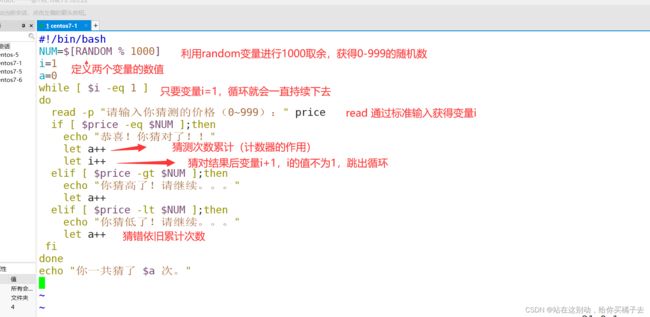
需求: 创建一个随机数为0-999 ;让用户通过键盘输入进行猜测,猜测错误给与提示并且继续持续让用户猜测,一直到猜出正确结果才会给予提示并且退出循环,并且计算用户用了多次猜中结果
[root@localhost xunhuan]#vim guess.sh
#!/bin/bash
NUM=$[RANDOM % 1000]
i=1
a=0
while [ $i -eq 1 ]
do
read -p "请输入你猜测的价格(0~999):" price
if [ $price -eq $NUM ];then
echo "恭喜!你猜对了!!"
let a++
let i++
elif [ $price -gt $NUM ];then
echo "你猜高了!请继续。。。"
let a++
elif [ $price -lt $NUM ];then
echo "你猜低了!请继续。。。"
let a++
fi
done
echo "你一共猜了 $a 次。"
结果执行:

3.2 while读取文件作为循环条件用法
while不同于for读取文件的是,while必须借助read来进行读取,但是read读文件(每次只能读取一行内容,如果read识别到了换行符,就结束这一次的读取)
语句格式1:重定向输入读取
while read 变量
do
循环执行语句
done < 文件的绝对路径
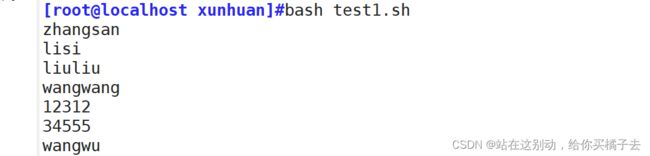
运用演示:读取user.text文件循环输出内容
[root@localhost xunhuan]#vim test1.sh
#!/bin/bash
while read line
do
echo $line
done

结果:
语句格式二: 管道传输文件
格式:
cat 文件路径 | while read line
do
循环执行语句
done
运用演示:读取user.text文件循环输出内容
[root@localhost xunhuan]#vim test2.sh
#!/bin/bash
cat /xunhuan/users.txt|while read line
do
echo $line
done
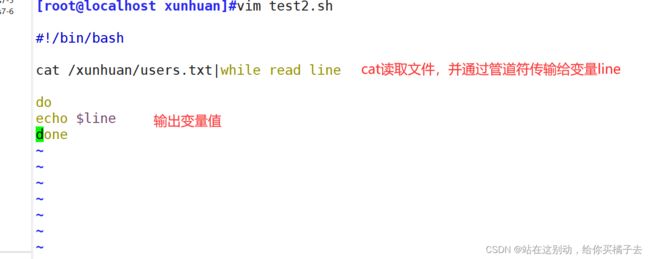
结果:

4.until循环
until循环与for,while循环不同的是,until循环是只要条件不符合就会一直循环,直到条件符合后才会退出循环
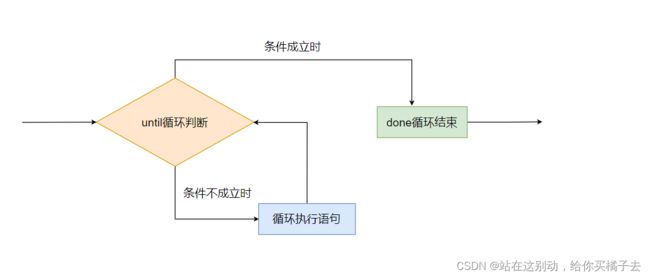
语句格式:
until 条件测试操作
do
命令序列
done
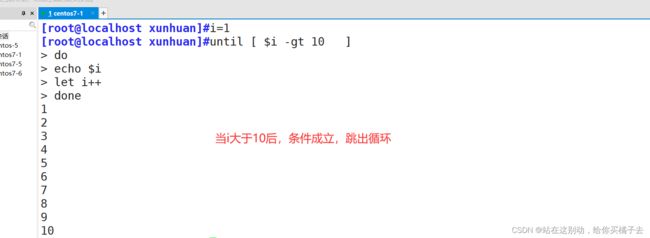
运用演示:打印数字1-10
[root@localhost xunhuan]#until [ $i -gt 10 ]
> do
> echo $i
> let i++
> done
5. 知识补充:echo的用法和字符串截取
5.1 echo的的常用选项
-n:不换行输出
-e 输出转义字符
"\"本身还存在一些特殊作用
(1)配合一些普通字符实现一些特殊的效果
转义字符的类型:
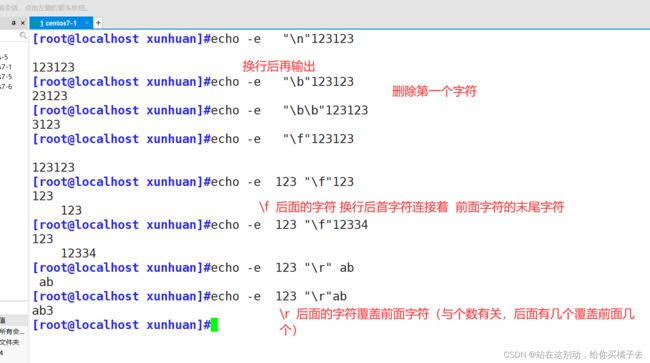
\b
转义后相当于退格键(backspace)但前提是"\b"后面存在字符; “\b"表示删除前一一个字符,"\b\b" 表示删除前两个字符。
\c
不换行输出,在"\c"后面不存在字符的情况下,作用相当于echo -n;但是当"\c"后面仍然存在字符时,"\c"后面的字符将不会被输出。
\n
换行,被输出的字符从"\n"处开始另起一行。
\f
换行,但是换行后的新行的开头位置连接着上一行的行尾;
\v
与\f相同;
\t
转以后表示插入tab,即横向制表符;
\r
光标移至行首,但不换行,相当于使用"\r"以后的字符覆盖"\r"之前同等长度的字符:但是当"\r"后面不存在任何字符时,"\r"前面的字符不会被覆盖
\\
表示插入""本身;
(2)可以把一些特殊字符转化为普通字符的含义(eg: $ ! . * & 等等)

5.2 截取字符串
5.2.1 通用截取方法
格式 echo { 变量 : 起始字符的位置 :要截取的个数(从起始位置开始计算) }

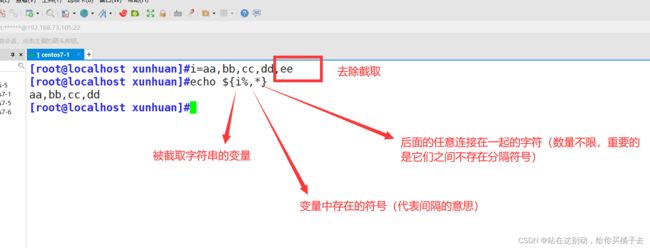
5. 2.2 逆向(去除末尾单个字符组合)截取方法
格式: echo $ { 变量%符号*} 注意:{}里面的表达式之间不要有空格
5.2.3 逆向(去除 除了首字符组合之外的所有字符)截取方法
格式: echo $ { 变量%%符号*} 注意:{}里面的表达式之间不要有空格
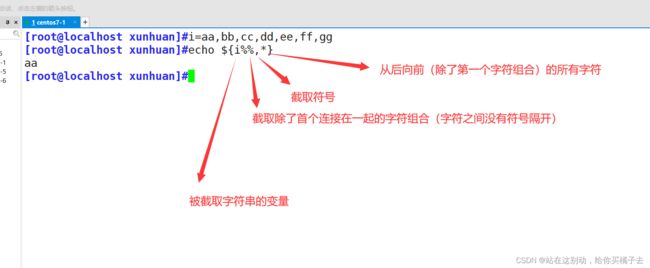
其他符号也能实现:

5.2.4 正向(去除首个单字符组合)截取方法
格式: echo $ { 变量#*符号} 注意:{}里面的表达式之间不要有空格
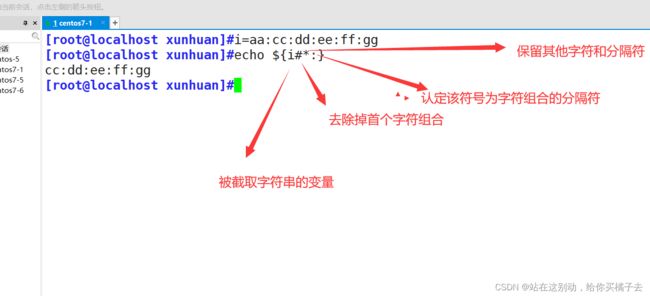
5.2.5 正向(去除除了末尾字符组合外的所有字符)截取方法
格式: echo $ { 变量##*符号} 注意:{}里面的表达式之间不要有空格

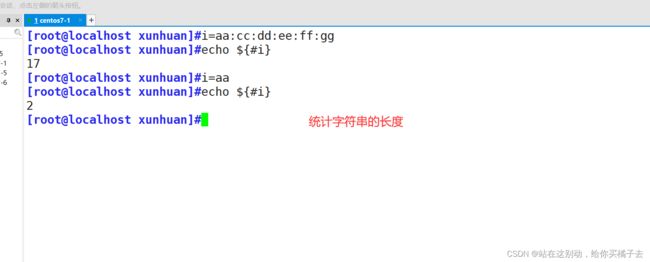
5.2.6 统计字符串的长度
格式:
echo ${#变量} 注意:{}里面的表达式之间不要有空格
总结
1. 掌握好三种循环的用法(特别是until和前两种循环对于条件判断是相反的)
2.for循环读取文件时,如果遇到未按照默认分隔符隔开的文件,可以通过修改分隔符来实现正常读取(但是先备份分隔符的默认值,再进行修改,最后进行还原)
3.掌握字符串的截取方式,可以帮助我们完成截取一些特殊文件的想要的截取结果
4.对echo的特殊用法也要多加以了解,可以高效的输出我们想要的内容