计算机视觉知识点之RCNN/Fast RCNN/Faster RCNN
Rcnn
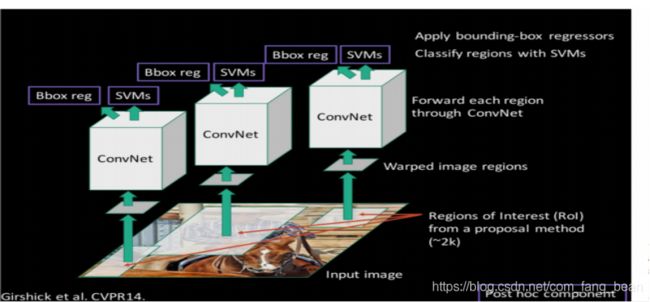
第一步:输入图像,采用Selective Search 从原始图片中提取2000个左右区域候选框
第二步:划分区域提案,进行归一化:将所有候选框变为固定大小的(227*227)区域,对每个候选区域,使用深度网络提取特征
第三步:CNN网络提取特征 送入每一类的SVM 分类器,判别是否属于该类
第四步:NMS(非极大值抑制)区域边框,采用DPM精修边框的位置

先模型输入为一张图片,然后在图片上提出了约2000个待检测区域,然后这2000个待检测区域一个一个地(串联方式)通过卷积神经网络提取特征,然后这些被提取的特征通过一个支持向量机(SVM)进行分类,得到物体的类别,并通过一个bounding box regression调整目标包围框的大小。
第一步:候选区域生成
RCNN开创性的提出了候选区(Region Proposals)的方法,先从图片中搜索出一些可能存在对象的候选区(Selective Search),使用了Selective Search方法从一张图像生成约2000-3000个候选区域。
基本思路如下:
- 使用一种过分割手段,将图像分割成小区域
- 查看现有小区域,合并可能性最高的两个区域。重复直到整张图像合并成一个区域位置
- 输出所有曾经存在过的区域,所谓候选区域
Selective research for object recognition(选择性搜索)
1.适应不同尺度:通过改变窗口的大小来适应物体的不同尺度,算法采用图像分割(image segmentation)和层次算法(Hierarchical Algorithm)
2.通过使用颜色、纹理、大小等多种分割策略对于分割好的区域进行合并
第二步:特征提取
1:预处理
使用深度网络提取特征之前,首先把候选区域归一化成同一尺寸227×227。 利用AlexNet网络对每个候选区域提取4096维特征向量(第7层的输出)。首先将候选区域转化为227×227分辨率的RGB图像,以便于可以作为CNN的输入。然后图像通过五个卷积层和两个全连接层向前传播来提取特征。
此处有一些细节可做变化:外扩的尺寸大小,形变时是否保持原比例,对框外区域直接截取还是补灰。会轻微影响性能。
2:预训练 训练过程是分阶段的,CNN与SVM分别单独进行训练。
1网络结构
上面AlexNet网络提取的特征为4096维,之后送入五个卷积层和两个全连接层进行分类。 学习率0.01。
2训练数据
使用ILVCR 2012的全部数据进行训练,输入一张图片,输出1000维的类别标号。
3调优训练
1网络结构
作者先将完整的AlexNet在ImageNet上进行预训练, 得到一个分类模型。为了使网络适应新任务(检测),将网络的最后一层修改为N + 1维向量(N表示类别数,1表示背景),替换原来的1000维向量(AlexNet原有类别),换成4096->21的全连接网络。
每一个batch包含32个正样本(属于20类)和96个背景。
正样本:将所有候选区域与检测框真值之间IoU ≥0.5的区域作为正样本(某一类别), 负样本:其余的作为负样本(背景)。
标定类别核背景:考察一个候选框和当前图像上所有标定框重叠面积最大的一个。如果重叠比例大于0.5,则认为此候选框为此标定的类别;否则认为此候选框为背景。
如果某个候选区域不是背景,则选择与之IOU最大的那个检测框真值的类别作为此候选区域的类别。以0.001(初始学习率的1/10)的学习率开始SGD,这样可以在不破坏初始化的情况下进行微调。在每个SGD迭代中,统一采样32个正样本(所有类别)和96个负样本,以构建大小为128的小批量。并将最后一层参数初始化伪随机数,其他层的参数为预训练得到的值。
2训练数据
使用PASCAL VOC 2007的训练集,输入一张图片,输出21维的类别标号,表示20类+背景。
第三步:类别判断
1:分类器
对每一类目标,使用一个线性SVM二类分类器进行判别。
输入: 为深度网络输出的4096维特征,
输出: 是否属于此类。
由于负样本很多,使用hard negative mining方法。
正样本
本类的真值标定框。
负样本
考察每一个候选框,如果和本类所有标定框的重叠都小于0.3,认定其为负样本
2:训练SVM分类器。
每个类别构建一个SVM分类器。以检测框真值作为正样本,以候选区域与检测框真值之间IoU <0.3的区域作为负样本,其余候选区域直接抛弃掉,不作为训练数据。以CNN网络提取的4096维特征作为SVM分类器训练数据的特征向量。
位置精修
目标检测问题的衡量标准是重叠面积:许多看似准确的检测结果,往往因为候选框不够准确,重叠面积很小。故需要一个位置精修步骤。
回归器
对每一类目标,使用一个线性脊回归器进行精修。正则项λ=10000λ=10000。
输入为深度网络pool5层的4096维特征,输出为xy方向的缩放和平移。
训练样本
判定为本类的候选框中,和真值重叠面积大于0.6的候选框。
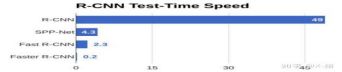
Fast RCNN与RCNN对比
解决的问题:
R-CNN存在以下几个问题:
1,训练分多步。
R-CNN网络中,一张图经由selective search算法提取约2k个建议框【这2k个建议框大量重叠】,而所有建议框变形后都要输入AlexNet CNN网络提取特征【即约2k次特征提取】,会出现上述重叠区域多次重复提取特征,提取特征操作冗余;
region proposal也要单独用selective search的方式获得,R-CNN的训练先要fine tuning一个预训练的网络,针对每个类别都训练一个SVM分类器,最后还要用regressors对bounding-box进行回归,
同理测试过程也包括提取建议框、提取CNN特征、SVM分类和Bounding-box 回归等步骤,步骤比较繁琐。
- 时间和内存消耗比较大。
在训练SVM和回归的时候需要用网络训练的特征作为输入,特征保存在磁盘上再读入的时间消耗还是比较大的。
3、测试的时候也比较慢,每张图片的每个region proposal都要做卷积,重复操作太多。
改进:Fast RCNN
Fast RCNN方法解决了RCNN方法三个问题:
问题一:测试时速度慢
RCNN一张图像内候选框之间大量重叠,提取特征操作冗余。
Fast RCNN将整张图像归一化后直接送入深度网络。在邻接时,才加入候选框信息,在末尾的少数几层处理每个候选框。
问题二:训练时速度慢
在训练时,本文先将一张图像送入网络,紧接着送入从这幅图像上提取出的候选区域。这些候选区域的前几层特征不需要再重复计算。
问题三:训练所需空间大
RCNN中独立的分类器和回归器需要大量特征作为训练样本。 本文把类别判断和位置精调统一用深度网络实现,不再需要额外存储。
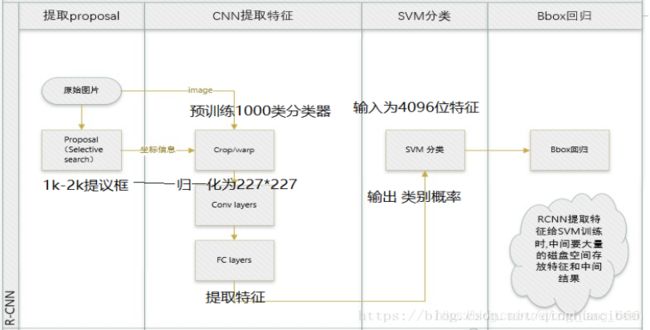

Fast R-CNN算法及其具体训练步骤
优点:通过引入ROI pooling层,避免了R-CNN算法对同一区域多次提取特征的情况从而提高了算法的运行速度,
缺点:总体流程上虽然仍然无法实现端到端的训练,但是也在R-CNN算法的基础上有了很大的改进。
Fast R-CNN算法在训练时依然无法做到端到端的训练,故训练时依旧需要一些繁琐的步骤。
算法流程:
- 输入图像
通过深度网络中的卷积层(VGG、Alexnet、Resnet等中的卷积层)对图像进行特征提取,得到图片的特征图;
- 通过选择性搜索算法得到图像的感兴趣区域(通常取2000个)
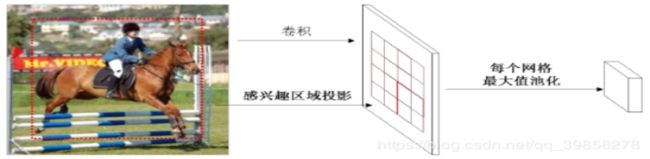
对得到的感兴趣区域进行ROI pooling(感兴趣区域池化):即通过坐标投影的方法,在特征图上得到输入图像中的感兴趣区域对应的特征区域,并对该区域进行最大值池化,这样就得到了感兴趣区域的特征,并且统一了特征大小。
- 对ROI pooling层的输出(及感兴趣区域对应的特征图最大值池化后的特征)作为每个感兴趣区域的特征向量;
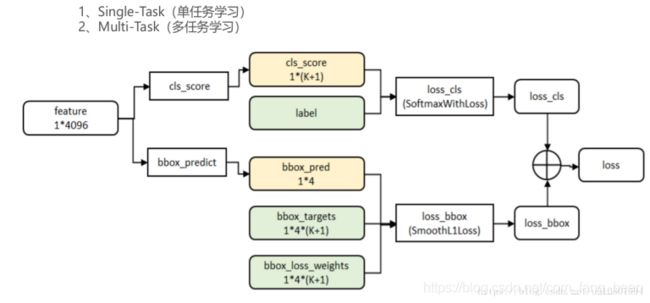
- 将感兴趣区域的特征向量与全连接层相连,并定义了多任务损失函数,分别与softmax分类器和boxbounding回归器相连,分别得到当前感兴趣区域的类别及坐标包围框
对所有得到的包围框进行非极大值抑制(NMS),得到最终的检测结果。
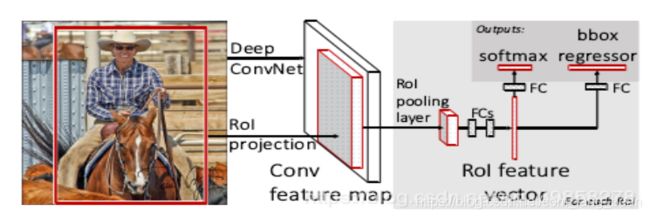
训练的过程:
网络有两个输入:图像和对应的region proposal。
其中region proposal由selective search方法得到,没有表示在流程图中。对每个类别都训练一个回归器,且只有非背景的region proposal才需要进行回归。

输入 224*224 图像
卷积和下采样:经过5个卷积层和2个降采样层(这两个降采样层分别跟在第一和第二个卷积层后面)后,
进入ROIPooling层:该层是输入是conv5层的输出和region proposal,region proposal的个数差不多2000。
全连接层:
先经过两个都是output是4096的全连接层。
再分别经过output个数是21和84的两个全连接层(这两个全连接层是并列的,不是前后关系),
前者是分类的输出,代表每个region proposal属于每个类别(21类)的得分,
后者是回归的输出,代表每个region proposal的四个坐标。
最后是两个损失层:
分类的是softmaxWithLoss,输入是label和分类层输出的得分;
回归的是SmoothL1Loss,输入是回归层的输出和target坐标及weight。
ROI pooling:ROI Pooling的作用是对不同大小的region proposal,从最后卷积层输出的feature map提取大小固定的feature map。因为全连接层的输入需要尺寸大小一样,所以不能直接将不同大小的region proposal映射到feature map作为输出,需要做尺寸变换。
VGG16网络使用H=W=7的参数,即将一个h*w的region proposal分割成H*W大小的网格,然后将这个region proposal映射到最后一个卷积层输出的feature map,最后计算每个网格里的最大值作为该网格的输出,所以不管ROI pooling之前的feature map大小是多少,ROI pooling后得到的feature map大小都是H*W。
三大优点:
- 卷积不再是对每个region proposal进行,而是直接对整张图像,这样减少了很多重复计算。原来RCNN是对每个region proposal分别做卷积,因为一张图像中有2000左右的region proposal,肯定相互之间的重叠率很高,因此产生重复计算。
- 用ROI pooling进行特征的尺寸变换,因为全连接层的输入要求尺寸大小一样,因此不能直接把region proposal作为输入。
- 将regressor放进网络一起训练,每个类别对应一每个类别对应一个regressor,同时用softmax代替原来的SVM分类器
aster RCNN算法详解
思想
从RCNN到fast RCNN,再到本文的faster RCNN,目标检 的四个基本步骤(
候选区域生成,特征提取,分类,位置精修)被统一到一个深度网络框架之内。所有计算没有重复,完全在GPU中完成,大大提高了运行速度。

摘要:算法主要解决两个问题:
1、提出区域建议网络RPN,快速生成候选区域;
2、通过交替训练,使RPN和Fast-RCNN网络共享参数。
faster RCNN可以简单地看做“区域生成网络(RPN)+fast RCNN“的系统,用区域生成网络代替fast RCNN中的Selective Search方法。
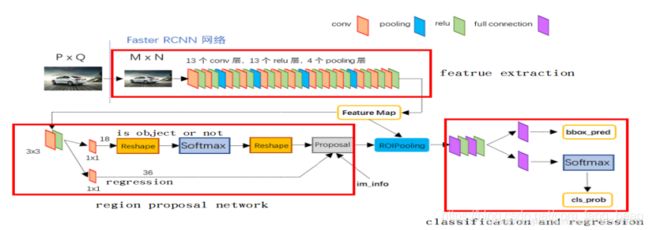

第一部分:特征提取部分
特征提取通过基础的网络模型,最常用的是Resnet50,Resnet101。
输入:原始图片
输出:通过滑动卷积的形式输出对应的feature map(特征图)
第二部分:区域生成网络RPN
解决这个系统中的三个问题:
1. 如何设计区域生成网络
2. 如何训练区域生成网络
3. 如何让区域生成网络和fast RCNN网络共享特征提取网
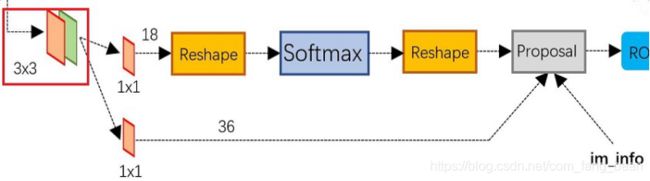
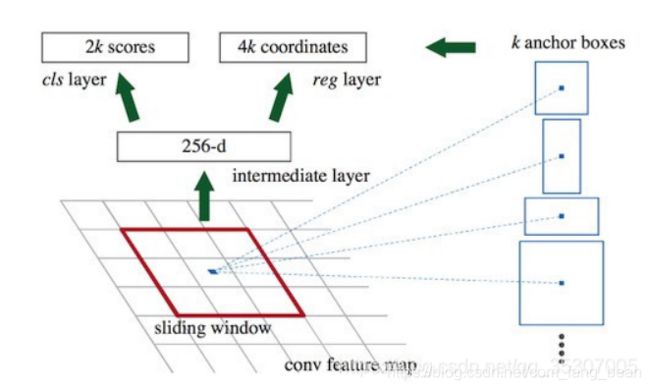
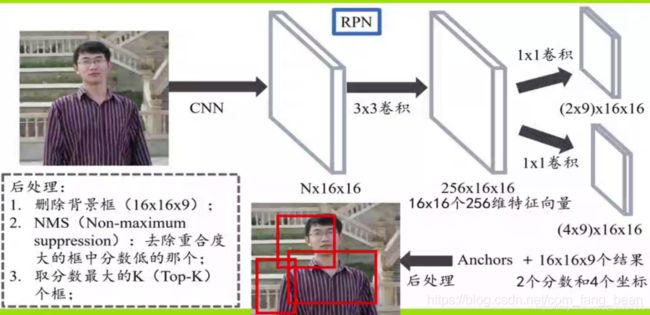
RPN网络结构
两个分支,分别为是否为前景物体的判断,和候选框的粗回归。
通过一个3*3卷积在共享特征图上进行滑动,对应每个cell(中心点),每个中心点生成对应的k个anchor box(候选框),k=9,这9种初始anchor包含三种面积(128×128,256×256,512×512),每种面积又包含三种长宽比(1:1,1:2,2:1),以进行后面的候选框回归以及点操作。
RPN在m,n特征图上会产生m * n * 9个anchor,计算每个产生的anchor和标注框的交并比IoU,大于0.7为前景,小于0.3为背景,去除0.3-0.7之间的anchor。
对剩下的anchor输入RoIPooling层。Roi pooling层的过程就是为了将proposal抠出来的过程,然后resize到统一的大小(14 * 14),然后下采样到7 * 7 * 512最后输入全连接,最后进行边框精修和分类。
感谢宇飞!!!!