飞桨深度学习集训营学习心得
- 本文同时发布于我的个人网站与CSDN博客,在CC BY-NC-SA 2.5 CN协议框架下共享,转载请注明来源
飞桨深度学习集训营学习心得
在这个特殊的寒假中,偶然加入到了飞桨深度学习集训营的学习队伍中。在这里较为系统的学习到了很多深度学习、计算机视觉方面的知识,还入门了Paddle框架的使用方法,相信即使是具有一定深度学习经验的同学,也会不小的收获。在CV部分课程结束的时候参加了集训营的小比赛,得到了满意的成绩。
PART 1 相遇
从一年多前开始,就听闻过Paddle框架,在2019年的“WAIC·开发者论坛”上更是近距离学习了来自Paddle团队成员关于核心架构与实战应用的报告,这一次终于能比较系统的入门Paddle。首先,想简单说一下使用Paddle的体验和感受,以及与其他框架的一些对比。
在使用Paddle之前,先后接触过Tensorflow、Pytorch这些框架,当时的Tensorflow使用的是静态图模型,必须先定义好Graph,然后通过feed对Graph馈入数据和标签。个人感觉纯静态图模型的编程方式入门难度相对比较高,而且与Python这种动态解释语言的设计哲学是相悖的。其次,在tf下写一个好的pipeline(CPU、GPU异步处理数据,充分的设备利用率)对普通用户的难度较大,静态图理论上是效率更优的,但是普通用户未必能充分发挥其能力,甚至效率可能不如其他动态图框架。
作为动态图框架,Pytorch的思想与编程方式都非常的Pythonic,Docs的内容也很详尽,许多地方都附上了简明的公式,非常适合学习。但部署一直是Pytorch广为诟病的短板,很久以来都缺少端到端的高效部署方案。
Paddle作为后起之秀吸收了前人的经验。首先,Paddle是同时支持静态图和动态图的,Paddle很多OP都封装进了paddle.fluid当中,文档内容比较丰富,许多地方会贴出相关学术论文的地址,方便深入学习。其次,Paddle带有大量的官方模型库,以做图像方面相关的研究为例,PaddleCV中给出了主流分类网络的静态图网络以及benchmark,PaddleDetection中给出了主流检测网络的静态图以及benchmark。最后但也是很重要的一点,Paddle支持端到端部署,推理引擎非常高效。
PART 2 小经验
课程虽然不长,但是干货满满,加上与老师同学的交流,学习到了很多,这里结合Paddle框架谈一谈学习到的一些CV知识与经验。(限于个人学识经验,可能存在不严谨之处,以下内容还请批判的看)
一、流程设计
一个深度学习任务大概分为数据分析、预处理、网络设计、训练、结果分析、推理部署6部分。
二、数据分析
-
了解数据规模,ground truth的数量大概可以支撑多大的网络;
-
如果涉及多类别,检查各类别ground
truth的比例,考虑是否用重采样等方法平衡类别; -
合理划分train/validate数据,确保两者数据分布相近;
-
可视化label,检查标注是否合理,清洗脏数据;
-
观察数据特点,必要时需要领域知识(如医学图像),合理安排预处理和网络;
-
基于ground truth bbox聚类调整anchor尺寸(针对anchor-base的网络)。
以本次“AI识虫”数据为例:

可视化ground truth,train/images/1.jpg
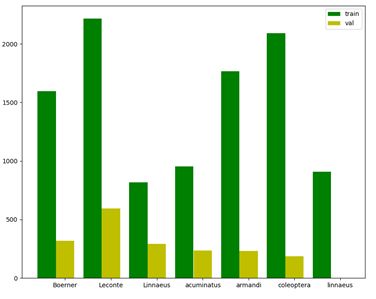
各类别train/val统计柱状图
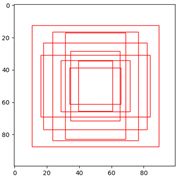
bbox聚类结果
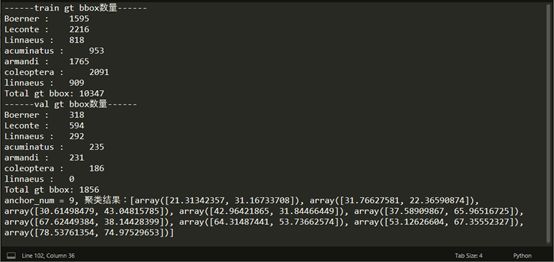
打印统计结果
代码在这里
三、预处理
针对不同数据特点,可以对图像进行去噪、去除无关区域和数据增广等操作,最多的操作就是数据增广。深度学习的本质是参数对数据的拟合,随着网络加深,模型的表达能力得到提高,但参数数量也会随之增加。在定量的数据下,网络的深度必定有一个平衡点。
一个自然的思路就是增加数据。随意数据增广可能引入噪音,增广必须基于数据集特点,将数据想象成高维空间的点,增广出来的数据必须大致落在原来数据集(可能的)分布曲面上(覆盖问题空间)。
以本次“AI识虫”为例:
数据大致上是由垂直向下的相机在固定场景下拍摄的在7种昆虫在不同位置、不同角度的照片。
首先,图片的对称性很强,非常适合进行旋转增强,扩增出更多角度昆虫的照片;
其次背景纯净,可以使用Mix up增强扩增出bbox部分交叠的情况;
最后,相机应该是采用自动曝光/自动对焦/自动白平衡模式,所以导致总体相片的色调不一致,部分照片也出现失焦,采用亮度对比度饱和度抖动可以扩增出色调不一致的情况,随机模糊也能模拟出失焦。

全角度旋转(0~90度旋转+Flip)
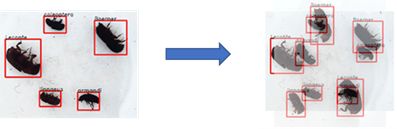
Mix up

阈值法确定新边界
带gt bbox的旋转可能出现边界不准的情况,可以通过bbox面积与旋转角度对边界进行调整;也可以对每个物体使用阈值化等方法确定每个新bbox的精确边界。
此外,增广的方法还有非常多,如Cutout、Crop、Multi-Scale Training/Testing、Coarse
Dropout、Cut Mix、Sample Pairing,还有基于RL对增广的探索方法等。
四、网络设计
自行搭建网络一开始往往效果不理想,建议从PaddleCV或者PaddleDetection提供的网络入手。每种网络的训练方法和适用范围可能不同,建议阅读相关的paper之后再用。
如果选择采用单阶段做目标检测问题,可以直接从PaddleCV的分类网络出发,自己添加bbox回归分支,如此灵活性可以大大提高。
如果选择一些流行的网络,可以获取到预训练模型,基于大数据集的预训练模型往往可以得到更好的效果。
五、训练
训练要注意速度和精度,不同的编码方式可能带来极大的效率差异。
-
Paddle支持分布式/多GPU,自己从头编写的代码调用
paddle.distributed.launch也可以实现数据并行。这点老师在“2-7【手写数字识别】之多GPU训练”中有提及; -
使用
fluid.io.DataLoader异步数据读取而不用同步Feed的方式,实现数据读取和模型训练异步并行的进行。这在IO速度低或预处理耗时的场景下可以大大减少网络每个epoch等待数据馈入的时间。
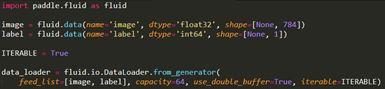
一个异步数据读取的demo
-
静态图效率一般比动态图高,也可以混合用。使用
paddle.fluid.compiler对Graph进行编译后,可以开启内存/显存优化,提高训练效率。静态图/动态图/两者混合都可以编译。 -
个人经验,一般来说,几种优化器在收敛速度上,
Adam>Momentum>SGD,收敛效果视情况而异。 -
可以尝试
piecewise_decay以外的学习率规划方案; -
实验新网络时不要过早的加入正则化;
六、结果分析
-
宏观的,对每种类别绘制出val分数曲线,如AP(30、50、70)、AR、FP、FN;
-
微观的,绘制出每张test图片的infer结果;
根据分数与可视化结果对训练集分布、网络结构、学习策略等做出微调。
训练最终模型时不要忘记加入验证集。
PART 3 启程
作为一款优秀的国产开源深度学习框架,Paddle超出了我的预料。在今后的科研与工作中,会将飞桨作为主要的开发工具之一。我的研究生专业是信息与信号处理,研究方向是自动化的异常信号检测,平时基于兴趣,会做比较多图像相关的个人项目。相信基于Paddle开发,不仅可以提高开发效率,还可以实现端到端的部署,省去大量的设备适配的时间。
接下来,我会继续探索Paddle在CV、NLP方面的应用,阅读官方Docs、阅读相关paper尝试新的网络结构与训练方法、逐步构建自己针对不同问题的pipeline。课程告一段落,但新的征程才刚刚开始!在下个学期,可能也会尝试深度强化学习框架PARL,利用强化学习技术去做一些有趣的事情:)
最后,非常感谢飞桨深度学习集训营的毕老师、孙老师、班主任老师、小助手,带来如此精彩有趣的课程,衷心祝愿飞桨深度学习集训营越办越好!
2020年2月29日
版权声明:本文为Sky的原创文章,遵循署名-非商业性使用-相同方式共享 2.5 中国大陆 (CC BY-NC-SA 2.5 CN)版权协议,转载请附上原文出处链接及本声明。
原文链接:https://willtian.cn/?p=827 / https://blog.csdn.net/qqZHT/article/details/104581958