分布式事务解决方案
分布式事务产生的背景
- 跨库事务:一个本地事务,涉及多个库实例的处理
- 分库分表:分库之后,导致一个SQL被映射到多个库去执行
- 微服务化:一个本地事务,设计到多个跨服务的RPC调用
目前分布式事务的方案都不能百分百解决分布式事务的问题,只是围绕怎么让分布式事务成功率更高来设计方案,每种方案都会有解决不了的问题存在,所以分布式事务不像数据库事务那样,要么commit,要么rollback,各种方案能最大可能的保证每个分支都commit或者rollback,当不能百分百保证所有分支事务都必须commit/rollback,所以会存在某些分支事务commit,某些分支事务rollback这种中间状态。当如果分布式应用能保证全年可用性达到99.99%,也是非常好的
一、DTP事务模型
X/Open DTP(X/Open Distributed Transaction Processing Reference Model) 是X/Open 这个组织定义的一套分布式事务的标准,也就是了定义了规范和API接口,由厂商进行具体的实现。有以下三个角色组成:
AP:Application,我们的应用程序
RM:Resource Manager,资源管理器,可以把它理解为应用程序借用RM对数据库资源的控制管理,资源必须实现XA定义接口
TM:Transaction Manger,事务管理器,负责生成事务唯一标识,监控事务的执行进度,完成事务的最终提交/回滚。
DTP就是一个分布式事务规范,那么实现这套规范,需要自己去实现两个协议,一个是TX协议:APP调用TM接口来开启/控制事务,一个是XA协议:TM调用RM的提交/回滚接口,来控制事务。
那么接下来将讨论以下几种分布式解决方案:2PC、TCC
二、2PC两阶段提交
prepare -> commit ,每个分支事务做完prepare(商品预扣)之后,最后由事务管理器一起commit/rollback,如果某个分支事务prepare失败,则rollback,如果commit/rollback失败,那么就会引发事务的失败,**但相比于两个分支事务独立提交(不做分布式事务处理),2PC有统一prepare的阶段,大大降低了某个事务commit/rollback的失败概率。**但是也引发了新的问题,两个分支事务prepare的时间会增加,也就增加了对资源锁定(商品预扣)时间,降低了并发度。那么我们可以看出,2PC是强一致性的。
MySql jdbc已经实现了XA规范,所以用jdbc就可以实现2PC:
import com.mysql.jdbc.jdbc2.optional.MysqlXAConnection;
import com.mysql.jdbc.jdbc2.optional.MysqlXid;
import javax.sql.XAConnection;
import javax.transaction.xa.XAException;
import javax.transaction.xa.XAResource;
import javax.transaction.xa.Xid;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.SQLException;
public class MysqlXAConnectionTest {
public static void main(String[] args) throws SQLException {
//true表示打印XA语句,,用于调试
boolean logXaCommands = true;
// 获得资源管理器操作接口实例 RM1
Connection conn1 = DriverManager.getConnection("jdbc:mysql://localhost:3306/test", "root", "shxx12151022");
XAConnection xaConn1 = new MysqlXAConnection((com.mysql.jdbc.Connection) conn1, logXaCommands);
XAResource rm1 = xaConn1.getXAResource();
// 获得资源管理器操作接口实例 RM2
Connection conn2 = DriverManager.getConnection("jdbc:mysql://localhost:3306/test", "root",
"shxx12151022");
XAConnection xaConn2 = new MysqlXAConnection((com.mysql.jdbc.Connection) conn2, logXaCommands);
XAResource rm2 = xaConn2.getXAResource();
// AP请求TM执行一个分布式事务,TM生成全局事务id
byte[] gtrid = "g12345".getBytes();
int formatId = 1;
try {
// ==============分别执行RM1和RM2上的事务分支====================
// TM生成rm1上的事务分支id
byte[] bqual1 = "b00001".getBytes();
Xid xid1 = new MysqlXid(gtrid, bqual1, formatId);
// 执行rm1上的事务分支
rm1.start(xid1, XAResource.TMNOFLAGS);//One of TMNOFLAGS, TMJOIN, or TMRESUME.
PreparedStatement ps1 = conn1.prepareStatement("INSERT into user(name) VALUES ('tianshouzhi')");
ps1.execute();
rm1.end(xid1, XAResource.TMSUCCESS);
// TM生成rm2上的事务分支id
byte[] bqual2 = "b00002".getBytes();
Xid xid2 = new MysqlXid(gtrid, bqual2, formatId);
// 执行rm2上的事务分支
rm2.start(xid2, XAResource.TMNOFLAGS);
PreparedStatement ps2 = conn2.prepareStatement("INSERT into user(name) VALUES ('wangxiaoxiao')");
ps2.execute();
rm2.end(xid2, XAResource.TMSUCCESS);
// ===================两阶段提交================================
// phase1:询问所有的RM 准备提交事务分支
int rm1_prepare = rm1.prepare(xid1);
int rm2_prepare = rm2.prepare(xid2);
// phase2:提交所有事务分支
boolean onePhase = false; //TM判断有2个事务分支,所以不能优化为一阶段提交
if (rm1_prepare == XAResource.XA_OK
&& rm2_prepare == XAResource.XA_OK
) {//所有事务分支都prepare成功,提交所有事务分支
rm1.commit(xid1, onePhase);
rm2.commit(xid2, onePhase);
} else {//如果有事务分支没有成功,则回滚
rm1.rollback(xid1);
rm1.rollback(xid2);
}
} catch (XAException e) {
// 如果出现异常,也要进行回滚
e.printStackTrace();
}
}
}
JTA:java版XA实现规范,就不需要上面那些繁琐的建连接,释放连接了,很多事情JTA这套规范已经做了,需要引入下面这个包:
<dependency>
<groupId>javax.transaction</groupId>
<artifactId>jta</artifactId>
<version>1.1</version>
</dependency>
如果是spring应用的话,就用atomikos这个就OK了,基于jta实现的,
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-jta-atomikos</artifactId>
</dependency>
具体代码实现参考:https://zhuanlan.zhihu.com/p/57805893
seata实现2PC

三、TCC - (try-confirm-cancel)
TCC可以说是应用层面的2阶段提交实现,上面的基于XA实现的2PC是一个应用操作多库的时候场景,需要数据库提供XA接口规范(SQL提交/回滚接口),TCC是多应用操作的场景,TCC里的提交/回滚是业务逻辑上的提交/回滚(扣减库存/释放库存),而不是XA上的数据库事务层面的回滚。可以说TCC是2PC在应用层面的实现,需要服务提供方提供三个接口:
try-锁定资源,比如锁定库存,更新表的可售库存字段,这对数据库来说是一个已经提交的SQL事务。
confirm-确定提交,比如锁定的库存,做真实的扣减,一个分布式事务,只有所有分支事务try成功了,才能进行这一步,如果资源锁定都失败,那么confirm肯定失败,这个时候必须调cancel尽快释放锁定的资源。所以这步必须确保成功,因为资源都锁定成功了,这一步在业务逻辑上提交肯定是没问题的,所以要在技术层面尽可能的做到confirm成功,comfirm可能由于网络问题,延时,导致不成功,所以这里需要涉及到重试、幂等。实在不行则只能人工介入兜底。
cancel-回滚锁定的资源,当某个分支事务在锁定资源失败时,回滚前面已经锁定的资源。
TCC相比于XA实现的2PC,优点是锁定资源不需要一直持有预扣库存这条记录的行锁,XA会一直持有这个锁,每个分支都prepare完成之后并commit了才会释放这个锁,持有时间比单个SQL预扣库存的时间更长,所以TCC可以支撑更高的并发度。
关于Seata实现TCC的方案参见:https://blog.csdn.net/huaishu/article/details/89880971
TCC需要注意三种异常处理:
空回滚:try阶段做回滚时,有的分支事务还没做过try,但是需要做整个事务的回滚,没做try的分支事务,就要做空回滚处理。要做的也很简单,需要一张额外的事务控制表,其中有分布式事务 ID 和分支事务 ID,第一阶段 Try 方法里会插入一条记录,表示一阶段执行了。Cancel 接口里读取该记录,如果该记录存在,则正常回滚;如果该记录不存在,则不做处理,直接返回,就是是空回滚。
幂等:commint失败需要重试,所以这里要保证commit接口是幂等的。
悬挂:什么样的情况会造成悬挂呢?在进行try阶段的时候发生了网络拥堵,rpc调用超时,此时触发事务回滚,回滚完成之后,整个事务就结束了,然鹅,这个时候造成网络拥堵的请求进来了,执行了try,这个时候就会有个异常状态的try分支事务得不到confirm。从而产生悬挂。怎么防止悬挂产生呢,就是要在事务控制表里,查看下分支事务状态是不是已经回滚了。
四、AT模式
AT模式是基于 XA 事务模型演进而来的,所以它的整体机制也是一个改进版的两阶段提交协议;
第一阶段:业务数据和回滚日志在同一个本地事务中提交,释放本地锁和连接资源;
第二阶段:提交异步化,非常快速地完成。回滚通过第一阶段的回滚日志进行反向补偿;
4.1 AT 模式第一阶段实现原理
在业务流程中执行库存扣减操作的数据库操作时,Seata 会基于数据源代理对原执行的 SQL 进行解析(Seata 在 0.9.0 版本之后支持自动代理);
然后将业务数据在更新前后保存到 undo_log 日志表中,利用本地事务的 ACID 特性,把业务数据的更新和回滚日志写入同一个本地事务中进行提交;

-
提交前,向TC注册分支事务:申请 tbl_repo 表中主键值等于 1 的记录的全局锁;
-
本地事务提交:业务数据的更新和前面步骤中生成的 UNDO_LOG 一并提交;
-
将本地事务提交的结果上报给TC;
AT 模式和 XA 最大的不同点:分支的本地事务可以在第一阶段提交完成后马上释放本地事务锁定的资源;AT 模式降低了锁的范围,从而提升了分布式事务的处理效率;
4.3 AT 模式第二阶段实现原理
TC 接收到所有事务分支的事务状态汇报之后,决定对全局事务进行提交或者回滚;
4.3.1 事务提交
如果决定是全局提交,说明此时所有分支事务已经完成了提交,只需要清理 UNDO_LOG 日志即可。这也是和 XA 最大的不同点;
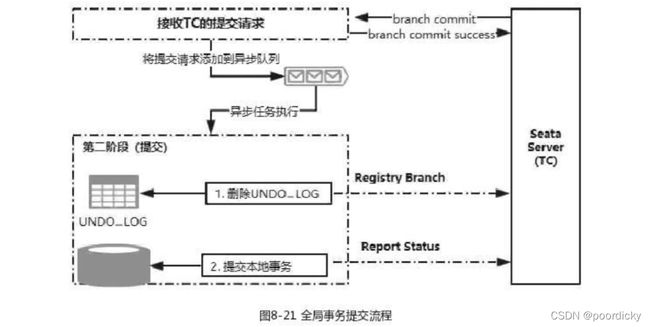
- 分支事务收到 TC 的提交请求后把请求放入一个异步任务队列中,并马上返回提交成功的结果给 TC;
- 从异步队列中执行分支,提交请求,批量删除相应 UNDO_LOG 日志;
4.3.2 事务回滚
整个全局事务链中,任何一个事务分支执行失败,全局事务都会进入事务回滚流程;也就是根据 UNDO_LOG 中记录的数据镜像进行补偿;
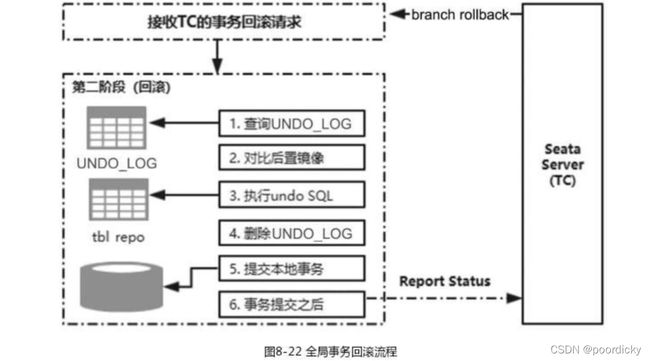
-
通过 XID 和 branch ID 查找到相应的 UNDO_LOG 记录;
-
数据校验:拿 UNDO_LOG 中的 afterImage 镜像数据与当前业务表中的数据进行比较,如果不同,说明数据被当前全局事务之外的动作做了修改,那么事务将不会回滚;
-
如果 afterImage 中的数据和当前业务表中对应的数据相同,则根据 UNDO_LOG中的 beforelmage 镜像数据和业务 SQL 的相关信息生成回滚语句并执行;
-
提交本地事务,并把本地事务的执行结果(即分支事务回滚的结果)上报给 TC;
关于事务的隔离性保证
在 AT 模式中,当多个全局事务操作同一张表时,它的事务隔离性保证是基于全局锁来实现的;
此节AT原理参考文章:https://www.cnblogs.com/dlhjw/p/15873601.html